Science | 蛋白质语言模型驱动的快速定向进化

Science | 蛋白质语言模型驱动的快速定向进化

DrugAI
发布于 2026-03-03 17:36:53
发布于 2026-03-03 17:36:53
DRUGONE
蛋白工程的核心挑战在于需要在高维序列空间中寻找能够协同增强功能的多突变组合。传统定向进化通常通过逐步叠加突变进行搜索,而机器学习方法又往往依赖大规模数据、多轮实验或昂贵的基因合成。研究人员提出了 MULTI-evolve 框架,通过结合蛋白语言模型、上位性建模以及高效多位点突变构建技术,实现端到端的快速蛋白进化。该方法能够预测具有协同效应的多突变组合,并通过优化的MULTI-assembly方法高效合成候选序列。在三个不同蛋白体系中,该框架仅需一次机器学习引导的进化循环即可实现最高约10倍改进,并在某些情况下获得更高数量级提升。整体而言,该方法提供了一种通用、高效的多突变蛋白工程策略。

蛋白质功能由氨基酸序列决定,而长度为N的蛋白理论上存在20^N种可能序列,其中仅极少数具有目标功能。自然进化依靠漫长时间探索这些序列空间,而现代生物技术需要在更短时间内完成这一任务。定向进化通过模拟自然选择加速蛋白优化,但传统方法通常局限于逐步突变搜索。近年来机器学习被用于扩大搜索范围,但其性能依赖于是否能够学习突变之间的上位性效应,也就是一个突变对另一个突变功能影响的改变。当训练数据中功能增强突变比例很低时,这类效应尤其难以学习。此外,多突变组合往往难以通过常规克隆方法快速构建,而商业DNA合成成本高且周期长。研究人员因此提出需要一个能够同时解决突变发现、上位性预测以及快速构建的统一框架。
方法
研究人员构建了MULTI-evolve流程。首先利用蛋白语言模型或已有功能数据识别潜在功能增强的单突变;随后对这些候选突变进行成对组合实验,获得包含关键上位性信息的小规模数据集;在此基础上训练神经网络模型学习突变组合与功能之间的关系,并外推预测更高阶突变组合的性能;最后通过MULTI-assembly多位点突变技术快速合成预测最优的多突变体并进行实验验证。整个流程通过单轮机器学习引导即可从单突变直接跳跃到高性能多突变组合,从而减少多轮实验迭代。
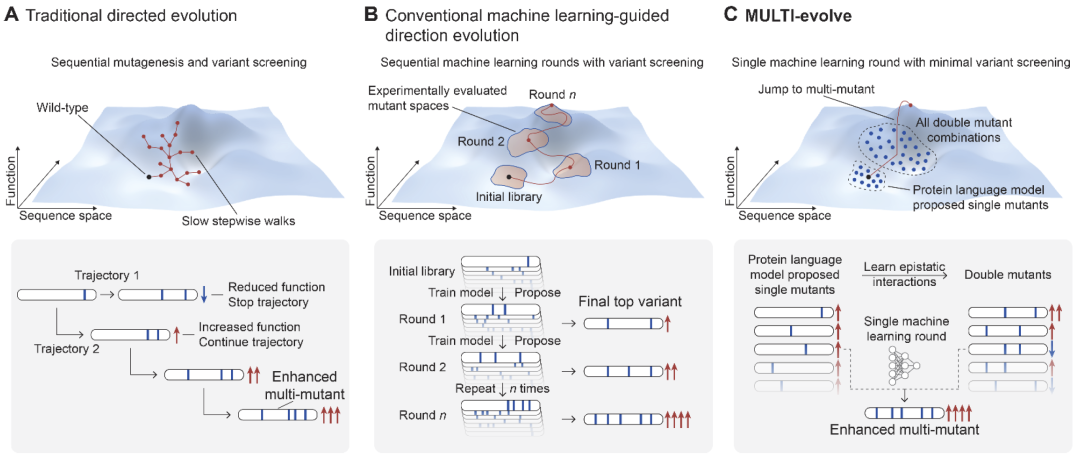
图1:利用MULTI-evolve工程化高活性多突变蛋白。
结果
框架构建与基准测试
研究人员首先验证蛋白语言模型集成策略在识别功能增强突变方面的能力。通过在大量深度突变扫描数据集上测试,发现组合多个语言模型预测能够显著提高命中率,并识别更多潜在有益突变。随后研究人员评估了用于学习上位性关系的神经网络模型,发现仅需包含双突变数据即可有效外推到更高阶突变组合,并在多种蛋白家族中保持稳定预测性能。与多种已有预测方法相比,MULTI-evolve在识别高适应度多突变体方面表现出更高准确率和更高精度,同时在低数据量条件下仍保持良好性能。
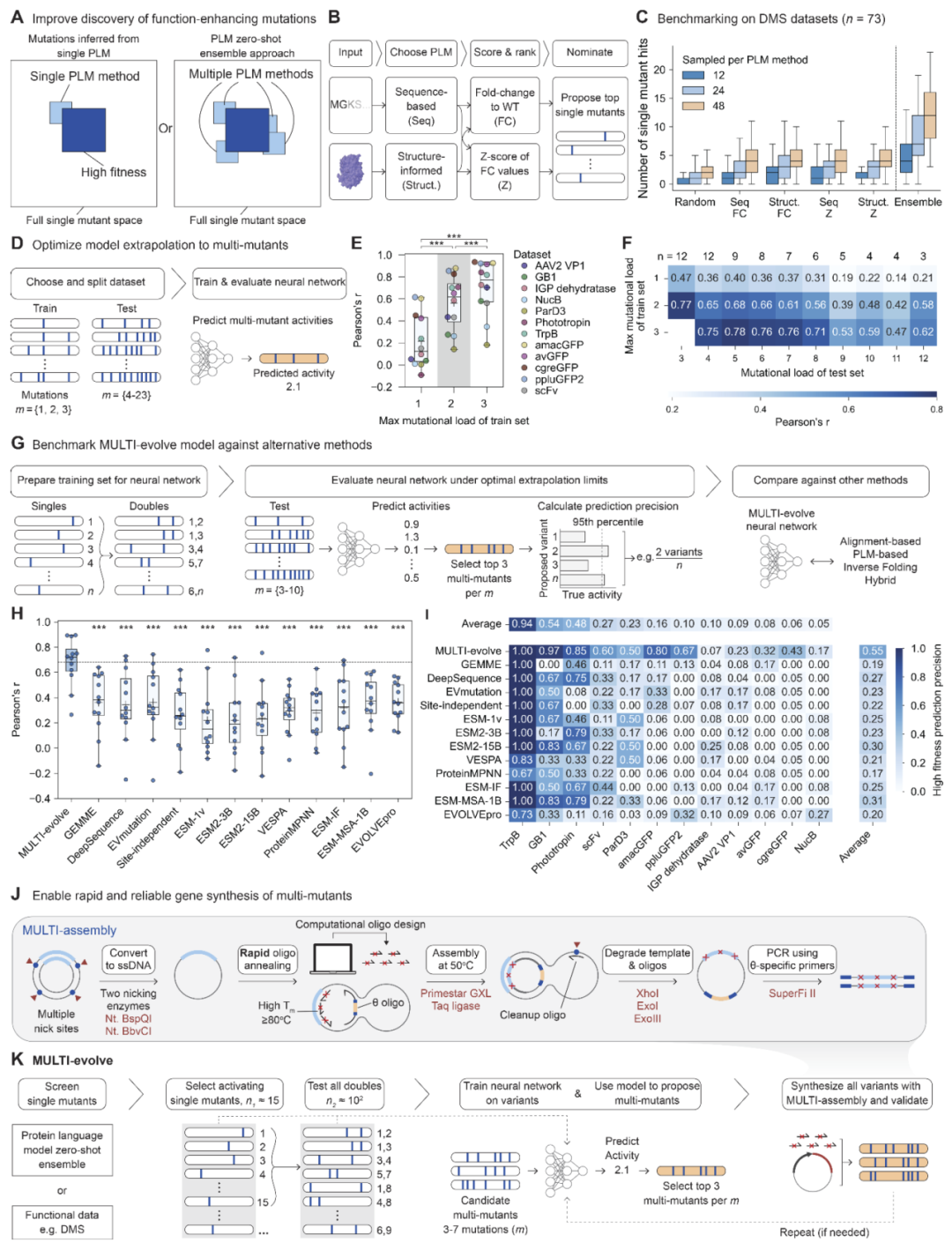
图2:MULTI-evolve框架的开发与设计。
APEX酶多突变工程
研究人员将该框架应用于APEX酶。通过语言模型预测与实验验证,首先获得多个功能增强单突变,然后系统测量其双突变组合以学习上位性结构。在此基础上模型预测包含5到7个突变的高阶组合,并选取最优候选进行实验测试。结果显示这些多突变体相对于野生型可达到数百倍活性提升,并显著超过单突变或双突变组合的性能。这表明模型成功捕获了突变间的协同效应。进一步生化实验确认活性提升源于催化效率提高,而非蛋白表达量变化。
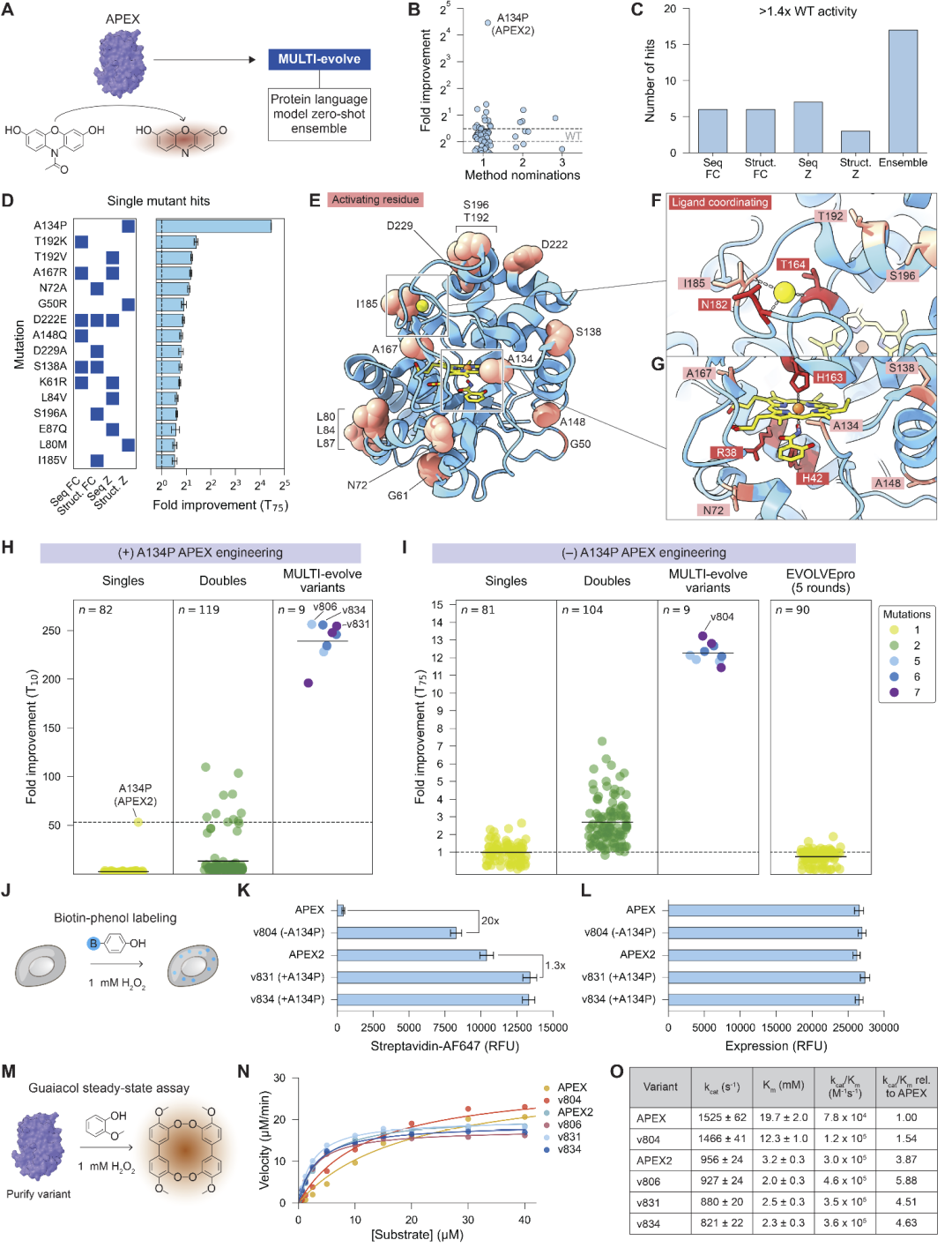
图3:利用MULTI-evolve优化APEX酶。
CRISPR-Cas13d系统优化
为验证方法的普适性,研究人员对RNA靶向CRISPR系统dCasRx进行优化。通过深度突变扫描获得单突变功能数据,并筛选增强转录剪接活性的突变位点。随后利用MULTI-evolve预测多突变组合。实验结果表明这些多突变体在多个内源基因中均表现出显著更高的转录剪接效率,并在不同实验系统中保持稳定增强效果,说明该框架不仅适用于酶,也适用于复杂核酸编辑蛋白。
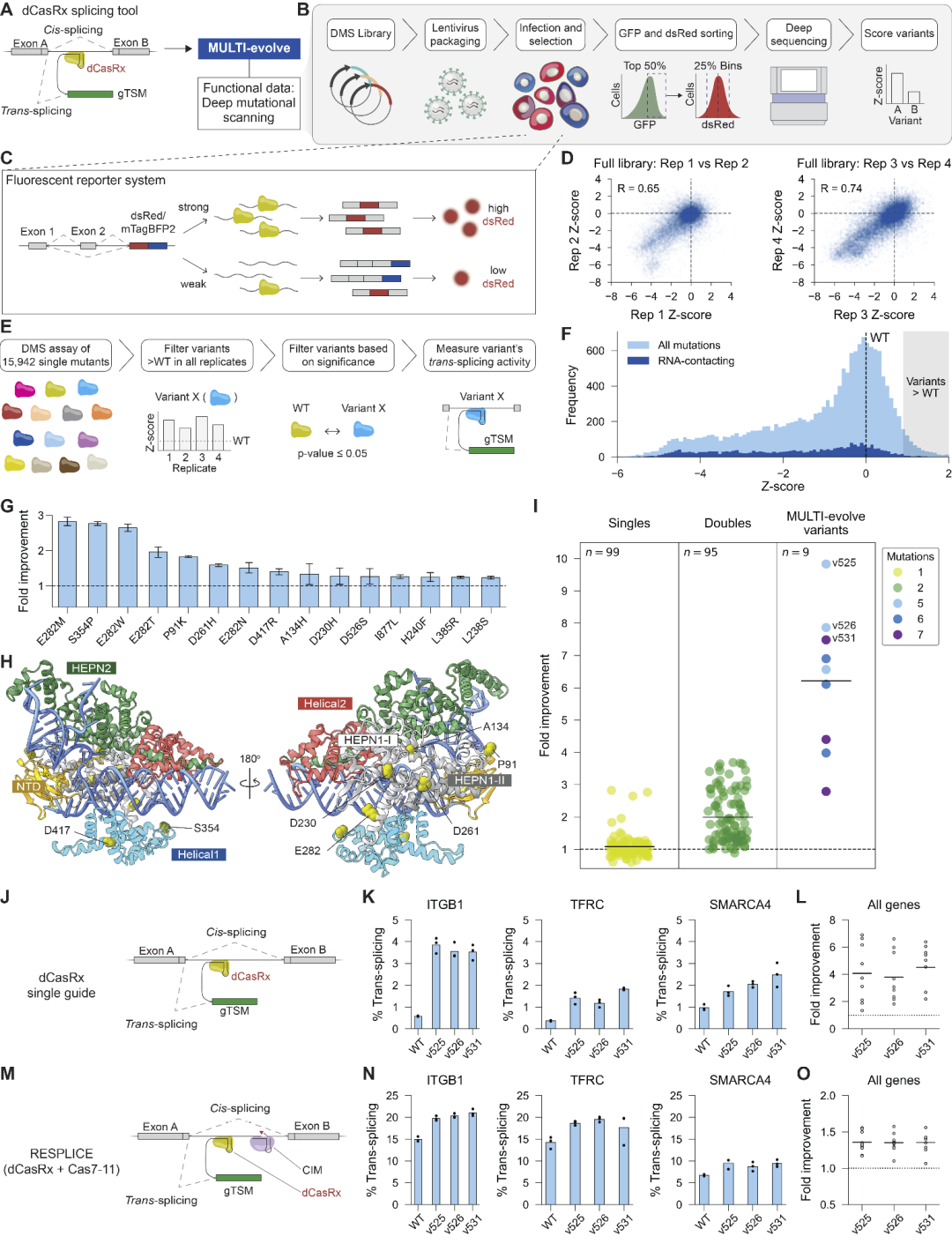
图4:利用MULTI-evolve优化基于dCasRx的RNA剪接工具。
抗体多目标优化
研究人员进一步在抗CD122抗体上测试该方法,用于同时优化表达量与结合亲和力。通过语言模型筛选潜在有益突变并进行实验验证,获得一组既能提高表达又不损害结合的单突变。随后训练模型学习多目标上位性关系,并预测包含3至7个突变的候选抗体。实验结果显示这些多突变体在表达量和结合能力上均显著优于原始抗体,并在纯化后验证仍保持改进效果。该实验展示了MULTI-evolve能够在存在性能权衡的复杂多目标优化场景中找到有效突变组合。
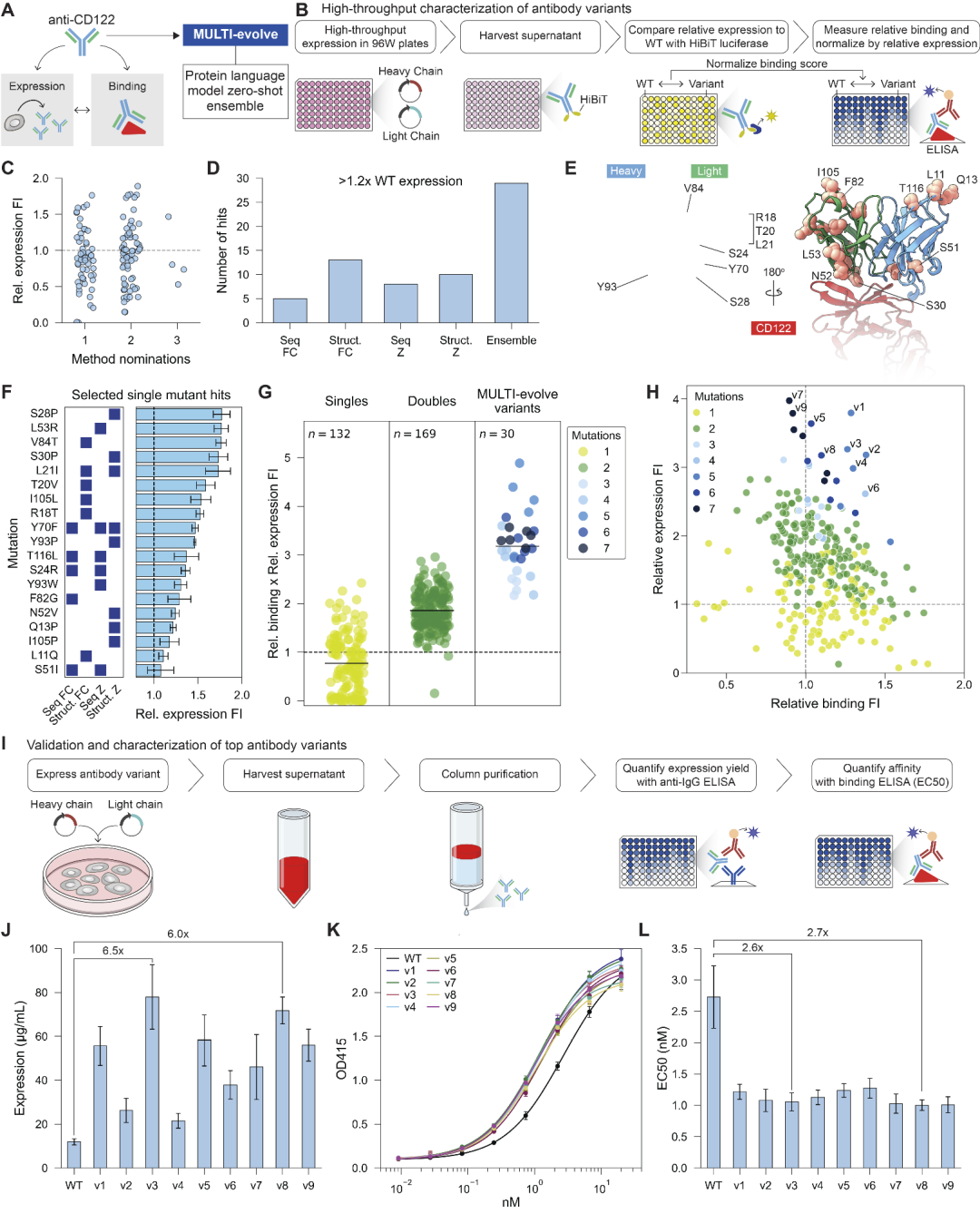
图5:基于MULTI-evolve的多目标抗体设计。
讨论
研究人员认为MULTI-evolve的核心创新在于将蛋白语言模型的进化先验、上位性学习模型以及高效多位点突变构建技术整合为统一流程,使得复杂多突变体能够在一次机器学习循环中被设计并验证。与现有机器学习引导定向进化方法相比,该框架只需约100到200个实验样本即可完成训练,并避免多轮迭代和大规模筛选。该方法既可使用计算预测突变,也可直接利用实验突变数据作为输入,因此具有高度灵活性。未来研究可通过引入结构信息、语言模型嵌入或更多功能预测模块进一步扩展能力,从而在蛋白设计、工业酶工程以及治疗性蛋白开发中实现更高效的序列空间探索。
整理 | DrugOne团队
参考资料
Vincent Q. Tran et al. ,Rapid directed evolution guided by protein language models and epistatic interactions.Science0,eaea1820
DOI:10.1126/science.aea1820

内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号