【源头活水】ECCV2024|DepictQA: 图像质量感知多模态语言模型

【源头活水】ECCV2024|DepictQA: 图像质量感知多模态语言模型

马上科普尚尚
发布于 2024-07-29 10:35:49
发布于 2024-07-29 10:35:49
“问渠那得清如许,为有源头活水来”,通过前沿领域知识的学习,从其他研究领域得到启发,对研究问题的本质有更清晰的认识和理解,是自我提高的不竭源泉。为此,我们特别精选论文阅读笔记,开辟“源头活水”专栏,帮助你广泛而深入的阅读科研文献,敬请关注!
项目主页:https://depictqa.github.io DepictQA-v1 (ECCV2024) :https://arxiv.org/abs/2312.08962 DepictQA-v2 (arXiv, preprint) :https://arxiv.org/abs/2405.18842 代码 (包括训练推理与数据集构造代码):https://github.com/XPixelGroup/DepictQA 数据集:https://huggingface.co/datasets/zhiyuanyou/DataDepictQA
为什么会做这个项目?
图像质量感知是一个宏大而复杂的课题。比如:
- 图像是细节越多越好吗?
并不是。很多人都会喜欢湛蓝纯净的天空。因此,在飘了一些淡淡的云彩的天空中加入blur,使得天空的颜色更加均匀,人看起来反而更好看。
- 失真一定会带来低质量吗?
并不是。如下图所示,右图是在左图的基础上添加噪声得到的。但是在这种情况下,噪声可以使手部皮肤看起来更加真实,而左图则显得过度平坦化。在这种情况下,噪声使图像更加真实。
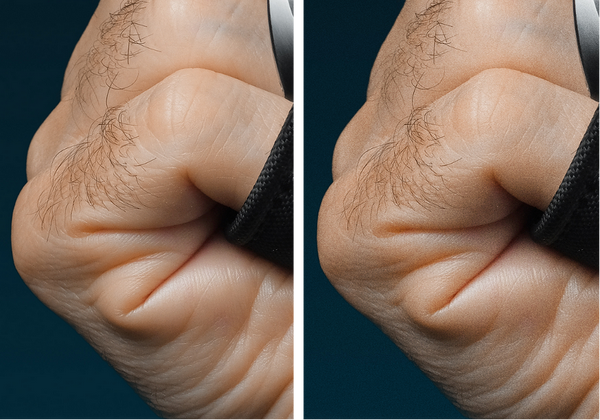
很容易发现,图像质量感知与图像的局部内容是强相关的,甚至是与个人的喜好强相关的。
那么,如何刻画如此复杂的质量感知呢?
现有的图像质量评价 (IQA) 方法使用score来描述图像质量,可以直接用于对比不同模型的性能,被广泛地作为metric或者loss使用,促进了图像生成、修复等领域的发展。但是,score这种描述形式是图像质量感知的一个综合的方面,其表达能力的上限是不足的,无法刻画复杂的局部性和内容相关性。
在大语言模型 (LLM) 和多模态语言模型 (MLLM) 出现后,我们希望语言成为描述图像质量感知这个复杂问题的工具,这也是这一系列工作的初衷。
TL;DR
- DepictQA是基于多模态语言模型 (MLLM) 的图像质量感知方法。我们希望借助MLLM,对图像质量进行类似于人类的、基于语言的描述。
- DepictQA-v1。为了验证MLLM感知图像质量的可行性,我们 (1) 构造了full-reference下的任务框架,(2) 构建了一个包括 大量的、简短的、模版化的构造数据 + 少部分的、详细的、人工标注的数据 组成的数据集,(3) 训练了一个MLLM,验证了MLLM感知图像质量的可行性。
- DepictQA-v2。在可行性验证之后,我们希望拓展模型的适用范围,进行了 (1) 任务框架的拓展 (任务类型从3种到8种),(2) 数据集的scaling up (detail数据从5K到56K),实现了 (3) 在自然图像上具有一定的泛化性。


Motivation: Score-based质量感知方法的局限性
现有的图像质量感知方法主要是score-based方法。这些方法输出一个score来描述图像质量,可以用于对比不同模型的性能,被广泛地作为metric或者loss使用,促进了图像生成、修复等领域的发展。
虽然取得了如此巨大的成功,我们认为score的描述形式限制了更深层次的质量感知。
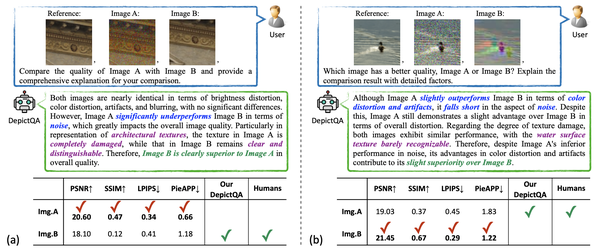
- 首先,图像质量包括了很多的因素,这些因素无法通过一个简单的score有效表达,例如图3中的噪声、色彩失真和伪影等。
- 其次,score无法模拟人类的感知过程。例如,在图3(b)中,人类一般首先识别图像的失真(即图像A中的噪声、图像B中的色彩失真和伪影),然后权衡这些失真对内容表达的影响(图像B中的色彩失真和伪影比图像A中的噪声更严重),最后得出结论 (图像A比图像B更好) 。但是,简单地对比score来判断好坏无法反应出人类复杂的感知过程。
最近,以ChatGPT为代表的大语言模型 (LLM) 将深度学习带入了大模型时代,随之出现的多模态大语言模型 (MLLM) 可以使用语言对图像的内容进行详细的描述。因此,我们希望探究基于MLLM、使用语言对于图像质量进行描述的方法。

DepictQA-v1
任务定义
我们建立了一个包括三个任务的任务框架。
- 质量描述。模型应该能够感知图像失真。如图5(a),给出参考图像和一张失真图像,模型需要描述失真图像中的失真和纹理损伤,并判断失真图像的整体质量。
- 质量对比。模型应该能直接对比两张图像的好坏。如图5(b),给出参考图像和两张不同的失真图像,模型需要确定哪一张失真图像的质量更好。
- 对比归因。模型应该能对两张图像的好坏进行判断并归因。如图5(c),模型需要描述两张失真图像的失真和纹理损伤,并推理权衡利弊,对比图像质量的好坏。该任务是质量描述和质量对比的综合。
数据收集
- 人工标注选项 + GPT-4语言化
在DepictQA-v1收集数据时,GPT-4V等强多模态模型还没有出现。我们设计了人工标注选项 + GPT-4语言化的数据策略。如图5所示,我们设计了由选择题构成的问卷,标注员标注问卷后,GPT-4将问卷的标注结果组合成语言,由此构造图像文本对。
大量的、简短的、模板化回答 + 少部分的、详细的回答
人工标注数据是详细的,但是费时费力获取难度大。因此,我们将已有的包含score的数据集转化为文本,构造大量的、简短的、模版化的数据。比如,图像A的score比图像B高,可以转化为"Image A maintains a better quality than Image B"。将模版化数据 + 详细数据混合训练,对于对比精度和归因准确性都有一定提升。
模型训练
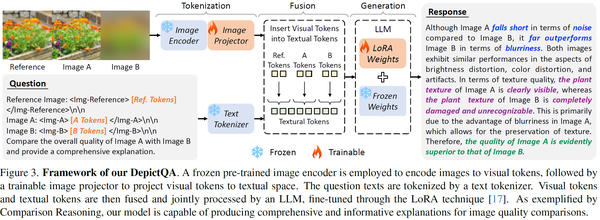
如图6所示,我们采用了LLaVA框架,包括image encoder、image projector、LLM三部分。
- 区分多张图像
LLaVA的输入是单张图像,而我们涉及到多张图像。如何让模型区别多张图像是十分重要的。我们测试了4种区分多种图像的方法,并根据结果选择了textual hint + tag hint的方法。
- 加入high-level数据作为正则化
质量相关的描述语言是单一的,包括的独立词汇量偏少。仅仅用这些数据训练,模型存在过拟合、说套话、重复说话的问题。因此,我们在训练过程中加入了LAMM引入的COCO详细描述数据作为正则化。
实验结果
- 在双图对比、多图对比 (双图对比的拓展) 上,超越了经典的score-based方法。
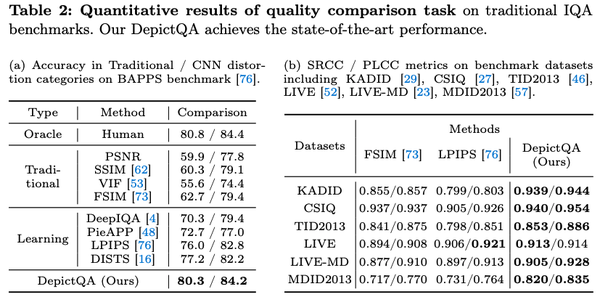
- 在质量描述和对比归因上,通用MLLMs不具有质量感知能力,而DepictQA-v1体现出了一定的质量感知能力。
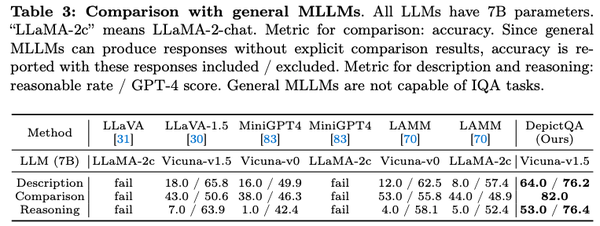
DepictQA-v2
任务定义
DepictQA-v1主要关注了full-reference设置下的3种任务。在DepictQA-v2中,我们对任务定义进行了拓展,从3种任务扩展到8种任务,提出了一个多任务的框架。如图7所示,拓展后的任务框架包括了单图评估和双图对比两大类任务,每类任务都包括了brief和detail两个子任务,支持full-reference和non-reference设置。

数据收集
- 更全面的自然图像。我们选择了KADIS-700K作为高质量图像的来源,一共包括了140K的高质量图像。
- 更全面的失真类型。我们构建了一个全面的失真库,包括了35种失真类型,每种类型包括了5个等级。
- 更大尺度的数据量。我们将detail数据从DepictQA-v1的5K扩增到了56K,相应地,brief的数据也扩增到了440K。
- 更合理的数据生成。在构造DepictQA-v2的数据集时,GPT-4V等强多模态模型已经出现。Co-Instruct直接采用了GPT-4V构造数据。虽然GPT-4V具有强大的内容识别、逻辑推理能力,但是其失真识别、质量对比能力都是不足的。因此,如图8所示,我们提出ground-truth-informed生成方法,将失真识别和质量对比的结果直接加入GPT-4V的prompt中,提升了生成数据的质量。
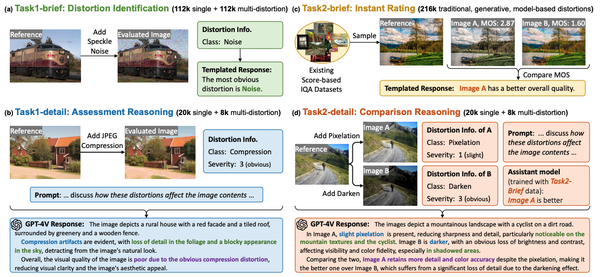
模型训练
我们采用了DepictQA-v1的模型架构。
- 图像分辨率的适应。由于图像的分辨率以及比例也是质量的重要部分,我们提出对于clip image encoder的位置编码进行差值,而保留图像的原始分辨率和比例。
- 置信度的计算。MLLM的response缺乏一个良好的置信度。我们提取了response中的key tokens,计算了key tokens的预测概率作为置信度。
实验结果
- 在失真识别上,超越了通用MLLMs、以及已有的MLLM-based质量感知模型。
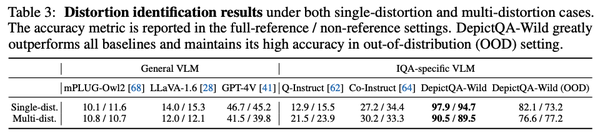
- 在直接对比上,超越了score-based方法、通用MLLMs、以及已有的MLLM-based质量感知模型。
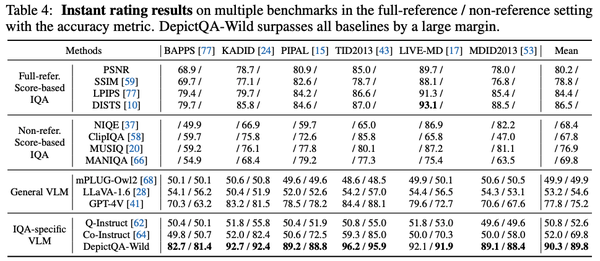
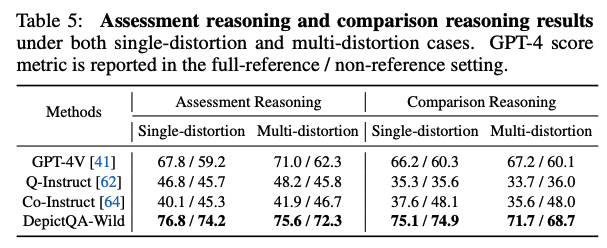
- 在评估归因和对比归因上,超越了通用MLLMs、以及已有的MLLM-based质量感知模型。
- 在web下载的真实图像上也体现出较好的泛化性。

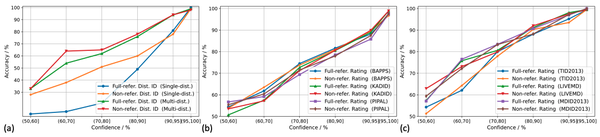
- 模型预测的置信度与模型性能的一致程度非常高。
不足与未来的工作
在这两篇工作中,我们展示了使用MLLMs描述图像质量的可能性。但是,MLLM-based图像质量感知模型的落地应用仍有很长的路要走。
- 数据的数量和覆盖范围不足,限制了模型的泛化性能。尽管DepictQA-v2已经进行了数据集的scaling up,但是对于非自然图像,其泛化性能依然不足。
- MLLM-based方法的应用不像score-based方法那么自然。Score可以被直接对比选择更优的模型,但语言不能被直接对比。Score也可以被用作loss优化模型,但语言目前还不具有这种特性。因此,质量感知的语言能否被输入生成模型或者修复模型用于质量提升,还需要进一步的探索。
本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。
收藏,分享、在看,给个三连击呗!本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-07-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号