INT量化的原理与核心概念


INT指 低精度整型数据格式, 以INT8为例,它用8个比特(0和1)来存储一个数,有256种(即2的8次方)可能的取值。
zero point
而量化是将模型原本用高精度浮点数(如FP32)表示的参数和计算,转换为INT8这类低精度整数的过程,这是一个“压缩”手段,能让模型体积更小、运行更快,同时尽量不损失精度。
下面这张对比表直观地理解FP32与INT8的差异:
数据类型 | 存储方式 | 存储空间 | 取值范围 | 硬件支持 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
FP32 | 单精度浮点数 | 4字节 | ±3.4e38 | 通用性强,几乎所有硬件都支持 | 精度高,数值表达范围大 | 占内存多,计算速度相对较慢 |
INT8 | 8位整数 | 1字节 | -128 ~ 127 | 依赖专用硬件加速指令集(如NVIDIA GPU的Tensor Cores) | 内存占用减少75%,计算速度可提升2-4倍 | 精度有损失,可能存在精度溢出或截断误差 |
PART 01
量化的原理
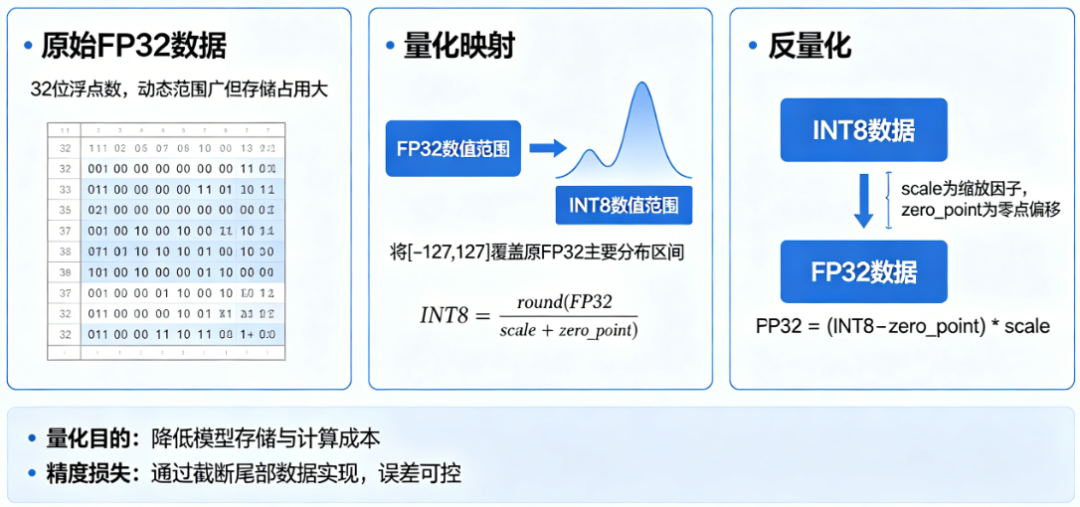
量化将一个FP32的张量(一个多维数组)映射到INT8的整数空间,这个映射过程主要靠以下三个核心概念:
- Scale (缩放因子) :决定将FP32值的范围“压缩”到INT8的 [-128, 127] 区间时,每一步的步长是多少,可以想象成用一把更“粗糙”的尺子去量物体。
- Zero Point (零点) :为了对齐数值范围,把FP32中的“0”映射到INT8中对应的某个整数。
- Clipping (截断) :超出INT8表达范围的极值会被直接截断,这是精度损失的主要来源之一。
整个量化的过程,简单来说分为三步:
- 确定范围 :通过校准过程,用一个小的代表性数据集(如500-1000个样本)来统计模型每一层的数据分布,确定量化的最小值(min)和最大值(max)。
- 计算映射 :根据确定的范围,计算出每个张量的 和 。
- 执行映射 :将每个FP32数值应用公式 ,转换成INT8整数,这个过程会不可避免地引入精度损失。
scale
PART 02
主流量化方案
根据模型量化阶段的不同,主要分为以下两种方案,各有侧重。
训练后量化 (Post-Training Quantization, PTQ)
PTQ是在模型训练完成后,直接对已训练好的模型进行量化,这种方法 无需重新训练 ,实现速度快。
- 适用场景 :快速上线、资源有限的场景,或在精度要求不是极致苛刻的任务中作为初步尝试。
- 优缺点 :实现简单、速度快,但在高精度要求的任务上,精度损失可能较明显。
- 常见实现 :
- W8A16(权重量化) :仅对模型权重进行INT8量化,激活值保持为FP16。优点是几乎无损,实现简单,缺点是内存节省和加速效果有限。
- W8A8(权重与激活量化) :对模型权重和激活值都进行INT8量化。优点是压缩和加速效果最大化;缺点是精度损失更明显,对校准数据依赖度高。
量化感知训练 (Quantization-Aware Training, QAT)
QAT是在模型训练或微调的过程中, 提前“模拟”量化带来的误差 ,让模型在低精度环境下学习,从而主动适应并弥补这种精度损失。
- 适用场景 :对模型精度有苛刻要求的任务,如医疗影像诊断、自动驾驶感知等。
- 优缺点 :精度损失最小,效果通常最优。但实现更复杂,需要修改训练代码和流程,训练时间更长。
- 注意事项 :
- 通常需要在 微调阶段 进行,而非从头训练。
- 通常有 额外的超参数 (如模拟量化噪声的强度)需要调整。
- 由于模型已适应量化,QAT模型在推理时通常比PTQ模型 对输入数据的微小变化更不敏感 ,稳定性更好。
PART 03
常见量化格式
常见的量化数据格式及其特点整理如下:
数据格式 | 存储空间 | 优点 | 缺点 | 典型应用 |
|---|---|---|---|---|
FP32 | 4字节 | 精度高,数值范围广 | 内存占用高,计算速度慢 | 模型训练 |
FP16/BF16 | 2字节 | 精度较高,内存占用适中 | 相比INT8加速效果有限 | 模型推理、混合精度训练 |
INT8 | 1字节 | 内存占用减少75%,计算速度可提升2-4倍 | 精度有损失 | 模型推理、边缘端部署 |
INT4 | 0.5字节 | 内存占用极低 | 精度损失更大 | 模型推理、极端压缩场景 |
目前量化方法主要以INT8和INT4为主,随着硬件发展,FP8、FP4等格式也在逐渐兴起。
PART 04
硬件注意事项
不同的硬件对量化的支持程度差异巨大,直接决定了量化后的模型能否真正跑起来。
NVIDIA GPU (主流平台)
- INT8支持 :几乎所有配备Tensor Cores的GPU都支持INT8,包括Turing(如RTX 20系)、Ampere(如RTX 30/A100)和Ada(如RTX 40/H100)架构。
- Blackwell架构警告 :最新的Blackwell架构GPU(如B100/B200) 不支持INT8 ,需要使用FP8格式替代。
Intel CPU
INT8量化主要依赖 VNNI(Vector Neural Network Instructions) 指令集加速。此技术从 第3代至强可扩展处理器 起得到支持。
AMD GPU / 其他硬件
部分推理框架(如vLLM)对AMD GPU的INT8支持尚不明确,需要确认具体框架版本。
特定硬件(如Google TPU、AWS Inferentia、Qualcomm Hexagon DSP)对INT8量化的支持差异很大,部署前务必仔细查阅相关文档。
PART 05
软件注意事项
主流框架及工具链
- PyTorch :通过 模块提供静态、动态和QAT量化能力。可使用 或 NVIDIA ModelOpt 进行高级量化。
torch.quantization
torch.ao.quantization
- ONNX Runtime :支持将量化模型转换为ONNX格式,以便在多种硬件后端上部署。
- TensorFlow Lite :支持动态范围量化和全整数量化,专为移动端和边缘设备优化。
PART 06
实践建议
- 使用代表性校准数据 : 校准数据必须能代表真实部署场景 。如果对模型进行了微调,建议使用微调用的训练数据进行校准,效果会更好。
- 优先选择静态量化 :静态量化在推理时更快,适合结构固定的模型(如CNN);动态量化更适合激活值范围变化大的模型(如Transformer)。
- 务必验证量化后精度 :量化后必须在代表性数据集上评估性能,对比量化前后的精度差异,确保损失在可接受范围内。
PART 07
总结
综合来看,INT8量化压缩术,关键在于在 模型精度、运行效率和实现成本 之间找到最佳平衡。
评估维度 | 方案一:训练后量化 (PTQ) | 方案二:量化感知训练 (QAT) |
|---|---|---|
研发投入 | 低 | 中高 |
精度损失 | 较小 | 极小(通常<1%) |
实施复杂度 | 低(无需重新训练) | 中高(需修改训练流程) |
项目周期 | 数小时至数天 | 数天至数周 |
最佳实践 | 快速原型验证、资源受限场景 | 高精度要求的任务(如医疗、自动驾驶) |
对于 VLA清洁机器人项目 ,如果追求 快速落地和资源效率 ,PTQ通常是更合适的起点,如果后续发现精度无法满足清洁要求,再考虑切换到QAT方案。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号