AI办公自动化:用通义千问批量翻译长篇英语TXT文档

AI办公自动化:用通义千问批量翻译长篇英语TXT文档

AIGC部落
发布于 2024-06-24 20:02:02
发布于 2024-06-24 20:02:02
在deepseek中输入提示词:
你是一个Python编程专家,现在要完成一个编写基于qwen-turbo模型API和dashscope库的程序脚本,具体步骤如下:
打开文件夹:F:\AI自媒体内容\待翻译;
获取里面所有TXT文档;
读取TXT文档内容;
将每个TXT文档的内容作为输入,并在调用API时附加提示语“翻译成中文”,API Key为:XXX,model为qwen-turbo;
接收API返回的结果,并将其保存到在同一文件夹中,文件标题名为原txt文件标题名加上“翻译”,文档格式为txt文档;
注意:
每一步都要打印相关的信息;
根据API的限流和请求要求,合理安排任务的发送频率,避免触发API的速率限制;
要有错误处理和调试信息,这有助于找出问题所在;
请求的输入长度范围应当在[1, 6000]之间,如果超长,需要对TXT内容分拆成多份,使单个输入内容不超过6000个字符,然后再一个个发送至API,接收API返回的结果,将之前分拆的内容按顺序整合在一起。;
在读取文件时跳过那些以"翻译.txt"结尾的文件,避免递归地处理同一个文件夹下的所有文件,包括已经生成的翻译文件;
在文件的开始处添加以下导入语句:from http import HTTPStatus;
在将某个部分的结果拼接到翻译结果列表时,可能会出现预期的字符串类型与实际的类型不匹配,确保在拼接翻译结果列表时,列表中的每个元素都是字符串类型;
API 返回是JSON 对象,其中包含了文本内容,需要对 JSON 对象进行解析,以提取出 text 字段中的文本内容。
qwen-turbo模型API的使用方法,请参照下面这个例子:
from http import HTTPStatus
import dashscope
def sample_sync_call():
prompt_text = '用萝卜、土豆、茄子做饭,给我个菜谱。'
resp = dashscope.Generation.call(
model='qwen-turbo',
prompt=prompt_text
)
# The response status_code is HTTPStatus.OK indicate success,
# otherwise indicate request is failed, you can get error code
# and message from code and message.
if resp.status_code == HTTPStatus.OK:
print(resp.output) # The output text
print(resp.usage) # The usage information
else:
print(resp.code) # The error code.
print(resp.message) # The error message.
sample_sync_call()
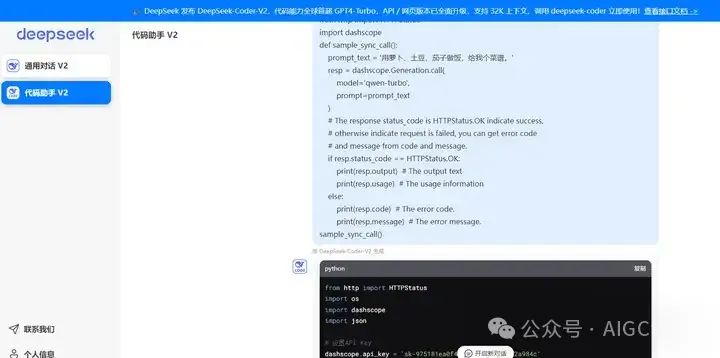
Deepseek生成的源代码:
from http import HTTPStatus
import os
import dashscope
import json
# 设置API Key
dashscope.api_key = 'XXX'
def translate_text(text):
prompt_text = f"翻译成中文: {text}"
resp = dashscope.Generation.call(
model='qwen-turbo',
prompt=prompt_text
)
if resp.status_code == HTTPStatus.OK:
return resp.output['text']
else:
print(f"Error: {resp.code} - {resp.message}")
return None
def process_file(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
if len(content) > 6000:
# Split content into chunks
chunks = [content[i:i+6000] for i in range(0, len(content), 6000)]
translated_chunks = []
for chunk in chunks:
translated_chunk = translate_text(chunk)
if translated_chunk:
translated_chunks.append(translated_chunk)
else:
print(f"Failed to translate chunk from file: {file_path}")
return
translated_content = ''.join(translated_chunks)
else:
translated_content = translate_text(content)
if translated_content:
translated_file_path = file_path.rsplit('.', 1)[0] + '翻译.txt'
with open(translated_file_path, 'w', encoding='utf-8') as translated_file:
translated_file.write(translated_content)
print(f"Translated file saved: {translated_file_path}")
else:
print(f"Failed to translate file: {file_path}")
def main():
folder_path = 'F:\\AI自媒体内容\\待翻译'
for filename in os.listdir(folder_path):
if filename.endswith('.txt') and not filename.endswith('翻译.txt'):
file_path = os.path.join(folder_path, filename)
print(f"Processing file: {file_path}")
process_file(file_path)
if __name__ == "__main__":
main()
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-19,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 Dance with GenAI 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号