使用Python城市交通大数据分析与可视化的研究案例

使用Python城市交通大数据分析与可视化的研究案例

renhai
发布于 2024-06-06 15:54:21
发布于 2024-06-06 15:54:21
介绍
在现代城市中,交通管理和规划面临越来越大的挑战。随着城市化进程的加速,交通拥堵、公共交通优化以及智能出行服务成为亟待解决的问题。利用大数据技术分析和可视化城市交通数据,为城市交通管理提供科学的决策支持,已经成为智慧城市建设的重要方向。Python作为一种功能强大且灵活的编程语言,在城市交通大数据分析与可视化中得到了广泛应用。通过使用Python,可以对交通流量数据、气象数据、公交客流数据等多源数据进行清洗、处理、分析和可视化,从而揭示交通模式和规律,优化交通管理策略。
在本研究中,我们将探讨Python在城市交通大数据分析中的应用,包括交通拥堵特征分析、交通流关联分析、智慧交通指标分析、交通指数分析和即席查询等方面。通过实际案例,如台北捷运系统的交通数据分析,我们将详细介绍数据清洗、主成分分析(PCA)、聚类分析(K-Means)和可视化技术的应用。此外,我们还将展示如何利用Python的Matplotlib、Seaborn和Plotly等可视化工具,直观地展示交通数据的分布和趋势。
通过本研究,我们希望能够为城市交通管理部门提供有价值的参考,帮助他们更好地理解和应对城市交通挑战,提高交通管理的效率和质量。
Python在城市交通大数据分析中的应用
交通拥堵特征分析
快速路网交通拥堵态势分布规律挖掘
在城市交通大数据分析中,交通拥堵特征分析是一个重要的应用领域。通过对多源数据的挖掘和分析,可以发现交通拥堵的规律和特征。Python作为一种强大的数据分析工具,广泛应用于交通拥堵特征分析中。例如,利用Python的pandas库和matplotlib库,可以对交通流量数据进行清洗、处理和可视化,帮助研究人员识别交通拥堵的高发区域和时间段。
通过对快速路网交通拥堵态势的分布规律进行挖掘,可以为交通管理部门提供决策支持。例如,利用Python的scikit-learn库,可以对交通流量数据进行聚类分析,识别出交通拥堵的热点区域,并通过可视化工具展示出来。
交通流关联分析
基于气象环境数据的关联分析应用
交通流量不仅受到道路条件的影响,还受到气象环境的影响。通过将交通流量数据与气象数据进行关联分析,可以更全面地了解交通流量的变化规律。Python在这方面提供了丰富的工具和库,例如,利用Python的numpy和pandas库,可以方便地处理和分析大规模的交通流量和气象数据。
在基于Python大数据可视化的城市通勤特征分析研究[1]中,通过对上海市公共交通卡数据的分析,研究人员发现了气象条件对交通流量的显著影响。例如,在雨天和雾天,交通流量显著减少,而在晴天和阴天,交通流量相对较高。通过Python的matplotlib库,可以将这些关联关系以图表的形式展示出来,帮助交通管理部门制定更合理的交通管理策略。
智慧交通指标分析
公交客流热力图
公交客流热力图是智慧交通指标分析中的一个重要应用。通过对公交客流数据的分析,可以了解不同区域和时间段的公交客流分布情况。Python在这方面提供了强大的数据可视化工具,例如,利用Python的seaborn库,可以方便地绘制公交客流热力图。
通过对公交客流数据的分析,研究人员绘制了公交客流热力图,展示了不同区域和时间段的公交客流分布情况。例如,在早高峰和晚高峰时段,市中心区域的公交客流量显著增加,而在非高峰时段,公交客流量相对较少。通过这些热力图,可以帮助交通管理部门优化公交线路和班次安排,提高公交服务的效率和质量。
区域客流时空动态图
区域客流时空动态图是另一种重要的智慧交通指标分析工具。通过对区域客流数据的时空分析,可以了解不同区域和时间段的客流变化情况。Python在这方面提供了丰富的工具和库,例如,利用Python的folium库,可以方便地绘制区域客流时空动态图。
在上海地铁预测可视化[2]中,通过对上海地铁各个站点的客流量进行预测和可视化,研究人员绘制了区域客流时空动态图,展示了不同时间段的地铁客流分布情况。
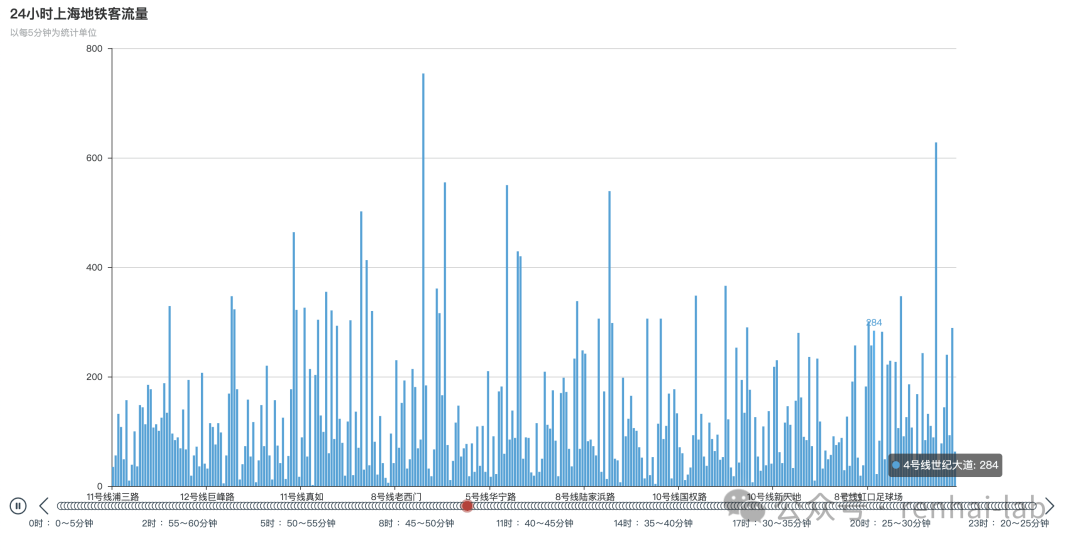
来自metro_prediction仓库
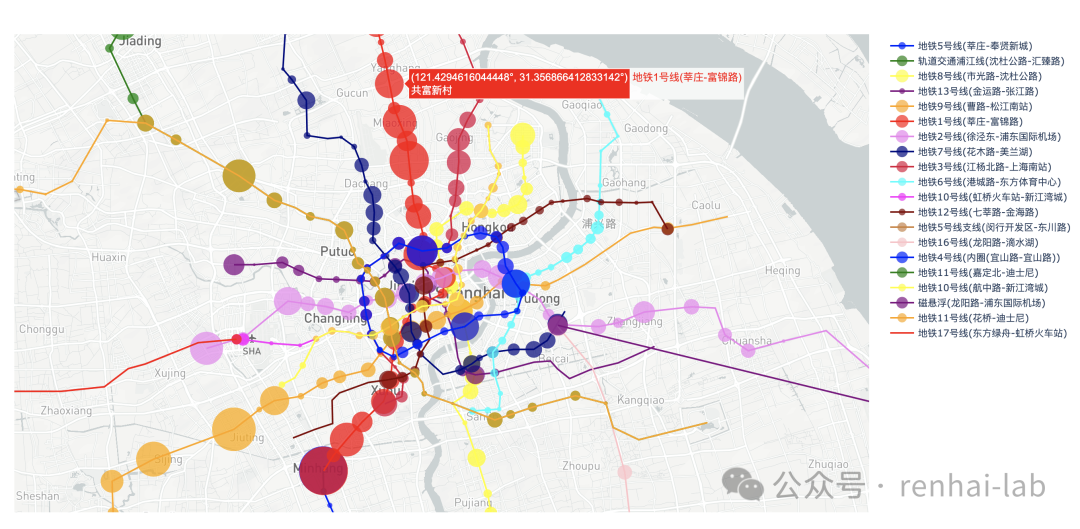
来自metro_prediction仓库
例如,在早高峰时段,市中心区域的地铁客流量显著增加,而在晚高峰时段,郊区区域的地铁客流量相对较高。通过这些时空动态图,可以帮助交通管理部门优化地铁线路和班次安排,提高地铁服务的效率和质量。
感兴趣的可以拿到代码试一下:

Readme Card
智能地址定位服务
智能地址定位服务是智慧交通系统中的一个重要组成部分。通过对交通数据的分析和处理,可以实现智能地址定位服务,帮助用户快速找到目的地。Python在这方面提供了强大的数据处理和分析工具,例如,利用Python的geopy库,可以方便地进行地址定位和地理编码。
比如腾讯云发布的智能地址服务,基于海量地址数据库和AI算法,提供多行业、多场景的智能地址解决方案,腾讯云[3]。
交通指数基本分析
历史回放功能
交通指数基本分析是智慧交通系统中的一个重要应用。通过对交通指数数据的分析,可以了解交通流量的变化规律和趋势。Python在这方面提供了丰富的工具和库,例如,利用Python的pandas和matplotlib库,可以方便地进行交通指数数据的分析和可视化。
通过对交通指数数据的分析,研究人员实现了历史回放功能,展示了不同时间段的交通流量变化情况。例如,通过历史回放功能,可以查看某一天的交通流量变化情况,了解交通拥堵的高发时段和区域。通过这些历史回放功能,可以帮助交通管理部门制定更合理的交通管理策略,提高交通管理的效率和质量。
交通指数分析
交通指数分析是智慧交通系统中的另一个重要应用。通过对交通指数数据的分析,可以了解交通流量的变化规律和趋势。Python在这方面提供了丰富的工具和库,例如,利用Python的scikit-learn库,可以对交通指数数据进行聚类分析,识别出交通拥堵的热点区域。
通过对轨道交通数据的分析,研究人员实现了交通指数分析,展示了不同区域和时间段的交通流量变化情况。例如,通过交通指数分析,可以识别出交通拥堵的高发区域和时间段,帮助交通管理部门制定更合理的交通管理策略,提高交通管理的效率和质量。
即席查询
即席查询是智慧交通系统中的一个重要功能。通过对交通数据的分析和处理,可以实现即席查询功能,帮助用户快速获取交通信息。Python在这方面提供了强大的数据处理和分析工具,例如,利用Python的sqlite3库,可以方便地进行数据库查询和管理。
通过对地铁客流量数据的分析,研究人员实现了即席查询功能,用户可以通过输入站点名称,快速获取该站点的客流量信息。例如,通过即席查询功能,用户可以了解某个站点的客流量变化情况,帮助用户合理安排出行时间和路线。通过这些即席查询功能,可以提高用户的出行效率和便利性。
数据分析
数据集描述
在本研究案例中,我们使用了台北捷运系统的每小时交通数据。数据集包含以下列:日期、小时、起点、终点、乘客数量。为了更好地分析工作日的交通模式,我们仅保留了工作日的数据。工作日的数据更能反映不同站点之间的有趣模式,例如住宅区的站点在白天可能有更多的通勤者进入,而在晚上,商业区的站点可能有更多的人进入。(source[4])
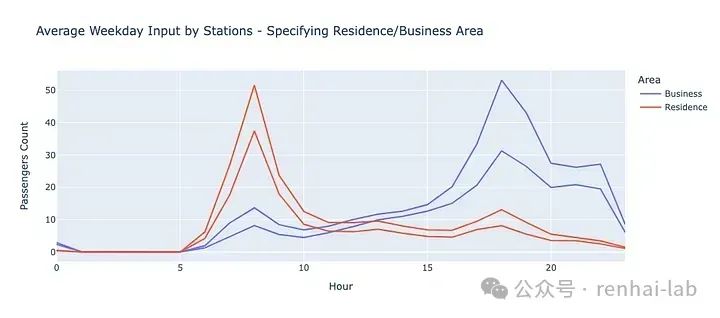
数据清洗
数据清洗是数据分析中至关重要的一步。我们需要确保数据的准确性和一致性,以便进行后续的分析和建模。以下是数据清洗的一些关键步骤:
- 缺失值处理:检查数据集中是否存在缺失值,并根据情况进行填补或删除。
- 数据类型转换:确保每一列的数据类型正确,例如日期列应为日期类型,乘客数量应为整数类型。
- 异常值检测:识别并处理异常值,例如某些小时的乘客数量异常高或低。
- 数据标准化:将数据标准化,以便在后续的分析中能够更好地比较不同站点的交通模式。
主成分分析 (PCA)
主成分分析(PCA)是一种降维技术,可以帮助我们识别数据中最重要的特征。在本案例中,我们使用PCA来减少数据的维度,并捕捉不同站点的交通模式。PCA的主要步骤如下:
- 数据标准化:在应用PCA之前,我们需要对数据进行标准化处理,以确保每个特征具有相同的尺度。
- 计算协方差矩阵:协方差矩阵反映了特征之间的相关性。
- 特征值分解:通过特征值分解,我们可以获得特征向量和特征值,特征向量代表了新的特征空间,特征值则表示每个特征向量的重要性。
- 选择主成分:根据特征值的大小,我们选择最重要的几个主成分来表示原始数据。
在本案例中,我们将参数 n_components 指定为 3,意味着我们选择三个最重要的主成分来表示数据。(source[5])

聚类分析 (K-Means)
在获得PCA结果后,我们进一步使用K-Means聚类算法对站点进行聚类。K-Means是一种常用的无监督学习算法,可以将数据点分成K个簇,使得同一簇内的数据点尽可能相似,不同簇之间的数据点尽可能不同。以下是K-Means聚类的主要步骤:
- 选择K值:确定要分成的簇的数量K。可以通过肘部法则(Elbow Method)来选择合适的K值。
- 初始化簇中心:随机选择K个数据点作为初始簇中心。
- 分配数据点:将每个数据点分配到离它最近的簇中心。
- 更新簇中心:计算每个簇的中心点,并将其作为新的簇中心。
- 重复步骤3和4:直到簇中心不再变化或达到预定的迭代次数。
通过K-Means聚类,我们可以将台北捷运的站点分成几个簇,每个簇代表具有相似交通模式的站点。(source[6])
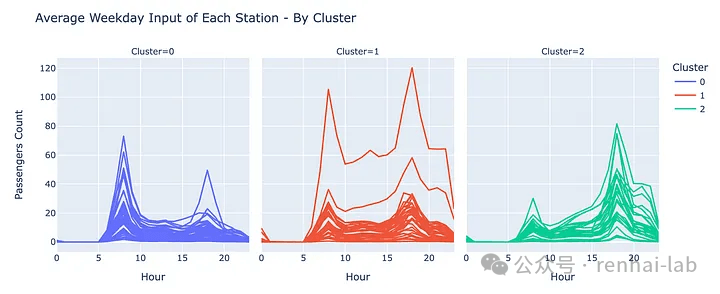
K-Means聚类结果
- 簇 0 :白天乘客较多,因此可能是“生活区”组。
- 簇 2:晚上乘客较多,因此可能是“商业区”组。
- 簇 1 :白天和黑夜都挤满了进入车站的人,解释这些车站的性质比较复杂,因为不同的车站可能有不同的原因。下面,我们将看看这个集群中的2个极端案例。
可视化
数据可视化是数据分析中不可或缺的一部分,它可以帮助我们更直观地理解数据和分析结果。在本案例中,我们使用了多种Python可视化库来展示分析结果:
- Plotly:用于创建交互式的3D散点图,以可视化K-Means聚类的结果。Plotly的强大之处在于它能够生成高质量的交互式图表,适用于展示复杂的数据关系。(source[7])
- Matplotlib:作为Python中最基础的可视化库,Matplotlib提供了丰富的绘图功能,可以创建各种类型的图表。我们使用Matplotlib来绘制每个站点的小时交通趋势图。(source[8])
- Seaborn:基于Matplotlib构建,Seaborn简化了复杂图表的创建过程,特别适合统计分析。我们使用Seaborn来绘制站点之间的交通模式对比图。(source[9])
结果与洞察
通过PCA和K-Means聚类分析,我们得到了以下洞察:
- 交通模式的差异:不同站点的交通模式存在显著差异。例如,台北车站作为一个重要的交通枢纽,在早晚高峰时段的乘客数量明显较多。而台北动物园站则在工作日的任何时段乘客数量都较少,因为周围居民较少,且市民在工作日很少去动物园。(source[10])
- 簇的特征:通过K-Means聚类,我们将站点分成了几个簇,每个簇代表具有相似交通模式的站点。例如,簇1中的站点在早晚高峰时段的乘客数量较多,而簇2中的站点则在中午时段的乘客数量较多。(source[11])
- 主成分的解释:PCA的结果显示,前三个主成分可以解释大部分数据的变异。第一个主成分主要反映了早晚高峰时段的交通模式,第二个主成分反映了中午时段的交通模式,第三个主成分则反映了夜间的交通模式。(source[12])
通过这些分析,我们可以更好地理解台北捷运系统的交通模式,为交通管理和规划提供有价值的参考。
数据可视化
数据预处理与转换
在进行数据可视化之前,数据预处理是一个关键步骤。数据预处理包括数据清洗、格式转换和特征工程等步骤。以交通数据为例,通常需要将时间戳从字符串格式转换为日期时间格式,以便进行时间序列分析。以下是一个示例代码片段,展示了如何使用Python进行时间戳转换:
import pandas as pd
# 读取数据
df = pd.read_csv('traffic_data.csv')
# 将时间戳从字符串转换为日期时间格式
df['Datetime'] = pd.to_datetime(df['Datetime'])
在数据预处理过程中,还需要处理缺失值和异常值。缺失值可以通过插值法或填充法进行处理,而异常值则可以通过统计方法或机器学习方法进行检测和处理。
数据可视化工具
Python提供了多种数据可视化工具,如Matplotlib、Seaborn和Plotly等。这些工具可以帮助我们直观地展示数据的分布和趋势。
Matplotlib
Matplotlib是Python中最基础的绘图库,适用于生成静态、出版质量的图表。以下是一个使用Matplotlib绘制时间序列图的示例:
import matplotlib.pyplot as plt
# 绘制时间序列图
plt.figure(figsize=(10, 6))
plt.plot(df['Datetime'], df['Traffic_Volume'])
plt.xlabel('Datetime')
plt.ylabel('Traffic Volume')
plt.title('Traffic Volume Over Time')
plt.show()
Seaborn
Seaborn是基于Matplotlib的高级绘图库,提供了更为美观和简洁的图表。以下是一个使用Seaborn绘制热力图的示例:
import seaborn as sns
# 绘制热力图
plt.figure(figsize=(12, 8))
sns.heatmap(df.corr(), annot=True, cmap='coolwarm')
plt.title('Correlation Heatmap')
plt.show()
Plotly
Plotly是一个交互式绘图库,适用于生成动态和交互式图表。以下是一个使用Plotly绘制交互式时间序列图的示例:
import plotly.express as px
# 绘制交互式时间序列图
fig = px.line(df, x='Datetime', y='Traffic_Volume', title='Interactive Traffic Volume Over Time')
fig.show()
交通数据可视化案例
在城市交通大数据分析中,数据可视化可以帮助我们理解交通流量的变化趋势和模式。以下是一些常见的交通数据可视化案例:
时间序列分析
时间序列分析是交通数据分析中的重要方法。通过绘制时间序列图,我们可以观察交通流量在不同时间段的变化趋势。例如,使用Prophet[13]模型进行交通流量预测,并绘制预测结果:
from fbprophet import Prophet
# 初始化Prophet模型
model = Prophet(yearly_seasonality=True)
# 训练模型
model.fit(df[['Datetime', 'Traffic_Volume']].rename(columns={'Datetime': 'ds', 'Traffic_Volume': 'y'}))
# 生成未来60天的数据框
future = model.make_future_dataframe(periods=60)
# 进行预测
forecast = model.predict(future)
# 绘制预测结果
fig = model.plot(forecast)
plt.title('Traffic Volume Forecast')
plt.show()
热力图分析
热力图可以帮助我们理解交通流量在不同时间和地点的分布情况。例如,使用Seaborn绘制交通流量的日均热力图:
# 提取日期和时间信息
df['Date'] = df['Datetime'].dt.date
df['Hour'] = df['Datetime'].dt.hour
# 计算日均交通流量
daily_traffic = df.groupby(['Date', 'Hour'])['Traffic_Volume'].mean().unstack()
# 绘制热力图
plt.figure(figsize=(14, 8))
sns.heatmap(daily_traffic, cmap='YlGnBu')
plt.title('Daily Average Traffic Volume Heatmap')
plt.xlabel('Hour of Day')
plt.ylabel('Date')
plt.show()
交通预测模型的可视化
在交通预测中,模型的可视化可以帮助我们评估模型的性能和预测结果的准确性。以下是一些常见的交通预测模型及其可视化方法:
ARIMA模型
ARIMA模型是一种常见的时间序列预测模型。以下是使用ARIMA模型进行交通流量预测并绘制预测结果的示例:
from statsmodels.tsa.arima_model import ARIMA
# 拟合ARIMA模型
model = ARIMA(df['Traffic_Volume'], order=(5, 1, 0))
model_fit = model.fit(disp=0)
# 进行预测
forecast, stderr, conf_int = model_fit.forecast(steps=60)
# 绘制预测结果
plt.figure(figsize=(10, 6))
plt.plot(df['Datetime'], df['Traffic_Volume'], label='Observed')
plt.plot(pd.date_range(start=df['Datetime'].iloc[-1], periods=60, freq='D'), forecast, label='Forecast')
plt.fill_between(pd.date_range(start=df['Datetime'].iloc[-1], periods=60, freq='D'), conf_int[:, 0], conf_int[:, 1], color='k', alpha=0.1)
plt.xlabel('Datetime')
plt.ylabel('Traffic Volume')
plt.title('ARIMA Traffic Volume Forecast')
plt.legend()
plt.show()
LSTM模型
LSTM模型是一种常见的深度学习时间序列预测模型。以下是使用LSTM模型进行交通流量预测并绘制预测结果的示例:
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
# 准备数据
data = df['Traffic_Volume'].values
data = data.reshape(-1, 1)
# 标准化数据
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data = scaler.fit_transform(data)
# 创建训练和测试数据集
train_size = int(len(data) * 0.8)
train, test = data[:train_size], data[train_size:]
# 创建数据集函数
def create_dataset(dataset, look_back=1):
X, Y = [], []
for i in range(len(dataset) - look_back - 1):
a = dataset[i:(i + look_back), 0]
X.append(a)
Y.append(dataset[i + look_back, 0])
return np.array(X), np.array(Y)
look_back = 1
X_train, Y_train = create_dataset(train, look_back)
X_test, Y_test = create_dataset(test, look_back)
# 重塑输入数据为LSTM的格式 [样本, 时间步, 特征]
X_train = np.reshape(X_train, (X_train.shape[0], 1, X_train.shape[1]))
X_test = np.reshape(X_test, (X_test.shape[0], 1, X_test.shape[1]))
# 创建LSTM模型
model = Sequential()
model.add(LSTM(50, input_shape=(1, look_back)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
# 训练模型
model.fit(X_train, Y_train, epochs=100, batch_size=1, verbose=2)
# 进行预测
train_predict = model.predict(X_train)
test_predict = model.predict(X_test)
# 反标准化预测结果
train_predict = scaler.inverse_transform(train_predict)
test_predict = scaler.inverse_transform(test_predict)
# 绘制预测结果
plt.figure(figsize=(10, 6))
plt.plot(df['Datetime'], scaler.inverse_transform(data), label='Observed')
plt.plot(df['Datetime'][:train_size], train_predict, label='Train Predict')
plt.plot(df['Datetime'][train_size + look_back + 1:], test_predict, label='Test Predict')
plt.xlabel('Datetime')
plt.ylabel('Traffic Volume')
plt.title('LSTM Traffic Volume Forecast')
plt.legend()
plt.show()
通过上述方法,我们可以利用Python进行城市交通大数据的分析与可视化,从而更好地理解交通流量的变化趋势和模式,为城市交通管理和规划提供数据支持。
结论
通过本研究,我们深入探讨了Python在城市交通大数据分析与可视化中的应用。我们发现,利用Python的各种数据处理和分析工具,如pandas、numpy、scikit-learn,以及可视化工具如Matplotlib、Seaborn和Plotly,可以有效地揭示城市交通模式和规律,为交通管理提供科学的决策支持。例如,通过对台北捷运系统的交通数据进行主成分分析(PCA)和聚类分析(K-Means),我们能够识别不同站点的交通模式,优化交通管理策略。
在交通拥堵特征分析方面,Python的pandas库和matplotlib库帮助我们识别交通拥堵的高发区域和时间段;在交通流关联分析中,通过将交通流量数据与气象数据进行关联分析,我们发现了气象条件对交通流量的显著影响;在智慧交通指标分析中,利用seaborn库绘制的公交客流热力图和区域客流时空动态图,为公交线路和班次安排优化提供了重要依据。
此外,智能地址定位服务和交通指数分析等应用展示了Python在提高用户出行效率和便利性方面的强大功能。通过即席查询功能,用户可以快速获取交通信息,合理安排出行时间和路线。
总体而言,Python在城市交通大数据分析与可视化中的应用,不仅提高了数据处理和分析的效率,还为交通管理和规划提供了强有力的支持。这些技术和方法在未来的智慧城市建设中将发挥越来越重要的作用。
参考资料
[1]
基于Python大数据可视化的城市通勤特征分析研究: https://xueshu.baidu.com/usercenter/paper/show?paperid=1r010r40127u0ef0sy4p0p30x9094411
[2]
上海地铁预测可视化: https://github.com/Aplicity/metro_prediction
[3]
腾讯云: https://cloud.tencent.com/developer/article/2203120
[4]
source: https://towardsdatascience.com/pca-k-means-for-traffic-data-in-python-a0ec66ab4789
[5]
source: https://towardsdatascience.com/pca-k-means-for-traffic-data-in-python-a0ec66ab4789
[6]
source: https://towardsdatascience.com/pca-k-means-for-traffic-data-in-python-a0ec66ab4789
[7]
source: https://dev.to/taipy/7-best-python-visualization-libraries-for-2024-5h9f
[8]
source: https://dev.to/taipy/7-best-python-visualization-libraries-for-2024-5h9f
[9]
source: https://dev.to/taipy/7-best-python-visualization-libraries-for-2024-5h9f
[10]
source: https://towardsdatascience.com/pca-k-means-for-traffic-data-in-python-a0ec66ab4789
[11]
source: https://towardsdatascience.com/pca-k-means-for-traffic-data-in-python-a0ec66ab4789
[12]
source: https://towardsdatascience.com/pca-k-means-for-traffic-data-in-python-a0ec66ab4789
[13]
Prophet: https://facebook.github.io/prophet/
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-05-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号