SciPy 稀疏矩阵(5):CSR

SciPy 稀疏矩阵(5):CSR

不可言诉的深渊
发布于 2024-06-13 19:31:34
发布于 2024-06-13 19:31:34
“
上回说到 LIL 格式的稀疏矩阵的 rows 属性和 data 属性是一个其元素是动态数组的数组。其在内存中的存储方式为一个外围定长数组的元素是指向对应动态数组的基地址的指针。这一回,我们需要把这样的指针给消去。然而,仅仅是为什么要消去就是一个很复杂的问题,复杂到完全不能直接回答。因此,首先我需要针对 CPU 访问内存数据的过程外加上程序的局部性原理这两个基础的背景知识进行讲解。
”
part 01、CPU 访问内存数据的过程
BETTER LIFE
在现代计算机体系中,CPU(中央处理器)访问内存数据的过程是一个精心设计且高效协同的流程。当 CPU 需要读取或写入数据时,它会首先查看距离自己最近且访问速度最快的寄存器。寄存器是 CPU 内部的高速存储单元,能够迅速响应 CPU 的读写需求。如果所需数据正好存储在寄存器中,即发生“命中”,CPU 将直接获取数据,无需进行进一步访问,极大地提升了数据处理的效率。若寄存器中没有所需数据,CPU 则会转向访问缓存(通常是 CPU 内部的 L1、L2 甚至 L3 缓存)。缓存是介于寄存器和主内存之间的存储层次,其访问速度虽然较寄存器慢一些,但相较于主内存来说仍然非常快。当 CPU 在缓存中命中所需数据时,它会直接从缓存中获取,避免了访问速度较慢的主内存。最后,如果 CPU 在寄存器和缓存中均未找到所需数据,它才会转向访问主内存。主内存是计算机系统中容量较大、但访问速度相对较慢的存储区域。CPU 通过内存控制器与主内存通信,发送读写请求并等待响应。一旦从主内存中获取到所需数据,CPU 会将其加载到缓存或寄存器中,以便后续快速访问。整个过程中,一旦在任一层次发生命中,CPU 就会直接获取数据并停止进一步的访问,从而优化了数据处理流程,提高了计算机的整体性能。
在计算机系统设计中,采用存储结构分层而非大量使用寄存器的原因,主要源于成本、效率以及技术实现的考量。首先,寄存器虽然速度快,但其数量有限且成本高昂,若大量使用会显著增加硬件成本。其次,分层存储结构能够更有效地管理数据访问的优先级,将经常访问的数据存储在高速存储器中,而将不常访问的数据放在速度较慢但成本较低的存储器中,从而平衡了速度与成本的关系。此外,分层存储结构也便于数据的分级保护和管理,不同层级的数据具有不同的访问权限和安全性,有助于维护系统的安全性和稳定性。因此,按存储速度给存储结构分层而非简单增加寄存器数量,更符合计算机系统设计的实际需求。
当然,不使用大量的缓存原因同上,但是这样做有一个新的问题:如何定义外加上管理数据访问的优先级?这就要说到程序局部性原理了。
part 02、程序的局部性原理
BETTER LIFE
在编程领域中,程序局部性原理是一个至关重要的概念。它主要指的是在程序执行过程中,某段时间内访问的存储位置,其在不远的将来很大概率上仍会被再次访问。这一原理在计算机科学的多个领域,如操作系统、缓存设计、内存管理等方面,都有着广泛的应用。程序局部性原理可以分为时间局部性和空间局部性两种。这种原理不仅有助于我们理解程序的运行方式,还为我们优化程序的性能提供了有力的理论支持。通过合理利用程序局部性原理,我们可以显著提高程序的执行效率,从而提升用户体验和系统性能。
时间局部性
在计算机科学的世界中,程序的时间局部性原理是一个核心概念,它深刻揭示了程序运行过程中的一种重要特性。简而言之,时间局部性原理指的是如果一个信息项被访问过一次,那么在未来它很可能再次被访问。这种特性在程序执行过程中尤为显著,因为程序往往会在一段时间内重复访问某些数据或执行某些操作。这种时间局部性原理对于优化程序性能和提高系统效率具有重要意义。通过利用时间局部性,我们可以预测程序的行为,从而采取更有效的缓存策略、预取技术和数据布局优化。例如,在 CPU 缓存设计中,根据时间局部性原理,可以将最近访问过的数据或指令存储在缓存中,以便在需要时快速访问,从而避免从主存中读取数据所带来的延迟。此外,时间局部性原理还对于操作系统的任务调度、文件系统的数据组织以及数据库索引的设计等方面具有重要的指导作用。因此,深入理解和应用时间局部性原理,不仅有助于提高单个程序的性能,还有助于提升整个系统的效率和响应速度。
空间局部性
在程序设计和优化中,空间局部性原理是一个核心概念,它揭示了程序在执行过程中访问数据的一种重要模式。简而言之,空间局部性原理指的是如果一个程序在某一时刻访问了某个存储单元,那么在不久的将来,其附近的存储单元也很可能被再次访问。这一原理深刻影响着计算机的内存管理、缓存设计以及程序的性能优化。它指导着开发者如何更有效地利用有限的内存资源,通过预先加载或缓存可能即将被访问的数据,来提高程序的运行效率。因此,深入理解并应用空间局部性原理,对于提升软件性能和用户体验具有十分重要的意义。
part 03、为何需消去 LIL 外层数组的指针
BETTER LIFE
故事还得从矩阵乘向量说起,矩阵乘向量的操作逻辑非常的简单,把矩阵看成一个有序的行向量组,首先有序的行向量组中第 1 个行向量和右乘的向量做内积运算(对应位置相乘再相加)得到结果向量中的第 1 个数,然后首先有序的行向量组中第 2 个行向量和右乘的向量做内积运算得到结果向量中的第 2 个数,以此类推。
我们显然可以发现 LIL 格式的稀疏矩阵进行该操作效率非常高,因为不同于 COO 格式的稀疏矩阵外加上 DOK 格式的稀疏矩阵获取某一行数据需要扫描整个稀疏矩阵的非零元素信息,LIL 通过把稀疏矩阵看成是有序的稀疏行向量组并对这些稀疏行向量进行压缩存储。因此,获取 LIL 格式的稀疏矩阵中的某一行(第 i 行)的非零元素的列索引和元素值只需要分别访问 rows 属性(数组)第 i 个元素(动态数组)和 data 属性(数组)的第 i 个元素(动态数组),根本不需要扫描所有的非零元素信息。
然而,LIL 格式的稀疏矩阵并不是最适合进行矩阵乘向量操作的稀疏矩阵格式,它还有优化空间。我们都知道,在计算机中进行矩阵向量乘法的时候,矩阵和向量都在内存中,然而计算机的运算是在 CPU 中,因此不可避免的会频繁地出现 CPU 访问内存的操作。为了避免 CPU 频繁地访问内存拖慢速度,我们需要借助程序的空间局部性原理把当前访问的内存地址以及周围的内存地址中的数据复制到高速缓存或者寄存器(如果允许的话)。
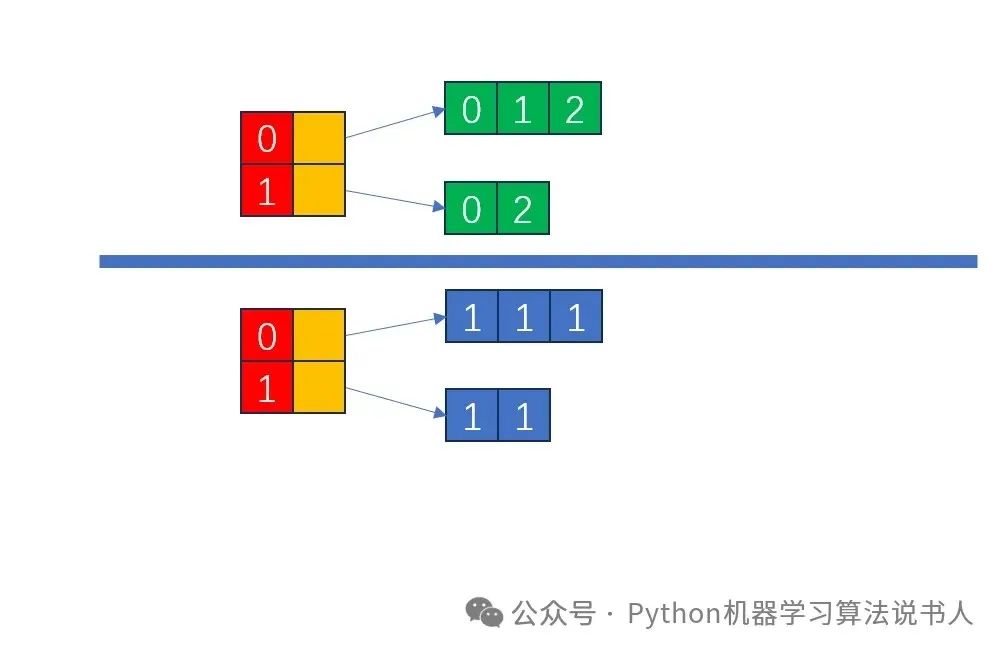
如图所示,我们可以发现 LIL 格式的稀疏矩阵虽然可以快速获取某一行的信息,但是它任意相邻两行的非零元素的列索引以及对应元素值并不是存储在一段连续的内存空间中,换句话说就是当缓存中的第 i 行非零元素的信息即将用完的时候,缓存更新为第 i 行的倒数一部分的元素以及后面一段根本无法访问的内存地址,根本不是第 i+1 行非零元素的信息。当然,在绝大多数情况下是这样,有极少数情况并不是这样,比如有着非常小的概率缓存更新为第 i 行的倒数一部分的元素以及一小段根本无法访问的内存地址再接第 i+1 行的前面一部分元素,只是这样的概率非常非常非常小,我们还是以考虑绝大多数情况为主。很明显在绝大多数情况下,LIL 格式的稀疏矩阵在进行矩阵乘向量操作的时候,每次用完一行数据有着非常大的概率缓存中无法找到下一行数据,导致缓存命中率非常低,进而频繁地出现 CPU 访问内存操作。
为了避免这种情况,我们需要把相邻两行的列索引和元素值放在一段连续的内存空间中,只有这样,当第 i 行数据即将用完的时候,第 i+1 行才会有非常大的概率在缓存中,从而可以充分利用缓存,降低 CPU 访问内存的次数。因此,消去 LIL 外层数组的指针是非常有必要的。
part 04、如何消去 LIL 外层数组的指针
BETTER LIFE
一种简单的方法是把多个动态数组首尾相连拼成一个一维数组,然而,仅仅把上述两个属性这么去拼是不正确的,因为这么做会丢失矩阵的行信息,为了不丢失矩阵的行信息,我们还需要一个数组(记作 indptr),这个数组的第 i 个元素表示第 i 行在拼接后的一维数组的起始位置(当然也可以表示第 i 行在拼接后的一维数组的终点位置,这里以起始位置为例进行操作)。
显然,以上图为例进行操作,得到的新数据结构如图所示。
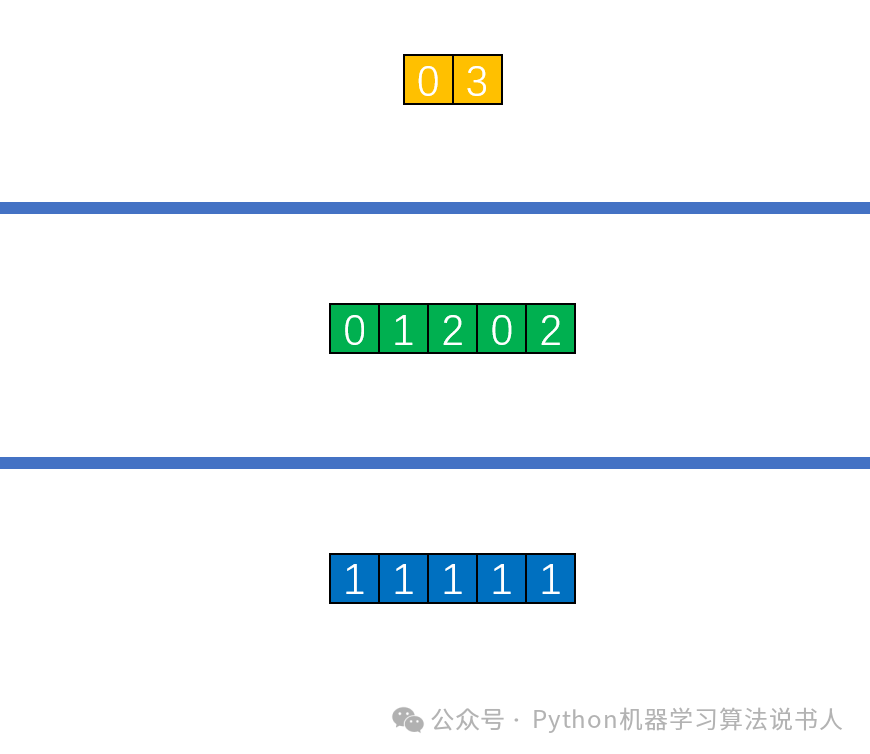
其中,从最上面开始依次是新出现的 indptr 数组、变换后的 rows 属性(记作 indices)以及变换后的 data 属性(记作 data)。
part 05、SciPy CSR 格式的稀疏矩阵
BETTER LIFE
SciPy CSR 格式的稀疏矩阵就是如上图所示的新数据结构,属性名也是一样的,唯一的不一样只有一个,就是 indptr 属性(数组)最后多出了一个元素,该元素表示非零元素的个数,其他完全一样。最后需要注意的有 2 点:第一,indptr、indices 外加上 data 这 3 个属性都是 NumPy 一维数组;第二,indices 并不要求块内有序,简单地说就是我假设 indices 从第 p 个元素到第 q 个元素(p<q)表示第 i 行的非零元素列索引,这一段元素并不要求它是从小到大排序,就比如说上图中的 indptr=[0, 3, 5](修正过后,最后一个元素表是非零元素个数),indices=[0, 1, 2, 0, 2],我们把 indices 改成 [1, 0, 2, 0, 2](交换前两个元素)也是可以的,data 也要跟着交换前两个元素,在这里交换前后没有变化。 之所以这种格式叫做 CSR,是因为 CSR 是 Compressed Sparse Row 的缩写。
实例化
SciPy CSR 格式的稀疏矩阵类的定义位于 scipy.sparse 包中的 csr_matrix 类,对其进行实例化就能获取一个 SciPy CSR 格式的稀疏矩阵的实例。当然,构造实例的方法主要有 5 种:
- csr_matrix(D):D 是一个普通矩阵(二维数组)。
- csr_matrix(S):S 是一个稀疏矩阵。
- csr_matrix((M, N), [dtype]):会实例化一个 M 行 N 列元素类型为 dtype 的全 0 矩阵。dtype 是一个可选参数,默认值为双精度浮点数。
- csr_matrix((data, (row_ind, col_ind)), [shape=(M, N)]):data 是非零元素值,row_ind 是非零元素行索引,col_ind 是非零元素的列索引,shape 是矩阵的行列数(M 行 N 列),默认会通过非零元素行索引外加上非零元素列索引进行推断。
- csr_matrix((data, indices, indptr), [shape=(M, N)]):第 i 行非零元素的列索引是 indices[indptr[i]:indptr[i+1]],对应的非零元素值存储在 data[indptr[i]:indptr[i+1]],shape 是矩阵的行列数(M 行 N 列),默认会通过 indices 和 indptr 进行推断。
案例
实例化一个 3 行 4 列元素类型为 8 位有符号整数的全 0 矩阵:
>>> import numpy as np
>>> from scipy.sparse import csr_matrix
>>> csr_matrix((3, 4), dtype=np.int8).toarray()
array([[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]], dtype=int8)通过元素值序列、行索引序列以及列索引序列来实例化一个 3 行 3 列元素值为 32 位有符号整数的稀疏矩阵:
>>> row = np.array([0, 0, 1, 2, 2, 2])
>>> col = np.array([0, 2, 2, 0, 1, 2])
>>> data = np.array([1, 2, 3, 4, 5, 6])
>>> csr_matrix((data, (row, col)), shape=(3, 3)).toarray()
array([[1, 0, 2],
[0, 0, 3],
[4, 5, 6]], dtype=int32)通过第 5 种实例化方法实例化一个稀疏矩阵:
>>> indptr = np.array([0, 2, 3, 6])
>>> indices = np.array([0, 2, 2, 0, 1, 2])
>>> data = np.array([1, 2, 3, 4, 5, 6])
>>> csr_matrix((data, indices, indptr), shape=(3, 3)).toarray()
array([[1, 0, 2],
[0, 0, 3],
[4, 5, 6]])依旧是通过元素值序列、行索引序列以及列索引序列来实例化一个 3 行 3 列元素值为 32 位有符号整数的稀疏矩阵,只不过这次我们看看相同的行列索引重复出现会怎样:
>>> row = np.array([0, 1, 2, 0])
>>> col = np.array([0, 1, 1, 0])
>>> data = np.array([1, 2, 4, 8])
>>> csr_matrix((data, (row, col)), shape=(3, 3)).toarray()
array([[9, 0, 0],
[0, 2, 0],
[0, 4, 0]], dtype=int32)显然,重复的行列索引把对应值相加,这和 COO 格式的稀疏矩阵处理方式完全一样。
循序渐进的构造 CSR 格式的稀疏矩阵的案例——从文本中构建一个 term-document 矩阵:
>>> docs = [["hello", "world", "hello"], ["goodbye", "cruel", "world"]]
>>> indptr = [0]
>>> indices = []
>>> data = []
>>> vocabulary = {}
>>> for d in docs:
... for term in d:
... index = vocabulary.setdefault(term, len(vocabulary))
... indices.append(index)
... data.append(1)
... indptr.append(len(indices))
...
>>> csr_matrix((data, indices, indptr), dtype=int).toarray()
array([[2, 1, 0, 0],
[0, 1, 1, 1]])下面我详细解释这段代码,前面 5 行的赋值语句直接跳过,从第 6 行开始。
第 1 次外层 for 循环,第 1 次内层 for 循环:d = ["hello", "world", "hello"],term = "hello",vocabulary = {"hello": 0},index = 0,indices = [0],data=[1],indptr=[0]。
第 1 次外层 for 循环,第 2 次内层 for 循环:d = ["hello", "world", "hello"],term = "world",vocabulary = {"hello": 0, "world": 1},index = 1,indices = [0, 1],data=[1, 1],indptr=[0]。
第 1 次外层 for 循环,第 3 次内层 for 循环:d = ["hello", "world", "hello"],term = "hello",vocabulary = {"hello": 0, "world": 1},index = 0,indices = [0, 1, 0],data=[1, 1, 1],indptr=[0, 3]。
第 2 次外层 for 循环,第 1 次内层 for 循环:d = ["goodbye", "cruel", "world"],term = "goodbye",vocabulary = {"hello": 0, "world": 1, "goodbye": 2},index = 2,indices = [0, 1, 0, 2],data=[1, 1, 1, 1],indptr=[0, 3]。
第 2 次外层 for 循环,第 2 次内层 for 循环:d = ["goodbye", "cruel", "world"],term = "cruel",vocabulary = {"hello": 0, "world": 1, "goodbye": 2, "cruel": 3},index = 3,indices = [0, 1, 0, 2, 3],data=[1, 1, 1, 1, 1],indptr=[0, 3]。
第 2 次外层 for 循环,第 3 次内层 for 循环:d = ["goodbye", "cruel", "world"],term = "world",vocabulary = {"hello": 0, "world": 1, "goodbye": 2, "cruel": 3},index = 1,indices = [0, 1, 0, 2, 3, 1],data=[1, 1, 1, 1, 1, 1],indptr=[0, 3, 6]。
最后还是通过第 5 种实例化方法实例化一个稀疏矩阵,但是这里很明显和之前不一样的地方就是它第 1 行的列索引存在重复,出现了 2 次 0,在这里处理的方式是把一行中重复列索引的对应值相加,和 COO 格式的稀疏矩阵差不多。当然,该实例的 indptr 属性、indices 属性、data 属性就是之前获取的 3 个同名列表,根本不做重复相加等化简操作。如何进行重复相加等化简操作只需要调用 sum_duplicates() 方法,调用该方法不仅会把重复的列索引的对应值相加,还会把同一行的列索引按从小到大的顺序排好。然而,这个方法并不完美,特别是当重复的列索引的对应值相加之后正好为 0,它根本不会自动去掉这样的零元素,删除零元素还需调用 eliminate_zeros() 方法。这 2 个方法都是原地操作,无返回值。现在方法有了,怎么消除零元素以及重复的列索引无非就是两个方法的调用顺序的问题。显然我们应该先消除重复的列索引,再消除零元素。反过来之所以不行是因为可能存在重复 2 次的列索引,一个地方元素值为 1,另一个地方元素值为 -1,显然它们都不是 0,所以先消除零元素不能把它们消去,然后消除重复的列索引把它们加在一起又出现了零元素。
最后我们以矩阵乘向量为例做一个性能测试,矩阵分别采用 LIL 格式和 CSR 格式,来看看 CSR 格式的稀疏矩阵相较于 LIL 格式的稀疏矩阵是否能够更充分地利用缓存。需要注意的是我们不去直接调用内部封装的方法,因为内部封装的方法会在执行之前先把 LIL 格式转化为 CSR 格式再调用 CSR 格式的方法,典型的牺牲空间换取时间,我们当然需要在同样的空间复杂度(在这里是 O(1),换句话说就是除了输入输出变量以外,中间的变量仅占用常数个存储单元)进行公平比较。因此,我们需要自己实现两种格式的稀疏矩阵的矩阵乘向量操作,这一点也不难,只需要继承 SciPy 中对应格式的稀疏矩阵类并重写 _mul_vector 方法就可以了,代码如下所示。
from scipy.sparse import csr_matrix, lil_matrix
from time import time
import numpy as np
class CSRMatrix(csr_matrix):
def _mul_vector(self, other):
ind_ptr, indices, data, rs = self.indptr, self.indices, self.data, self._shape[0]
result = np.zeros(rs, dtype='uint8')
for i in range(rs):
s, e = ind_ptr[i], ind_ptr[i+1]
cs, vs = indices[s:e], data[s:e]
for j in range(cs.shape[0]):
result[i] += vs[j]*other[cs[j]]
return result
class LILMatrix(lil_matrix):
def _mul_vector(self, other):
rows, data, rs = self.rows, self.data, self._shape[0]
result = np.zeros(rs, dtype='uint8')
for i in range(rs):
cs, vs = rows[i], data[i]
for j in range(len(cs)):
result[i] += vs[j]*other[cs[j]]
return result
np.random.seed(0)
a, b = np.random.randint(2, size=(1000, 255), dtype='uint8'), np.random.randint(2, size=255, dtype='uint8')
csr, lil = CSRMatrix(a), LILMatrix(a)
start = time()
csr@b
end = time()
print('csr time:', end-start)
start = time()
lil@b
end = time()
print('lil time:', end-start)
运行结果如图所示。
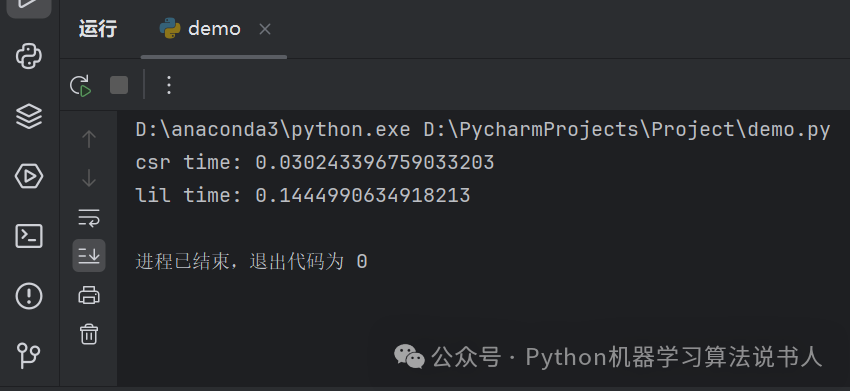
从运行结果可以很明显的发现 CSR 格式的稀疏矩阵做矩阵向量乘法的性能要优于 LIL 格式的稀疏矩阵做矩阵向量乘法的性能,这验证了我们之前的理论分析。
优缺点
SciPy CSR 格式的稀疏矩阵有着以下优点:
- 进行算术操作的性能非常高效。
- 进行行切片操作的性能非常高效。
- 进行矩阵乘向量运算的操作非常迅速。
当然,SciPy CSR 格式的稀疏矩阵也有缺点:
- 进行列切片操作的性能非常低下。
- 对其修改矩阵元素的代价非常高昂。
part 06、下回预告
BETTER LIFE
不同于 LIL 格式的稀疏矩阵把相邻两行的非零元素的列索引和元素值存储在内存的不同位置,CSR 格式的稀疏矩阵中相邻两行的非零元素的列索引和元素值在内存中是紧密相连的,这在进行矩阵乘向量的操作的时候可以充分提高缓存的命中率,有效降低 CPU 访问内存的次数,提高了矩阵乘向量的操作效率。
但是我们可以发现 LIL 格式和 CSR 格式都是把稀疏矩阵看成有序稀疏行向量组,然后对行向量组中每一个行向量进行压缩存储。学过线性代数的人都非常地清楚,矩阵不仅可以看成是有序行向量组,还可以看成是有序列向量组。因此,稀疏矩阵不仅可以看成是有序稀疏行向量组,还可以看成是有序稀疏列向量组。我们完全可以把稀疏矩阵看成是有序稀疏列向量组,然后模仿 LIL 格式或者是 CSR 格式对列向量组中的每一个列向量进行压缩存储。然而,模仿 LIL 格式的稀疏矩阵格式 SciPy 中并没有实现,大家可以尝试自己去模仿一下,这一点也不难。因此,下回直接介绍模仿 CSR 格式的稀疏矩阵格式——CSC 格式。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-11,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 Python机器学习算法说书人 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号