Notepad++将搜索内容所在行选中,并进行复制等操作


背景
Notepad++在非常多的数据行内容中,按照指定内容检索,并定位到具体行,而后对内容行的数据进行复制、剪切、删除等处理动作。
操作说明
检索并标记所在行
- 弹出搜索框:按下 Ctrl + F。
- 输入查找字符串:在搜索框中输入要查找的字符串。
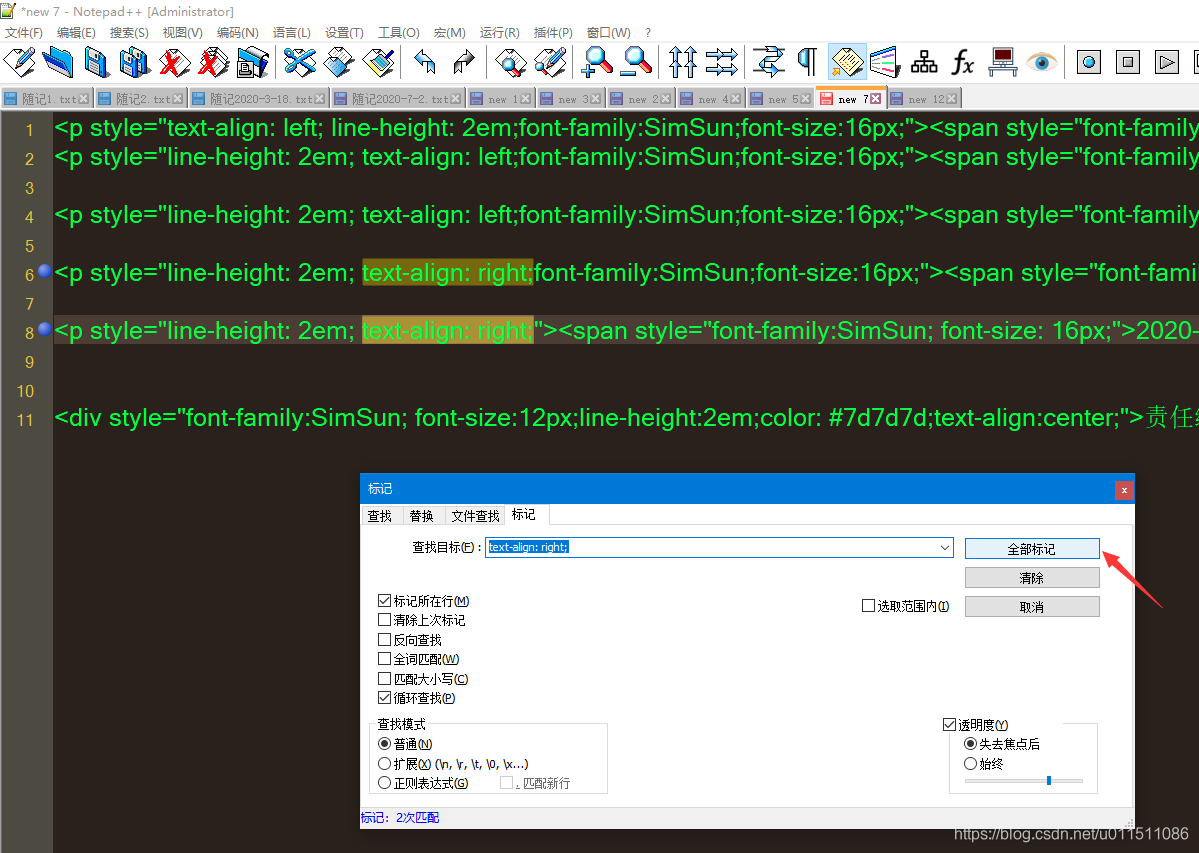
- 标记记录:
- 在查找框顶部菜单中选择【标记】。
- 在标记栏的右侧点击【全部标记】。这时,所有找到的记录会被高亮显示,并在左侧出现蓝色圆点。
检索并标记所在行
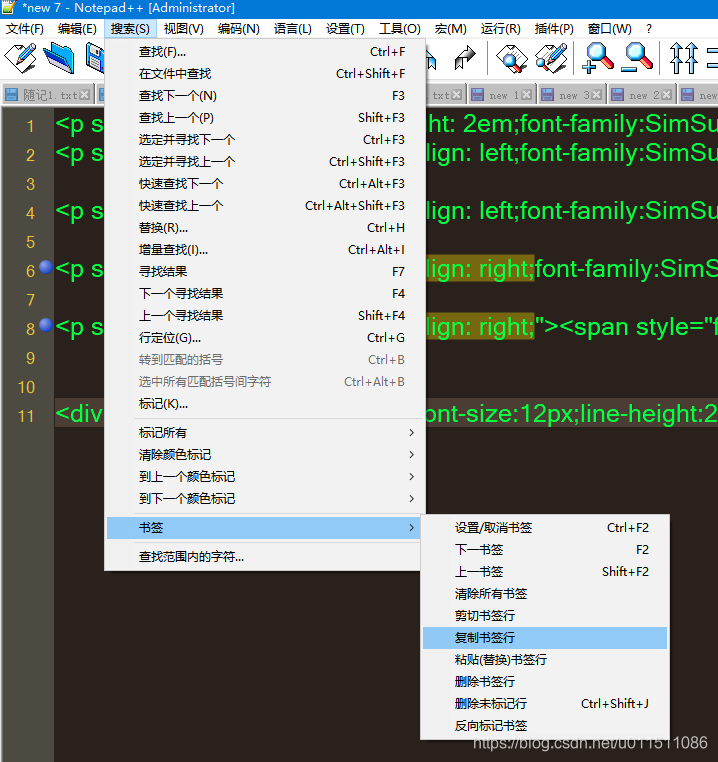
- 复制标记行:
- 在 Notepad++ 的菜单栏中选择:搜索 → 书签 → 复制书签行。
- 将复制的内容粘贴到新建的文本框中。
本篇文章如有帮助到您,请给「翎野君」点个赞,感谢您的支持。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-10-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号