IBM计算存储:SSD如何加速十亿级向量搜索?

IBM计算存储:SSD如何加速十亿级向量搜索?

数据存储前沿技术
发布于 2026-03-09 17:36:45
发布于 2026-03-09 17:36:45
阅读收获
- 深入理解计算型存储(Computational Storage)在AI向量数据库领域的具体落地路径,特别是IBM VSM如何通过FPGA重构SSD,实现物理感知的数据布局和固件优化,为设计下一代高性能存储系统提供硬件级创新思路。
- 洞察AI基础设施投资的新趋势,认识到在特定大规模RAG场景下,计算型存储SSD在成本效益(TCO)和能效比上超越传统GPU方案的潜力,为评估相关技术公司的市场前景提供新视角。
- 掌握向量相似度搜索“精度、速度与成本”三角制约的最新解决方案,了解DiskANN、HNSW等算法在硬件加速下的演进,以及“近数据计算”如何解决“内存墙”和“IO墙”问题,为存储系统、AI硬件加速等研究方向提供前沿案例。
- 明确IBM VSM在IVF场景下的性能特征和适用条件,理解高并发、批处理对计算型存储利用率的关键影响,从而在设计大规模RAG或推荐系统时,更好地选择和优化底层存储方案。
全文概览
在AI大模型时代,RAG(检索增强生成)和语义搜索已成为挖掘非结构化数据价值的核心。然而,当向量数据量激增至数十亿级别时,您是否正面临传统全内存向量索引方案的容量与成本困境?昂贵的DRAM和数据在CPU与存储间频繁搬运造成的“内存墙”与“IO墙”瓶颈,正严重制约着AI应用的规模化落地。
IBM的最新探索,为这一挑战提供了颠覆性答案。他们将标准SSD重构为专用的向量搜索加速卡——Vector Search Module (VSM),通过“计算型存储”理念,直接在存储层并行执行向量搜索。这不仅彻底解决了海量向量数据无法在内存中承载的问题,更在硬件层面实现了距离计算和Top-K排序的全卸载。这种存算一体的架构,究竟如何打破传统瓶颈,实现十亿级向量数据的亚毫秒级检索?它又将如何重塑我们对AI基础设施的认知,为大规模RAG应用带来前所未有的性能与成本效益?本文将深入剖析IBM VSM的底层设计与实战表现。
👉 划线高亮 观点批注
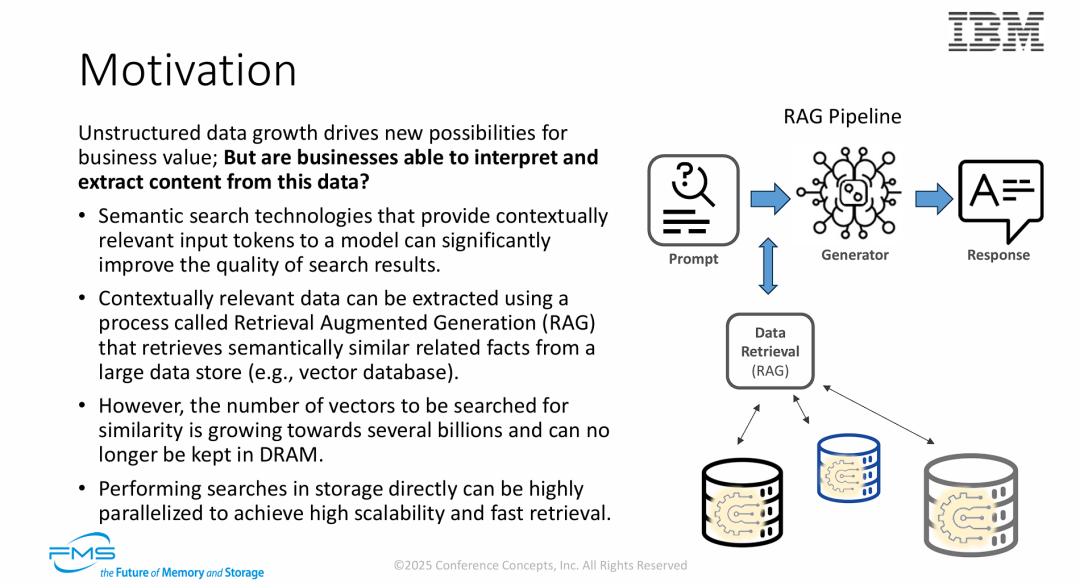
图片的核心观点在于论证将向量搜索从内存(DRAM)下沉到存储(Storage)的必要性,主要包含以下逻辑:
- 业务驱动: RAG 和语义搜索是挖掘非结构化数据价值的关键技术。
- 技术瓶颈: 随着向量数据量激增至数十亿级别,传统的全内存(In-Memory)向量索引方案在容量和成本上已不可行(DRAM 放不下)。
- 架构演进: 为了解决扩展性问题,未来的趋势是利用近数据计算(或存储内计算) 技术,直接在存储层并行执行向量搜索,以实现高吞吐和低延迟的大规模检索。

图片的核心观点是定义向量相似度搜索的技术原理及其通用性:
- 数据即向量(Embeddings): 任何非结构化数据(文本、图片、生物序列)都可以被转化为高维数学向量。
- 相似即距离(Proximity): 搜索的核心机制是计算向量之间的空间距离。语义相似的事物(如猫和狗,或者苹果公司和谷歌)在向量空间中距离更近。
- 广泛的行业相关性: 这种存储和检索技术不仅仅用于生成式 AI(RAG),还是生物信息学(DNA、药物研发)、多媒体检索和风控安全(异常检测)等关键领域的底层基础设施。这进一步佐证了为何存储系统需要针对此类负载进行专门优化的重要性。
向量相似度空间概念,为后续 NAND 管理上的 Sub-clusters提供了数学基础。
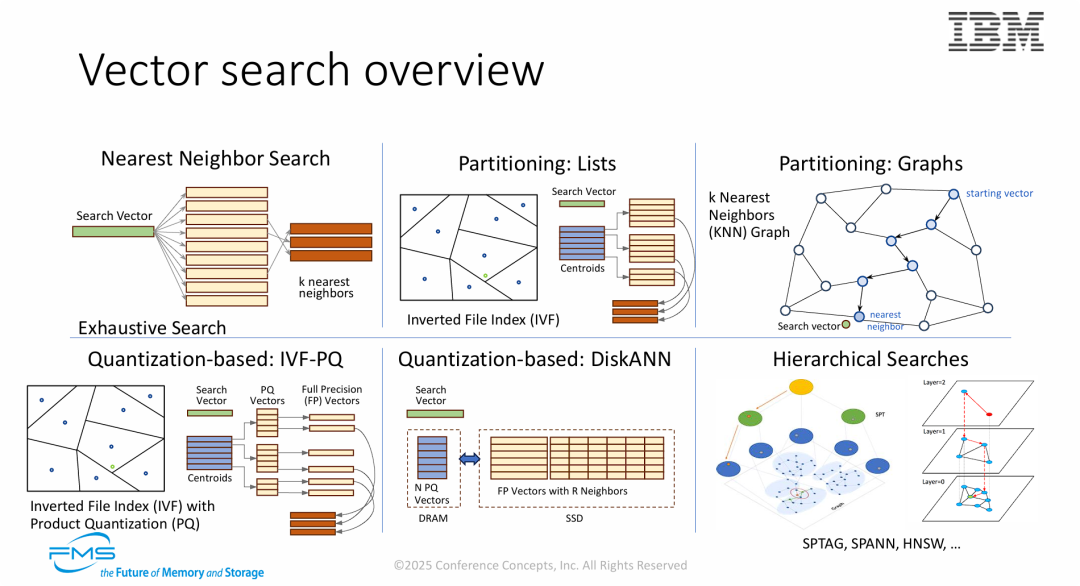
图片的核心观点是展示向量索引技术如何通过算法演进,解决“精度、速度与成本”的三角制约,特别强调了存储介质在其中的角色变化:
- 从暴力到索引: 为了应对大规模数据,技术从线性扫描(Exhaustive)演进为空间划分(IVF)和图遍历(Graphs)。
- 从内存到磁盘(DiskANN): 图片明确提出了 DiskANN 架构,证明了高性能向量搜索不再局限于昂贵的 DRAM。通过内存缓存压缩索引 + SSD 存储全量数据的混合模式,企业可以使用低成本的闪存存储来承载海量 AI 知识库。
- 技术栈多样性: 现代 AI 存储系统不能只支持一种算法,而需要混合使用量化(PQ)、分层图(HNSW)和磁盘卸载(DiskANN)技术,以在有限的硬件资源下实现最佳的 RAG 检索性能。
===
技术类别 | 具体技术 (Technology) | 核心机制 (Mechanism) | 存储与内存特征 (Storage & Memory Profile) | 优势与局限 (Pros & Cons) |
|---|---|---|---|---|
1. 最近邻搜索 | Exhaustive Search (暴力/穷举搜索) | 全量扫描:将搜索向量与库中所有向量逐一比对。 | 存储密集/IO密集:需要读取全部数据。若数据在磁盘,IO压力极大;若在内存,占用极大。 | ✅ 精度最高 (100% Recall) ❌ 不可扩展,随着数据量增加,延迟呈线性增长,无法用于大规模生产。 |
2. 分区:列表法 | IVF (Inverted File Index) | 空间划分:利用 Voronoi 图将空间划分为多个区域(聚类),只搜索最近的几个中心点区域。 | 访问优化:减少了需要访问的数据块,不再需要全量读取。 | ✅ 速度快于暴力搜索,通过缩小范围减少计算。 ❌ 边界点的召回率可能下降(即漏掉分界线附近的邻居)。 |
3. 分区:图算法 | kNN Graph | 图遍历:数据点互联成图,从起点沿着边跳转,逐步逼近最近邻。 | 随机访问:搜索过程涉及大量的内存随机访问(Pointer chasing)。 | ✅ 搜索效率极高,适合内存场景。 ❌ 构建图极其耗时,且图结构需要大量内存来存储边关系。 |
4. 基于量化 | IVF-PQ (Product Quantization) | 有损压缩:结合 IVF 分区,并将高维全精度向量压缩(量化)为低精度短向量。 | 内存优化:显著降低内存占用(通常可压缩 10-100 倍),允许在内存中存更多数据。 | ✅ 极高的吞吐量和内存效率。 ❌ 精度损失,量化过程会丢失部分向量信息,导致搜索结果不如全精度准确。 |
5. 基于量化 | DiskANN (重点关注) | SSD/内存混合:DRAM 存压缩导航图,SSD 存全量高精度向量和邻居表。 | 分层存储:利用 SSD 的大容量替代昂贵的 DRAM。打破了“内存容量墙”。 | ✅ 极致的成本效益,单机可支撑十亿级向量规模,且保持较高性能。 ❌ 延迟略高于纯内存方案,依赖高性能 NVMe SSD。 |
6. 分层搜索 | Hierarchical (HNSW, SPANN等) | 多层导航:类似跳表结构。上层稀疏图用于快速定位,下层稠密图用于精细查找。 | 内存换速度:除了存数据,还需要存储多层索引结构,内存开销通常较大。 | ✅ 目前最快的算法之一,对数级复杂度 ()。 ❌ 内存消耗大,不适合超大规模数据全内存部署。 |

通过对比表格展示了 IBM 现有的标准存储模块(Flash Core Module, FCM)与新的向量搜索模块(VSM)在架构设计上的核心差异,右侧则展示了具体的硬件电路板实物图
图片揭示了 IBM 在存储技术上的一个重大创新方向——“计算型存储(Computational Storage)”在 AI 领域的落地。其核心观点如下:
- 硬件重定义: IBM 利用 FPGA 的可编程性,将一块标准的 SSD(FlashCore Module)“变身”为专用的向量搜索加速卡(VSM)。
- 以计算为中心的设计: VSM 的设计完全背离了传统存储“追求容量和压缩”的逻辑,转而采用SLC 模式、全内存映射表、无压缩对齐存储等策略。这种设计不惜牺牲存储密度,只为换取极致的向量检索速度和低延迟。
- 解决数据搬运瓶颈: 通过在 SSD 内部直接处理数十亿级别的向量搜索,避免了将海量数据搬运到主机内存(DRAM)的过程,彻底解决了大模型时代 RAG 应用面临的 Memory Wall(内存墙) 问题。这是对前几张 PPT 中提到的“DRAM 放不下”问题的最终硬件解决方案。
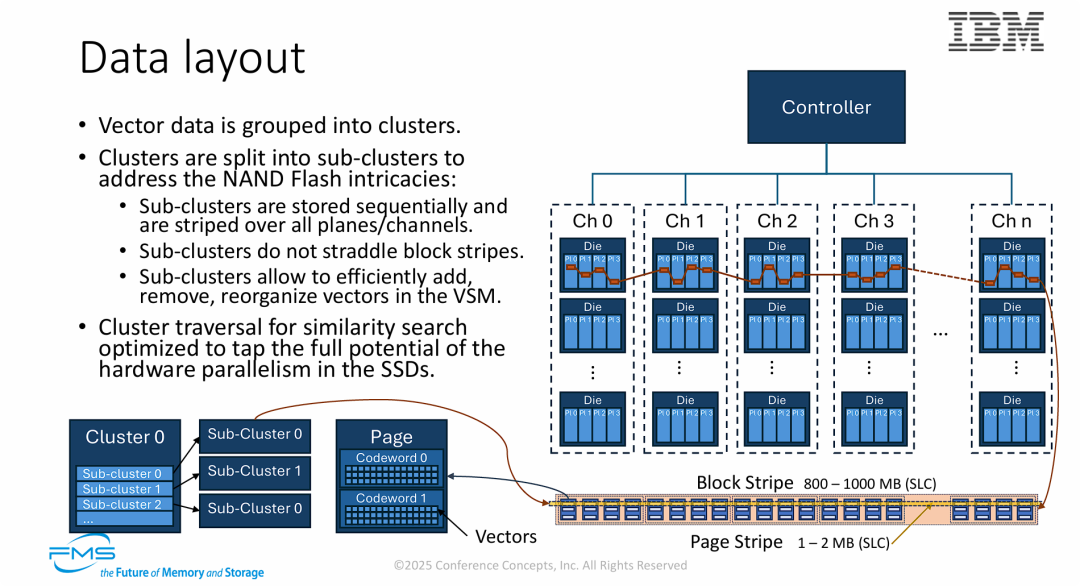
图片的核心观点在于展示 "软硬结合的极致优化",解释了 VSM 如何通过物理感知的数据布局(Hardware-aware Data Layout) 来榨取 SSD 的性能:
- 最大化并行度(Parallelism): 通过将向量数据的 Sub-clusters 条带化(Striping)到所有的 Channel 和 Die 上,VSM 确保了在进行相似度搜索时,能够同时激活所有 Flash 芯片。这使得内部读取带宽最大化,解决了传统存储中 I/O 瓶颈的问题。
- 适配 Flash 物理特性: 数据结构的设计充分尊重了 NAND Flash 的物理限制(如 Block 边界、Page 大小)。不跨越块条带(No straddling)的设计避免了读写放大,并优化了垃圾回收(GC)和数据更新的效率。
- 为计算而生的布局: 这种布局不是为了存文件,而是为了配合前序 PPT 提到的算法(如遍历聚类中心)。数据在物理上的连续性和对齐,保证了 FPGA 在扫描向量时能获得稳定且极高的流式吞吐量。

图片深入探讨了 VSM 如何在固件层面管理数据地址映射和空间回收,这是确保持续高性能读写的关键机制。
展示 IBM 如何为了适配 AI 向量负载而重构 SSD 的底层固件逻辑:
- 消除元数据瓶颈: 通过将 LPT 映射粒度变粗(从 4KB 变为 Sub-cluster),将元数据表缩小了 3500 倍并锁定在 DRAM 中。这彻底消除了传统大容量 SSD 在随机读取时常见的 LPT 加载延迟,保证了向量搜索的确定性低延迟。
- 智能的数据生命周期管理: 引入 Skip Lists(跳表) 技术来处理向量数据的增删改。这是一种典型的“用计算换 I/O”策略,允许在粗粒度的存储块中高效地管理细粒度的向量删除,避免了频繁的读写放大(Write Amplification),从而延长了 SSD 的寿命并维持了高性能。
在众多SSD厂商关于向量检索的硬件设计PR材料中,VSM 架构设计和公布的细节是更底层的,这对于理解、促成SSD在AI工作流中发挥更大作用,起到了布道意义。
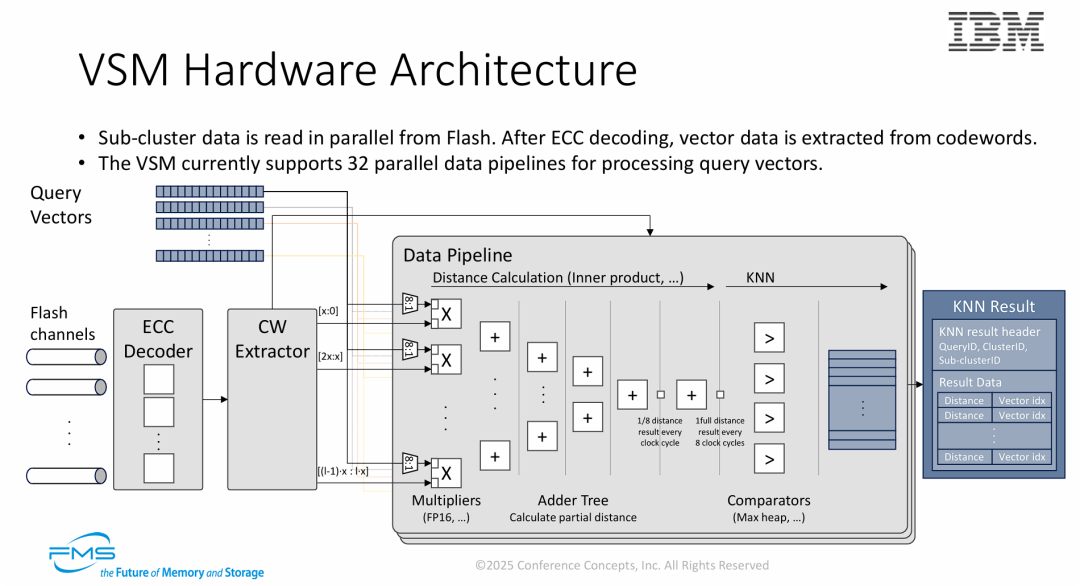
图片展示了 “近数据计算(Near-Data Processing)” 的终极形态。其核心技术亮点在于:
- 全硬件卸载(Full Hardware Offload): 整个 RAG 检索中最耗时的步骤——距离计算(Distance Calculation) 和 Top-K 排序(KNN)——完全由 SSD 内部的 FPGA 专用电路完成。
- 流式计算架构(Streaming Architecture): 数据从 Flash 读取后,不经过 DRAM 缓存,直接进入计算流水线(ECC -> 乘法 -> 加法 -> 排序)。这种“边读边算”的模式最大化了 Flash 的内部带宽利用率。
- 极高的计算密度: 通过 32 条并行流水线和优化的加法树设计,单个存储模块变成了一个高性能的向量搜索引擎,从而彻底解决了 CPU 与存储之间的数据传输瓶颈(IO Wall)。

图片的核心观点在于验证 VSM 在真实世界超大规模数据下的可用性,并明确了其在系统级架构中的角色:
- 规模验证: 通过使用 60 亿(ArXiv)和 12 亿(Common Crawl)规模的数据集,有力地证明了 VSM 具备处理Billion-scale(十亿级) 数据的能力,兑现了之前 PPT 关于“大容量存储”的承诺。
- 多模态支持: 特别提到了使用 ColPali Vision LLM 对 PDF 进行向量化,暗示 VSM 非常适合处理当下最热门的多模态 RAG(Multimodal RAG) 场景(即直接搜索文档截图或图片,而不仅仅是文本)。
- Host-Device 协同架构: 在 IVF 测试模式中,清晰地展示了 Host(主机负责索引导航)+ VSM(存储负责暴力扫描) 的异构协同工作模式。VSM 并不是要替代所有向量计算,而是专注于它最擅长的——对海量存储数据进行高带宽的并行扫描。
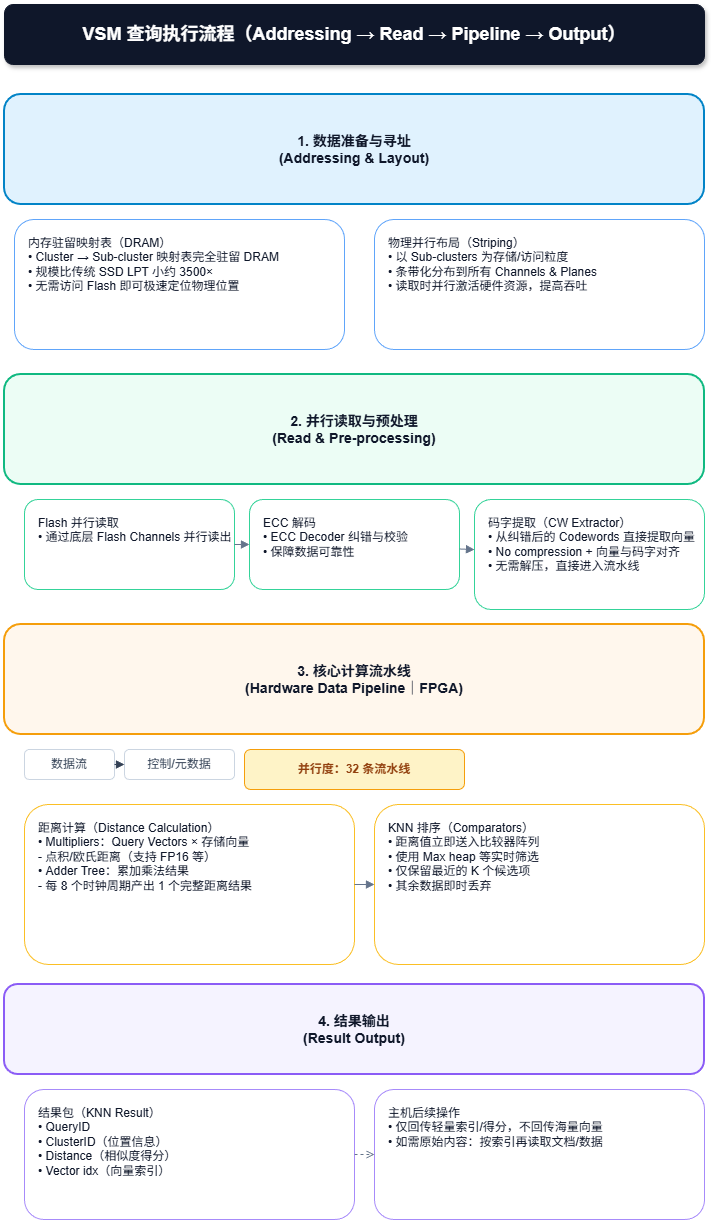
图片的核心观点通过详尽的数据证明了 “计算型存储”硬件设计的正确性,并揭示了性能调优的关键点:
- 硬件排序的胜利: 数据证明 FPGA 内部的“流水线排序”彻底消除了传统 CPU 搜索中排序带来的开销,无论用户要找 1 个还是 100 个结果,耗时一样。
- 瓶颈转移: 性能瓶颈不再是 Flash 的读取速度,而是 ECC(纠错)计算能力。这为之前的“SLC only”设计决策提供了最强有力的技术支撑——使用 SLC 不仅是为了耐用,更是为了降低纠错复杂度,从而释放带宽。
- 确定性的低延迟: VSM 展现了亚 10 毫秒(<0.01s) 扫描百万级向量的能力,这对于实时 RAG 应用来说是极其优异的指标,证明了穷举搜索在硬件加速下完全具有生产可用性。

图片的核心观点在于打破了“AI 必须用 GPU”的迷思,特别是在 RAG 和大规模检索场景下:
- 解决“存算分离”的痛点: 对于 12 亿这样的大规模数据集,GPU 方案受限于显存容量(HBM 放不下),必须频繁通过 PCIe 搬运数据,导致性能瓶颈。而 VSM 采用存算一体(Processing In Memory/Storage),数据不出盘直接计算,因此在海量数据扫描上拥有巨大的系统级优势。
- 极致的性价比与能效(TCO): 48 块 VSM 组成的存储服务器,不仅在性能上碾压 4 张 H100,在能效上更是有 30 倍 的优势。考虑到 H100 的高昂价格和功耗,VSM 提供了一种极其经济高效的替代方案来构建大规模向量数据库。
- 线性扩展能力: 从 1x 到 48x,VSM 的性能几乎是线性增长的。这意味着企业可以通过简单地增加存储盘来线性提升 AI 检索能力,架构极其简单且易于扩展。

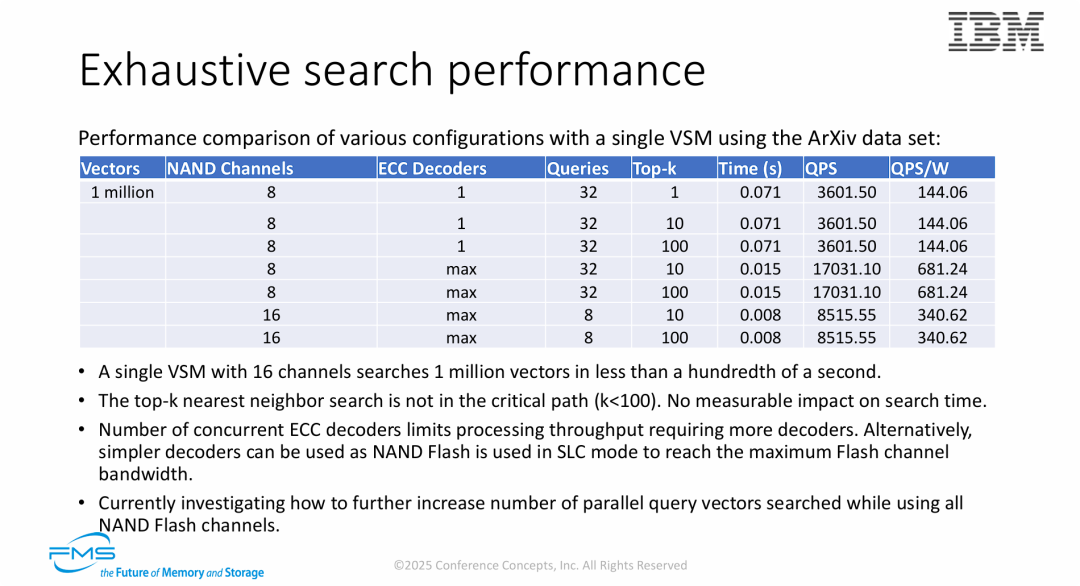
图片的核心观点在于探讨IVF 算法在专用硬件上的“性能损耗”机制:
- 分层存储架构确立: 明确了 DRAM 存索引(轻量),VSM 存数据(重量) 的分界线。这种设计让系统能支持的数据规模仅受限于 SSD 容量,而不受限于 DRAM。
- 批处理的“碎片化”痛点: 揭示了高性能向量存储的一个关键瓶颈——查询发散(Query Divergence)。虽然 VSM 硬件有强大的并行能力(32 pipelines),但 IVF 算法会将查询分散到不同的聚类中。如果进入 VSM 的查询批次太“散”,硬件利用率就会直线下降。这暗示了在生产环境中,查询调度器(Query Scheduler) 的智能程度(如何将访问相同聚类的查询凑成一批)将是决定系统最终性能的关键因素。
图片是对 VSM IVF 场景实战能力的定性:
- 负载特征敏感性: VSM 并不是在任何情况下都快。它存在明显的 “批处理门槛” 。如果业务场景是低并发、低延迟,VSM 可能无法发挥并行优势(利用率为0%);但在高并发(10k+ queries) 场景下,它能跑满硬件性能。
- 暴力美学的胜利: 通过堆叠 VSM 数量(Scale-out),可以在 10亿级 数据规模下实现 CPU 无法企及的高吞吐量。48块 VSM 的方案证明了,通过并行存储硬件来解决高精度搜索(High Recall)带来的巨大计算压力,是一条可行且高效的路径。
VSM 适合的高并发场景
场景名称 | 场景特征 | 匹配点 |
|---|---|---|
1. 互联网级推荐系统(召回阶段) | 为数亿用户实时生成推荐列表,涉及十亿级物品库中为成千上万个用户同时查找相似物品。 | 天然高并发: 流量巨大(QPS 数万甚至数十万),满足 VSM 对 nqueries 的高要求。对 Top-k 容忍度高: 召回阶段通常只需找出前 100-500 个候选集,VSM 在 Top-k 搜索中表现稳定高效。 |
2. 大型 ToC 端的 RAG(检索增强生成)服务 | 面向公众的 AI 搜索服务,后端每秒面临海量用户提问。 | Micro-batching(微批处理): 可在网关层将 10-50 毫秒内到达的数百个用户请求“攒”成一个 Batch 发送给 VSM。热点聚类效应: 大量用户查询意图集中在特定语义聚类上,VSM 的“所有查询命中相同聚类”最佳情况能应对热点流量,实现极致加速。 |
3. 内容安全审核与版权查重(去重) | 视频网站或社交平台每天数百万新增上传内容,需与十亿级历史库比对,检查侵权、重复或违规。 | 离线/近线批处理: 允许秒级甚至分钟级延迟,可构建任务队列,积攒几千个视频指纹后批量比对,吃透 VSM 吞吐红利。暴力搜索优势: 为不漏掉任何风险,有时需全库扫描,VSM 在暴力搜索模式下比 CPU 服务器快 20-990 倍。 |
4. 生物信息学与 AI 制药(AI Drug Discovery) | 幻灯片明确列出“AI 药物发现”和“DNA 序列分类”。科学家比对蛋白质结构或基因序列时,提交包含数万个待测序列的“大作业”。 | 计算密集型大任务: 典型的 Throughput-oriented(吞吐量导向) 任务,而非 Latency-oriented(延迟导向)任务,完全契合 VSM 的批处理特性。 |
5. 网络安全与异常检测(Anomaly Detection) | 金融机构或云厂商分析海量日志流,检测异常流量或欺诈行为。 | 流式批处理: 日志数据是源源不断的流,安全系统通常对日志进行滑动窗口聚合,每秒产生数万条向量进行特征比对,是 VSM 擅长的高并发场景。 |

图片的核心观点是 “现有标准不够用”:
- 抽象层级过高: 现有的 KV 和对象存储接口抽象程度太高,屏蔽了底层的物理细节。
- 丢失了物理优化机会: 前几张 PPT 强调的 VSM 核心优势——“将子聚类条带化到所有 Flash 通道以实现最大并行度”——在现有标准接口下无法实现。因为标准接口不允许主机或应用直接控制数据在 NAND Die/Plane 上的具体布局。
- 缺乏细粒度管理: NVMe KV 不支持原地更新,而 VSM 需要通过 Skip List(跳表)在子聚类内部进行细粒度的向量无效化和追加写,标准接口无法提供这种精细的操作原语。
因此,这张图隐含的下一步逻辑是:为了发挥计算型存储的威力,需要定义一套新的、能透传物理布局感知的存储接口。

图片的核心观点在于 “存储即计算(Storage-as-Compute)的通用化与系统化”:
- 硬件通用性: IBM 并不想做一个孤立的加速卡,而是要把“向量搜索”变成 FlashCore Module 的一个可动态开启的软件定义功能。这极大地降低了用户的部署门槛和 TCO。
- 架构的云原生化演进: 在数据保护层面,从传统的 RAID 转向Replication(多副本)。这是为了适应向量搜索的高并发读取特性——副本不仅是为了防丢数据,更是为了提供并行读取的带宽(Load Balancing)。这标志着存储底层逻辑正在从“块存储思维”向“分布式对象/数据库思维”转变。
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- IBM VSM通过重构SSD固件和硬件设计,实现了向量搜索的极致加速。然而,这种高度定制化的计算型存储方案,在通用性、生态兼容性以及与现有云原生存储架构的融合方面,可能面临哪些挑战?
- 文章指出现有存储接口抽象层级过高,无法发挥计算型存储的物理优化潜力。未来,我们是否需要一套全新的、物理布局感知的存储接口标准?这套标准应由谁来主导,又将如何平衡性能与通用性?
- VSM在特定高并发批处理场景下表现卓越,但在低并发、低延迟场景中利用率可能下降。这是否意味着计算型存储将主要作为特定AI工作负载的加速器,而非通用存储的替代品?其在不同AI应用场景中的最佳部署策略和经济模型会是怎样的?
原文标题:SSD controller architecture for similarity search in Vector DBs[1]
Notice:Human's prompt, Datasets by Gemini-3-Pro
#FMS25 #xPU卸载与计算型存储
---【本文完】---

丰子恺-护生画集-冬日的同乐
👇阅读原文,搜索🔍更多历史文章。
- https://files.futurememorystorage.com/proceedings/2025/20250805_SSDT-102-1_Pletka-2025-08-05-15.01.42.pdf ↩
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号