图解分布式存储技术


Hello 我是方才,10人研发leader、4年团队管理&架构经验。 文末,方才送你一份25年最新的架构师备考资料,记得领取哟!
一般大型的分布式微服务项目,都会涉及海量数据、高并发读写等场景,就需要用到分布式数据存储。
常见的包括MySQL集群、分布式数据库、搜索引擎、分布式对象存储、分布式缓存系统等。
分布式缓存系统后续方才会单独讲解,今天我们先了解其他几个分布式数据存储架构。
MySQL的使用
在分布式场景下,单机版MySQL是无法满足海量数据的存储和高并发读写的,这个时候就会进阶到MySQL集群架构。
常用的架构方案有:主从架构(包括一主多从和多主多从)、读写分离架构、分库分表等。
主从复制与读写分离的核心思路:
- 原理:主库通过二进制日志(binlog)异步/半同步复制数据到从库,实现数据冗余。读写分离将写操作定向至主库,读操作分发到多个从库。
- 优点:提升读性能、增强数据可靠性、故障时可切换从库。
- 挑战:主从延迟可能导致数据不一致,需业务容忍或通过半同步复制缓解。
- 场景:读多写少的业务(如电商商品页、新闻网站)。
主从复制
MySQL 支持异步复制、同步复制、半同步复制。
- 异步复制:主库不需要等待从库的响应(性能较高,数据一致性低)。
- 同步复制:主库同步等待所有从库确认收到数据(性能差,数据一致性高)。
- 半同步复制:主库等待至少一个从库确认收到数据(性能折中,数据一致性较高)。
MySQL 默认是异步复制,具体流程如下:
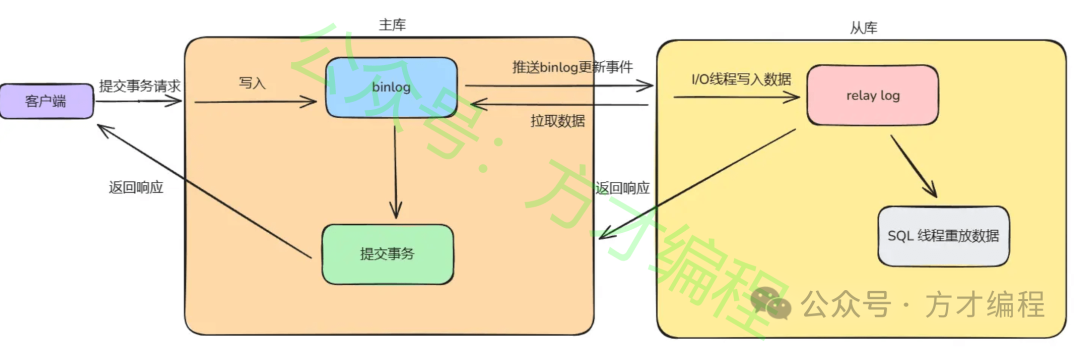
主从复制流程
主库:
- 接受到提交事务请求
- 更新数据
- 将数据写到binlog中
- 给客户端响应
- 推送binlog更新事件到从库中
从库:
- 主动拉取数据,由 I/O 线程将 binlog 写入到 relay log 中。
- 由 SQL 线程从 relay log 重放事件,更新数据
- 给主库返回响应。
读写分离
注意:读写分离架构适用的场景是读多写少的场景,比如常见的信息网站:B站、微博等都是读多写少。
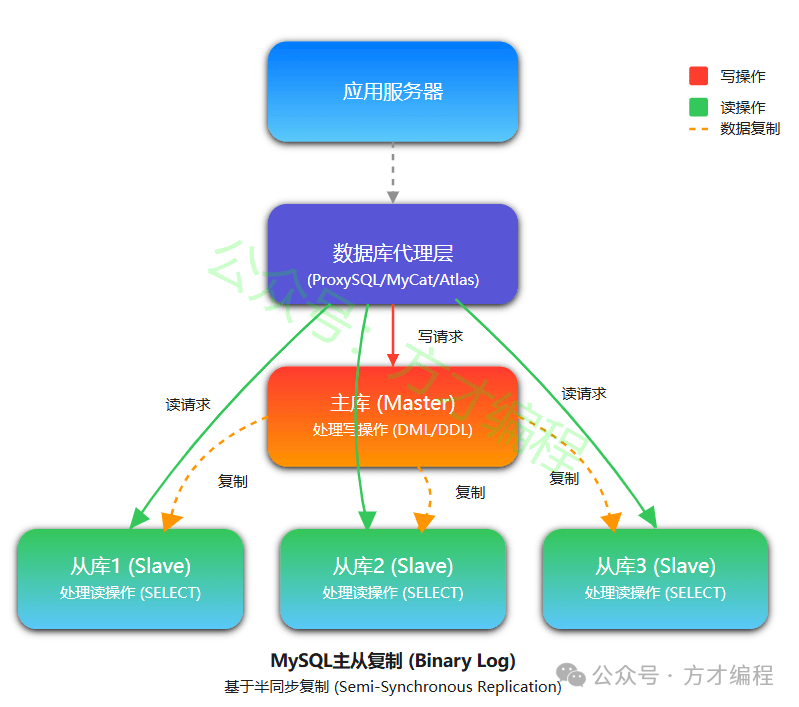
读写分离架构
读写分离架构
分库分表
当单表数据量超过3000万行时,B+树深度达到4层,查询需要4次磁盘I/O,这个时候,我们的单表查询延迟可能就比较高了,同时主从同步的延迟指标也会上升,此时就需要分库分表,降低单表的数据量,从而保证查询性能。
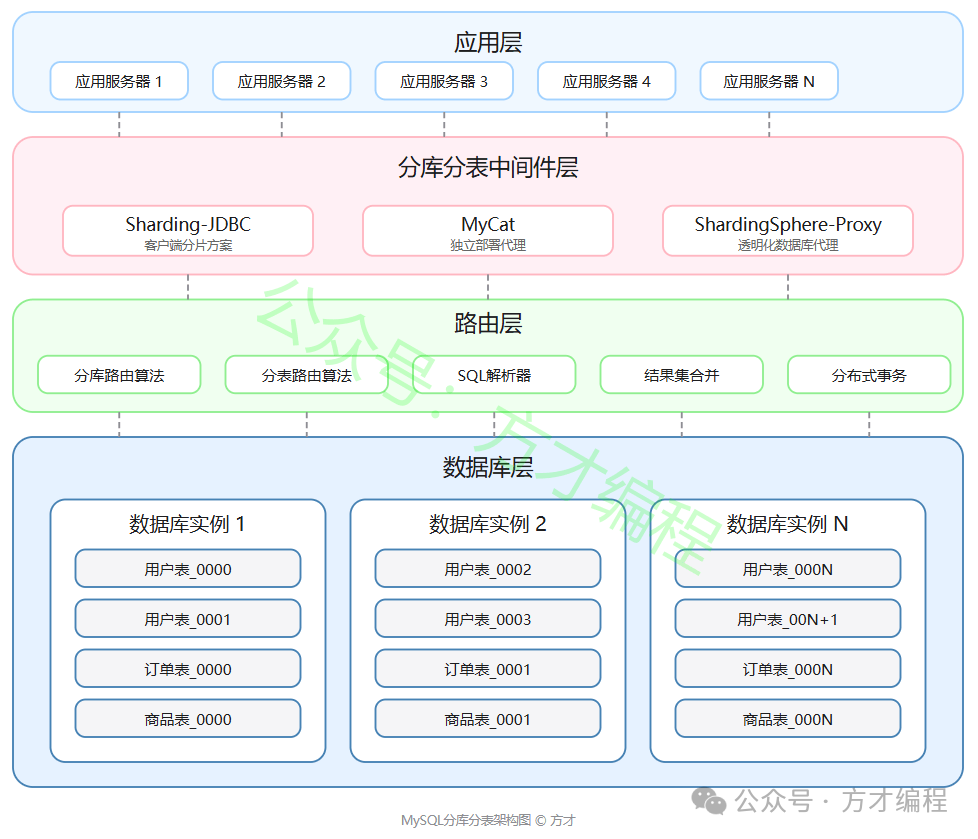
分库分表架构图
分库分表架构图
- 挑战:跨库JOIN困难、分布式事务复杂(需使用XA、Saga等方案)。
- 场景:单表数据超千万级(如大型金融交易系统、社交平台用户表)。
TiDB(分布式数据库)
通过上面的内容,我相信大家能感受到使用MySQL集群去应对分布式存储的场景,技术复杂度和实施成本是极高的。
所以分布式数据库应运而生,这里方才介绍下我自己用过的-TiDB。
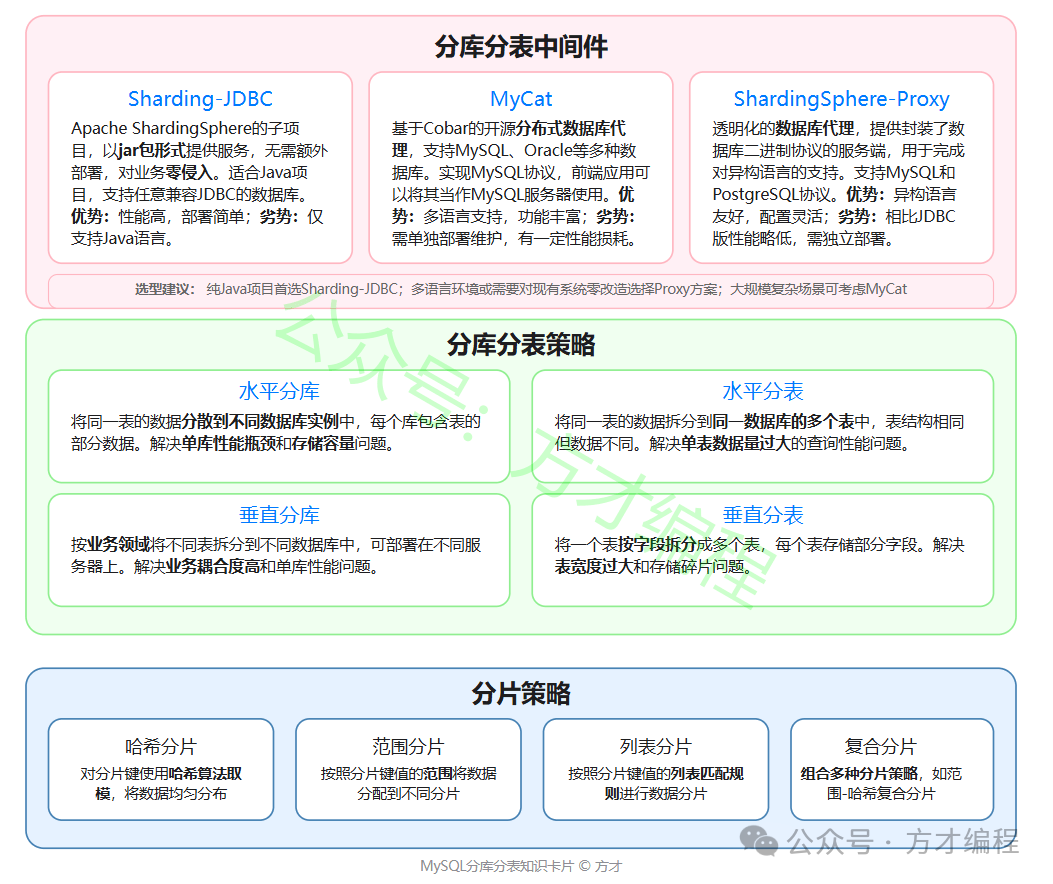
- 架构:
- TiKV:分布式键值存储引擎,基于Raft协议保证强一致性。
- PD(Placement Driver):全局调度中心,管理数据分布与负载均衡。
- TiDB Server:无状态SQL层,兼容MySQL协议。
- 特性:HTAP(混合事务与分析处理)、水平扩展、自动分片(Region)。
- 场景:高并发OLTP(如支付系统)结合实时OLAP(如报表分析)。
分布式数据库帮我们解决了主从复制、数据分片、组件运维复杂度等等问题,对应用方来说,不用再担心底层问题,可以专注于业务逻辑本身。
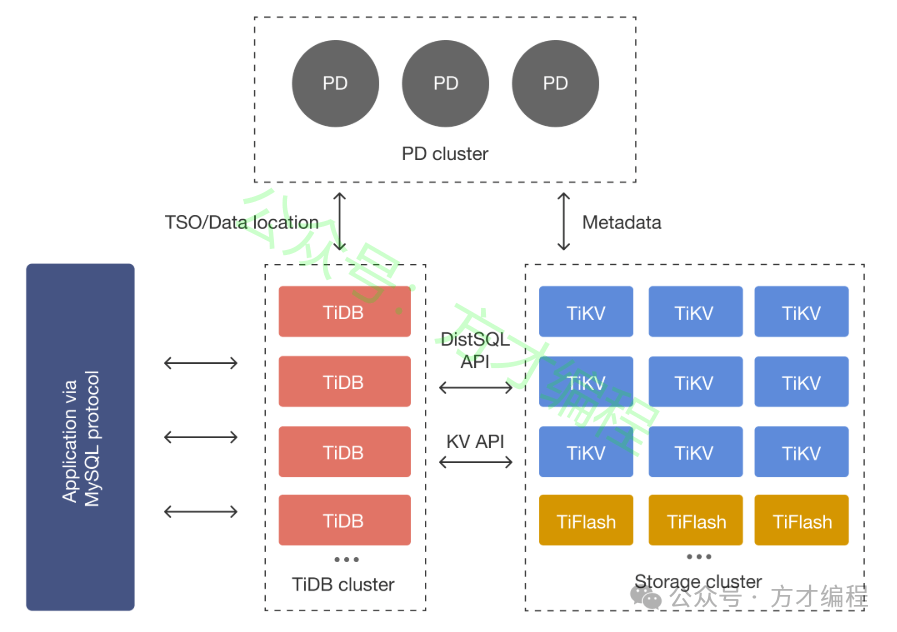
TiDB架构图
TiDB架构图
TiDB vs MySQL 架构方案对比表
对比维度 | TiDB(分布式架构) | MySQL(主从/读写分离) | MySQL(分库分表) |
|---|---|---|---|
数据分片方式 | 自动水平分片,基于 Region 动态分裂(无需人工干预) | 无原生分片能力,依赖主从复制同步数据 | 需手动分片(如按用户 ID 哈希),需中间件(如 Sharding-JDBC) |
扩展性 | 弹性水平扩展(计算与存储分离,按需扩容节点) | 垂直扩展(硬件升级)或有限水平扩展(增加从库) | 需停机扩容,数据迁移复杂(如从 16 分片扩至 32 分片) |
事务一致性 | 分布式 ACID 事务(基于 Percolator 模型,跨节点强一致) | 主从异步复制(可能数据延迟),单机事务强一致 | 单分片内事务一致,跨分片需应用层控制(如 Saga 模式) |
负载均衡 | PD 组件自动调度(数据分布均衡,热点自动迁移) | 需手动配置读写分离(如 ProxySQL),主库压力集中 | 中间件路由(如 MyCat),需人工监控热点 |
高可用性 | 基于 Raft 多副本自动故障转移(RPO=0,RTO<30s) | 主从切换依赖 MHA 或 MGR(人工介入或半自动恢复) | 分片独立高可用(需为每个分片配置主从) |
复杂查询能力 | 支持跨节点 Join 和聚合(优化器自动路由) | 单库复杂查询性能受限(如大表 Join) | 跨分片查询需合并结果(性能差,如分页查询) |
HTAP 支持 | 原生 HTAP(行存 TiKV + 列存 TiFlash,实时分析) | 仅 OLTP(需 ETL 同步至分析型数据库) | 仅 OLTP(分片后 OLAP 更复杂) |
运维复杂度 | 自动运维(扩缩容、故障恢复),统一监控(Grafana/Prometheus) | 主从同步监控、手工故障切换(如网络分区处理) | 分片策略维护、数据迁移工具开发(如双写过渡) |
典型适用场景 | 大数据量(PB 级)、高并发(10万+ QPS)、强一致需求(如金融交易) | 小规模数据(单表<2000万行)、简单读写分离场景 | 中大规模数据(单库无法承载),但需接受分片复杂性 |
Elasticsearch(搜索引擎)
方才先简单介绍下ES(关于ES的详细介绍,后续有专题讲解):
- 核心机制:
- 倒排索引:快速全文搜索(如关键词检索)。
- 分片与副本:数据分片存储,副本保证高可用。
- 优势:近实时搜索、聚合分析、支持复杂查询(如模糊匹配、地理位置)。
- 场景:日志分析(ELK栈)、电商商品搜索、大数据分析。
什么场景需要?
有的小伙伴可能会有疑问,有了数据库为什么还需要搜索引擎?方才以一些典型的应用场景为例,做个对比说明:
- 电商平台:
- 数据库:存储用户信息、订单数据,处理支付事务。
- 搜索引擎:实现商品搜索(支持颜色、价格区间、关键词高亮)、个性化推荐。
- 社交网络:
- 数据库:管理好友关系、私信记录。
- 搜索引擎:快速检索用户发布的动态、评论内容,支持地理位置附近的人搜索。
- 日志监控系统:
- 数据库:存储系统配置、用户权限。
- 搜索引擎:实时分析日志(如 ELK 栈),快速定位服务器故障。
整个架构如下:
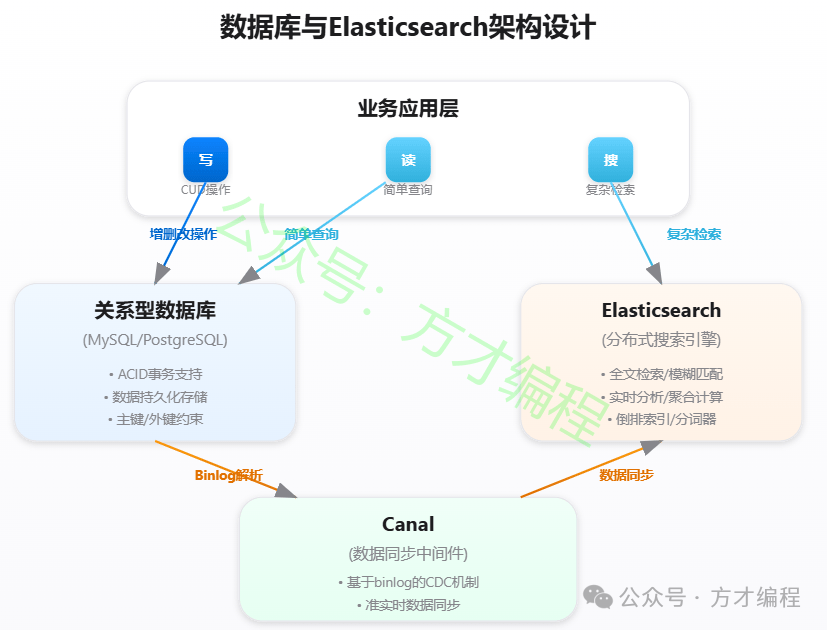
ES业务架构
ES业务架构
MinIO(对象存储)
前面介绍的数据库、搜索引擎等,更适合存储一些结构化或者半结构化的数据,在一个业务系统中, 一般都会有存储图片、pdf等非结构化数据的需求,这个时候,就会使用的对象存储服务(简称 OSS 服务)。
MinIO 是一个高性能、分布式、云原生的对象存储系统,专为存储和管理海量非结构化数据(如图片、视频、日志、备份文件等)设计。它完全兼容 Amazon S3 API,是开源领域最流行的 S3 替代方案,适用于私有云、混合云和边缘计算场景。
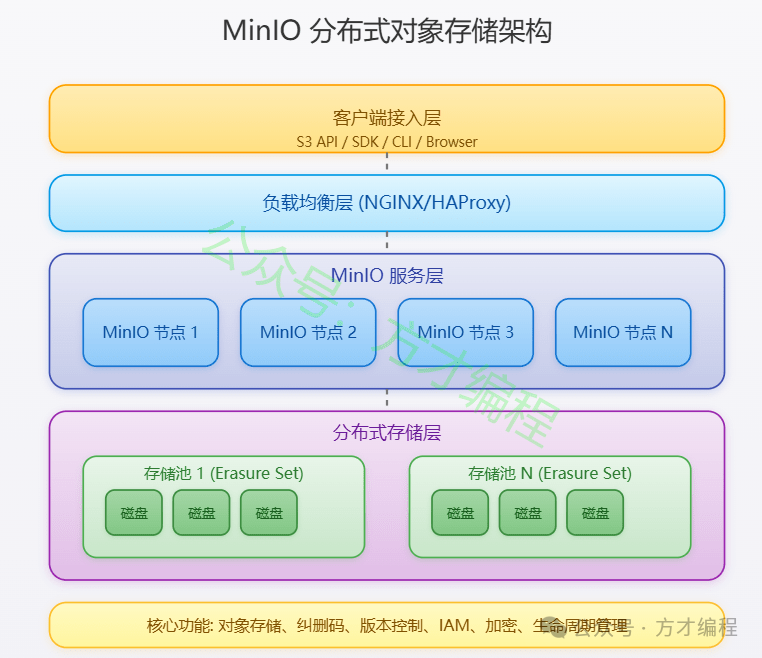
MinIo 架构
MinIo 架构
技术选型对比
技术 | 核心能力 | 一致性模型 | 适用场景 |
|---|---|---|---|
MySQL主从 | 读写分离、数据冗余 | 最终一致性 | 读多写少,容忍延迟 |
分库分表 | 数据分片、降低单点压力 | 依赖中间件 | 超大规模数据,高并发写入 |
TiDB | 强一致、HTAP | 强一致性 | 高并发事务+实时分析,替代分库分表 |
Elasticsearch | 全文搜索、聚合分析 | 最终一致性 | 日志、搜索、复杂查询 |
MinIO | 海量非结构化数据存储 | 强一致性 | 文件存储、云原生应用 |
总结
- 组合使用:TiDB处理结构化事务数据,ES实现搜索,MinIO存储文件,形成完整技术栈。
- CAP权衡:TiDB侧重CP(一致性与分区容忍),ES侧重AP(可用性与分区容忍)。
- 演进路径:初期用MySQL主从+读写分离,数据增长后分库分表或迁移至TiDB,按需引入ES和MinIO。
通过合理选型与组合,可构建高扩展、高可用的分布式系统,应对不同业务场景的数据挑战。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-04-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号