智能音箱——智能家居入口的黄粱一梦?



原创丨作者:罗超
2022,全球AIoT行业急转直下
近日,脸书母公司Meta宣布裁员1.1万人,约占员工总数的13%。过去一年,这个社交媒体巨头将重心转向元宇宙,其在该领域投入已超过100亿美元。扎克伯格宣称,沉浸式的数字宇宙最终将取代智能手机,成为人们融入科技生活的主要方式。但现实却泼了Meta冷水,其股价今年暴跌超过71%已回到2015年水平。
Meta不是唯一苦于市场低迷的公司。正如CNN分析的那样,Meta的困境与更广泛的经济和技术趋势相关。无独有偶,亚马逊也加入了硅谷裁员潮,本轮大裁员预计裁撤1万个工作岗位,其中Alexa和Luna云游戏两个部门是重灾区,Alexa以及背后的智能音箱业务不再受宠。全球AIoT行业已迎来重大转折。。
国内市场更加惨淡。来自调研机构洛图科技的最新报告显示,2022年三季度中国智能音箱市场销量为575万台,同比下降26.2%;前三季度销量累计为1991万台,不足2000万台,截至目前我国智能音箱市场销量已连续三个季度出现20%以上的大幅度下滑。IDC此前发布的报告也显示,2022年上半年中国智能音箱市场总销量只有1483万台,同比下降27.1%,销售额为42亿元人民币,同比下降16.2%。
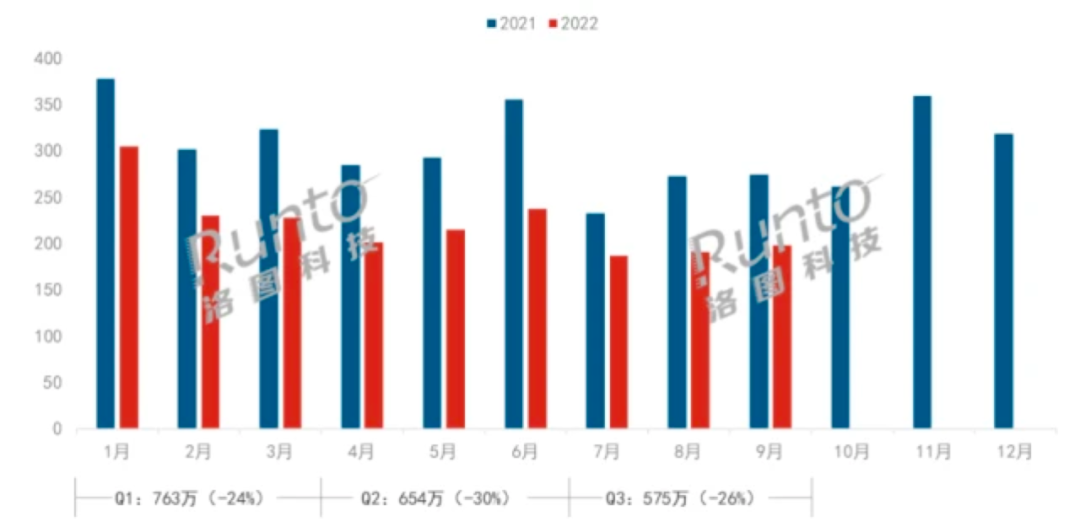
智能音箱行业的玩家也已大幅减少,2019年“百箱大战”的盛景不复存在,依然活跃在市场的玩家只有小米、百度、阿里等少数“不缺钱”的企业,而且这些企业都在“去智能音箱化”,它们很久没有发布严格意义上的“智能音箱”新品了。往年会在双11展开重点营销教育市场、争夺用户的智能音箱行业,今年双11却集体“哑火”,不见价格战,战报也没怎么发。
曾经,智能音箱被视作接棒智能手机、智能电视后的下一代智能硬件,一些人甚至认为智能音箱将成为智能家居的“入口”。从数据来看,智能音箱前些年也确实经历了每年100%以上的爆发式增长。作为昔日科技巨头的宠儿,智能音箱为什么到了2022年急转直下,成了昨日黄花?
智能音箱在中国早就“死”了
2011 年10月,苹果将 Siri 集成到 iPhone 4S 中,智能语音助理由此进入大众视野。2014年亚马逊发布首款智能音箱产品Echo,虽然没有专门的发布会,但这款产品却掀起了新的硬件潮流。
2016年,“互联网女皇”、KPCB合伙人玛丽·米克尔预判:“语音拐点已经到来,在2015年智能手机销量下滑之后,Echo销量或将腾飞。”接下来几年,这一预测变为现实,Echo代表的智能音箱成为美国最热的消费电子新类目之一。

国内市场,2018年百度、阿里与小米掀起轰轰烈烈的智能音箱大战,推动市场高速增长。来自IDC的数据显示,中国市场2018年智能音箱全年出货量突破2000万台,同比增长1051.8%;2019年出货量达到4589万台,同比增长109.7%。2020年疫情等因素让市场增速放缓但依然在高速增长,2020年阿里向天猫精灵AIoT生态投资100亿,天猫精灵销量也突破了千万大关。
2021年智能音箱行业遇到瓶颈,但没有出现明显下滑;2022年,智能音箱市场急转直下。智能音箱卖不动的关键原因是什么?
智能家居头部品牌欧瑞博创始人兼CEO王雄辉曾有一个大胆断言:“在中国智能音箱是一个伪命题。”他认为,Echo在美国卖得好是因为美国消费者本就有购买桌面音箱的需求,比如Party、聚餐、跳舞等场景需要音乐氛围。在智能音箱普及前美国的传统音箱市场规模本就可观,JBL、Bose、哈曼卡顿、Sonos等等人们耳熟能详的音箱大牌均源自美国,人们购买智能音箱是因为人们需要音箱。然而中国却没有桌面音箱这样的市场基础,只有大学生等少数群体受限居住环境会购买音箱用来娱乐。
既然如此为什么前些年智能音箱卖得还不错呢?显而易见智能音箱一度被视作“智能家居入口”,互联网巨头想要抢占入口纷纷加码布局,亏本卖音箱以硬件获得用户,这让整个市场非理性增长,说得更直接点是虚假的繁荣。就像社区团购等等TO VC行业一样,商业模式难以成立的生意之所以能持续运转,是因为有资本输血抢占流量。不过一旦资本态度发生变化,市场就会难以为继,伪需求也就会露出真实面目。
来自洛图科技的报告显示2021年上半年市面上智能音箱只剩9个品牌,进一步向头部市场集中。2022年,百度、阿里以及小米等头部科技巨头遭遇了前所未有的环境逆风,疫情、股价、监管诸多原因让它们不得不收缩战线,智能音箱得到的预算大福减少,这对整个行业来说无异于釜底抽薪。
当资本不再“拱火”时,智能音箱就很难持续大热。这几年还有少数智能音箱玩家在努力,但它们主打的产品严格意义上其实都已经不能算是音箱了。2018年,小度在国内率先推出了带屏智能音箱小度在家;2020年起智能音箱市场出现了分野:带屏智能音箱加速增长,而“古典智能音箱”也就是不带屏的智能音箱则增长乏力。最近小米和小度相继发布的新品“小米智能家庭屏6”、“添添全智能家庭平板”也已从“智能音箱”彻底迭代为“智能屏”形态。

(智能中控屏场景示意图,来源:欧瑞博官网)
智能中控屏或是家居入口“真龙”
IDC《中国智能家居设备市场2022年第二季度跟踪报告》显示,2022年上半年中国智能家居中控屏市场出货量为30万台,同比增长160.7%,预计2022年智能家居中控屏市场出货量将突破65万台,同比增长106.4%,未来五年市场出货量年复合增长率将超过60%。
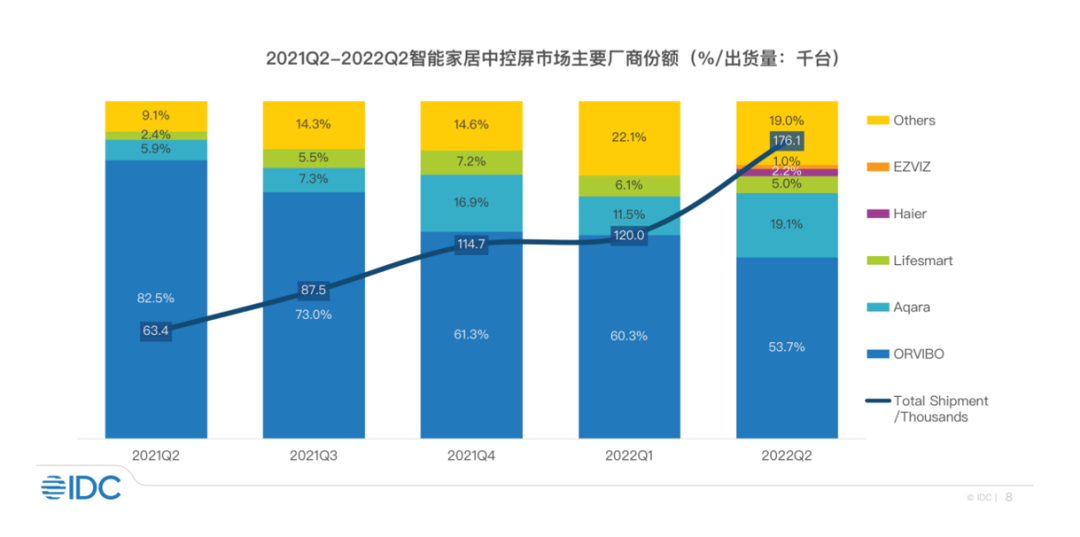
智能中控屏增长强劲,玩家蜂拥而至。除2018年就已推出MixPad系列产品主攻智能家居中控屏赛道的欧瑞博外,华为、小米等巨头也在加码,一些做智能音箱的玩家也转到了这一赛道,当年智能音箱市场出现过的“百箱大战”眼看就要在智能中控屏市场复现。
IDC报告显示,从2021年Q1到2022年Q2,欧瑞博“凭借先发优势和丰富的产品选择”稳居智能家居中控屏市场第一,跻身智能家居行业头部玩家,值得关注。不过随着更多玩家特别是华为等科技巨头意识到中控屏的价值并加码投入,虎视眈眈欧瑞博的市场份额,如何守住领先位置是其不得不面对的问题。
为什么现在智能中控屏又被业界视作家居入口“真龙”?欧瑞博王雄辉早前接受媒体采访时曾表示,欧瑞博认为智能家居的交互一定会由专门的中控屏来做,语音只是人机交互的一种,却不是全部,智能音箱、电视什么都想做,不可能都做好,欧瑞博从开关这一个最基础的点去打,最终形成了MixPad这一独特的“智能家居中控屏”的产品形态,“用屏幕将交互做了折叠”,可以连接控制更多智能家居产品,用户体验足够简单。过去人们靠开关、遥控器这样的设备去做这些事情,如今智能中控屏可以取代家里杂乱且多的传统开关,智能中控屏十分自然地“从墙上长出来”,符合人与家的交互习惯。退一万步来说,它首先是更好用、更好看、更智能的开关。
公开资料显示,欧瑞博自2018年首款MixPad面世以来4年时间已连续发布9款智能家居中控屏产品,进行了多次产品升级。MixPad在一体化墙面智能开关的基础上集成多协议智能家居网关、多模态智能交互助理、场景化智能服务等能力,搭载自主研发的原生全屋智能操作系统 HomeAI OS,成为了强大的全屋智能交互入口。欧瑞博多次获得包括iF金奖(iF GOLD AWARD)在内的全球知名产品与技术奖项,在全屋智能领域申请超过600项专利、350项发明专利,入选“专精特新”高新技术企业,被称为“智能家居小巨人”。

(欧瑞博智能中控屏MixPad系列)
随着越来越多家居设备智能化,智能家居的人机交互一定是多场景、碎片化的,人们会采用最方便的交互设备和形式,因此智能中控屏成为入口之路也会是场持久战。不过智能中控屏其本质是分布式的智能开关,用户会更高频地使用,在家居场景将扮演类似于微信在手机上的“超级入口”角色。
至于是用语音交互还是其他方式交互最终还是用户决定。用户需要的是符合习惯的自然交互,语音有些场景下是很方便,比如如果你晚上起床还用语音去唤醒灯肯定会被老婆骂,再比如你都下楼了再喊语音助理关窗帘就不符合使用习惯了。因此,智能家居中控屏一直在做的是多模态AI交互:语音、触屏、按键、App、传感等等。
智能音箱也好、智能中控屏也罢,最终谁能成为智能家居入口还需市场进一步验证。不过数据会说话,具备“开关”这一确定性的高频需求,同时兼备多模态AI交互方式,智能中控屏的价值正浮出水面,真正满足用户需求,解决用户使用痛点让这一品类在过去高速增长,大有成为下一代家居入口“真龙”的势头。
你方唱罢我登场,群雄逐鹿又一轮。新的智能家居入口之战,欧瑞博们谁将笑到最后?让我们拭目以待。
END
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-11-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号