老八股谈事务处理,到底在谈什么?


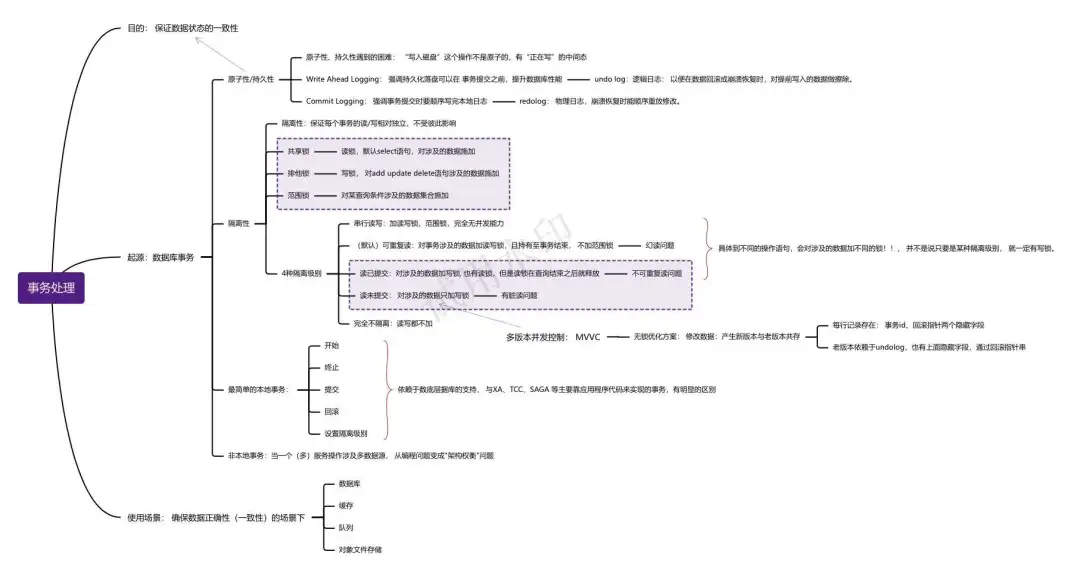
1. 事务处理的目标:数据状态的一致性
当我们谈事务处理,就是在谈确保数据状态的一致性Consistency。
一致性: 确保数据是正确的,不同数据间不会产生矛盾 (这里的一致性与分布式共识算法中的一致性概念不一样)。
事务最早源自数据库系统,为达成数据库状态的一致性C Consistency, 需做三个方面的努力:
- 原子性 Atomic
- 隔离性 Isolation
- 持久性 Durability
故可以看到ACID并非正交,AID是手段,目的是C, 拼凑的4字单词带来的误解已经超过容易传播的好处。
事务的场景:虽最早起源自数据库,但今天所有需要确保数据正确性的系统(包括不限于 数据库、缓存、队列、对象存储)都会涉及事务处理。
2. 传统数据库的本地事务
本地事务是最基础的事务,不涉及使用全局事务协调器的事务。
事务相关的动作: 开始、结束、提交、回滚、设置隔离级别有赖于底层数据库支持,与XA、TCC、SAGA依靠应用程序代码实现不同。
原子性和持久性
遇到的问题: “写入磁盘” 并不是原子的,有“正在写”的中间态。
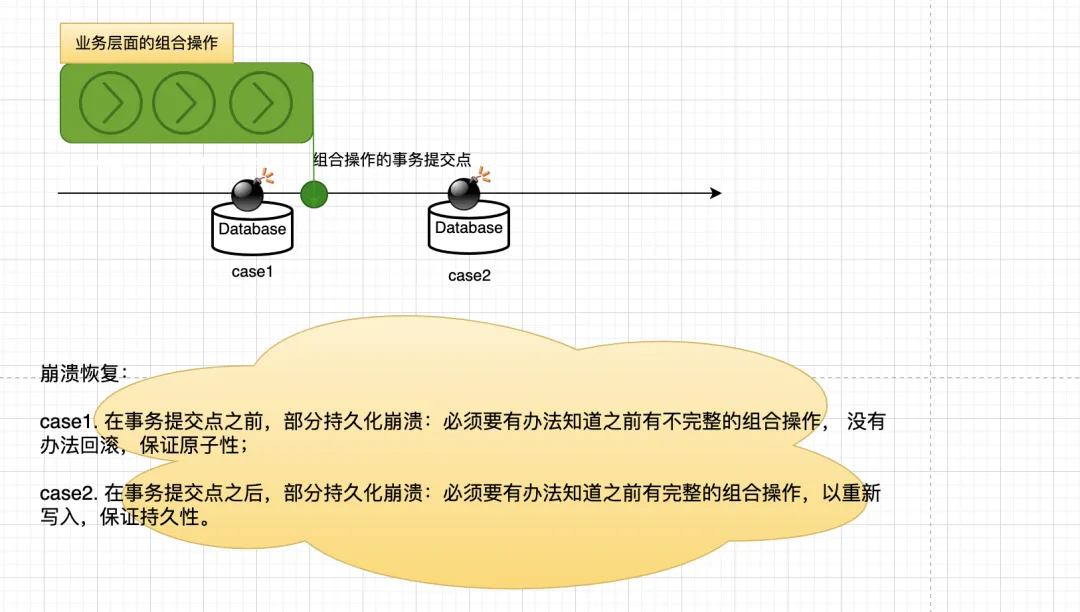
业务上的操作组合与数据库的落盘行为在不同的时空维度,因数据库崩溃恢复的时机,导致数据库难以做到业务逻辑自洽的数据一致性。
2.1 Commit Logging强调事务提交要顺序写日志
- 将修改数据的全部信息(哪个页、磁盘、从什么修改成什么)记录到磁盘日志(顺序写)
- 见到事务成功提交的“commit record”,数据库才会根据日志信息持久化落盘
- 修改完成之后,在日志中加入一条“end record”,表示事务已经完成持久化。
事务日志的生成就是事务提交的关键点,代表性的有阿里的Oceanbase, 但是有一个巨大的问题,所有对数据的真实修改都必须发生了事务提交之后, 这对提升数据库性能不利。
2.2 Write Ahead Logging强调持久化落盘可在事务提交之前
undolog 出现了。
当变动数据写入磁盘前,写明修改了哪个数据,从什么改成什么。 以便在数据回滚或崩溃恢复时,可以根据undolog 日志对提前写入的数据进行擦除。
- 分析阶段: 从事务日志中找出“不包含end record”的日志, 作为待恢复的事务集合
- 重做阶段: 从以上待恢复事务集合中,找出“含有commit record”的事务日志,这一部分已经写完事务日志,可以重做
- 回滚阶段: 以上剩下的事务日志,不包含commit record,说明事务日志还没有写完,这部分需要回滚,根据事务日志id到undolog中找到逻辑日志开始回滚。
redolog: 物理日志
undolog: 逻辑日志
隔离性
保证每个事务各自读写的数据相对独立,不会彼此影响。
读操作(select): 默认共享锁(S锁), 除非显式 for update, 允许多个事务施加读锁,持有后阻止施加写锁。
写操作(update delete add): 排它锁(X锁),持有时其他事务不能再施加读写锁,其他事务也不能写。
范围锁: 某种查询条件内的范围数据被加排他锁。
这里面有两个时机: 施加锁、 具体读写
持有锁的释放时机 决定了隔离级别。
- 串行读: 加读写锁,范围锁,无并发能力----
- 可重复读: 加读写锁且持有至事务结束,不加范围锁---有幻读问题,两次相同的范围查询的数据集不一样
- 读已提交: 加读写锁,但读锁在查询之后即释放,不加范围锁--- 不可重复读问题,两次读取某数据可能不一样
- 读未提交:加写锁,完全不加读锁--- 幻读问题,读到了另一个事务未提交的数据。
这里我的误区:

上图这个读已提交的例子,两次读的事务1并没有写锁,并不会阻止其他事务2写入。
事务的隔离级别: 定义了各种锁在不同加锁时间上的组合。
事务的隔离效果: 事务的隔离级别 + 具体的操作语句(决定涉及的数据会用上哪些锁)
MVCC
针对“一个事务读,另一个事务写”, 有多版本并发控制(multi- verison-concurrency-control)。
无锁优化方案: 对数据的任何修改,都不会直接覆盖之前的数据,而是产生新版本与老版本共存。
mysql的实现: 每行记录有事务id、回滚指针两个隐藏字段, 每次修改形成的旧版本(依赖undolog)也有这隐藏字段,通过回滚指针串起来。
每个事务开启时创建自己的ReadView视图。
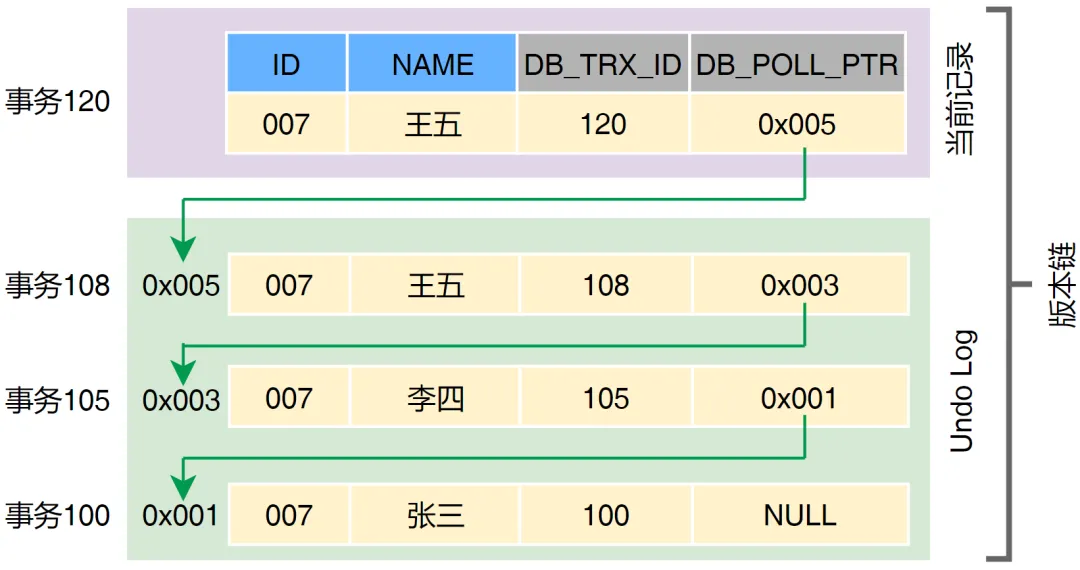
可重复度、读已提交依赖于MVCC来实现。
可重复读: 读取事务id小于等于当前事务id的最大版本的数据;
读已提交: 读取最新版本的数据
That's All, 这是我对《周志明的软件架构课》中有关本地事务的读书笔记,记录了
- 事务的本质,AID确保数据状态一致性C
- 传统数据库的本地事务的演进: Commit Logging、Write Ahead Logging
- 数据库事务隔离级别的本质: 不同锁在不同作用时长的组合结果。
- 针对”一个事务读,一个事务写“的隔离级别,有MVCC来实现。
《周志明的架构课》在极客时间上是免费阅读,读完思考后对很多八股文都有醍醐灌顶的感觉,强烈推荐。
参考资料
[1]
周志明的软件架构课: https://time.geekbang.org/column/article/319481
本篇文字和图片均为原创,读者可结合图片探索源码, 欢迎反馈 ~。。~。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号