
Algo在文件中查找冗余数据
我有一个二进制文件,其中一个记录被多次重复。该文件仅由此记录组成,但可能重复多次。
我不知道唱片有多大。提取记录并知道重复次数的最佳算法是什么?
例如,假设我有一个文件,其内存表示为十六进制。(忽略文件头和所有内容)
3F5C BA 3F5C BA 3F5C
在这里,我的记录是3F5CBA,3字节,在这里重复15次。
如何获得这些值(记录的大小及其重复次数)。可以使用Rabin Karp完成,但有没有其他更好和有效的方法来做到这一点。

回答 3
Stack Overflow用户
发布于 2015-12-22 11:35:12
一种可能是获取文件的大小并对其进行因子分析。例如,如果文件大小为1280,则您知道记录大小为下列之一:
1,2,4,5,8,10,16,20,32,40,64,80,128,160,256,320,640,1280然后,你可以测试每一个假设,直到你找到一个匹配或用尽的可能性。
当然,这假定文件没有被截断或以其他方式损坏。
这可能不是最有效的方法,但它的编码速度很快,而且可以非常快地完成您的任务。这取决于您的文件有多大,以及您想要这样做的频率。有时,蛮力解决方案是正确的解决方案,即使它不是“最好的”解决方案。
Stack Overflow用户
发布于 2015-12-22 11:54:02
您可以查看后缀树,可以将字符串的所有后缀插入后缀树中,并计算某个子字符串发生的次数,然后执行树遍历并找到答案。
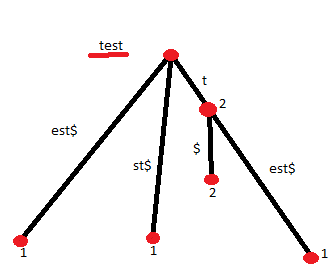
Stack Overflow用户
发布于 2015-12-22 13:40:27
- 首先假设记录的长度
l为1 - 通过比较随后所有大小为
l的块,检查您的假设是否正确。一旦你发现不匹配就停止。 - 如果没有发现错配,您就完成了。回去吧。
- 搜索长度为
l的块的下一个匹配项。这给了另一个候选记录长度。如果下一个匹配块开始于索引i(基于零),则设置l = i并转到步骤2。
如果您知道总是有一个解决方案,您可能会稍微加快步骤2。如果你检查了50%的数据,你可以停止。
注:这个答案假设您正在寻找最短的可能记录。例如,如果您的所有字节都是FF,则可以找到许多其他解决方案,而不是l=1 (例如,只有一个大记录)。
示例:从大小为1的记录开始,在您的例子中是3F。然后通过检查所有后续字节是否也是3F来检查这是否是完整的记录。您可以停止使用下一个字节,因为它不同。现在寻找下一个3F。它发生在索引3(以零为基础)。现在您知道您的记录至少有3个字节长。假设您的记录有3个字节长。检查随后的三个字节块是否与您的记录匹配。完成了!
https://stackoverflow.com/questions/34422810
复制








腾讯云开发者
