1. 基于 c++ executions的异步实现 - 从理论到实践

1. 基于 c++ executions的异步实现 - 从理论到实践

fangfang
发布于 2023-12-31 07:55:16
发布于 2023-12-31 07:55:16
1. 纠结的开篇
故事的开篇是笔者参与开发的一款自研引擎的底层 C++ 框架, 恰逢其时, 包含 stackless coroutine 特性的 C++20 已经发布并得到了几大主流 C++ 编译器的支持, 所以我们框架的异步模块实现也很自然的基于 stackless coroutine 的特性实现了一版工作在单一线程上的协程调度器, 对于一些依赖多次串行的异步操作来完成的业务逻辑来说, 这种机制确实带来了很大的便利, 你可以以非常线性的方式来对这种类型的业务逻辑进行实现了. 但美好总是短暂的, 很快我们就碰到了大量多线程相关的异步逻辑使用场景, 如FrameGraph里的DAG实现等, 完全依托Lambda Post机制, 肯定也是可以写的, 但相关的复杂度并不低, 这种情况下, 团队成员就开始考虑能否借助协程, 来简化相关代码的复杂度了.
这种情况下, 我们开始考虑以单线程版本的协程调度器实现作为基础, 尝试结合比较新的 C++ 异步思路, 来重新思考应该如何实现一个支持多线程, 尽量利用 C++ 新特性, 同时业务层简单易用的异步框架了. 问题的一部分答案我们其实在 <<从无栈协程到C++异步框架>>系列文章中给出了部分答案, 最后我们通过结合 ASIO 的调度器与 stackless coroutine, 以及来自 taskflow 的思路解决DAG相关的描述问题, 很大程度上已经解决了上面的问题. 但更未来向的 executions 在框架中的位置和标准化之后如何更好的利用它来进一步支持上对异步的结构化表达, 以及它与前面的Lambda Post, 多线程协程的区别和它的适用场景, 都是一个未来需要比较好的去回答的一个问题, 这也是本文主要想去探索解决的问题. 从本文最初成文(大概是2022年5月, 发布于公司内部KM和purecpp)到这次重新整理整个系列(2023年9月), 整个尝试的过程只能说一波三折, 并不是非常顺利了, 当然, 随着对相关实现的深入理解和细节的深挖, 收益也是颇多的. 闲话不多说了, 我们直接切入主题, 以笔者项目中对异步的实践和相关的思考来展开这篇总览的内容.
2. 前尘往事 - Lambda Post 应用介绍
2. ASIO 多线程调度 - lambda post 应用介绍
尽管我们通常将ASIO作为网络库使用,但实际上,它在支持通用任务调度方面也表现出色。借助C++11引入的lambda和函数对象,我们可以将通用任务包装成lambda,然后使用post()方法将其提交到某个io_context上, 整个任务派发的过程也是现在众多游戏引擎所使用的lambda post式的异步任务派发机制。大体的过程如下图所示:
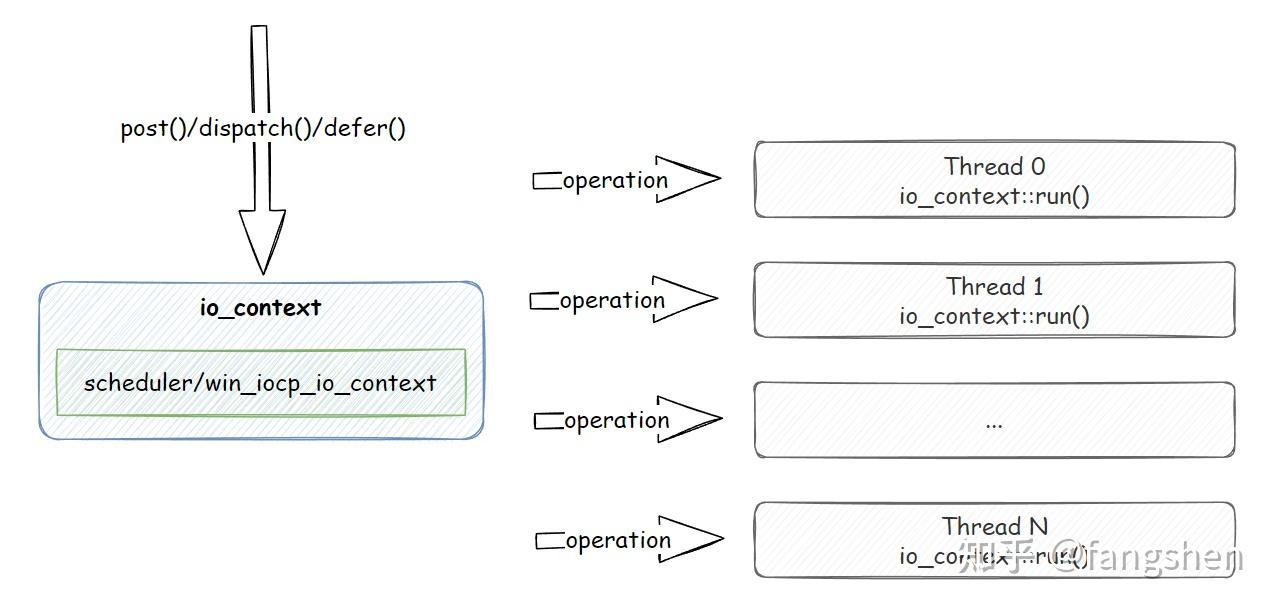
我们一般是通过io_context内的scheduler impl的post(), dispatch(), defer()这三个方法之一将业务侧的lambda传递给asio, asio会将对应的lambda存储为一个operation, 也就是一个任务, 而具体的operation最后会被执行io_context::run()的线程所执行.
!hint 需要注意的是
asio没有使用句柄式的方式对operation进行管理, 在需要返回值的情况下, 是通过额外的async_result的模板来完成异步传值等操作的. 下文中我们会对async_result做简单的介绍.
2.1 项目应用实例简介
ASIO所使用调度器本身就是一个很通用的lambda post机制, 所以将ASIO作为通用的并发框架当然也是切实可行的。实际上,网易的许多项目都采用了这种方法。最初是他们的服务器将ASIO作为底层并发框架,后来知名度较高的Messiah引擎也借鉴和发扬了这种方式,将ASIO作为底层基础的并发框架。
当然, 实际项目的使用中一般会将ASIO作简单的包装, 为了方便大家的理解, 这里直接以笔者所在的CrossEngine项目举例(CrossEngine是一个游戏引擎, 下文我们简称CE), 方便大家理解如何将ASIO用作通用的异步调度器的.
2.1.1 隔离式的ASIO使用
游戏引擎中一般会涉及到多个线程之间的任务调度, 下图是CE框架层中的asio::io_context与线程的关系和分组:
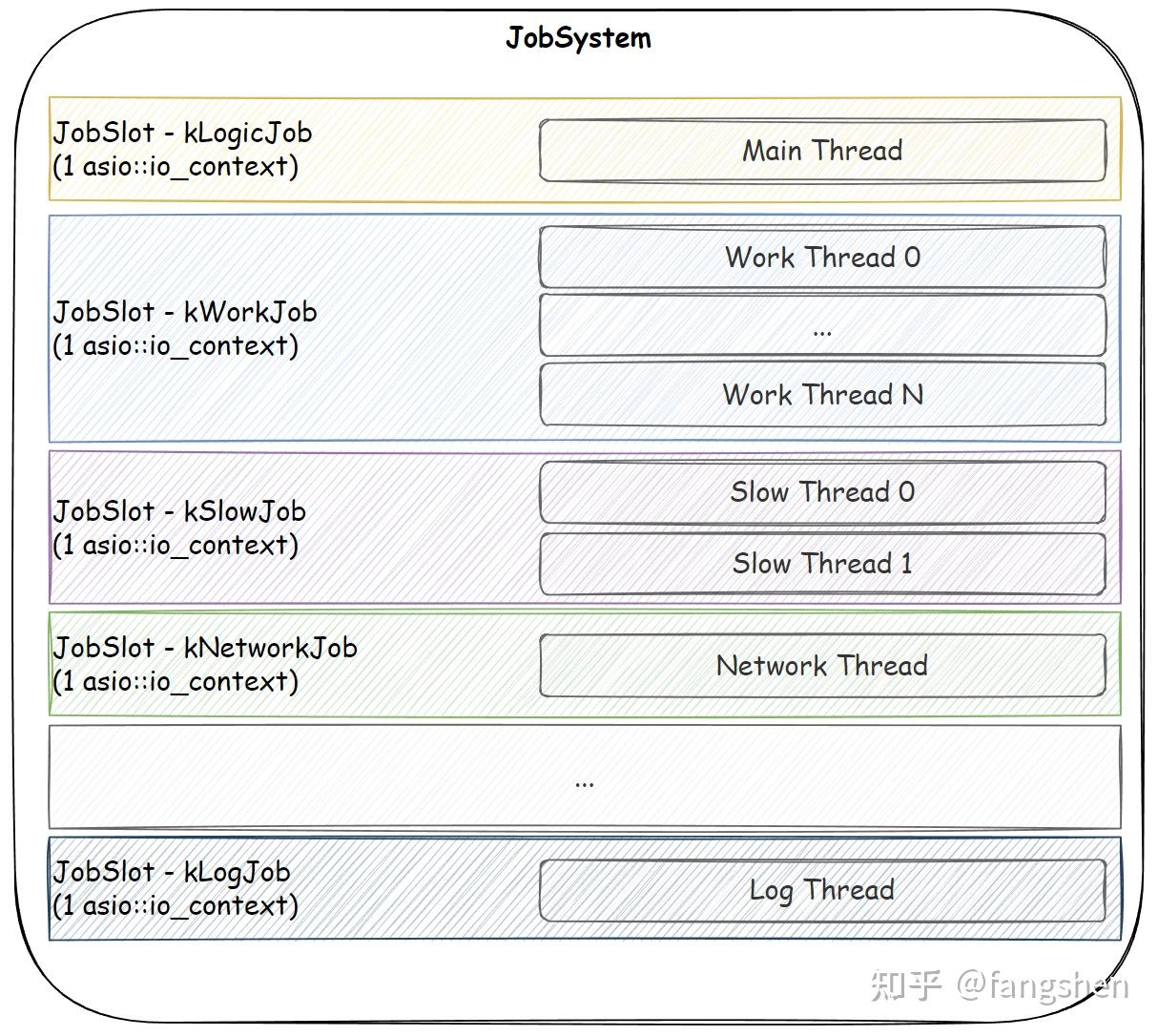
JobSystem图
整体的封装是比较简洁的: 1. 外围的JobSystem负责对所有的JobSlot进行管理 2. 每个JobSlot一一对应一个asio::context 3. 每个JobSlot会创建一组线程池用于其关联的asio::io_context的任务的调度, 也就是每个线程调用io_context::run()来执行投递来的任务. 4. 主线程(逻辑线程)是比较特殊的存在, 我们一般是使用手动驱动其工作的模式. 5. 业务侧使用JobType枚举来选择对应的asio::io_context来进行任务的投递, 这样就对业务侧适当隔离了asio本身, 枚举也易于记忆和使用.
2.1.2 JobType 简介
JobType 本身也是一种业务侧对任务进行分组的方式, 不同的 JobType 对应的是某一类粒度或者业务特性相近的任务, 如 kWorkJob, 对应的是一组工作线程, 我们希望在其上执行的任务粒度都是非常小的, 这样在有很多任务被投递到工作线程上的时候, 它们可以很好的并发, 而不是出现长时间等待另外一个任务完成后才能被调度的情况.
具体在CE框架层中对应JobType的定义如下:
enum class JobType : int {
kLogicJob = 0, // logic thread(main thread)
kWorkJob, // work thread
kSlowJob, // slow work thread(run io or other slow job)
kNetworkJob, // add a separate thread for network
kNetworkConnectJob, // extra connect thread for network
kLogJob, // log thread
kNotifyExternalJob, // use external process to report something, 1 thread only~~
kTotalJobTypes,
};JobType**的具体使用是: - kLogicJob - 主线程(逻辑线程)执行任务 - kWorkJob - Work Thread线程池执行任务(多个), 一般是计算量可控的小任务 - kSlowJob - IO专用线程池, IO相关的任务投递到本线程池 - kNetworkJob - 目前tbuspp专用的处理线程 - kNetworkConnectJob - 专用的网络连接线程, tbuspp模式下不需要 - kLogJob - 日志专用线程, 目前日志模块是自己起的线程, 可以归并到此处管理 -** kNotifyExternalJob** - 专用的通知线程, 如lua error的上报, 使用该类型
2.1.3 一个简单的文件异步读取示例
对于一个简单的异步任务, 它可能的执行状态是先在某个线程上做阻塞式的执行, 然后再回归主线程进行回调, 如下图所示:
sequenceDiagram
Logic Job ->>+Work Job: calculate task
Work Job ->>-Logic Job: calculate result这里我们给出CE中的异步文件读取代码为例:
auto ticket = GJobSystem->RequestTicket();
auto fullPath = GetFullPath(relPath);
GJobSystem->Post(
[this, ticket, relPath, fullPath, loadFunc]() {
ByteBufferPtr outBuf;
try {
// ... Code read file from system to outBuf ignore here.
} catch (std::exception& ex) {
ERR_DEF("Read file failed, name:%s, err:%s", fullPath.c_str(), ex.what());
}
GJobSystem->Post(
[outBuf, ticket, relPath, loadFunc]() {
if (ticket) {
loadFunc(ticket, relPath, "", outBuf);
}
},
JobType::kLogicJob);
},
JobType::kSlowJob);
return ticket;我们用两次Post()完成了文件的异步读取: 1. 第一次Post()后的任务会在kSlowJob上执行, 最后会被投递到JobSystem图上的两个Slow Thread之一进行执行. 2. 在完成文件的IO后, 会进行第二次的Post(), 将文件读取的结果投递给主线程, 在主线程回调相关的callback.
2.1.4 流水线式任务的示例
在CE中, 结合对asio::strand的封装, 对于下图中的流水线式任务:
sequenceDiagram
participant L as Logic Job
participant W1 as Work Job1
participant W2 as Work Job2
participant W3 as Work Job3
L ->>W1: part 1
activate W1
W1 ->>W2: part 2
deactivate W1
activate W2
W2 ->>W3: part 3
deactivate W2
activate W3
W3 ->>W2: part 4
deactivate W3
activate W2
W2 ->>L: return
deactivate W2我们直接使用代码:
auto strand = GJobSystem->request_strand(gbf::JobType::kWorkJob);
starnd.post([](){
//part1~
// ...
});
starnd.post([](){
//part2~
// ...
});
starnd.post([](){
//part3~
// ...
});
starnd.post([](){
//part4~
// ...
});
starnd.post([](){
GJobSystem->post([](){
//return code here
// ...
}, gbf::JobType::kLogicJob);
});就完成了这类链式任务的实现, 这样也能避免让具体的业务关注过于底层的复杂设计.
2.1.5 lambda post小议
对于lambda post类型的JobSystem实现来说, 整体设计上都是大同小异的, 可能差别比较多的地方主要体现在这两处: 1. 线程池的表达, 像CE这种是比较简约的设计, 某个线程创建后, 它对应执行的任务类型就被固定下来了, 但部分引擎如Halo, 使用的是更具公用性的线程, 一个线程可以对某几类任务进行调度. 后者的设计实现更紧凑, 间接可以实现减少总线程数, 那肯定也意味着更低的thread context switch了, 但底层的任务获取也会相对更复杂一些. 2. 依赖asio::strand这类设施, 我们能够补齐多工作线程上的线性表达能力, 但对于更复杂的DAG类型的组合任务表达, 每个引擎可能都会有自己差异化的实现. 本系列主要关注的是asio本身, 这部分暂时不进行展开了.
2.2 asio 与其他实现的对比
正好2021年的GDC上有一个\<\<One Frame In Halo Infinite>>的分享, 里面主要讲述的是对Halo Infinite的引擎升级, 提供新的JobSystem和新的动态帧的机制来支撑项目的, 我们直接以它为例子来对比一下framework和Halo的实现, 并且也借用Halo Infinite的例子, 来更好的了解这种lambda post模式的缺陷, 以及可以改进的点. Halo引入新的JobSystem主要是为了将老的Tetris结构的并发模式:

向新的基于Dependency的图状结构迁移:

他使用的JobSystem的业务Api其实很简单, 我们直接来看一下相关的代码:
JobSystem& jobSsytem = JobSystem::Get();
JobGraphHandle graphHandle = jobSystem.CreateJobGraph();
JobHandle jobA = jobSystem.AddJob(
graphHandle,
"JobA",
[](){...} );
JobHandle jobB = jobSystem.AddJob(
graphHandle,
"JobB",
[](){...} );
jobSystem.AddJobToJobDependency(jobA, jobB);
jobSystem.SubmitJobGraph(graphHandle);通过这样的机制, 就很容易形成如:
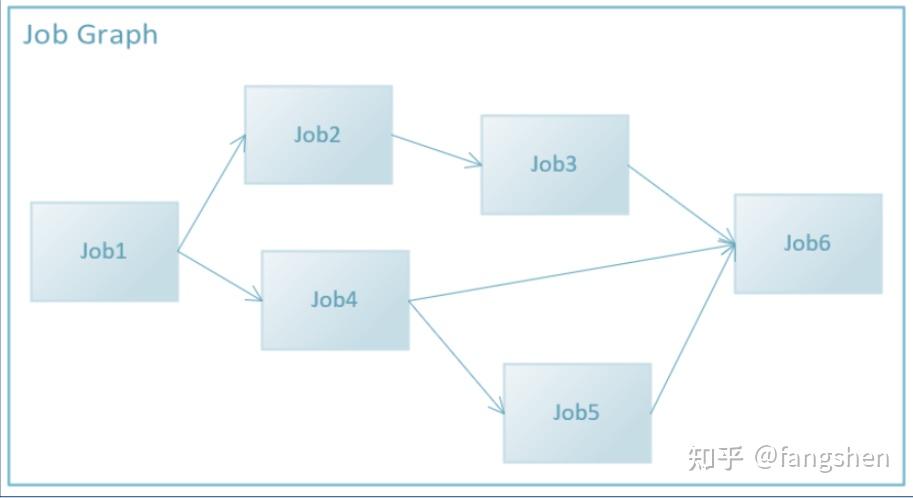
另外还有一个用于同步的SyncPoint:
JobSystem& jobSystem = JobSystem::Get();
JobGraphHandle graphHandle = jobSystem.CreateJobGraph();
SyncPointHandle syncPointX = jobSystem.CreateSyncPoint(graphHandle, "SyncPointX");
JobHandle jobA = jobSystem.AddJob(graphHandle, "JobA", [](){...});
JobHandle jobB = jobSystem.AddJob(graphHandle, "JobB", [](){...});
jobSystem.AddJobToSyncPointDependency(jobA, syncPointX);
jobSystem.AddSyncPointToJobDependency(syncPointX, jobB);
jobSystem.SubmitJobGraph(graphHandle);大致的作用如下:
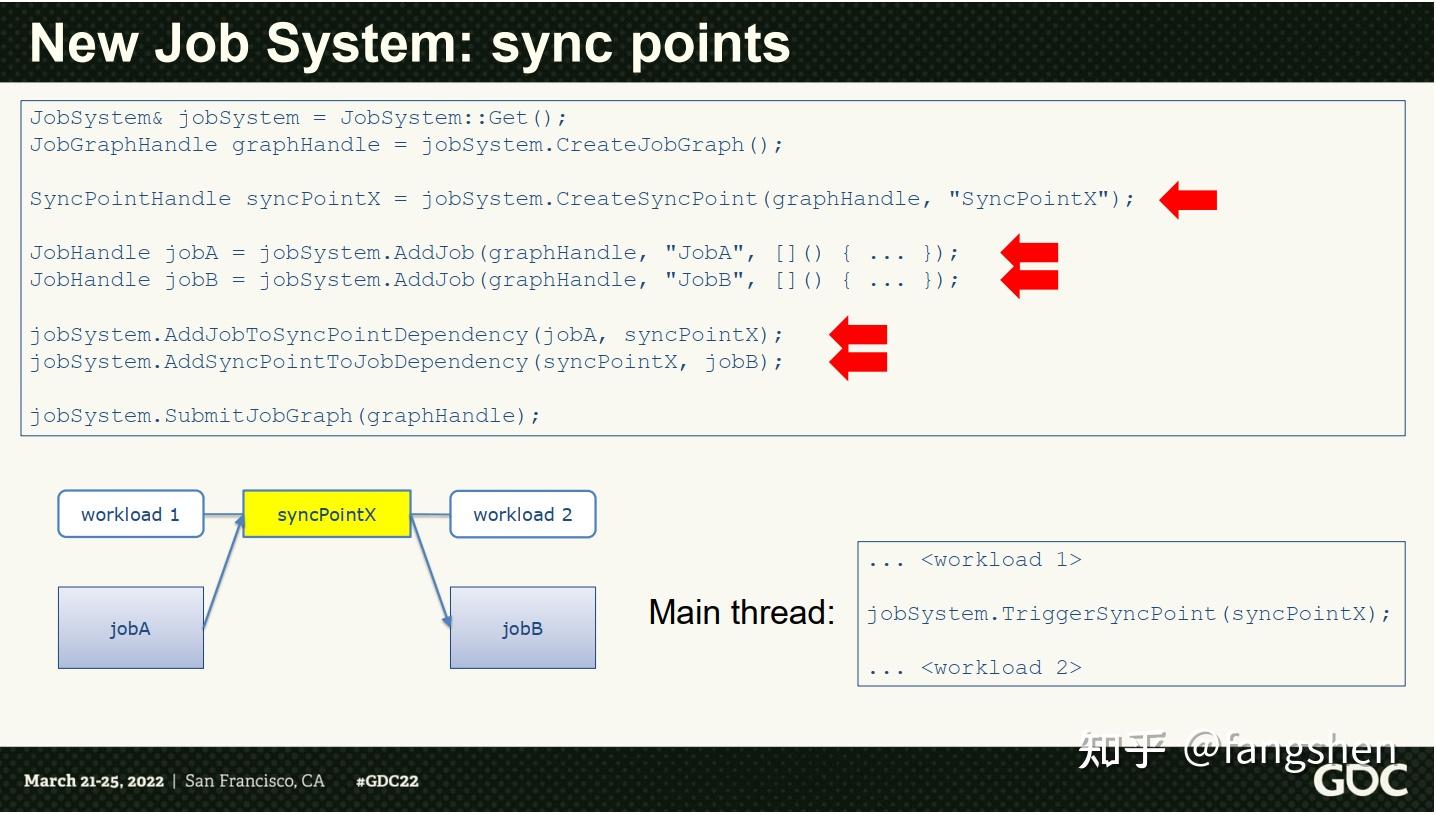
这样在workload主动触发SyncPoint后, 整体执行才会继续往下推进, 这样就能方便的加入一些主动的同步点对整个Graph的执行做相关的控制了.
回到asio, 我们前面也介绍了, 使用strand和post(), 我们也能很方便的构造出Graph形的执行情况 , 而SyncPoint其实类型framework中提供的Event, 表达上会略有差异, 但很容易看出两套实现其实是相当类同的. 这样的话, Halo 的JobSystem有的所有优缺点, framework基本也同样存在了, 这里简单搬运一下:

对于复杂并发业务的表达以lambda内嵌为主, 虽然这种方式尽可能保证所有代码上下文是比较集中的, 对比纯粹使用callback的模式有所进步, 但这种自由度过高的方式本身也会存在一些问题, 纯粹靠编码者来维系并发上下文的正确性, 这种情况下状态值在lambda之间的传递也需要特别的小心, 容易出错, 并且难以调试.
2.3 coroutine实现部分
coroutine部分之前的帖子里已经写得比较详细了, 这里仅给出链接以及简单的代码示例: 1. 如何在C++17中实现stackless coroutine以及相关的任务调度器 2. C++20 Coroutine实例教学 2. 另外还有一个purecpp大会的演讲视频, 主要内容与上述的两篇文章相关度比较高, 这里也给出相关的链接, 感兴趣的同学可以自行观看: C++20 coroutine原理与应用
代码示例:
//C++ 20 coroutine
auto clientProxy = mRpcClient->CreateServiceProxy("mmo.HeartBeat");
mScheduler.CreateTask20([clientProxy]()
-> rstudio::logic::CoResumingTaskCpp20 {
auto* task = rco_self_task();
printf("step1: task is %llu\n", task->GetId());
co_await rstudio::logic::cotasks::NextFrame{};
printf("step2 after yield!\n");
int c = 0;
while (c < 5) {
printf("in while loop c=%d\n", c);
co_await rstudio::logic::cotasks::Sleep(1000);
c++;
}
for (c = 0; c < 5; c++) {
printf("in for loop c=%d\n", c);
co_await rstudio::logic::cotasks::NextFrame{};
}
printf("step3 %d\n", c);
auto newTaskId = co_await rstudio::logic::cotasks::CreateTask(false,
[]()-> logic::CoResumingTaskCpp20 {
printf("from child coroutine!\n");
co_await rstudio::logic::cotasks::Sleep(2000);
printf("after child coroutine sleep\n");
});
printf("new task create in coroutine: %llu\n", newTaskId);
printf("Begin wait for task!\n");
co_await rstudio::logic::cotasks::WaitTaskFinish{ newTaskId, 10000 };
printf("After wait for task!\n");
rstudio::logic::cotasks::RpcRequest
rpcReq{clientProxy, "DoHeartBeat", rstudio::reflection::Args{ 3 }, 5000};
auto* rpcret = co_await rpcReq;
if (rpcret->rpcResultType == rstudio::network::RpcResponseResultType::RequestSuc) {
assert(rpcret->totalRet == 1);
auto retval = rpcret->retValue.to<int>();
assert(retval == 4);
printf("rpc coroutine run suc, val = %d!\n", retval);
}
else {
printf("rpc coroutine run failed! result = %d \n", (int)rpcret->rpcResultType);
}
co_await rstudio::logic::cotasks::Sleep(5000);
printf("step4, after 5s sleep\n");
co_return rstudio::logic::CoNil;
} );执行结果:
step1: task is 1
step2 after yield!
in while loop c=0
in while loop c=1
in while loop c=2
in while loop c=3
in while loop c=4
in for loop c=0
in for loop c=1
in for loop c=2
in for loop c=3
in for loop c=4
step3 5
new task create in coroutine: 2
Begin wait for task!
from child coroutine!
after child coroutine sleep
After wait for task!
service yield call finish!
rpc coroutine run suc, val = 4!
step4, after 5s sleep整体来看, 协程的使用还是给异步编程带来了很多便利, 但框架本身的实现其实还是有比较多迭代优化的空间的: 1. asio的调度部分与coroutine部分的实现是分离的 2. 早期我们自己的coroutine调度器实现仅支持主线程
2.4 小结
上面也结合halo的实例说到了一些限制, 那么这些问题有没有好的解决办法了, 答案是肯定的, 虽然execution并未完全通过提案, 但整体而言, execution新的sender/reciever模型, 对于解决上面提到的一些缺陷, 应该是提供了非常好的思路, 我们下一章节中继续展开.
3. so easy - execution就是解?
最开始的想法其实比较简单, 结合原来的framework, 适当引入提案中的execution一些比较可取的思路, 让framework的异步编程能更多的吸取c++新特性和execution比较高级的框架抽象能力, 提升整个异步库的实现质量. 所以最开始定的主线思路其实是更多的向execution倾斜, 怎么了解掌握execution, 怎么与现在的framework结合成了主线思路. 我们选择的基础参考库是来自冲元宇宙这波改名的Meta公司的libunifex, 客观来说, Meta公司的folly库, 以及libunifex库的实现质量, 肯定都是业界前沿的, 对c++新特性的使用和探索, 也是相当给力的. 这些我们后续在分析libunifex具体实现的篇章中也能实际感受到. 但深入了解libunifex后, 我们会发现, 它是一个特点鲜明的库,优缺点都不少. 相关的优点: 1. 尝试为c++提供表达异步的框架性结构. 2. 泛型用得出神入化, ponder在它前面基本是小弟级别的, 一系列泛用性特别强的template 编程示例, 比如隐含在sender/receiver思路内的lazy evaluate表达, 如何在大量使用泛型的情况下提供业务定制点等等. 3. 结构化的表达并发和异步, 相关代码的编写从自由发挥自主把控走向框架化, 约束化, 能够更有序更可靠的表达复杂异步逻辑 4. 整个执行pipeline的组织, 所有信息是compile time和runtime完备的, dependencies不会丢失. 5. 节点之间的值类型是强制检查的, 有问题的情况 , 大多时候compiler time就会报错. 相关的缺点: 1. 整个库的实现严重依赖了c++20 ranges采用的一种定制手段 cpo, 并且也使用了类似ranges的pipe表达方法, 理解相关代码存在一定的门坎.(后续会有具体的篇章展开相关的内容) 2. 库同时向下兼容了c++17, 但由于c++17本身特性的限制, 引入了大量的宏, 以及X Macros展开的方式, 导致相关的代码阅读难度进一步提升. 但实际上c++17版本并不具备可维护的价值, 依赖SIFINAE的实现, 如果中间任何一环报错, 必然需要在N屏的报错中寻找有效信息. 3. libunifex对coroutine的支持存疑, 虽然让coroutine可以作为一种reciever存在, 但本质上来说, coroutine其实更适合拿来做流程控制的胶水, 而不是作为异步中的某个节点存在. 4. 默认的scheduler实现质量离工业级还存在一定的距离, 这一点后续的代码分析中也会具体提到. 诸多问题的存在, 可能也是 executions 提案没有短时间内获得通过的原因吧, 但整体来说, executions 本身的理念还是很有参考价值的, 但以它的现状来说, 离最终的解肯定还是有比较大的距离的. 不过以 libunifex 为例, 我们已经能够直接编译运行相关的实现了, 虽然机制本身存在一定的复杂度, 不过对于我们学习参考, 肯定已经足够了。
4. 一点点补充
我们在其他文章中也提到过, 现阶段其实更多的推荐大家使用更成熟的库, 如 taskflow 的DAG表达来解决复杂的非线性并发问题,尝试使用已经进入c++20标准的 stackless coroutine 来解决一些线性并发逻辑的实现问题, 这样应该是更容易落地并且更可控的。 这几种并发实现相关的对比和结论这里直接上图了, 不再详细展开。

5. 系列的大纲
本系列涉及的基础知识和相关内容比较多. 整体的推进思路是先进行 c++ 异步总览性的表达, 这也是本篇文章做的事情。后面会直接以libunifex为例,进行libunifex实现的概述, 然后再补充一点 executions 依赖的底层机制, 如基本的pipeline机制, 以及tag invoke 机制, 最后再对 libunifex 的实现做一些细节性的讲述.
- 《1. 基于 c++ executions 的异步实现 - 从理论到实践 >>~~
- 《2. 基于 c++ executions 的异步实现 - libunifex的使用与实现概述>>
- 《3. exectuions 依赖的管道实现 - 在 c++ 中实现LINQ>>
- 《4. executions 依赖的定制机制 - 揭秘 cpo与tag_invoke!>>
- 《5. 基于 c++ executions的异步实现 - libunifex中的concepts详解>>
- 《6. 基于 c++ executions的异步实现 - strutured concurrency实现解析>>
- 《7. 基于 c++ executions的异步实现 - libunifex的scheduler实现》
6. 参考
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-12-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号