Muti-Similarity Loss:考虑了batch中整体距离分布的对比损失函数
Muti-Similarity Loss:考虑了batch中整体距离分布的对比损失函数

作者:Keshav G 编译:ronghuaiyang
导读
这是对比损失函数的一种变体,不再是使用绝对距离,还要考虑batch中其他样本对的整体距离分布来对损失进行加权,大家可以试试。

度量学习的目的是学习一个嵌入空间,在这个空间中,相似样本的嵌入向量被拉近,而不同样本的嵌入向量被推远。Multi Similarity Loss提出了一种直观的更好的方法来实现这一目标,并在公共基准数据集上得到了验证。本文的主要贡献有两个方面:a)在混合算法中引入多重相似性,b)困难样本对挖掘。
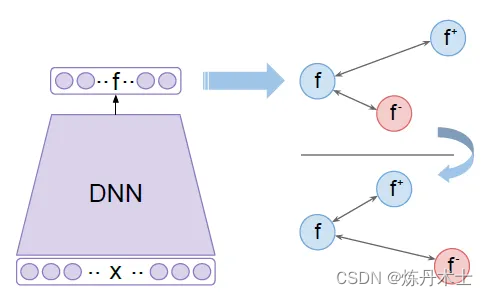
多重相似度损失
这种损失涉及携带配对信息的三种类型的相似性。
1. 自相似度:

x1 = anchor, x2 = positive, x3,x4 = negatives
自相似性确保属于正类的实例距离anchor的距离比属于负类的实例距离锚的距离更近。

Sᵢₖ= 样本对的余弦相似度,λ = 相似度margin, α,β = 超参数
MS-Loss包括两个部分:
i) 正样本部分

x1 = Anchor, x2,x3 = positives, λ = margin
这部分只讨论正样本对。λ表示相似度的margin,控制了正样本对的紧密程度,对那些相似度<λ的正样本对进行惩罚。在上面的图中我们可以看到两个样本对(x1, x2)和(x1,x3),正样本对(x1, x2)的损失很低,因为,由于超参数α总是大于零,这一项的值相比(x1,x3)是非常小的。对于(x1,x3)这一对的损失为αα。
ii) 负样本部分:

x1 = anchor, x2,x3 = negatives, λ = margin
这部分只处理负样本对,这部分损失确保负样本与anchor的相似性尽可能低。这意味着靠近x1的负样本(即具有高相似性)应该比远离x1的负样本(即具有较低的相似性)受到更大的惩罚。这从损失中是很明显的,损失(x1, x2)为,而损失x1-x3为。
2. 负样本相对相似度

在MS损失中分配给负样本对的权值,这是由MS损失对单个样本对的导数推导出来的。
样本对权重wᵢⱼ被定义为这个样本对的损失相对于总损失的贡献。

MS-loss只考虑了一个负样本对x1-x2,不仅根据x1-x2之间的自相似度,而且根据其相对相似度,即批处理中存在的所有其他对x1的负样本来分配权重。在上面的式子中, Sᵢⱼ指(x1, x2)的自相似度,Sᵢₖ指x1-x3,x1-x4, x1-x5, x1-x6 x1-x7之间的相似度。
在上图中虽然x1-x2在所有的case中具有相同的Sᵢⱼ,但是其权重wᵢⱼ在不同的case中是不一样的。相同相似年代ᵢⱼ在所有情况下,wᵢⱼ因情况而异。
- Case 1: 所有其他的负样本相对于x2都距离x1更远。
- Case 2: 所有的其他负样本相对于x1的距离和x2一样。
- Case 3: 所有其他的负样本相对于x1的距离比x2更近。
在三个case中,wᵢⱼ的区别是分母项βᵢₖᵢⱼ,其中Sᵢₖ= x1-x3,x1-x4, x1-x5 x1-x6 x1-x7之间的余弦相似度,Sᵢⱼ=x-x2之间的余弦相似度。
- Case 1: wᵢⱼ最大,因为βᵢₖᵢⱼ最小,Sᵢₖ<Sᵢⱼ使得指数是个负数。
- Case 2: wᵢⱼ中等,因为βᵢₖᵢⱼ中,指数是0。is in middle, since in denominator term Σ[e^(β(Sᵢₖ- Sᵢⱼ))], Sᵢₖ≃ Sᵢⱼ making it e^(zero-ish term).
- Case 3: wᵢⱼ最小,因为βᵢₖᵢⱼ最大,Sᵢₖ>Sᵢⱼ,使得指数是整数。
3. 正样本相对相似度

在MS损失中分配给正样本对的权重,这是由MS损失相对于单个正样本对的导数推导出来的。

负样本相似度表示单个负样本对与batch中所有其他负样本对的关系。类似地,正样本相对相似度定义了batch中单个正样本对(x1-x2)与所有其它所有正样本对(x1-x3、x1-x4、x1-x5、x1-x6)之间的关系。按照我们在负样本相对相似度下所做的步骤,我们可以很容易地验证上图所示的结果。
困难正负样本的挖掘
多重相似度损失论文的作者在训练中只使用了困难的负样本和正样本,并丢弃了所有其他的样本对,因为它们对效果的提升几乎没有贡献,有时也降低了性能。只选择那些携带最多信息的对也会使算法的计算速度更快。

A = anchor, P = positives, N = negatives
i) 困难负样本挖掘

上面的式子表明只有那些与anchor点相似度大于正样本点最小相似度的负样本才应该包含在训练中。因此,在上面的图表中,我们所选择的是红色的负样本,因为它们都在与anchor的相似性最小的正样本的内部,其余的负样本都被丢弃。
ii) 困难正样本挖掘

上面的式子表明,只有那些与anchor点相似度小于具有最大相似度(最接近anchor点)的负样本点的正样本点才应该被包括在训练中。困难的正样本被涂成蓝色,其余的则被丢弃。
代码理解
class MultiSimilarityLoss(nn.Module):
def __init__(self, cfg):
super(MultiSimilarityLoss, self).__init__()
self.thresh = 0.5
self.margin = 0.1
self.scale_pos = cfg.LOSSES.MULTI_SIMILARITY_LOSS.SCALE_POS
self.scale_neg = cfg.LOSSES.MULTI_SIMILARITY_LOSS.SCALE_NEG
def forward(self, feats, labels):
# feats = features extracted from backbone model for images
# labels = ground truth classes corresponding to images
batch_size = feats.size(0)
sim_mat = torch.matmul(feats, torch.t(feats))
# since feats are l2 normalized vectors, taking
its dot product with transpose of itself will yield a similarity matrix whose i,j (row and column) will correspond to similarity between i'th embedding and j'th embedding of the batch, dim of sim mat = batch_size * batch_size. zeroth row of this matrix correspond to similarity between zeroth embedding of the batch with all other embeddings in the batch.
epsilon = 1e-5
loss = list()
for i in range(batch_size):
# i'th embedding is the anchor
pos_pair_ = sim_mat[i][labels == labels[i]]
# get all positive pair simply by matching ground truth labels of those embedding which share the same label with anchor
pos_pair_ = pos_pair_[pos_pair_ < 1 - epsilon]
# remove the pair which calculates similarity of anchor with itself i.e the pair with similarity one.
neg_pair_ = sim_mat[i][labels != labels[i]]
# get all negative embeddings which doesn't share the same ground truth label with the anchor
neg_pair = neg_pair_[neg_pair_ + self.margin > min(pos_pair_)]
# mine hard negatives using the method described in the blog, a margin of 0.1 is added to the neg pair similarity to fetch negatives which are just lying on the brink of boundary for hard negative which would have been missed if this term was not present.
pos_pair = pos_pair_[pos_pair_ - self.margin < max(neg_pair_)]
# mine hard positives using the method described in the blog with a margin of 0.1.
if len(neg_pair) < 1 or len(pos_pair) < 1:
continue
# continue calculating the loss only if both hard pos and hard neg are present.
# weighting step
pos_loss = 1.0 / self.scale_pos * torch.log(
1 + torch.sum(torch.exp(-self.scale_pos * (pos_pair - self.thresh))))
neg_loss = 1.0 / self.scale_neg * torch.log(
1 + torch.sum(torch.exp(self.scale_neg * (neg_pair - self.thresh))))
# losses as described in the equation
loss.append(pos_loss + neg_loss)
if len(loss) == 0:
return torch.zeros([], requires_grad=True)
loss = sum(loss) / batch_size
return loss
论文 : http://openaccess.thecvf.com/content_CVPR_2019/papers/Wang_Multi-Similarity_Loss_With_General_Pair_Weighting_for_Deep_Metric_Learning_CVPR_2019_paper.pdf
代码: https://github.com/MalongTech/research-ms-loss/blob/master/ret_benchmark/losses/multi_similarity_loss.py
后台回复“MSLoss”获取打包好的论文和代码

—END—
英文原文:https://medium.com/@kshavgupta47/multi-similarity-loss-for-deep-metric-learning-ad194691e2d3















腾讯云开发者
