在 TKE 上部署 AI 大模型
原创
在 TKE 上部署 AI 大模型
原创
imroc
修改于 2025-02-20 20:10:52
修改于 2025-02-20 20:10:52
概述
本文介绍如何在 TKE 上部署 AI 大模型,以 DeepSeek-R1 为例,使用 Ollama、vLLM 或 SGLang 运行大模型并暴露 API,然后使用 OpenWebUI 提供交互界面。
Ollama 提供是 Ollama API,部署架构:

vLLM 和 SGLang 都提供了兼容 OpenAI 的 API,部署架构:

Ollama、vLLM、SGLang 与 OpenWebUI 介绍
- Ollama 是一个运行大模型的工具,可以看成是大模型领域的 Docker,可以下载所需的大模型并暴露 Ollama API,极大的简化了大模型的部署。
- vLLM 与 Ollama 类似,也是一个运行大模型的工具,但它针对推理做了很多优化,提高了模型的运行效率和性能,使得在资源有限的情况下也能高效运行大语言模型,另外,它提供兼容 OpenAI 的 API。
- SGLang 与 vLLM 类似,性能更强,且针对 DeepSeek 做了深度优化,也是 DeepSeek 官方推荐的工具。
- OpenWebUI 是一个大模型的 Web UI 交互工具,支持通过 Ollama 与 OpenAI 两种 API 与大模型交互。
技术选型
Ollama、vLLM 还是 SGLang?
- Ollama 的特点:个人用户或本地开发环境使用 Ollama 很方便,对各种 GPU 硬件和大模型的兼容性很好,不需要复杂的配置就能跑起来,但性能上不如 vLLM。
- vLLM 的特点:推理性能更好,也更节约资源,适合部署到服务器供多人使用,还支持多机多卡分布式部署,上限更高,但能适配的 GPU 硬件比 Ollama 少,且需要根据不同 GPU 和大模型来调整 vllm 的启动参数才能跑起来或者获得更好的性能表现。
- SGLang 的特点:是性能卓越的新兴之秀,针对特定模型优化(如 DeepSeek),吞吐量更高。
- 选型建议:如果有一定的技术能力且愿意折腾,能用 vLLM 或 SGLang 成功跑起来更推荐用 vLLM 和 SGLang 将大模型部署到 Kubernetes 中,否则就用 Ollama ,两种方式在本文中都有相应的部署示例。
AI 大模型数据如何存储?
AI 大模型通常占用体积较大,直接打包到容器镜像不太现实,如果启动时通过 initContainers 自动下载又会导致启动时间过长,因此建议使用共享存储来挂载 AI 大模型(先下发一个 Job 将模型下载到共享存储,然后再将共享存储挂载到运行大模型的 Pod 中),这样后面 Pod 启动时就无需下载模型了(虽然最终加载模型时同样也会经过CFS的网络下载,但只要 CFS 使用规格比较高,如 Turbo 类型,速度就会很快)。
在腾讯云上可使用 CFS 来作为共享存储,CFS 的性能和可用性都非常不错,适合 AI 大模型的存储。本文将使用 CFS 来存储 AI 大模型。
GPU 机型如何选?
不同的机型使用的 GPU 型号不一样,机型与 GPU 型号的对照表参考 GPU 计算型实例 ,Ollama 相比 vLLM,支持的 GPU 型号更广泛,兼容性更好,建议根据事先调研自己所使用的工具和大模型,选择合适的 GPU 型号,再根据前面的对照表确定要使用的 GPU 机型,另外也注意下选择的机型在哪些地域在售,以及是否售罄,可通过 购买云服务器 页面进行查询(实例族选择GPU机型)。
镜像说明
本文中的示例使用的镜像都是官方提供的镜像,tag 为 latest,建议根据自身情况改成指定版本的 tag,可点击下面的连接查看镜像的 tag 列表:
- sglang: lmsysorg/sglang
- ollama: ollama/ollama
- vllm: vllm/vllm-openai
官方镜像均在 DockerHub,且体积较大,在 TKE 环境 默认有免费的 DockerHub 镜像加速,国内地域也可以拉取 DockerHub 的镜像,但速度一般,镜像较大时等待的时间较长,建议将镜像同步至 容器镜像服务 TCR,再替换 YAML 中镜像地址,这样可极大加快镜像拉取速度。
操作步骤
步骤1: 准备集群
登录 容器服务控制台,创建一个集群,集群类型选择TKE 标准集群。详情请参见 创建集群。
步骤2: 准备 CFS 存储
安装 CFS 插件
- 在集群列表中,单击集群 ID,进入集群详情页。
- 选择左侧菜单栏中的组件管理,在组件页面单击新建。
- 在新建组件管理页面中勾选 CFS(腾讯云文件存储)。
支持选择 CFS(腾讯云文件存储) 或 CFS Turbo(腾讯云高性能并行文件系统),本文以 CFS(腾讯云文件存储)为例。 CFS-Turbo 的性能更强,读写速度更快,但成本也更高。如果希望大模型运行和下载速度更快,可以考虑使用 CFS-Turbo。
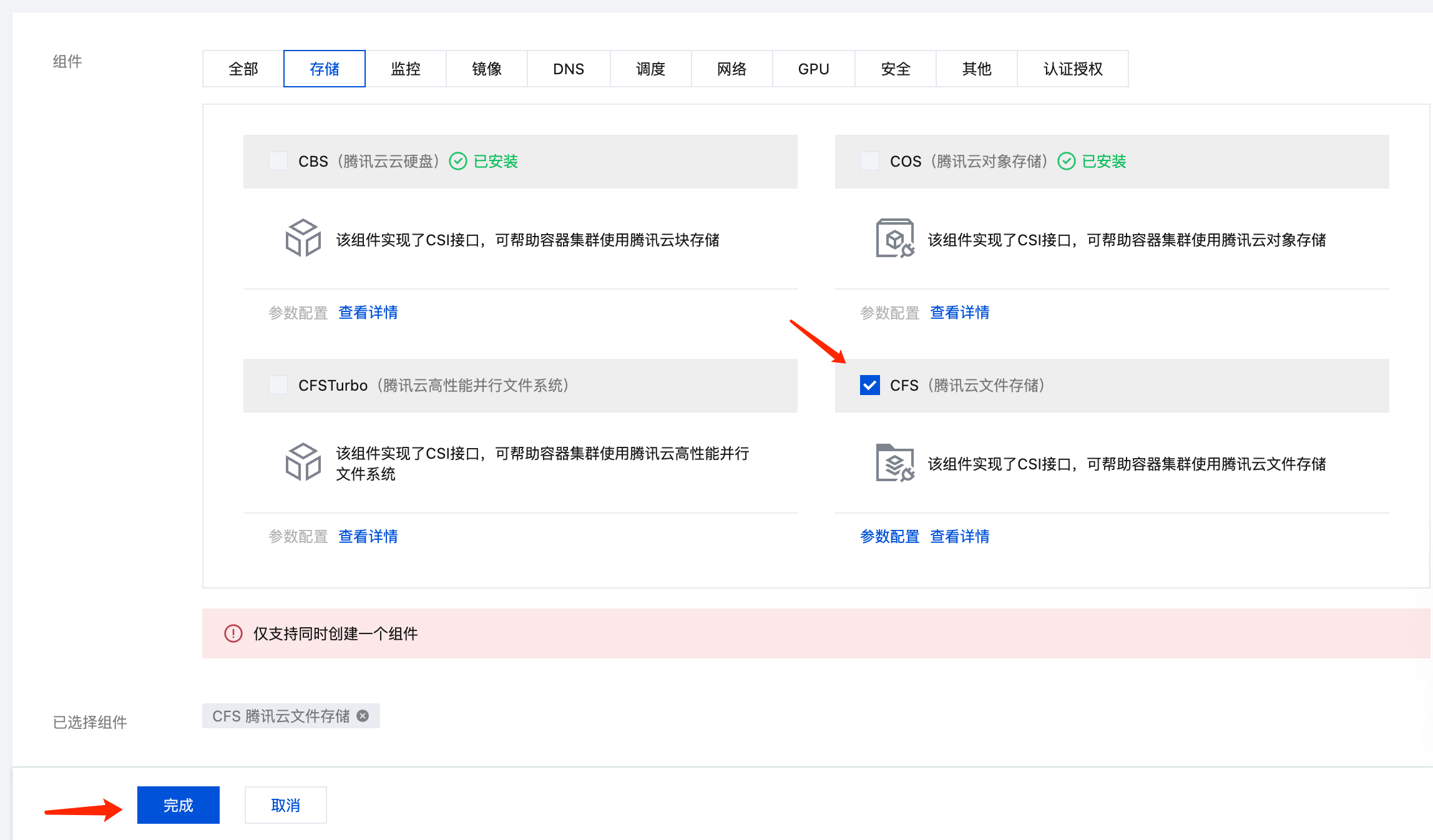
- 单击完成即可创建组件。
新建 StorageClass
该步骤选择项较多,因此本文示例通过容器服务控制台来创建 PVC。若您希望通过 YAML 来创建,可以先用控制台创建一个测试 PVC,然后复制生成的 YAML 文件
- 在集群列表中,单击集群 ID,进入集群详情页。
- 选择左侧菜单栏中的存储,在 StorageClass 页面单击新建。
- 在新建存储页面,根据实际需求,创建 CFS 类型的 StorageClass。如下图所示:
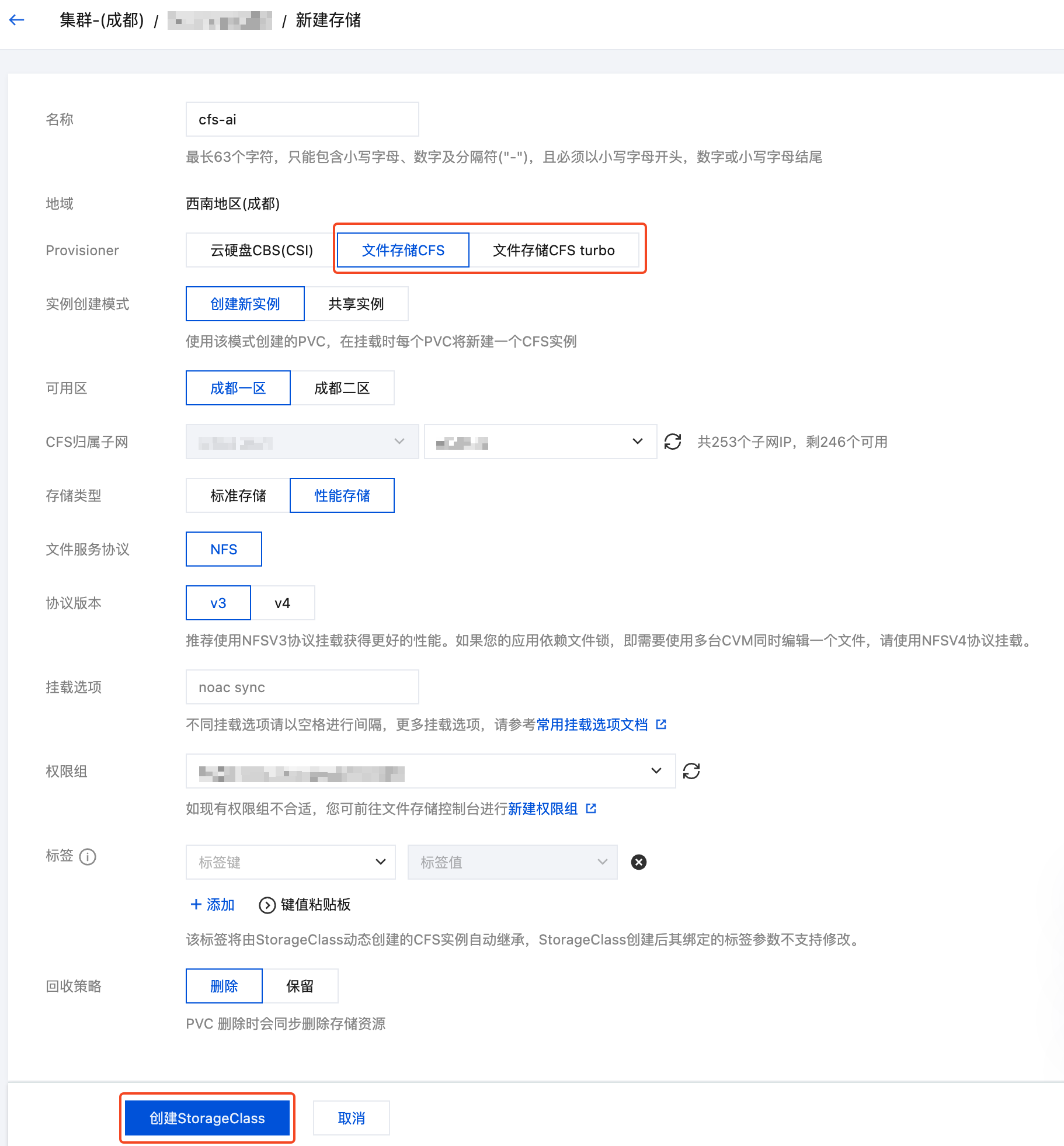
- 名称:请输入 StorageClass 名称,本文以 “cfs-ai” 为例。
- Provisioner:选择 “文件存储 CFS”。
- 存储类型:建议选择“性能存储”,其读写速度比“标准存储”更快。
如果是新建 CFS-Turbo
StorageClass,则需要在文件存储控制台先新建好 CFS-Turbo 文件系统,然后创建StorageClass时引用对应的 CFS-Turbo 实例。
创建 PVC
创建一个 CFS 类型的 PVC,用于存储 AI 大模型:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ai-model
labels:
app: ai-model
spec:
storageClassName: cfs-ai
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi- 注意替换
storageClassName。 - 对于 CFS 来说,
storage大小无所谓,可随意指定,按实际占用空间付费的。
再创建一个 PVC 给 OpenWebUI 用,可使用同一个 storageClassName:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: webui
labels:
app: webui
spec:
accessModes:
- ReadWriteMany
storageClassName: cfs-ai
resources:
requests:
storage: 100Gi步骤3: 新建 GPU 节点池
- 在集群管理页面,选择集群 ID,进入集群的基本信息页面。
- 选择左侧菜单栏中的节点管理,在节点池页面单击新建。
- 选择节点类型。配置详情请参见 创建节点池。
- 如果使用原生节点或普通节点,操作系统选新一点的;系统盘和数据盘默认 50GB,建议调大点(如200GB),避免因 AI 相关镜像大导致节点磁盘空间压力大;机型配置在GPU 机型中选择一个符合需求且没有售罄的机型,如有 GPU 驱动选项,也选最新的版本。
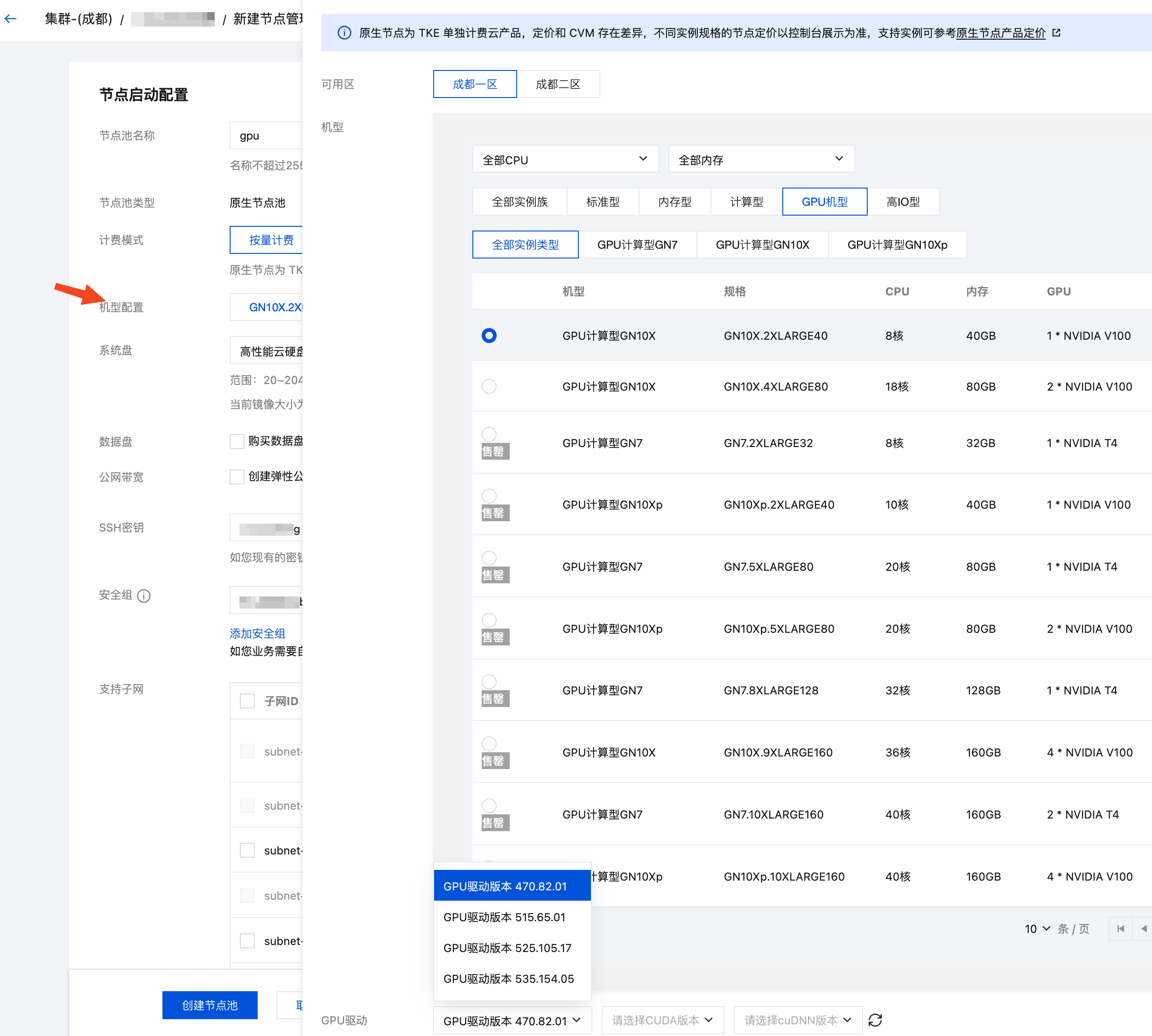
- 如果使用超级节点,是虚拟的节点,每个 Pod 都是独占的轻量虚拟机,所以无需选择机型,只需在部署的时候通过 Pod 注解来指定 GPU 卡的型号(后面示例中会有)。
- 单击创建节点池。
GPU 插件无需显式安装,如果使用普通节点或原生节点,配置了 GPU 机型,会自动安装 GPU 插件;如果使用超级节点,则无需安装 GPU 插件。
步骤4: 使用 Job 下载 AI 大模型
下发一个 Job,将需要用的 AI 大模型下载到 CFS 共享存储中,以下分别是 vLLM、SGLang 和 Ollama 的 Job 示例:
- 使用之前 Ollama 或 vLLM 的镜像执行一个脚本去下载我们需要的 AI 大模型,本例中下载的是 DeepSeek-R1 的模型,修改
LLM_MODEL以替换大语言模型。 - 如果使用 Ollama,可以在 Ollama 模型库 查询和搜索需要的模型;如果使用 vLLM,可以在 Hugging Face 模型库 和 ModelScope 模型库 查询和搜索需要的模型(国内环境可以用 ModelScope 的模型库,避免因网络问题下载失败,通过
USE_MODELSCOPE环境环境变量控制是否从 ModelScope 下载)。
vLLM Job
apiVersion: batch/v1
kind: Job
metadata:
name: vllm-download-model
labels:
app: vllm-download-model
spec:
template:
metadata:
name: vllm-download-model
labels:
app: vllm-download-model
annotations:
eks.tke.cloud.tencent.com/root-cbs-size: '100' # 如果用超级节点,默认系统盘只有 20Gi,vllm 镜像解压后会撑爆磁盘,用这个注解自定义一下系统盘容量(超过20Gi的部分会收费)。
spec:
containers:
- name: vllm
image: vllm/vllm-openai:latest
env:
- name: LLM_MODEL
value: deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
- name: USE_MODELSCOPE
value: "1"
command:
- bash
- -c
- |
set -ex
if [[ "$USE_MODELSCOPE" == "1" ]]; then
exec modelscope download --local_dir=/data/$LLM_MODEL --model="$LLM_MODEL"
else
exec huggingface-cli download --local-dir=/data/$LLM_MODEL $LLM_MODEL
fi
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
persistentVolumeClaim:
claimName: ai-model
restartPolicy: OnFailureSGLang Job
apiVersion: batch/v1
kind: Job
metadata:
name: sglang-download-model
labels:
app: sglang-download-model
spec:
template:
metadata:
name: sglang-download-model
labels:
app: sglang-download-model
spec:
containers:
- name: sglang
image: lmsysorg/sglang:latest
env:
- name: LLM_MODEL
value: deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
- name: USE_MODELSCOPE
value: "1"
command:
- bash
- -c
- |
set -ex
if [[ "$USE_MODELSCOPE" == "1" ]]; then
exec modelscope download --local_dir=/data/$LLM_MODEL --model="$LLM_MODEL"
else
exec huggingface-cli download --local-dir=/data/$LLM_MODEL $LLM_MODEL
fi
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
persistentVolumeClaim:
claimName: ai-model
restartPolicy: OnFailureOllama Job
apiVersion: batch/v1
kind: Job
metadata:
name: ollama-download-model
labels:
app: ollama-download-model
spec:
template:
metadata:
name: ollama-download-model
labels:
app: ollama-download-model
annotations:
eks.tke.cloud.tencent.com/root-cbs-size: '100' # 如果用超级节点,默认系统盘只有 20Gi,vllm 镜像解压后会撑爆磁盘,用这个注解自定义一下系统盘容量(超过20Gi的部分会收费)。
spec:
containers:
- name: ollama
image: ollama/ollama:latest
env:
- name: LLM_MODEL
value: deepseek-r1:7b
command:
- bash
- -c
- |
set -ex
ollama serve &
sleep 5 # sleep 5 seconds to wait for ollama to start
exec ollama pull $LLM_MODEL
volumeMounts:
- name: data
mountPath: /root/.ollama # ollama 的模型数据存储在 `/root/.ollama` 目录下,挂载 CFS 类型的 PVC 到该路径。
volumes:
- name: data
persistentVolumeClaim:
claimName: ai-model
restartPolicy: OnFailure步骤5: 部署 Ollama、vLLM 或 SGLang
- 运行大模型需要使用 GPU,因此在 requests/limits 中指定了
nvidia.com/gpu资源,以便让 Pod 调度到 GPU 机型并分配 GPU 卡使用。 - 如果希望大模型跑在超级节点,需通过 Pod 注解
eks.tke.cloud.tencent.com/gpu-type指定 GPU 类型,可选V100、T4、A10*PNV4、A10*GNV4,具体可参考 这里。 - 如调度到超级节点,也指定下
eks.tke.cloud.tencent.com/root-cbs-size: '100'这个注解提升系统盘容量(默认只有 20GB,镜像解压后可能撑爆磁盘)。
vLLM
通过 Deployment 部署 vLLM:
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm
labels:
app: vllm
spec:
selector:
matchLabels:
app: vllm
replicas: 1
template:
metadata:
labels:
app: vllm
spec:
containers:
- name: vllm
image: vllm/vllm-openai:latest
imagePullPolicy: Always
env:
- name: PYTORCH_CUDA_ALLOC_CONF
value: expandable_segments:True
- name: LLM_MODEL
value: deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
command:
- bash
- -c
- |
vllm serve /data/$LLM_MODEL \
--served-model-name $LLM_MODEL \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code \
--enable-chunked-prefill \
--max_num_batched_tokens 1024 \
--max_model_len 1024 \
--enforce-eager \
--tensor-parallel-size 1
securityContext:
runAsNonRoot: false
ports:
- containerPort: 8000
readinessProbe:
failureThreshold: 3
httpGet:
path: /health
port: 8000
initialDelaySeconds: 5
periodSeconds: 5
resources:
requests:
cpu: 2000m
memory: 2Gi
nvidia.com/gpu: "1"
limits:
nvidia.com/gpu: "1"
volumeMounts:
- name: data
mountPath: /data
- name: shm
mountPath: /dev/shm
volumes:
- name: data
persistentVolumeClaim:
claimName: ai-model
# vLLM needs to access the host's shared memory for tensor parallel inference.
- name: shm
emptyDir:
medium: Memory
sizeLimit: "2Gi"
restartPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: vllm-api
spec:
selector:
app: vllm
type: ClusterIP
ports:
- name: api
protocol: TCP
port: 8000
targetPort: 8000--served-model-name参数指定大模型名称,与前面下载 Job 中指定的名称要一致,注意替换。- 模型数据引用前面下载 Job 使用的 PVC,挂载到
/data目录下。 - vLLM 监听 8000 端口暴露 API,定义 Service 方便后续被 OpenWebUI 调用。
SGLang
通过 Deployment 部署 SGLang:
apiVersion: apps/v1
kind: Deployment
metadata:
name: sglang
labels:
app: sglang
spec:
selector:
matchLabels:
app: sglang
replicas: 1
template:
metadata:
labels:
app: sglang
spec:
containers:
- name: sglang
image: lmsysorg/sglang:latest
env:
- name: LLM_MODEL
value: deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
command:
- bash
- -c
- |
set -x
exec python3 -m sglang.launch_server \
--host 0.0.0.0 \
--port 30000 \
--model-path /data/$LLM_MODEL
resources:
limits:
nvidia.com/gpu: "1"
ports:
- containerPort: 30000
volumeMounts:
- name: data
mountPath: /data
- name: shm
mountPath: /dev/shm
volumes:
- name: data
persistentVolumeClaim:
claimName: ai-model
- name: shm
emptyDir:
medium: Memory
sizeLimit: 40Gi
restartPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: sglang
spec:
selector:
app: sglang
type: ClusterIP
ports:
- name: api
protocol: TCP
port: 30000
targetPort: 30000LLM_MODEL环境变量指定大模型名称,与前面下载 Job 中指定的名称要一致,注意替换。- 模型数据引用前面下载 Job 使用的 PVC,挂载到
/data目录下。 - SGLang 监听 30000 端口暴露 API,并定义 Service 以便后续被 OpenWebUI 调用。
Ollama
apiVersion: apps/v1
kind: Deployment
metadata:
name: ollama
labels:
app: ollama
spec:
selector:
matchLabels:
app: ollama
replicas: 1
template:
metadata:
labels:
app: ollama
spec:
containers:
- name: ollama
image: ollama/ollama:latest
imagePullPolicy: IfNotPresent
command: ["ollama", "serve"]
env:
- name: OLLAMA_HOST
value: ":11434"
resources:
requests:
cpu: 2000m
memory: 2Gi
nvidia.com/gpu: "1"
limits:
cpu: 4000m
memory: 4Gi
nvidia.com/gpu: "1"
ports:
- containerPort: 11434
name: ollama
volumeMounts:
- name: data
mountPath: /root/.ollama
volumes:
- name: data
persistentVolumeClaim:
claimName: ai-model
restartPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: ollama
spec:
selector:
app: ollama
type: ClusterIP
ports:
- name: server
protocol: TCP
port: 11434
targetPort: 11434- Ollama 的模型数据存储在
/root/.ollama目录下,挂载已经下载好 AI 大模型的 CFS 类型 PVC 到该路径。 - Ollama 监听 11434 端口暴露 API,定义 Service 方便后续被 OpenWebUI 调用。
- Ollama 默认监听的是回环地址(127.0.0.1),指定
OLLAMA_HOST环境变量,强制对外暴露 11434 端口。
步骤6: 配置 GPU 弹性伸缩
如果需要对 GPU 资源进行弹性伸缩,可以按照下面的方法进行配置。
GPU 的 Pod 会有一些监控指标,参考 GPU 监控指标,可以根据这些监控指标配置 HPA 实现 GPU Pod 的弹性伸缩,比如按照 GPU 利用率:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: vllm
spec:
minReplicas: 1
maxReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: vllm
metrics: # 更多 GPU 指标参考 https://cloud.tencent.com/document/product/457/38929#gpu
- pods:
metric:
name: k8s_pod_rate_gpu_used_request # GPU利用率 (占 Request)
target:
averageValue: "80"
type: AverageValue
type: Pods
behavior:
scaleDown:
policies:
- periodSeconds: 15
type: Percent
value: 100
selectPolicy: Max
stabilizationWindowSeconds: 300
scaleUp:
policies:
- periodSeconds: 15
type: Percent
value: 100
- periodSeconds: 15
type: Pods
value: 4
selectPolicy: Max
stabilizationWindowSeconds: 0需要注意的是,GPU 资源通常比较紧张,缩容后不一定还能再买回来,如不希望缩容,可以给 HPA 配置下禁止缩容:
behavior:
scaleDown:
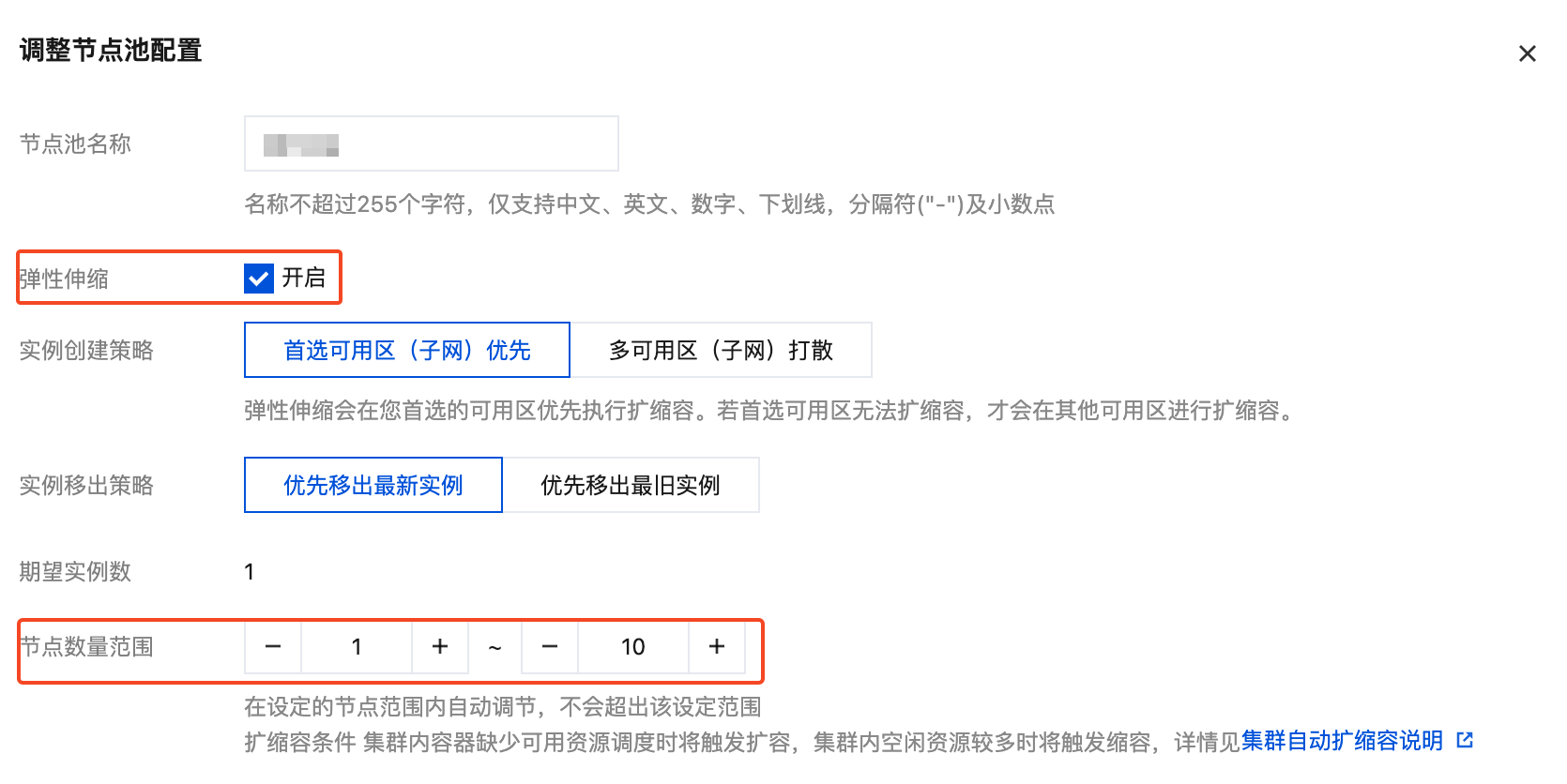
selectPolicy: Disabled如果使用原生节点或普通节点,还需对节点池启动弹性伸缩,否则 GPU Pod 扩容后没相应的 GPU 节点会导致 Pod 一直处于 Pending 状态。
节点池启用弹性伸缩的方法是编辑节点池,然后勾选弹性伸缩,配置一下节点数量范围,最后点击确认:
步骤7: 部署 OpenWebUI
使用 Deployment 部署 OpenWebUI,并定义 Service 方便后续对外暴露访问。后端 API 可以由 vLLM、SGLang 或 Ollama 提供,以下提供这三种情况的 OpenWebUI 部署示例:
vLLM 后端
apiVersion: apps/v1
kind: Deployment
metadata:
name: webui
spec:
replicas: 1
selector:
matchLabels:
app: webui
template:
metadata:
labels:
app: webui
spec:
containers:
- name: webui
image: imroc/open-webui:main # docker hub 中的 mirror 镜像,长期自动同步,可放心使用
env:
- name: OPENAI_API_BASE_URL
value: http://vllm-api:8000/v1 # vllm 的地址
- name: ENABLE_OLLAMA_API # 禁用 Ollama API,只保留 OpenAI API
value: "False"
tty: true
ports:
- containerPort: 8080
resources:
requests:
cpu: "500m"
memory: "500Mi"
limits:
cpu: "1000m"
memory: "1Gi"
volumeMounts:
- name: webui-volume
mountPath: /app/backend/data
volumes:
- name: webui-volume
persistentVolumeClaim:
claimName: webui
---
apiVersion: v1
kind: Service
metadata:
name: webui
labels:
app: webui
spec:
type: ClusterIP
ports:
- port: 8080
protocol: TCP
targetPort: 8080
selector:
app: webuiSGLang 后端
apiVersion: apps/v1
kind: Deployment
metadata:
name: webui
spec:
replicas: 1
selector:
matchLabels:
app: webui
template:
metadata:
labels:
app: webui
spec:
containers:
- name: webui
image: imroc/open-webui:main # docker hub 中的 mirror 镜像,长期自动同步,可放心使用
env:
- name: OPENAI_API_BASE_URL
value: http://sglang:30000/v1 # sglang 的地址
- name: ENABLE_OLLAMA_API # 禁用 Ollama API,只保留 OpenAI API
value: "False"
tty: true
ports:
- containerPort: 8080
resources:
requests:
cpu: "500m"
memory: "500Mi"
limits:
cpu: "1000m"
memory: "1Gi"
volumeMounts:
- name: webui-volume
mountPath: /app/backend/data
volumes:
- name: webui-volume
persistentVolumeClaim:
claimName: webui
---
apiVersion: v1
kind: Service
metadata:
name: webui
labels:
app: webui
spec:
type: ClusterIP
ports:
- port: 8080
protocol: TCP
targetPort: 8080
selector:
app: webuiOllama 后端
apiVersion: apps/v1
kind: Deployment
metadata:
name: webui
spec:
replicas: 1
selector:
matchLabels:
app: webui
template:
metadata:
labels:
app: webui
spec:
containers:
- name: webui
image: imroc/open-webui:main # docker hub 中的 mirror 镜像,长期自动同步,可放心使用
env:
- name: OLLAMA_BASE_URL
value: http://ollama:11434 # ollama 的地址
- name: ENABLE_OPENAI_API # 禁用 OpenAI API,只保留 Ollama API
value: "False"
tty: true
ports:
- containerPort: 8080
resources:
requests:
cpu: "500m"
memory: "500Mi"
limits:
cpu: "1000m"
memory: "1Gi"
volumeMounts:
- name: webui-volume
mountPath: /app/backend/data
volumes:
- name: webui-volume
persistentVolumeClaim:
claimName: webui
---
apiVersion: v1
kind: Service
metadata:
name: webui
labels:
app: webui
spec:
type: ClusterIP
ports:
- port: 8080
protocol: TCP
targetPort: 8080
selector:
app: webuiOpenWebUI 的数据存储在
/app/backend/data目录(如账号密码、聊天历史等数据),我们挂载 PVC 到这个路径。
步骤8: 暴露 OpenWebUI 并与模型对话
如果只是本地测试,可以使用 kubectl port-forward 暴露服务:
kubectl port-forward service/webui 8080:8080在浏览器中访问 http://127.0.0.1:8080 即可。
你还可以通过 Ingress 或 Gateway API 来暴露,下面给出示例。
Gateway API
注意: 使用 Gateway API 需要集群中装有 Gateway API 的实现,如 TKE 应用市场中的 EnvoyGateway,具体 Gateway API 用法参考 官方文档
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: ai
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
namespace: envoy-gateway-system
name: imroc
hostnames:
- "ai.imroc.cc"
rules:
- backendRefs:
- group: ""
kind: Service
name: webui
port: 8080parentRefs引用定义好的Gateway(通常一个 Gateway 对应一个 CLB)。hostnames替换为你自己的域名,确保域名能正常解析到 Gateway 对应的 CLB 地址。backendRefs指定 OpenWebUI 的 Service。
Ingress
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: webui
spec:
rules:
- host: "ai.imorc.cc"
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: webui
port:
number: 8080host替换为你自己的域名,确保域名能正常解析到 Ingress 对应的 CLB 地址。backend.service指定 OpenWebUI 的 Service。
最后在浏览器访问相应的地址即可进入 OpenWebUI 页面。
首次进入 OpenWebUI 会提示创建管理员账号密码,创建完毕后即可登录,然后默认会使用前面下载好的大模型进行对话。

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号