Keras中损失函数的意义?
我用python中的keras建立了一个神经网络,无法真正理解损失函数的含义。
这里首先介绍一些一般信息:我使用了类为0-9的扑克手数据集,这是我用OneHotEncoding编写的向量。我在最后一层使用了softmax激活,所以我的输出告诉我,如果样本属于某个类,向量中的10个条目中的每个条目的概率。例如:我的实际输入(0,1,0,0,0,0,0,0,0,0,0),这意味着第1类(从0-9表示从没有牌到皇家同花顺),第1类意味着一对(如果你知道扑克)。利用神经网络,它得到了像(0.4,0.2,0.1,0.1,0.2,0, 0,0,0,0)这样的输出,这意味着我的样本属于0类,20 %属于1类,等等!
好了!我还使用二进制cross_entropy作为损失,准确性度量和.当我从keras中使用mode.evaluate()时,我得到了类似于0.16的损失,我不知道如何解释这一点。这是否意味着,平均而言,我的预测偏离了真实的0.16?所以如果我对0级的预测是0.5,也可以是0.66或0.34?或者我怎么解释它?
请派人来帮忙!
回答 1
Stack Overflow用户
发布于 2020-05-04 02:08:38
首先,根据您的问题定义,您有一个多类问题。因此,您应该使用categorical_crossentropy。二进制cross_entropy适用于两类问题或多标签分类.
但一般情况下,损失函数的值具有相对的影响值。首先,您必须理解cross_entropy的含义。公式是:
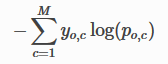
其中c是观测的正确分类
Y是二进制指示符(0或1),如果类标号c是观测值o的正确分类,那么p是c类的预测概率。
对于二进制交叉熵,M等于2。对于范畴交叉熵,M>2。因此,当预测的概率收敛到实际标号时,交叉熵就会减小:

现在让我们以您的示例为例,其中您有10个类,实际输入是:(0,1,0,0,0,0,0,0,0,0,0,0,0)。如果你损失了0.16,就意味着
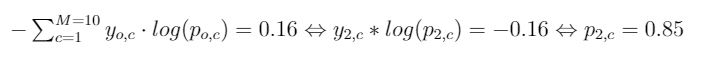
这意味着您的模型已将0.85分配给正确的标签。
因此,损失函数给出正确分类概率的日志。在角点中,损失是按整批计算的,它是整个数据在特定批次中正确分类概率的日志的平均值。如果您使用evaluate函数,那么您正在评估的整个数据的正确分类概率的日志平均值。
https://stackoverflow.com/questions/61589138
复制










相似问题
在画布上打印div
在div上覆盖画布
在画布上绘画并自动删除它(HTML5)
在画布上绘图,添加贴纸,定制位图- Android
联合所有并维护活动记录关系?
腾讯云开发者
