数据库CPU 100% ??


Hello 我是方才,10人研发leader、4年团队管理&架构经验。
专注于分享成体系的编程知识、职场经验、个人成长历程等!
文末,方才送你一份优质的技术资料,记得领取哟!
今天方才给大家分享一个生产故障:2w条库表的全表扫导致数据库节点cpu使用率100%,最终导致系统故障的问题(什么?2w条就吃满了?不可能,绝对不可能!然而. . .)。
造成故障的原因很低级,但从这故障,你至少可以学到到3点:
- 生产级故障的定位和处理流程;
- 对于持续增长的表,一定要在设计阶段创建好索引;
- 要学会通过数值计算去正确分析问题, 而不是纯靠推测;
故障详情
某日上午,监控机器人突然告警:数据库节点CPU占比90%,然后客服务群反馈系统会时不时自动切换为运维页面(内部服务错误导致)。
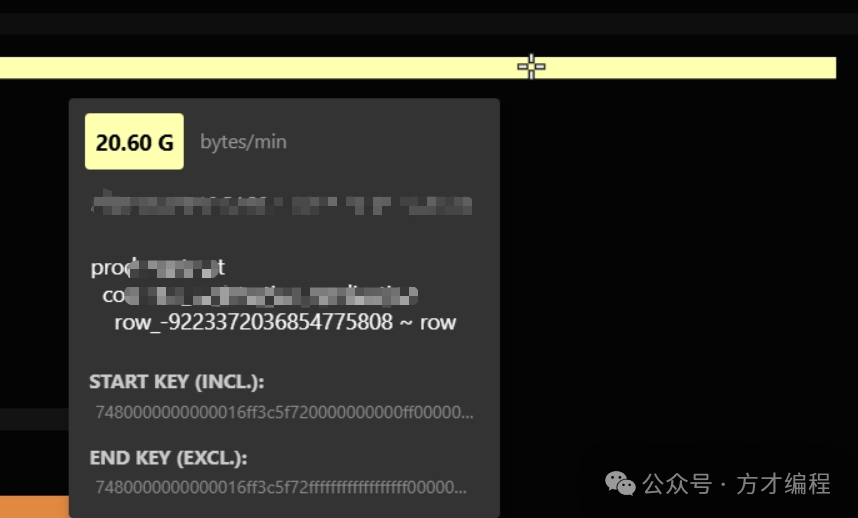
通过问题定位和分析,最终故障为:2w条数据库表的全表扫描,仅仅是该表的查询就导致数据库磁盘读取量持续在 20G/min,从而导致节点磁盘读取、网络带宽激增,最终导致 数据库01节点cpu吃满,数据库服务卡死,系统崩溃。
分析过程
通过监控,逐步确认问题点:
- 数据库指标情况 QPS只有500左右,999延迟指标在10s左右;
- 数据库服务器资源情况:节点01的cpu 使用率接近 100%,其中user进程 90%以上,说明是数据库自身的问题,并非基础设施故障;(PS:因为方才也遇到是因为底层基础设施导致虚拟机CPU,被system进程吃满的情况,大家如果有兴趣,可以在评论区告诉方才,后续给安排上)
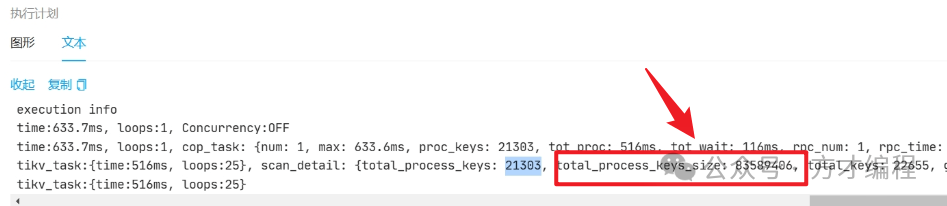
- 通过tidb自带的面板-流量可视化,发现有异常的高亮磁盘读取,最高达 20G/min ,结合慢sql日志,发现某个sql存在全表扫,单次查询扫描的key大小为 80M,只要每分钟查询250次左右,就会达到这个读取量。
- ps:为什么全表扫会导致CPU飙升?核心原因在于大规模数据处理带来的计算、I/O和网络资源消耗。
一些重点监控记录:
- 节点CPU情况
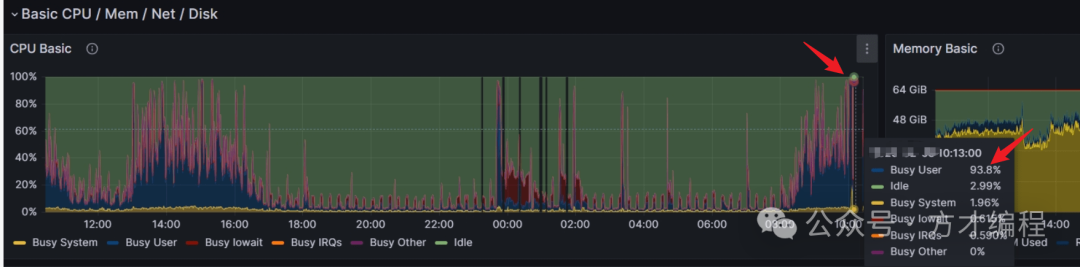
image-20250402143015296
- 节点网络带宽情况
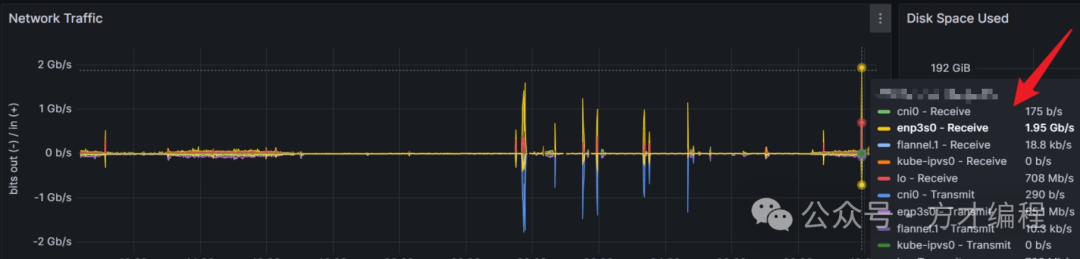
- 数据库磁盘读取监控
- 全表扫 2.1万的数据,单个sql 扫描的磁盘大小 83MB:

解决方案
通过上面的描述,是不是感觉解决过程挺顺利的、挺简单的??
然而现实是,这个问题从发现到彻底解决问题,大概用时1小时!!!
为什么这么久?因为部署实施方案不合理,虽然用到了分布式数据库,但因为服务器资源有限,TiDB节点和Tikv节点、PD节点在同一个虚拟机中,监控面板TiDB Dashboard 也在上面,这导致两个非常严重的问题:
- 全表扫时,TiDB、TiKV进程,压力均为剧增,服务器资源很快达到瓶颈;
- 数据库监控可视化面板也一起崩溃,导致只能推测是因为sql的问题导致的问题,但无法知晓是什么sql,两眼一抹黑;
最后通过关停系统,恢复数据库监控,处理问题sql,才恢复了系统。
解决方案很简单,就是根据查询和更新场景的条件,创建合适的索引。
最后,方才想说的是,后端程序员,一定要把创建索引这件事刻在骨子里!
ps:有伙伴问,这个事情最后谁背锅?背锅?什么锅?服务器性能太辣鸡了而已~ ~ ~
ps:方才很想把文章写得更加有趣,奈何能力有限,有兴趣的可以看看AI故事版,哈哈
AI故事版本
"警报!数据库CPU 100%!"上午十点十七分,当老王正喝着第三杯咖啡时,钉钉机器人突然在运维群里炸出一串血红色的告警。监控大屏上,代表数据库01节点的火焰图标正在疯狂跳动。
客服主管张姐的语音紧随其后:"所有客户页面都在跳运维提示!"技术部空气骤然凝固,键盘声此起彼伏。我盯着TiDB监控面板上诡异的折线——QPS明明只有500,999延迟却像坐火箭般窜到10秒,这就像看到高速公路车流正常,但每辆车都堵了十公里。
"见鬼,user进程吃掉90%CPU!"运维组长大刘的咆哮回荡在办公区。经验告诉我,这种时候要像法医解剖尸体般精准——快速调出流量可视化面板,果然发现有个"黑洞"在疯狂吞噬资源:某张2.1万行的表正以20G/分钟的恐怖速度读取磁盘,相当于每分钟搬空整个《魔兽世界》客户端。
"查慢SQL日志!"我声音有些发抖。当看到那个没有索引的全表扫描查询时,后背瞬间渗出冷汗——单次扫描83MB数据,每分钟执行250次就是20GB流量。这就像用消防水龙头给花盆浇水,服务器不崩才怪。
但现实远比想象魔幻:当我们试图打开TiDB Dashboard找具体SQL时,监控面板居然先于系统崩溃了!原来为了省资源,TiDB、TiKV、PD三大组件竟挤在同一台虚拟机里。"这架构简直是俄罗斯轮盘赌!"大刘气得摔了马克杯。
生死时速持续了58分钟。最终我们只能壮士断腕——紧急关停服务,在监控恢复瞬间抓出罪魁祸首:某个新上线的查询功能,开发时测试数据量小没暴露问题,上线后直接触发全表扫描风暴。
"加索引!给where条件所有字段加联合索引!"当手指重重敲下回车,监控大屏的红色警报像退潮般消散。张姐在群里发了个跪谢的表情包:"页面正常了!"
复盘会上,CTO指着事故报告的手在颤抖:"知道吗?这次全表扫描产生的数据流量,相当于每分钟传输20部高清电影。没有索引的查询,就像让数据库在沙漠里找一粒特定的沙子。"
窗外暮色渐沉,我在事故报告末尾敲下三个血泪教训:
- 索引设计要像写遗嘱般严谨——每个字段都要考虑查询场景
- 监控系统必须独立部署,绝不能和数据库同居
- 性能评估要像做数学题——用磁盘读取量(行数×行大小)预判风险
当有人问起谁该背锅时,运维新人小声嘀咕:"要不说是服务器太菜?"整个会议室突然爆发出劫后余生的笑声。但在深夜的办公室里,我默默给所有核心表补上了索引——有些学费,交一次就够疼一辈子了。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-04-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号