分布式系统测试:可靠性及可用性测试概述
原创
分布式系统测试:可靠性及可用性测试概述
原创
Janesong
修改于 2024-09-04 12:16:12
修改于 2024-09-04 12:16:12
近些年,一些大厂及其客户都关注系统可靠性,现将分布式系统可靠性测试概述整理如下,期望起到抛砖迎玉作用。也欢迎各位大佬评论区里留言。
在分布式系统中,需要考虑两个指标:可用性和可靠性指标。它往往是衡量系统好坏的两个指标。一般这两个指标也用于系统性能评价中。系统测试/集成测试中,尤其是大型分布式系统需要考虑这两个指标。
理论概述
系统可靠性
系统可靠性是指系统在规定的时间内和规定的工况下,完成规定功能的能力或概率。简单来说,就是系统能够持续、稳定地运行,不因内部故障或外部干扰而中断或失效的能力。
可靠性指标
如何量化系统的可靠性,即如何判定一个大型系统相比于另一个而言更加可靠?为此,业界定义了以下几个主要的可靠性评价指标,用以刻画系统的可靠程度。
Ø MTTF(Mean Time To Failure,平均失效时间),表示某个存储部件预计可正常运行的平均时间。即正常提供服务的时间。
Ø MTTR(Mean Time To Repair,平均修复时间),表示修复一个失效部件所需的平均时间。
Ø MTBF(Mean Time Between Failures,平均失效间隔时间),表示系统部件平均每次失效之间所间隔的时间。换句话说:两次故障间隔时间。一般而言,若MTBF越大,意味着在固定时间窗口下,系统发生失效的次数越少。MTBF可以用小时(MTBF in hours)和年(MTBF in years)来表示。一个系统部件的MTBF可通过以下两种方法计算而得:第一,通过累加MTTF和MTTR的值而得;第二,可将所观测的时间窗口时长除以在该窗口下所发生的失效次数而得。例如,若某个系统部件的MTBF为1年,其物理意义表示该部件平均每一年发生一次失效。
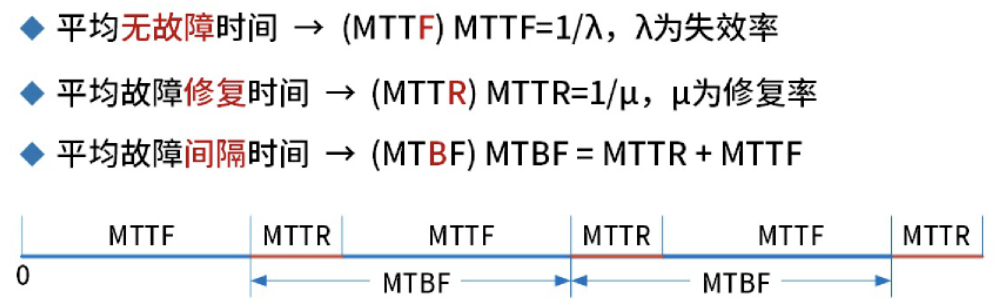
在系统性能评价中通常用平均无故障时间 (MTBF)和 平均故障修复时间 (MTTR)分别表示计算机系统的可靠性和可用性,MTBF大且MTTR小表示系统具有高可靠性和高可用性。
存储系统可靠性指标
在一些大型系统测试可靠性及关注点上,对于存储系统还有下述三个指标:AFR、FIT和PPM,它与上述三个指标一同衡量系统的可靠性。
AFR(Annual Failure Rate,平均年失效率),表示某个系统磁盘平均一年内的失效次数。可以发现,AFR是MTBF的倒数。
AFR:Annualized Failure Rate又称为硬盘年度失败概率,一般用来反映一个设备在全年的使用出故障的概率,可以很直观的理解,AFR越低,系统的可靠性越高,因为AFR与系统的数据可靠性强相关;而这个指标通常又是由另一个磁盘质量指标MTBF(Mean Time Before Failure)推算出来,而MTBF各大硬盘厂商都是有出厂指标的,比如说希捷的硬盘出厂的MTBF指标为120W个小时。以下为AFR的计算公式:
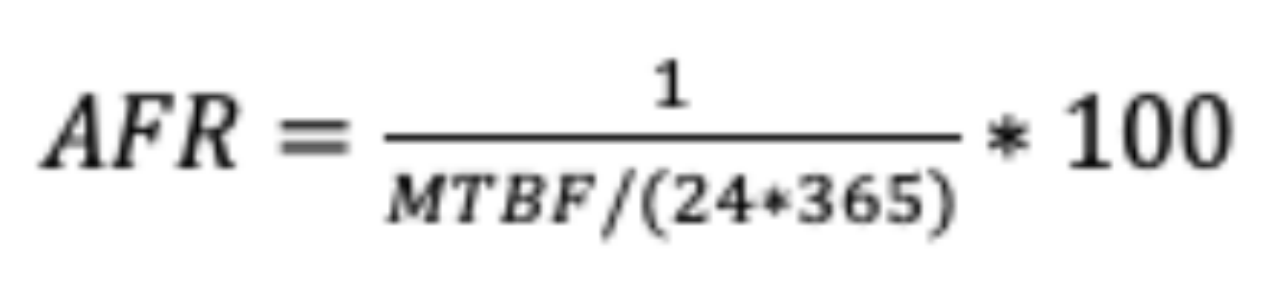
FIT(Failures In Time)
FIT表示在十亿小时的操作中预期的故障次数。FIT值越低,说明产品在长时间运行中的可靠性越高。
FIT指标特别适用于需要高可靠性保证的产品,如航空航天电子或医疗设备。例如,一个电子组件的FIT为5,意味着在十亿小时运行中预期平均有5次故障,适用于对可靠性要求极高的应用。
PPM(Parts Per Million)
PPM,即百万分率,衡量每百万单位产品中可能出现的缺陷产品数量。这是一个关键的生产质量指标,帮助制造商量化生产过程中的缺陷率。
PPM广泛应用于质量控制严格的制造行业,如半导体制造。举例来说,如果一个芯片生产线的PPM为50,这意味着每生产一百万片芯片中有50片可能存在缺陷。
系统可用性
系统可用性是指系统在规定时间内能够正常运行的能力。它是衡量系统稳定性和可靠性的重要指标之一。一个可用性高的系统意味着系统能够以较高的概率在需要时处于可用状态,无论是在硬件故障、软件错误、人为操作错误或其他不可预测的情况下。
系统可用性通常受到系统错误、基础结构问题、恶意攻击和系统负载等多种因素的影响。为了提高系统的可用性,可以采取多种措施,如为系统物理层提供失效备援支持、设计合理的异常处理机制、优化资源使用策略、设计更好的运行时升级策略以及处理不稳定的网络连接等。
可用性指标
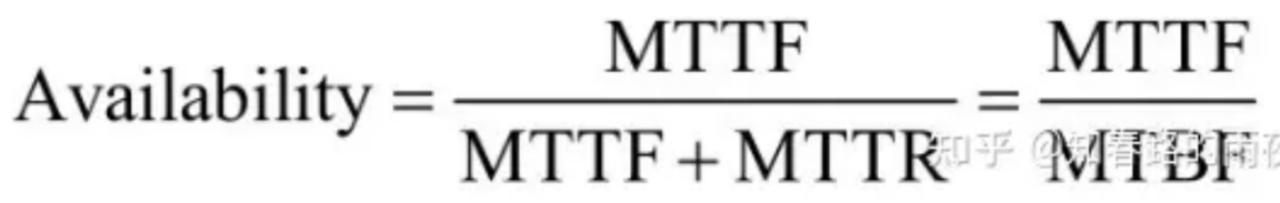
可用性和可靠性指标度量
在实际应用中,一般MTTR很小,所以通常认为MTBF~ MTTF。
>>> 可靠性可以用MTTF/(1+MTTF)来度量。
>>> 可用性可以用MTBF/(1+MTBF)来度量。
>>> 可维护性可以用1/(1+MTTR)来度量。
在实际可靠性指标度量中,我们通常还有个“千小时可靠度”,通常记作R。即系统运行一千小时,可靠概率有多大。与该指标对立的还有个“失效率”。“千小时可靠度”与“失效率”合起来为1.
比如:对于大型分布式系统【每类组件在同一时刻都需要正常运作提供服务,整体才能对外提供正常服务。对于大型分布式系统,每类组件只要对外提供服务就认为组件正常,对于分布式系统组件内/集群内有某个部署实例出问题,但该组件依然能提供对外服务认为组件正常】,运作1000小时后,其中有2个组件先后失效,即有两次故障发生。那么
失效率:2/1000=0.002, 可靠度R:1-2/1000=0.998。
分布式可靠性及可用性测试概述
我们基于上述来设计对应分布式系统的可靠性及可用性测试概述。
对于大型分布式系统而言,一般都是将同一个组件的多副本部署在不同地域的有相同网络区域里,即物理上各节点是分散的,逻辑上通过配置等共同组成一个完整的系统,对外提供服务。
可靠性测试的目的,一般是通过模拟各种故障 或 制造各种突发事项来看系统能否提供正常服务且多久能恢复。
注意:这里模拟的故障,在故障时间点上,只要系统还能提供对外提供服务,故障表现(如:性能下降、请求延迟变大)不一定需要研发Repair,但对于 故障时间点结束,系统还没恢复或恢复后各项指标没有达到预期,那就需要研发同学Repair了。
节点可靠性
节点:就是单个服务器,多个服务器通过网络连接组成集群。
一般对节点可靠性测试,常见的有关机。
注意:一般情况下,会有短时间的性能损耗。此处关机节点停用,主要关注点有:对系统影响度以及恢复用时。
实际操作
步骤:
1、分布式系统部署好,服务端已经接入监控系统,或登录服务端每台机器上通过命令行方式将监控命令启动。【若是后者,需要有个团队认可的汇总数据的方法】
2、在环境里发起大批量的请求持续一段时间;持续时间要做完第5步;注意:请求的地址,最好是对外开放服务地址,即发生节点后,系统能自动将请求转到可用的节点上。
3、在这段时间内,将某个节点关机 shutdown【停用节点】;
4、关注服务端监控指标:性能指标曲线变化:
① 下降后能否恢复。若能恢复,证明系统能将请求切换到正常服务的节点上。同时要关注恢复的用时【这点可以从侧面看出整个系统响应链路上,有效转移请求用时】。
② 若所有请求都不能处理,如:全是TimeOut,或直接Error,而且持续时间很长,那么就表明系统没有将请求转移到有效节点上【可优先查看服务端的log:在请求调度转移、故障节点摘除处】
5、节点开机【启用节点】。这点主要关注:
① “新节点”上的服务能否自动启动,系统能否将请求分流到这个“新节点”,即节点重新正确加入环境并提供服务。
② “新节点”加入后,系统的性能指标能恢复到第一步,一般要求相差无几才行。
注意:这种方式要控制好“大批量请求”的量,一般要能找到问题,且不能压垮系统为主,不是做“疲劳测试”、“瓶颈测试”哟。至于“大批量请求”的请求,一般推荐实际系统上去挑选使用频率高的接口、功能来测试,可以考虑只有写、只有读,也可以读写混合。
在实际操作过程中,可以停一个节点,也可以停多个节点。到底多少个合理,需要看环境里节点数量,也要考虑停多个节点后系统还能运作,即一般停机个数最大不会超过(n+1)/2个节点,这是计算机系统里的大多数原理。而具体停用哪个节点,需要看系统部署情况,以及系统自身特性,也要看本次停机测试点等。
补充:对于分布式系统中的“一致性”,即写请求将数据存储到不同的节点上,一般系统在设计时,就会考虑,比如:多副本冗余存储方式、数据一致性保障设计等。再此不在阐述。
网络可靠性
硬件故障:连接器件、线路故障(损坏、脱落等)==》这点 对于大型存储系统需要考虑,一些持久化的软件诉求,也需要有选择性考虑。
软件故障:网络风暴,IP冲突,网口闪断,交换机配置丢失,网卡故障,时延丢包等
实际操作
与节点可靠性相似,只是将第2步,更换为模拟网络故障。
注意:一定要控制好故障影响范围,也就是大家口里“混沌测试”的半径控制。
一般针对被测某个组件操作,就需要严格控制网络故障范围,要针对某些IP,甚至是这些节点上Port。否则,依赖组件受影响后,会因为依赖组件自身问题而影响被测系统,从而使得测试不够精准,在定位问题时产生不必要的耗时,甚至忽略深层次故障。
对于整套系统/一套完备环境,那网络故障需要确保每个故障都设置到节点上,这里关注点是,整个系统的交互。这种情况比较少。因为一套分布式系统在架构设计时这点是严格经过论证的,而且在各组件部署网络图上也有体现,各组件一般也都会有容错考虑。投入这种,耗时较多,且产出数据理论上早就有了,不会给团队带来更多收益。
系统可靠性
系统可靠性测试主要验证四个指标
Ø 成熟性:指系统避免因错误的发生而导致失效的能力
Ø 容错性:在系统发生故障或违反指定接口的情况下,系统维持规定的性能级别的能力
Ø 易恢复性:系统发生失效情况下,重建规定的性能级别并恢复受直接影响的数据的能力
Ø 依从性:系统依附于可靠性相关的标准、约定和规约的能力。
内存
内存泄漏保护机制(cgroup)、高压下内存泄漏问题、高内存占用率下系统运行稳态
补充:一般是要求程序没有内存泄漏的。如果某种场景下期望结果有内存泄漏,那么我们关注点是内存是否真的泄漏了,这些内存泄漏的影响表现是什么。后者更多的是系统已知问题以及影响。
CPU
高CPU下系统运行稳态。一般期望:CPU涨上去后,能否降下来,CPU降下来后,能否恢复到最初状态等。
各种压测工具
利用各种压测工具,可以将被测系统的各项指标【CPU、Memory、磁盘读写、网卡等等】生成负载。这种就类似“疲劳测试”,主要关注:系统在大量请求【偏于极端】下,系统是什么表现,以及这种表现,团队是否认可接受。
实际操作
这种一般聚焦某个组件在分布式环境里,自身的事项了。一般是考虑系统组件特性,以及某种特殊场景来看系统是否达到预期目标。
下述是两种场景验证【实际中测试过程中不止这两种哈】
流量猛增后恢复验证步骤:
1、分布式系统部署好,服务端已经接入监控系统;
2、在环境里发起一批量的请求持续一段时间;持续时间要做完第5步;
注意:此处的请求,一般是本组件内部容易有内存、CPU问题的功能或接口。比如:Redis的 写大key、Dump命令带来的瞬时CPU高等,即针对本组件的特性来设计的。
3、随着时间推移,CPU和内存使用都涨起来,达到下一个步骤的准入,比如:各节点上CPU已经达到50%,内存占用一半左右;
4、在增加一批请求,与步骤2里的请求共同形成大批量请求;==》一般是考虑系统能抗最大流量来,即“极端测试”
此时关注:CPU、内存都占用系统最大资源量,看系统是否能崩溃
① 服务端假死、客户端请求都是TimeOut或直接Error且不能恢复 ===》看情况,多数情况下不接受。
② 只是有若干个TimeOut或Error,总体响应延迟,但系统么有崩溃,还在提供服务。===》若延迟在期望范围内,就是理想状态,系统可靠。若延迟超出,那就得找团队人员排查问题点。
5、将请求量逐步减少到步骤2里的请求量,或 直接停止请求,此时关注点:
① 系统的CPU、内存能否下降,下降用时多久
流量阶梯增长验证步骤:
1、分布式系统部署好,服务端已经接入监控系统;
2、在环境里发起一批量的请求持续一段时间;注意每隔一段时间,新增发压请求流量。新增流量请求数量一致,实现发压请求阶梯线性增长;
此时关注:系统各节点上CPU、内存是否也有阶梯点的增长,并发量达到多少时,CPU、内存指标曲线进入一个平缓区【该流量可能是系统推荐的当前部署规模下的一个拐点】这里也可以看到,不同流量请求下的系统响应延迟指标。
一般情况下,看到请求里错误开始增多,即停止。该请求量是系统瓶颈的一个请求量。
3、重新发起步骤2,达到系统瓶颈时,开始阶梯下降:
此时关注:系统各节点上CPU、内存是否也有阶梯点的递减。对应的系统响应延迟是否减少。
系统稳定性
在做系统可靠性测试,对于系统稳定性测试是绕不开的。这是最常见的一种测试手段。
在过往,我们一般拿出一套专用环境,去跑这种长时间、常见功能或接口的压测,定期定时查看性能指标。
实际操作
1、分布式系统部署好,服务端已经接入监控系统;
2、在环境里发起一批量的请求持续7*24h或更长时间;
注意:这里一批请求量一般考虑系统能抗住,或请求量达到某个系统阈值,如CPU达到70%、内存占用50%等;请求内容,都是优先考虑系统特性或常用功能及接口。
3、定时查看被压系统的各项指标
关注点:整套系统,在这么久的时间内CPU是否有增长、内存情况。这种能发现系统长时间运作,是否稳定,是最直观最常见的系统可靠性测试方法之一。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号