ES8 向量功能窥探系列(一):混合搜索功能初探与增强
原创
ES8 向量功能窥探系列(一):混合搜索功能初探与增强
原创
Rassyan
修改于 2025-02-20 21:34:18
修改于 2025-02-20 21:34:18
导语
Elasticsearch 8.x 引入了强大的向量搜索功能,使得在大规模数据集上进行高效的k近邻(kNN)搜索成为可能。向量搜索在许多应用场景中都非常重要,例如RAG、推荐系统、图像搜索等等。本文旨在深入浅出地剖析Elasticsearch 8.x的kNN搜索和混合搜索功能,介绍其实现原理和关键技术点。同时,我们还将解读腾讯云ES对社区做出的相关贡献,通过源码级别的解读,帮助读者更好地理解和应用Elasticsearch的向量搜索功能。
1. kNN查询流程分析
1.1 查询类型
熟悉Elasticsearch的朋友对查询的几个阶段一定不陌生:Query Phase和Fetch Phase。
这两个Phase是query_then_fetch(默认的search_type)会产生的两个阶段。而另一个search_type,dfs_query_then_fetch,顾名思义,它的阶段分为三个:DFS Phase,DFS Query Phase和Fetch Phase。
我们先做个有趣的尝试,在执行包含kNN查询的语句上,添加参数search_type=query_then_fetch,我们看会发生什么。
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "cannot set [search_type] when using [knn] search, since the search type is determined automatically"
}
],
"type": "illegal_argument_exception",
"reason": "cannot set [search_type] when using [knn] search, since the search type is determined automatically"
},
"status": 400
}可以看到提示kNN搜索有固定的search_type。在Elasticsearch的源码中可以看到kNN查询会必然分配DFS_QUERY_THEN_FETCH的查询模式。org.elasticsearch.action.search.TransportSearchAction#adjustSearchType
static void adjustSearchType(SearchRequest searchRequest, boolean singleShard) {
// if there's a kNN search, always use DFS_QUERY_THEN_FETCH
if (searchRequest.hasKnnSearch()) {
searchRequest.searchType(DFS_QUERY_THEN_FETCH);
return;
}
...
}1.2 阶段分析
在传统的BM25类搜索中,分布式频率统计(Distributed Frequency Statistics,简称DFS)阶段,系统会在实际执行查询之前,从所有的分片中收集额外的信息,这个阶段的目的是为了使得score更加准确。由于每个分片都是独立的,它们只知道自己的局部数据,没有全局视图。对于文档的评分可能会因为分片内部的因素(如逆文档频率Inverse Document Frequency,简称IDF),分片无法准确计算IDF,这可能导致跨分片评分不一致。通过DFS阶段,可以收集这些分片特有的统计信息,以便在后续的查询阶段能够更公平地比较来自不同分片的评分,确保评分的准确性和一致性。
而在kNN查询中,DFS阶段的目的则略有不同。由于kNN搜索依赖于向量空间中的距离计算,而不是基于文本的词频统计,DFS阶段在这里的作用是从每个分片中收集最佳的k个候选结果。这些候选结果随后会被合并,以确定全局最佳的k个结果。然后,这些全局最佳的k个命中结果会被传递到DFS Query Phase。
DFS_QUERY_THEN_FETCH的查询模式会先执行DFS Phase,通过KnnVectorQueryBuilder构建向量查询。org.elasticsearch.search.dfs.DfsPhase#executeKnnVectorQuery
private void executeKnnVectorQuery(SearchContext context) throws IOException {
...
List<KnnSearchBuilder> knnSearch = context.request().source().knnSearch();
List<KnnVectorQueryBuilder> knnVectorQueryBuilders = knnSearch.stream().map(KnnSearchBuilder::toQueryBuilder).toList();
...
List<DfsKnnResults> knnResults = new ArrayList<>(knnVectorQueryBuilders.size());
for (int i = 0; i < knnSearch.size(); i++) {
...
// 构建并执行向量查询
Query knnQuery = searchExecutionContext.toQuery(knnVectorQueryBuilders.get(i)).query();
knnResults.add(singleKnnSearch(knnQuery, knnSearch.get(i).k(), context.getProfilers(), context.searcher(), knnNestedPath));
}
context.dfsResult().knnResults(knnResults);
}DFS Phase会将合并后的候选结果,传递到下一个阶段:DFS Query Phase。org.elasticsearch.action.search.SearchDfsQueryThenFetchAsyncAction#getNextPhase`
@Override
protected SearchPhase getNextPhase(final SearchPhaseResults<DfsSearchResult> results, SearchPhaseContext context) {
final List<DfsSearchResult> dfsSearchResults = results.getAtomicArray().asList();
final AggregatedDfs aggregatedDfs = SearchPhaseController.aggregateDfs(dfsSearchResults);
// 合并每个分片收集到的最佳的k个候选结果
final List<DfsKnnResults> mergedKnnResults = SearchPhaseController.mergeKnnResults(getRequest(), dfsSearchResults);
return new DfsQueryPhase(
dfsSearchResults,
aggregatedDfs,
mergedKnnResults,
queryPhaseResultConsumer,
(queryResults) -> new FetchSearchPhase(queryResults, aggregatedDfs, context),
context
);
}DFS Query Phase则会通过KnnScoreDocQueryBuilder构建候选结果的评分查询。
org.elasticsearch.action.search.DfsQueryPhase#rewriteShardSearchRequest
ShardSearchRequest rewriteShardSearchRequest(ShardSearchRequest request) {
...
for (DfsKnnResults dfsKnnResults : knnResults) {
List<ScoreDoc> scoreDocs = new ArrayList<>();
// 拆分DFS阶段合并后的结果
for (ScoreDoc scoreDoc : dfsKnnResults.scoreDocs()) {
if (scoreDoc.shardIndex == request.shardRequestIndex()) {
scoreDocs.add(scoreDoc);
}
}
...
// 携带DFS阶段的结果构建评分查询
QueryBuilder query = new KnnScoreDocQueryBuilder(scoreDocs.toArray(new ScoreDoc[0]))
.boost(source.knnSearch().get(i).boost()).queryName(source.knnSearch().get(i).queryName());
...
subSearchSourceBuilders.add(new SubSearchSourceBuilder(query));
i++;
}
source = source.shallowCopy().subSearches(subSearchSourceBuilders).knnSearch(List.of());
request.source(source);
return request;
}1.3 流程总结
尽管DFS阶段的原始设计目的是收集词频信息,kNN搜索实际上并没有这个概念,有点“货不对板”。但DFS阶段基本思想是收集和合并全局信息,kNN搜索也有这个需要。因此,Elasticsearch选择在DFS阶段进行kNN搜索的全局向量信息收集和合并操作。
目前,我们了解了kNN搜索会在:
- DFS Phase:使用
KnnVectorQueryBuilder构建分片级别的向量查询,利用HNSW算法来快速找到与查询向量最近的文档向量,最终再全局归并。HNSW算法本篇不作分析。 - DFS Query Phase:使用
KnnScoreDocQueryBuilder构建分片级别的评分查询,以便在最终的结果集中对文档进行排序。
2. kNN功能分析
2.1 顶层kNN查询
顾名思义,顶层kNN查询(Top-level kNN search)将knn子句写在查询DSL的顶层,形如:
GET hybird_test/_search
{
"query": {...},
"knn": {
"field": "vector",
"num_candidates": 5,
"k": 5,
"query_vector": [...]
}
}我们上面介绍的流程就是顶层kNN查询的大体流程。它是ES 8.x引入的,在混合搜索、向量搜索上专门设立、最常用的查询语法。
在SearchSourceBuilder中定义如下,List的定义代表其可以一次性进行多个kNN搜索,多路的得分会被加和处理。
private List<KnnSearchBuilder> knnSearch = new ArrayList<>();引入了和query子句平级的kNN子句后,一次DSL查询会“兵分多路”,这就是我们所说的混合搜索,Elasticsearch 8.x的版本支持原生的混合搜索,这是众多向量数据库所不能及的。混合搜索结合了BM25和向量搜索各自的优势,实现了比BM25搜索的召回更具语义性,比向量搜索的召回更加精准。
2.2 Query中kNN查询
除了ES 8.x引入的顶层kNN查询,在ES 8.12版本还引入了Query中的kNN查询(kNN Query),用法形如:
GET hybird_test/_search
{
"size": 5,
"query": {
"bool": {
"must": [
{
"match": {...}
},
{
"knn": {
"field": "vector",
"num_candidates": 5,
"query_vector": [...]
}
}
]
}
}
}Query中kNN查询是为了满足更多的专家级需求,因为它将kNN查询子句作为传统的BM25类的查询子句处理,与传统丰富的查询组合用法如bool、dis_max、function_score等兼容。然而BM25评分基于TF/IDF,kNN的评分基于向量的距离(余弦、点积、欧式多种距离计算方式),原理和方式相差甚远,复合查询的评分会需要用户对最终的评分运算方式有十分精确的理解和把控。
Query中kNN查询也不再使用DFS阶段进行近邻搜索,收集全局信息。
进行kNN搜索的首选方法是使用顶层kNN查询。Query中的kNN查询作为ES支持的能力,只做介绍不做展开。腾讯云ES刚刚发布了8.13.3版本,也自然支持了这个专家级的功能。
3. RRF分析
3.1 融合算法介绍
Ranked Retrieval Fusion(RRF)是一种融合算法,用于将多个查询结果进行融合,以提高搜索结果的准确性。RRF的基本原理是对每个查询结果进行排序,并根据排名分配权重,最终将各个查询结果的权重进行累加,生成融合后的结果。
RRF的数学公式如下:
其中, \text{rank}_i(d) 表示文档 d 在第 i 个查询结果中的排名, k 是一个常数,用于平滑排名。
3.2 使用方法
在混合搜索中,通过指定rank参数来启用RRF
GET hybird_test/_search
{
"query": {...},
"knn": {...},
"rank": {
"rrf": {
"window_size": 100,
"rank_constant": 60
}
}
}3.3 功能缺陷:仅保留rank,抹除score
RRF算法只采用了各路召回的排名,不关注得分,启用了RRF的查询会抹除过程中的所有得分信息,最终只保留融合后的排名。
不知道融合结果中每个文档的具体得分,也就无法知道融合后的结果来源于哪路召回,查询过程就“黑盒化”了,查询分析会受到很大阻碍。RRF查询结果示例:
{
...
"hits": {
...
"hits": [
{
"_index": "hybird_test",
"_id": "999006",
"_score": null,
"_rank": 1
},
{
"_index": "hybird_test",
"_id": "999005",
"_score": null,
"_rank": 2
}
]
}
}4. RRF功能增强
4.1 找回抹除掉的来源和得分
笔者通过提交issue与社区讨论,得出了最短改造路径:通过“命名查询”(Named queries)的实现方式。命名查询通俗讲,允许对DSL的查询子句命名,从而从最终结果中得到已命名子句的匹配信息,包括命中、子句的具体得分情况。
功能实现后,开启RRF的混合搜索的效果如下,可以在matched_queries中直观看到召回文档来源于哪路搜索:
{
...
"hits": {
...
"hits": [
{
"_index": "hybird_test",
"_id": "999006",
"_score": null,
"_rank": 1,
"matched_queries": [
"query",
"knn"
]
},
{
"_index": "hybird_test",
"_id": "999005",
"_score": null,
"_rank": 2,
"matched_queries": [
"knn"
]
}
]
}
}通过_search中指定include_named_queries_score=true参数,还可以获得各路搜索的具体得分:
{
...
"hits": {
...
"hits": [
{
"_index": "hybird_test",
"_id": "999006",
"_score": null,
"_rank": 1,
"matched_queries": {
"query": 1,
"knn": 0.9124442
}
},
{
"_index": "hybird_test",
"_id": "999005",
"_score": null,
"_rank": 2,
"matched_queries": {
"knn": 1
}
}
]
}
}4.2 源码改造细节
由于Query中kNN查询和传统DSL子句有着一样的使用方式,在源码中也是直接继承了传统DSL子句的命名查询的能力:org.elasticsearch.index.query.AbstractQueryBuilder#queryName(java.lang.String)。
所以功能改造任务就简化为,只需实现顶层kNN查询的queryName功能,也就是在DFS阶段和DFS Query阶段,让kNN查询支持并有效传递queryName。
得益于Elasticsearch源码优良设计和复用能力,这一改造最终简化为3点:
- 将
_name字段添加到KnnSearchBuilder中。 - 修改序列化以包含
_name。 - 确保
_name在跨阶段的查询执行期间得到处理并包含在响应中。
笔者按照以上思路完成开发和测试验证,提交了PR,最终这一功能也被社区所采纳。
4.3 增强功能成效
下面一张图概括了该功能的最终效果
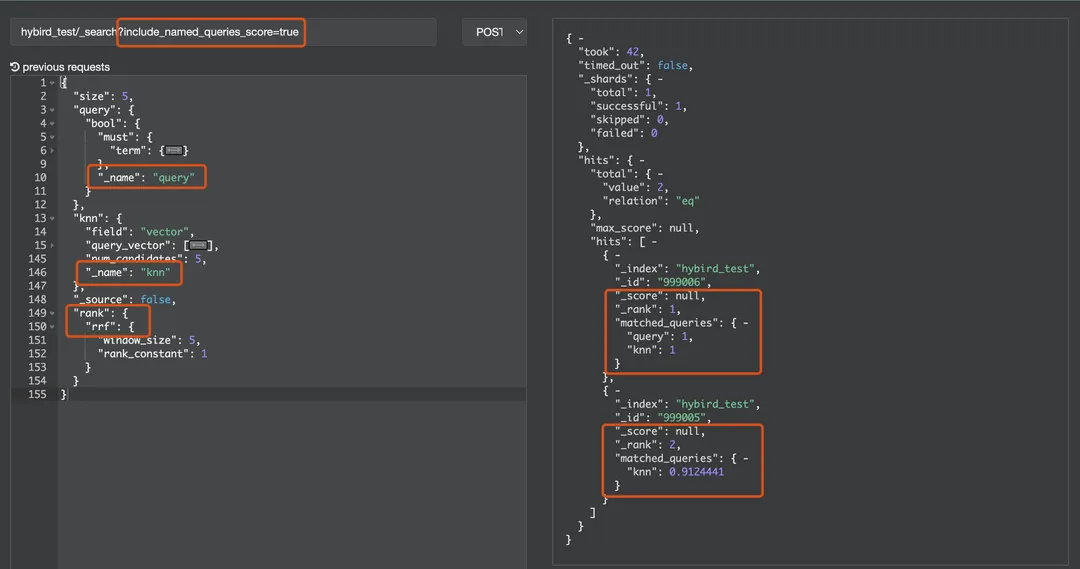
knn_with_query_name
4.4 腾讯云ES的贡献
该功能已贡献给社区,按Elasticsearch官方的计划,将会在8.15版本进行功能的发布。
而腾讯云ES自发完成了该功能的提出与实现,在腾讯云ES新发布的ES 8.13.3版本,和8.11.3的新内核版本上,均能提前使用到该功能特性。
腾讯云ES也率先将该功能特性服务于内部微信某平台的客户,快速支持了客户业务的顺利上线。
5. 总结
5.1 内容回顾
本文初步探索了Elasticsearch 8.x的kNN搜索功能,包括其查询流程、功能实现和RRF融合算法。通过源码级别的解析,帮助读者深入理解Elasticsearch的向量搜索功能。同时介绍了腾讯云ES在向量搜索方向对社区的相关贡献,对RRF混合搜索实现了功能上的增强。
5.2 系列展望
笔者希望这个文章系列,对ES8引入的向量功能各个方面都能够进行初步的解析和探索,以达到科普和共同进步的目的。也希望更多有向量/混合搜索需求的用户,可以尝试和使用腾讯云ES 8.x,如果您也有独到的需求或想法,可以联系到腾讯云ES团队,我们将竭尽全力与您共同探索与解决。目前最新腾讯云ES紧跟社区步伐,发布了8.13.3版本,同时也在不断地增加我们的自研功能和优化,我们会在后面带来更多的剖析。由于水平有限,如果文章中有错误之处,敬请谅解,笔者十分愿意进行探讨和勘误;如果您有感兴趣的ES向量功能点,可以进行留言,笔者也会纳入后续系列文章的选题考虑。
下期内容预告:《ES8向量功能窥探系列(二):向量数据的存储与优化》
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号