flink集群模式
原创

前言 :
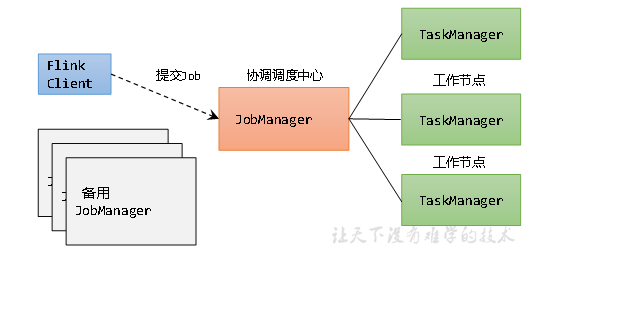
TaskManager的组成:由若干个(在底层flink-conf.yaml文件配置)taskSlot组成
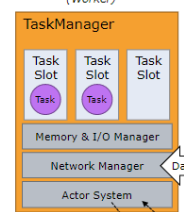
这是一个flink集群的各个角色的分配,TaskManager可以在部署到其他虚拟机上,一般默认的数量是三个。
jobmanger:负责整个 Flink 集群任务的调度以及资源的管理从客户端中接收作业
客户端通过将编写好的 Flink 应用编译打包,提交到 JobManager,JobManger根据集群TaskManager 上 TaskSlot 的使用情况,为提交的应用分配相应的 TaskSlot 资源并命令 TaskManager 启动与执行从客户端中获取的作业;JobManger还负责协调Checkpoint 操作,每个 TaskManager 节点 收到 Checkpoint 触发指令后,完成 Checkpoint 操作,所有的 Checkpoint 协调过程都是在 Fink JobManager 中完成。
TaskManager:负责具体的任务执行和任务资源申请和管理
TaskManger从 JobManager 接收需要执行的任务,然后申请Slot 资源(根据集群Slot使用情况以及并行度设置)并尝试启动Task,开始执行作业,TaskManager中最小的资源调度单位是TaskSlots。TaskManger数量由集群中Slave数量决定
taskSlots:Task共享系统资源(内存);TaskManger并发执行能力决定性因素。
TaskManager 是一个 JVM 进程,是实际负责执行计算的Worker,会以独立的线程来执行一个task或多个subtask。为了控制一个 TaskManager 能执行多少个 task,Flink 提出了 Task Slot 的概念
(1)Task之间通过 TaskSlot 方式共享系统资源(内存),TaskSlots也决定TaskManger并发执行能力。
(2)每个TaskSlot代表TaskManager资源不同分割。例如,具有三个插槽的TaskManager会将其内存的1/3平均分配到每个TaskSlot。分配资源意味着子任务不会与其他作业的子任务竞争内存,而是具有一定数量的保留托管内存。需要注意的是,此处没有对CPU进行隔离。当前TaskSlot仅将任务的内存进行隔离,简言之,即每个TaskSlot持有部分TaskManger内存,同一个作业下的task/subtask可共享TaskSlot
Client:Flink程序提交的客户端
Client是Flink程序提交的客户端,当用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处理。正因为其需要提交到Flink集群,所以Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给JobManager。
各个角色执行的功能:

flink client 相当于甲方,把job(需求)转换并提交给jobmanager(领导),然后jobmanger把job拆分成各个算子,分配给TaskManager执行。
-----------------------------------------------------------分割线-------------------------------------------------------------------------
1、会话模式(Session Mode)
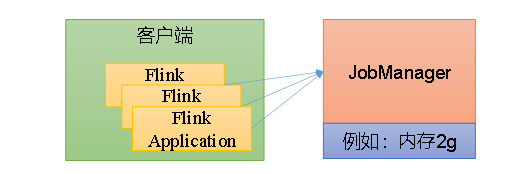
工作模式:
会话模式是先启动一个集群,此时集群的资源已确定,所有的 flink client提交的job作业都会共享这些固定的资源 。当集群的资源不足,新提交的任务可能会失败。当一个TaskManager执行的job作业过多的时候,若是某一个作业导致TaskManager宕机,已经提交的但尚未完成的job都会收到影响。
缺点:
资源共享会导致很多问题,比如死锁问题。
特点:
只适合当个规模小、执行时间短的大量作业 。
2、单作业模式(Per-Job Mode)
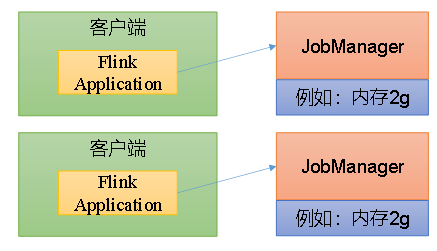
工作模式:
单作业模式为flink client提交的每个作业单独启动一个集群,即一个作业一个集群,由客户端提交应用程序,然后启动集群,提交作业给jobmanger进行分发给taskmanager执行。job作业完成的时候,集群也会随之关闭。这样,即使是某一个job出错导致TaskManager宕机,也不会影响到其他job作业的运行。
该模式在生产环境运行更加稳定,是实际应用的首选模式。
注意:Flink 本身无法直接这样运行,所以单作业模式一般需要借助一些资源管 理框架来启动集群,比如 YARN、Kubernetes(K8S)。
3、应用模式(Application Mode)
需要为每一个提交的应用单独启动一个 JobManager,也就是创建一个集群。这 个 JobManager 只为执行这一个应用而存在,执行结束之后 JobManager 也就关闭了,这就是所 谓的应用模式
三个模式比较:
会话模式和单作业模式的应用代码都是在flink client上提交,有客户端提交给jobmanger。但是,这种方式客户端需要占用大量的网络带宽,去下载依赖和二进制数据发送给jobmanger,并且提交客户用的是一个指定节点,因此会加重消耗该节点的资源,严重会影响宕机。
单作业模式和应用模式的比较:
单作业模式是通过客户端来提交 的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由 JobManager 执行应 用程序的,并且即使应用包含了多个作业,也只创建一个集群。
--------------------------------------------------------------------------
Flink 任务停止后,JobManager 会将已经完成任务的统计信息进行存档,History Server 进程则在任务停止后可以对任务统计信息进行查询。比如:最后一次的 Checkpoint、任务运行时的相关配置。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号