大幅节省计算成本,准确率反而飙升!DeepConf如何让AI推理既聪明又高效?

大幅节省计算成本,准确率反而飙升!DeepConf如何让AI推理既聪明又高效?

AI浩
发布于 2025-09-11 20:00:07
发布于 2025-09-11 20:00:07
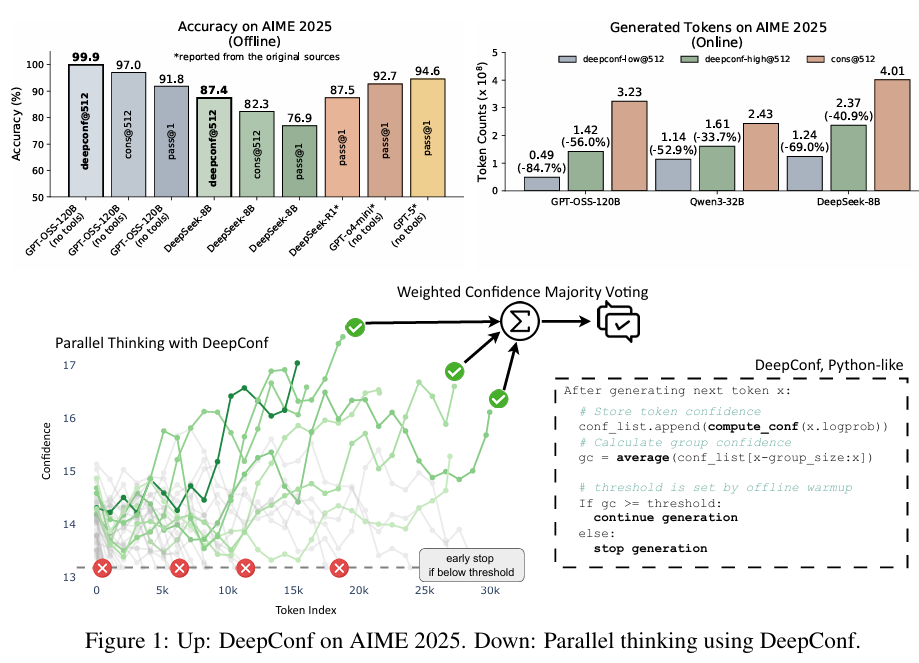
★用AI做数学题,准确率99.9%却只花了原来15%的计算量
你是否曾经感叹,虽然大型语言模型在数学推理上表现出色,但生成多个推理路径导致的计算成本却令人头疼?现在,一种名为DeepConf的新方法正在改变这一局面——它不仅能显著提升模型准确率,还能大幅降低计算开销,最高节省84.7%的Token生成量!
自一致性的困境:准确率提升的代价
当前,最先进的LLM在解决复杂数学问题时,通常采用自一致性(Self-Consistency)方法:生成多个推理路径,然后通过"民主投票"选出最终答案。这种方法确实提升了准确率,但代价巨大。
以8B参数的Qwen3模型在AIME 2025数学竞赛题上的表现为例:使用标准多数投票方法将准确率从68%提升到82%,需要每个问题额外生成511条推理路径,消耗1亿个额外Token!这种计算开销使得高质量推理只能在资源丰富的环境中进行,严重限制了实际应用。
更令人头疼的是,这种方法存在收益递减现象——随着生成的推理路径增加,准确率的提升越来越有限,甚至可能下降。问题的核心在于:传统方法平等对待所有推理路径,而实际上有些路径从一开始就注定是错误的。
DeepConf的突破:让AI学会"自信思考"
DeepConf的核心创新在于引入了置信度机制,让模型能够自我评估推理过程的质量。这种方法简单却有效:在生成过程中实时监测模型的"信心水平",一旦发现信心不足就立即停止,避免浪费计算资源。
两种工作模式,适应不同场景
离线模式:生成所有推理路径后,计算每条路径的置信度得分,只让高置信度的路径参与最终投票。
在线模式:在生成过程中实时监控置信度,一旦发现当前路径置信度过低,立即终止生成。
关键技术:局部置信度信号
此前的方法多使用全局平均置信度评估整条路径,但这种方式有个致命缺陷:少数高置信度token可能掩盖中间出现的严重推理错误。
DeepConf采用了更精细的局部置信度信号:
- 最低组置信度:跟踪滑动窗口内token的平均置信度,持续监控窗口内的最低值
- 尾部置信度:只关注生成末尾部分的置信度,因为最终答案的正确性更依赖于推理链的末端
这些局部信号能灵敏捕捉推理过程中的"崩溃点",为实时决策提供了可靠依据。
实验结果:既准又快,表现惊人
研究团队在多个权威推理基准上测试了DeepConf,包括AIME 2024/2025、HMMT 2025、BRUMO25和GPQA,使用的模型涵盖DeepSeek、Qwen3、GPT-OSS等最新开源模型。
准确率大幅提升
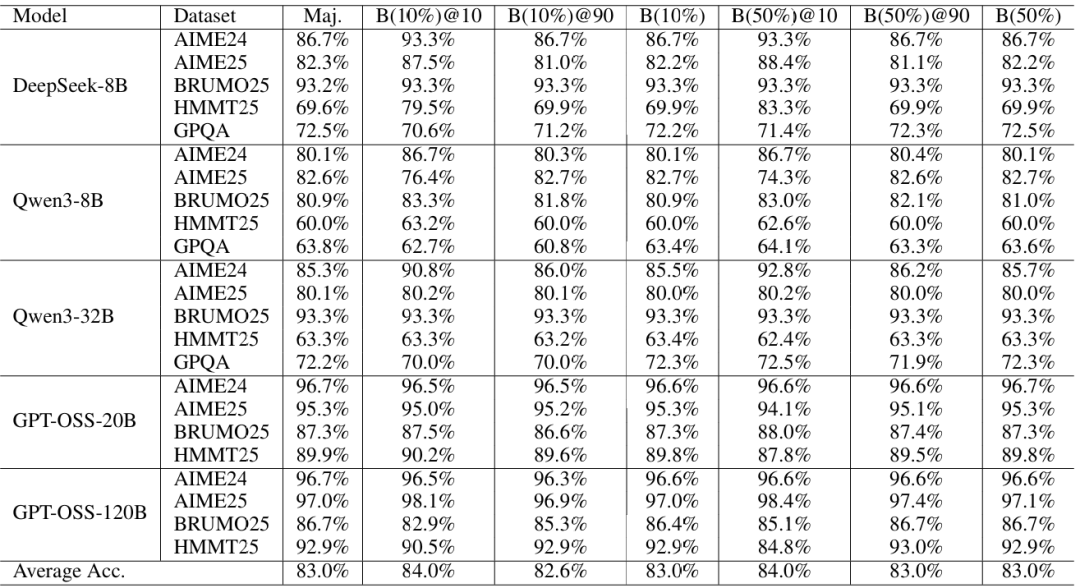
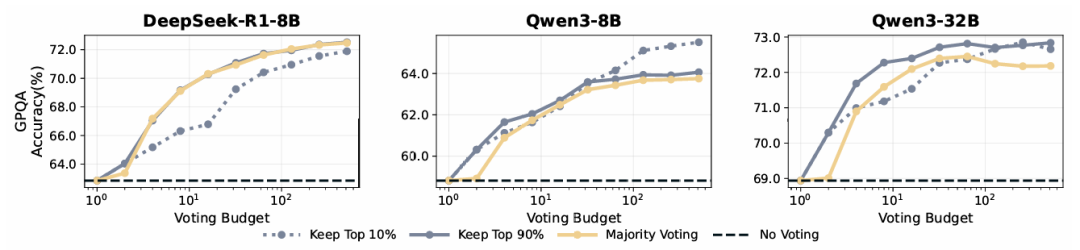
在离线模式下,仅保留置信度最高的**前10%**推理路径进行投票,能在多数数据集上实现最佳准确率:
- 使用GPT-OSS-120B模型时,DeepConf将AIME 2025的准确率从**97.0%提升至99.9%**,几乎完全解决了该基准
- DeepSeek-8B在AIME 2025上的准确率从82.3%提升到87.4%
- Qwen3-32B在AIME 2024上从85.3%提升到90.8%
计算量大幅下降
在线模式下,DeepConf能动态终止低置信度路径的生成,效果更加显著:
- 在达到相同甚至更高准确率的情况下,平均减少62.88%的Token生成量(激进过滤模式)
- 保守过滤模式也能节省47.67%的计算开销
- 在最佳情况下,计算成本降低了84.7%
这意味着原来需要100美元计算成本的任务,现在只需要15.3美元就能完成,而且效果更好!
实际应用:前景广阔
DeepConf的价值不仅体现在学术实验中,更在于其实际应用潜力:
教育领域:智能辅导系统可以低成本提供高精度数学解题指导
科研计算:减少科学计算中的推理成本,提高研究效率
商业应用:降低企业部署高质量推理模型的成本和能耗
移动设备:使得高性能推理可能在资源受限的边缘设备上运行
挑战与未来方向
尽管DeepConf表现优异,但仍面临一个关键挑战:**模型有时会对错误答案表现出"高度自信"**。这种情况虽然少见,但仍需解决。
研究团队指出,未来的工作将集中于:
- 改进置信度校准技术,使信号更加可靠
- 将DeepConf扩展到强化学习设置中
- 探索更稳健的不确定性量化方法
结语:高效推理的新范式
DeepConf的成功证明了测试时压缩(Test-Time Computation Compression) 的巨大潜力。通过让模型在推理过程中"自我评估",我们能够以更低的成本获得更优的性能。
这种方法不仅技术上有趣,更具有重要的实际意义:它让高质量AI推理变得更加普惠和可持续,为LLM在实际应用中的广泛部署扫除了一大障碍。
未来,随着这类技术的成熟,我们有望看到更多智能应用出现在日常生活中,而不再局限于资源丰富的大型科技公司。AI推理的高效化,正在打开一个全新的可能性空间。
论文翻译
摘要
https://arxiv.org/pdf/2508.15260v1
大型语言模型(LLMs)通过测试时扩展方法(如使用多数投票的自一致性)在推理任务中展现出了巨大潜力。然而,这种方法常常导致准确率的收益递减和高计算开销。为解决这些挑战,我们提出了"深度思考与置信度"(Deep Think with Confidence, DeepConf),这是一种简单而强大的方法,能够在测试时提高推理效率和性能。DeepConf利用模型内部置信度信号,在生成过程中或生成后动态过滤掉低质量的推理轨迹。它不需要额外的模型训练或超参数调整,并可以无缝集成到现有的服务框架中。我们在各种推理任务和最新的开源模型(包括Qwen 3和GPT-OSS系列)上评估了DeepConf。值得注意的是,在具有挑战性的基准测试(如AIME 2025)上,DeepConf@512达到了99.9%的准确率,并且相比完整的并行思考,生成的token减少了84.7%。
在这里插入图片描述
1 引言
大型语言模型(Ms)展示了卓越的推理能力,特别是当配备了增强其测试时推理性能的方法时。一种突出的技术是自一致性(self-consistency),它采样多条推理路径并通过多数投票聚合最终答案(Wang等人,2023)。这种被称为并行思考(parallel thinking)的方法显著提高了推理准确率,但带来了巨大的计算开销:每个查询生成大量推理轨迹使推理开销线性增加,限制了实际部署(Xue等人,2023)。例如,在AIME 2025上使用标准多数投票将pass@1准确率从68%提高到82%,使用Qwen3-8B需要每个问题额外511条推理轨迹,消耗1亿个额外的token。
此外,并行思考与多数投票表现出收益递减——随着轨迹数量的增加,性能往往会达到饱和或下降(Chen等人,2024a)。一个关键限制是,标准多数投票平等对待所有推理轨迹,忽略了质量差异(Pal等人,2024;Wang等人,2025)。当低质量轨迹主导投票过程时,这可能导致次优性能。
最近的研究利用下一个token的分布统计来评估推理轨迹质量(Geng等人,2024;Fadeeva等人,2024;Kang等人,2025)。更高的预测置信度通常与更低的熵和减少的不确定性相关。通过聚合token级别的统计信息(如熵和置信度分数),现有方法在整个轨迹上计算全局置信度度量,以识别和过滤低质量轨迹,从而提高多数投票性能(Kang等人,2025)。
然而,全局置信度度量在实践中存在几个限制。首先,它们可能会掩盖局部推理步骤中的置信度波动,而这些波动可以提供足够的信号来估计轨迹质量。在整个轨迹的token上取平均可能会掩盖在特定中间步骤发生的严重推理崩溃。其次,全局置信度度量需要在计算前生成完整的推理轨迹,这阻止了对低质量轨迹的早期停止。
我们提出了"深度思考与置信度"(Deep Think with Confidence, DeepConf),这是一种简单而有效的测试时方法,基于局部置信度测量,将并行思考与置信度感知过滤相结合。DeepConf在离线和在线两种模式下运行,在生成过程中或生成后识别并丢弃低置信度推理轨迹。这种方法在保持或提高最终答案准确率的同时,减少了不必要的token生成。
我们在多个推理基准测试(AIME_2024/2025、HMMT 2025、BRUMO25、GPQA-Diamond)和模型(DeepSeek-8B、Qwen3-8B/32B、GPT-OSS-20B/120B)上评估了DeepConf。通过在每个设置上平均64次重复的广泛实验,我们证明了DeepConf实现了更优越的推理性能,同时与标准多数投票相比需要显著更少的生成token。
在可以访问所有推理轨迹的离线模式下,使用GPT-OSS-120B(无需工具)的DeepConf@512在AIME_2025上达到了99.9%的准确率,使该基准测试达到饱和,而cons@512(多数投票)为97.0%,pass@1为91.8%。在具有实时生成控制的在线模式下,DeepConf在保持或超过准确率的同时,相比标准并行思考将token生成减少了84.7%。图1突出了我们的关键结果。
2 置信度作为推理质量的指标
最近的研究表明,可以使用从模型内部token分布中得出的指标来有效评估推理轨迹质量(Kang等人,2025)。这些指标提供了模型内在信号,用于区分高质量推理轨迹和错误轨迹,无需外部监督。
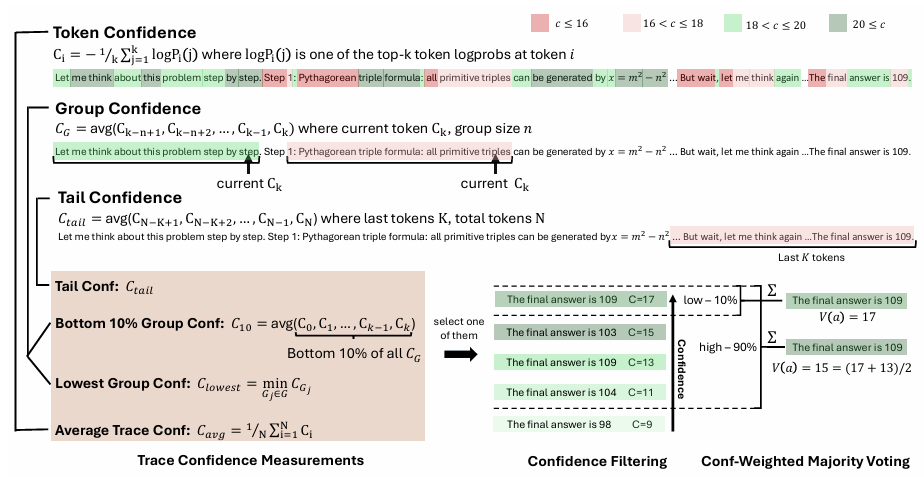
标记熵。给定语言模型在位置i处的预测token分布P,标记熵定义为:

在这里插入图片描述
图2:不同指标下正确与错误推理轨迹的置度分布。数据来自HMMT25:30个问题,每个问题4096条轨迹。
其中表示第j个词汇标记的概率。低熵表示分布集中,模型确定性高;而高熵则反映预测中的不确定性。
标记置信度。我们将标记置信度定义为位置i处前k个token的负平均对数概率:
其中k表示考虑的前k个token的数量。高置信度对应分布集中和模型确定性高,而低置信度表示token预测中的不确定性。
平均轨迹置信度。标记级指标需要聚合以评估整个推理轨迹。按照Kang等人(2025)的方法,我们采用平均轨迹置信度(也称为自我确定性)作为轨迹级质量度量:
其中N是生成的总token数。如图2所示,平均轨迹置信度能有效区分正确和错误的推理路径,值越高表示正确可能性越大。
尽管有效,平均轨迹置信度仍存在明显局限性。首先,全局聚合会掩盖中间推理步骤中的失败:少数高置信度token可能掩盖大量低置信度片段,可能隐藏关键错误。其次,这种方法需要在计算前生成完整的推理轨迹,这阻止了对低质量生成的早期终止,导致计算效率低下。
3 基于置信度的深度思考
在本节中,我们介绍如何更有效地利用置信度指标来提高推理性能和思考效率。我们针对两种主要场景:离线思考和在线思考。离线思考利用置信度通过评估和聚合已完成推理轨迹中的信息来增强推理性能。在线思考在token生成过程中结合置信度,以实时提高推理性能和/或计算效率。
3.1 置信度测量
为解决自我确定性等全局置信度度量的局限性,我们引入了几种替代的置信度测量方法,这些方法能捕捉局部中间步骤质量,并提供更细粒度的推理轨迹评估。
组置信度。我们使用组置信度来量化中间推理步骤的置信度。组置信度通过在推理轨迹的重叠片段上对token置信度进行平均,提供了更局部化和更平滑的信号。每个token与一个滑动窗口相关联,组由n个先前的token组成(例如,n=1024或2048),相邻窗口有重叠。对于每个组,组置信度定义为:
其中是组中token的数量。
评估推理轨迹质量需要从组置信度中聚合信号。我们观察到,轨迹中置信度极低的中间步骤会显著影响最终解决方案的正确性。例如,当推理过程中置信度急剧下降,出现重复的低置信度token如"wait"、"however"和"think again"时,会破坏推理流程并导致后续错误。
底部10%组置信度。为捕捉极低置信度组的影响,我们提出了底部10%组置信度,其中轨迹置信度由轨迹中置信度最低的10%组的平均值决定:
其中是置信度最低的10%组的集合。从经验上看,我们发现10%能有效捕捉不同模型和数据集上最成问题的推理片段。
最低组置信度。我们还考虑了最低组置信度,它表示推理轨迹中置信度最低的组的置信度——底部10%组置信度的一个特例。该度量仅基于置信度最低的组来估计轨迹质量:
其中G是推理轨迹中所有token组的集合。我们将在后面讨论最低组置信度如何提高在线思考场景中的推理效率。
尾部置信度。除了基于组的度量外,我们还提出了尾部置信度,它通过关注最后部分来评估推理轨迹的可靠性。该指标的动机是观察到推理质量通常在长链思考的末尾下降,而最后步骤对正确结论至关重要。在数学推理中,最终答案和结论步骤尤为重要:即使中间推理有希望,但开始强而结尾弱的轨迹可能产生错误结果。尾部置信度定义为:
其中表示固定数量的token(例如,2048)。图2比较了不同的置信度测量方法,表明底部10%和尾部置信度指标比平均置信度方法更能有效区分错误和正确的轨迹分布,这表明这些指标对轨迹质量评估更有效。
3.2 基于置信度的离线思考
我们现在描述如何应用各种置信度测量来改进离线设置中的推理性能。在离线思考中,每个问题的推理轨迹已经生成,关键挑战是从多个轨迹中聚合信息以更好地确定最终答案。虽然最近的工作提出了使用LLM总结和分析推理轨迹的高级方法,但我们专注于标准的多数投票方法。
多数投票。在标准多数投票中,每个推理轨迹的最终答案对最终决策的贡献相等。设T为所有生成轨迹的集合,对于每个,令为从轨迹t中提取的答案字符串。每个候选答案a的投票计数为:
在这里插入图片描述
图3:置信测量和基于置信度的离线思考。
其中是指示函数。最终答案选择为得票最多的答案:
置信度加权多数投票。我们不是平等对待每个轨迹投票,而是根据相关轨迹的置信度对每个最终答案进行加权。对于每个候选答案,我们将其总投票权重定义为:
其中是从上述讨论的置信度测量中选择的轨迹级置信度。我们选择具有最高加权投票的答案。这种投票方案倾向于由高置信度轨迹支持的答案,从而减少不确定或低质量推理答案的影响。
置信度过滤。我们在置信度加权多数投票的基础上应用置信度过滤,以控制对高置信度推理轨迹的集中度。置信度过滤根据轨迹置信度分数选择前η%的轨迹,确保只有最可靠的路径对最终答案有贡献。我们在所有置信度测量中提供两个选项:和。
前10%选项专注于最高置信度分数,适用于预期少数可靠轨迹就能产生准确结果的情况。然而,依赖非常少的轨迹如果模型表现出偏差,可能会导致错误答案。前90%选项提供了一种更平衡的方法,通过包含更广泛的轨迹来维持多样性并减少模型偏差。这确保考虑了替代的推理路径,特别是当置信度分布趋于均匀时。图3提供了置信度测量以及离线思考如何与置信度结合的示意图。此外,算法1提供了该算法的详细信息。
3.3 在线思考与置信度
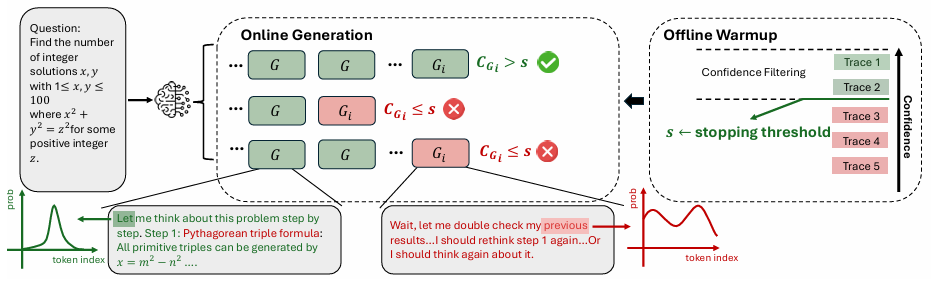
在在线思考过程中评估置信度能够实现在生成过程中的实时轨迹质量估计,从而动态终止没有前景的轨迹。这种方法在资源受限环境或需要快速响应的情况下特别有价值。最低组置信度指标可以有效地应用于这种在线设置中。当标记组置信度低于关键阈值时,我们可以停止轨迹生成,确保此类轨迹很可能在置信度过滤过程中被排除。
在这里插入图片描述
图4:在线生成过程中的DeepConf。
我们提出了DeepConf-low和DeepConf-high两种算法,它们基于最低组置信度,在线思考过程中自适应地停止生成并调整轨迹预算。该方法包含两个主要组件:离线预热和自适应采样。
离线预热。DeepConf需要一个离线预热阶段来建立用于在线确定的停止阈值s。对于每个新提示,我们生成条推理轨迹(例如,)。停止阈值s定义为:
其中表示所有预热轨迹,是轨迹的置信度,是期望的保留比例。具体来说,DeepConf-low使用顶部(对应90th百分位),而DeepConf-high使用顶部(对应10th百分位),在所有设置中保持一致。此阈值确保在在线生成过程中,当轨迹置信度低于预热阶段保留的顶部最高置信度轨迹的水平时,终止该轨迹。
自适应采样。在DeepConf中,我们在所有方法中采用自适应采样,根据问题难度动态调整生成的轨迹数量(Xue等人,2023)。难度通过生成轨迹之间的共识来评估,量化为多数投票权重与总投票权重的比率。
是一个预设的共识阈值。如果,则模型对当前问题未达成共识,轨迹生成将继续,直到达到固定轨迹预算B。否则,轨迹生成停止,使用现有轨迹确定最终答案。
由于我们使用最低组置信度,足够大的预热集可以准确估计停止阈值s;因此,任何在线终止的轨迹其组置信度<sn_{i n="" i="" t}
4 实验
4.1 实验设置
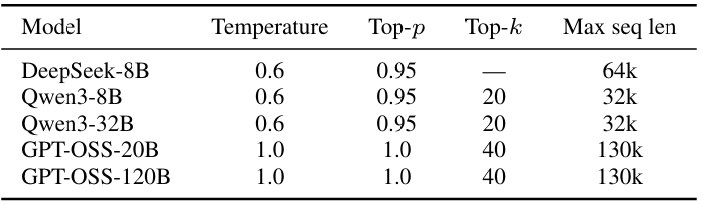
模型。我们评估了来自三个模型家族的五个开源推理LLM:DeepSeek-8B(Guo等人,2025)、Qwen3-8B、Qwen3-32B(Yang等人,2025a)、GPT-OSS-20B和GPT-OSS-120B(OpenAI,2025)。这些模型以其强大的数学推理和长链思考性能而闻名,完全开源以确保可重现性,并涵盖多个参数规模以测试鲁棒性。完整的生成超参数和提示模板在附录F中提供。
基准测试。我们在五个具有挑战性的数据集上进行评估:AIME24(Art of Problem Solving,2024a;b)、AIME25(Art of Problem Solving,2025a;b)、BRUMO25(bru,2025)、HMMT25(HMMT,2025)和GPQA(Rein等人,2024)。前四个是高难度数学竞赛问题,而GPQA包含研究生级别的STEM推理任务。所有基准测试都被最近的顶级推理LLM评估广泛采用(例如,Grok-4(xAI,2025)、Qwen3(Yang等人,2025a)、GPT-5(OpenAI,2025)),并出现在MathArena排行榜上(Balunović等人,2025)。
基线。我们采用自一致性(Wang等人,2023)与多数投票作为主要基线。每个LLM采样T个独立推理路径,并通过无权重多数投票选择最终答案,如第3.2节所述。
实验设置。对于每个问题,我们通过预先生成4,096条完整推理轨迹的池来建立共同的采样框架;该池作为离线和在线评估的基础。离线实验从该池中重新采样大小为(例如,)的工作集,并在每次运行中应用指定的投票方法。在线实验同样重新采样工作集以驱动具有早期停止的即时生成;该池确保方法之间的一致采样。
我们报告四种关键方法:(i)Pass@1(单轨迹准确率),(ii)Cons@K(使用K条轨迹的无权重多数投票准确率),(iii)Measure@K(置信度加权多数投票准确率),以及(iv)Measure+top-η%@K,该方法在应用加权多数投票前保留工作集中置信度最高的前轨迹(我们使用)。特定的置信度度量因设置而异。我们还报告生成的总token数。所有指标均在64次独立运行上取平均,每次运行都进行新的重采样;除非另有说明,token计数包括所有生成轨迹的端到端计数,提前终止的轨迹仅计算停止前生成的token。
对于在线评估,我们使用最低组置信度(公式6)和2,048个token的重叠窗口实例化DeepConf-low和DeepConf-high。每个问题以条完整轨迹开始进行离线预热;然后我们设置一个特定运行的停止阈值
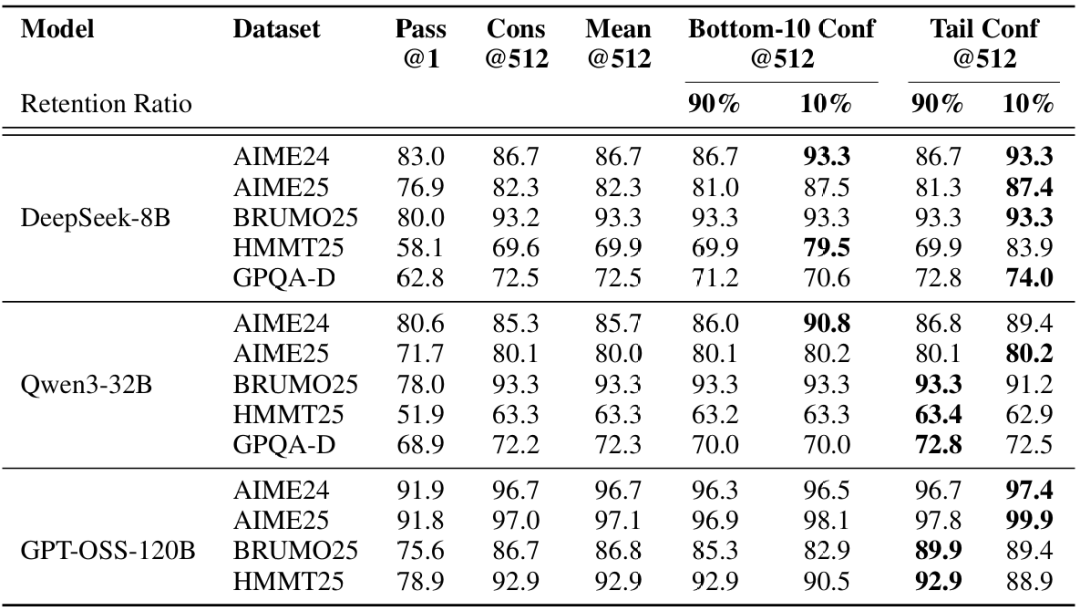
表1:离线设置中置信度测量的基准测试。报告准确率(%)。Cons@512和mean@512表示使用512条轨迹的多数投票和平均平均置信度。所有实验重复64次。
在这里插入图片描述
在这里插入图片描述
其中包含按置信度排名的前百分位轨迹(DeepConf-low的η=10,DeepConf-high的η=90;第3.3节)。在生成过程中,当前组置信度低于s的轨迹会提前终止;完成的轨迹通过置信度加权多数投票进行聚合,并在共识或预算K达到时自适应停止生成。
对于离线评估,我们从第3.1节中基准测试三种轨迹级置信度定义:(i)平均轨迹置信度(公式3),(ii)底部10%组置信度(公式5),以及(iii)最后2,048个token的尾部置信度(公式7)。对于每个指标,我们报告Measure@K和Measure+top-η%@K,其中,top-η%截止点在每次运行中在采样的工作集内重新计算(第3.2节)。
4.2 离线评估
我们在表1中展示了在投票规模下,三种模型在五个数据集上的离线结果。我们比较以下方法:Pass@1 = 单轨迹准确率,Cons@512 = 使用512条轨迹的无权重多数投票;Mean Conf@512 = 使用平均轨迹置信度(公式3)的置信度加权多数投票;Bottom-10% Conf@512和Tail Conf@512 = 分别使用(i)最低10%重叠组置信度的平均值(公式5)和(ii)最后2,048个token的平均置信度(公式7)的置信度加权多数投票。90%/10%子列表示置信度过滤中的保留比例η:我们在投票前保留工作集中置信度最高的前η%轨迹。例如,当K=512且η=10%时,我们保留约51条轨迹进行投票。
总体而言,在大多数设置中,具有过滤的置信度感知加权始终优于标准多数投票(Cons@512)。使用η=10%的过滤产生最大收益,例如DeepSeek-8B在AIME25上的显著改进(82.3%→87.4%)和Qwen3-32B在AIME24上的改进(85.3%→90.8%);GPT-OSS-120B甚至在AIME25上达到99.9%。局部(Tail Conf和Bottom-10%)和全局(Average Trace Conf)置信度度量在识别高置信度轨迹方面都显示出有希望的结果。然而,过滤涉及重要的权衡:虽然激进过滤(η=10%)在大多数情况下最大化准确率增益,但由于模型对错误问题的过度自信,有时可能会损害性能,如GPT-OSS-120B所示。在这种情况下,保守过滤(η=90%)提供了更安全的选择。所有方法都观察到相比pass@1的显著改进,证实了集成方法的价值。我们在附录B.4中提供了详细的置信度度量比较。

在这里插入图片描述
在这里插入图片描述
图5:使用最低组置信度过滤的离线准确率(DeepSeek-8B)在AIME24、AIME25、BRUMO25和HMMT25上。η%变体在置信度加权多数投票前仅保留置信度最高的前η%轨迹。
我们随后证明最低组置信度也有效。图5报告了使用最低组置信度(公式6)捕获每个轨迹中最不自信的token组(窗口大小2,048)的离线结果。在每个采样的工作集中,我们保留置信度最高的前η%轨迹,然后应用置信度加权多数投票。在DeepSeek-8B上,AIME24、AIME25、BRUMO25和HMMT25四个数据集上,保留顶部η=10%始终优于多数投票达到的最佳准确率:+0.26至+9.38个百分点(平均+5.27),并且相比单轨迹(或无投票)准确率有大幅改进(+10.26至+20.94个百分点;平均+14.30)。保守的η=90%设置在所有四个数据集上匹配或略微超过最佳多数投票准确率(+0.16至+0.57个百分点;平均+0.29),同时仍提供相比单轨迹准确率的显著改进(平均+9.31)。这些结果推动了在线变体的设计:关注最不自信的片段可靠地识别具有局部推理崩溃的轨迹,为离线过滤提供强有力的信号,并在在线生成过程中提供自然的停止标准。
除了这些结果外,我们在附录B.3中对保留率η进行了消融实验,并在附录C中展示了完整的离线结果。
4.3 在线评估
在本节中,我们通过改变预算来评估在线算法的准确率-成本权衡,其中成本计算所有生成的token,包括提前停止轨迹的部分token。按照第3.3节,我们使用条轨迹进行预热,以使用最低组置信度(窗口大小2,048)设置停止阈值s:我们在置信度的前预热轨迹上设置s(),然后终止任何当前组置信度低于s的新轨迹。每次新轨迹完成后,我们重新应用相同的阈值s进行过滤,使该过程匹配离线最低组置信度过滤器版本,同时节省提前停止轨迹的成本。我们考虑两种在线变体:DeepConf-low()和DeepConf-high(),它们继续采样直到共识(我们使用)或达到预算上限K。我们在附录B.1中与仅基于预算的变体(总是运行到上限K而不进行共识停止)和不同的τ值进行比较。
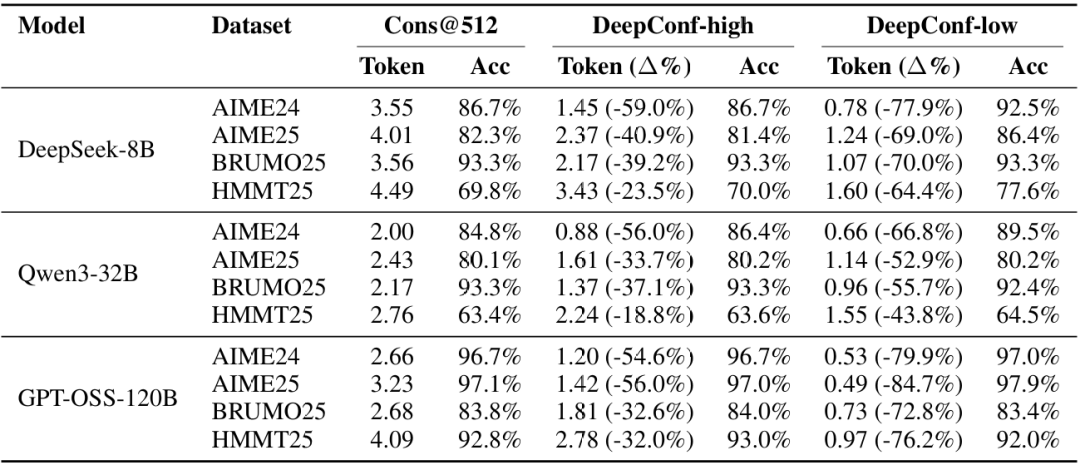
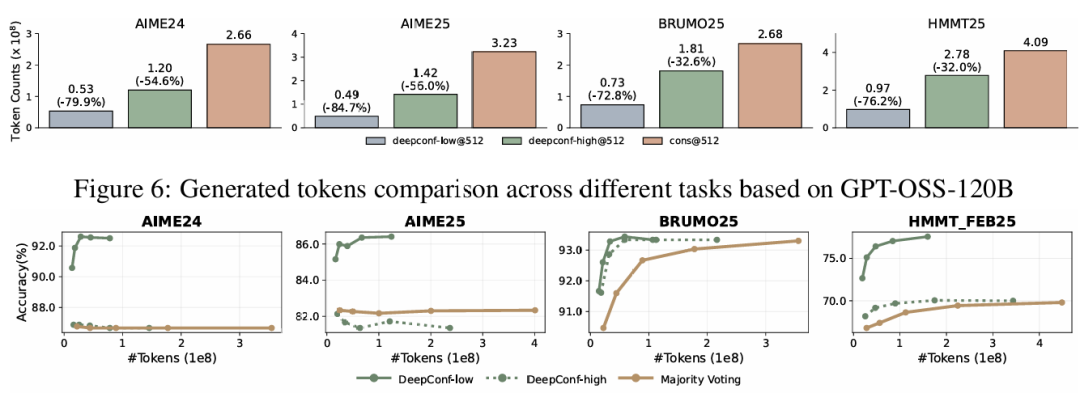
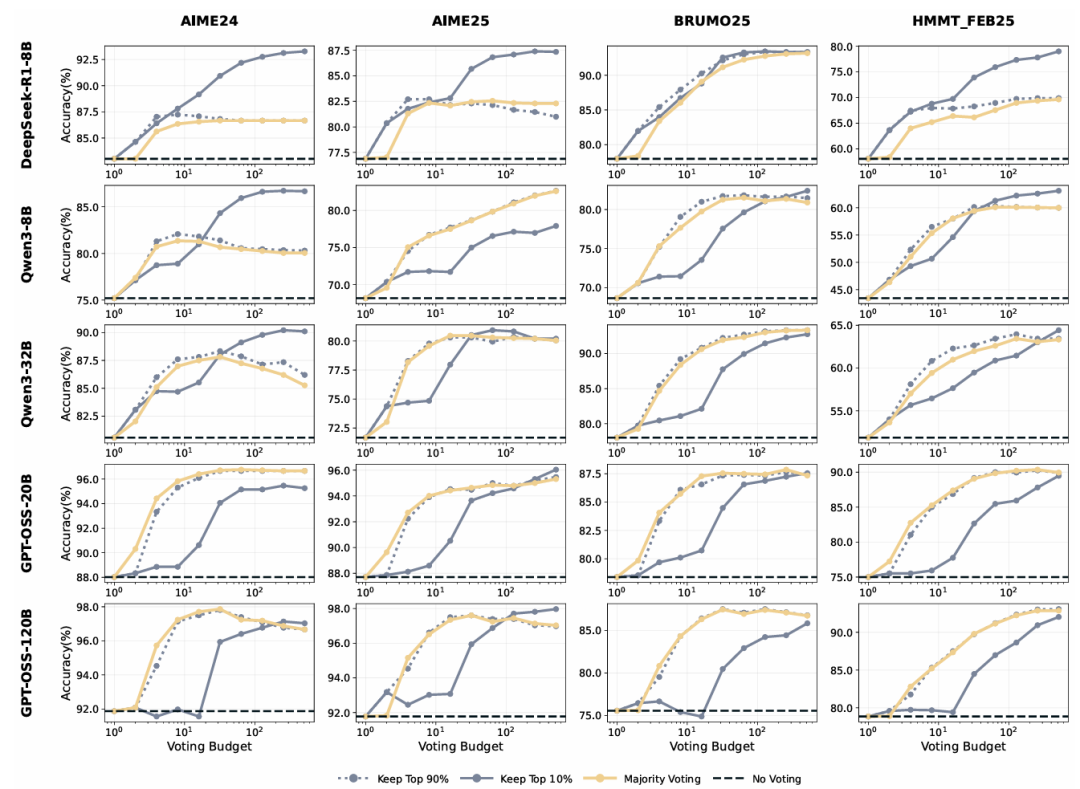
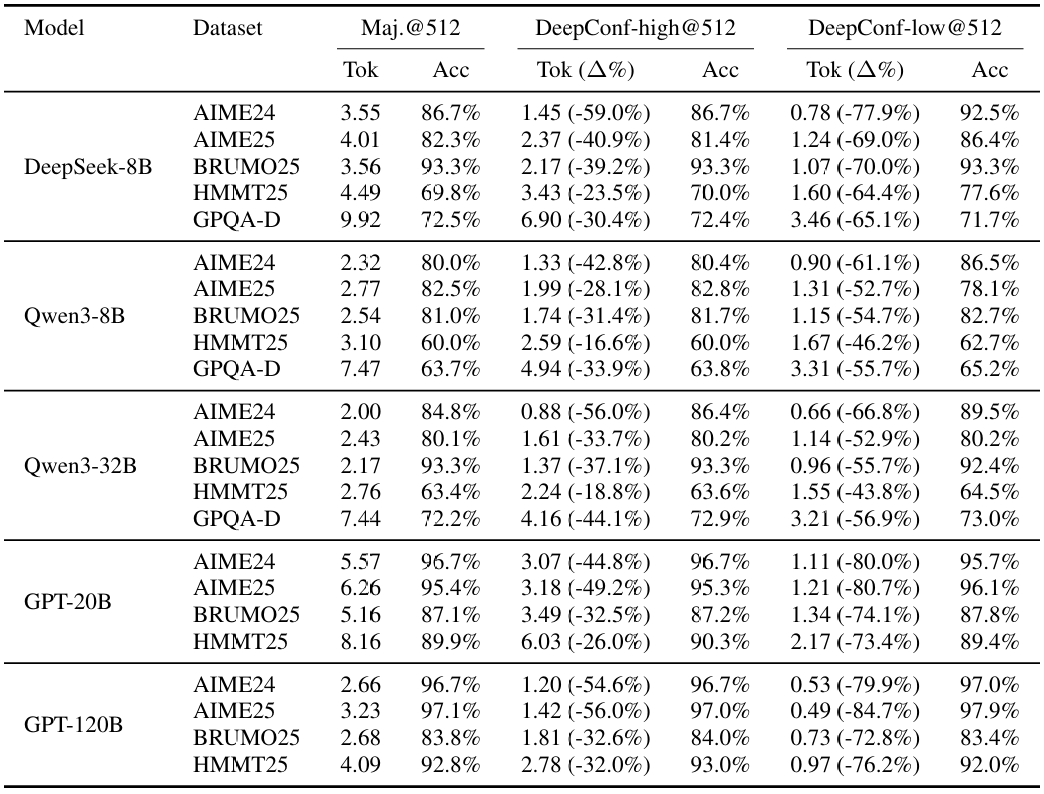
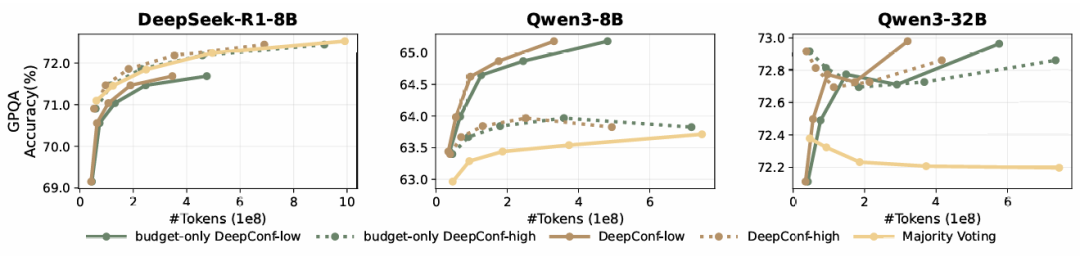
表2展示了在DeepSeek-8B/Qwen3-32B/GPT-OSS-120B上,投票规模预算的DeepConf自适应采样版本的性能。与多数投票基线相比,DeepConf-low在AIME24/AIME25/BRUMO25/HMMT25上减少了43-79%的token。虽然它在大多数情况下匹配或提高了准确率(例如,DeepSeek-8B AIME24:+5.8%),但在某些设置中经历了明显的准确率下降(例如,Qwen3-32B BRUMO25:-0.9%)。更为保守的DeepConf-high在这些数据集上节省了18-59%的token,同时保持几乎相同的准确率或仅产生最小的性能下降。图6展示了GPT-OSS-120B的token减少模式,说明了DeepConf如何在保持有竞争力的准确率的同时实现显著的计算节省(即高达85.8%),适用于不同的数学推理任务。
图7比较了DeepSeek-8B上的DeepConf和多数投票基线。DeepConf方法展示了明显的效率优势,同时保持等效的准确率:DeepConf-low在相同准确率水平下比多数投票基线平均节省62.88%的token,DeepConf-high节省47.67%。就性能而言,DeepConf的行为与离线设置类似:η=10%(low)过滤在大多数情况下产生最高的准确率增益,尽管它偶尔会在特定数据集上导致准确率下降(例如,表2中GPT-OSS-120B在HMMT25上的表现)。
表2:在线设置中DeepConf的基准测试。在投票规模预算512下,多数投票和DeepConf(high/low)的准确率(%)和token(×10⁸)。
在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
图7:使用在线最低组置信度过滤的准确率vs.生成token数(DeepSeek-8B)在AIME24、AIME25、BRUMO25和HMMT25上。High/low表示保留置信度最高的前90%/10%轨迹进行投票。
这些结果支持我们的设计:使用最不自信的片段来控制轨迹提供了一个强有力的局部信号用于早期终止,并且自适应共识停止进一步压缩token而不牺牲准确率。
此外,我们在附录B.2中提供了预热大小的消融实验,并在附录D中报告了完整的在线结果。
5 未来工作
我们认为这项工作有几个有希望的方向。首先,将DeepConf扩展到强化学习设置中,可以利用基于置信度的早期停止来指导策略探索并提高训练期间的样本效率。其次,解决模型在错误推理路径上表现出高置信度的情况,这是我们实验中观察到的一个关键限制。未来的工作还可以探索更稳健的置信度校准技术和不确定性量化方法,以更好地识别和缓解过度自信但错误的预测。
6 结论
我们提出了DeepConf,一种简单而有效的方法,显著增强了集成投票场景中的推理性能和计算效率。通过在最先进的推理模型和具有挑战性的数据集上进行广泛实验,DeepConf展示了显著的准确率提升,同时实现了有意义的token节省,在8B到120B参数的模型规模上观察到一致的收益。我们希望这种方法突显了测试时压缩作为高效LLM推理的实用且可扩展解决方案的潜力。
附录
A 相关工作
A.1 测试时扩展
当前大型语言模型(LLMs)越来越多地通过在推理时分配大量推理资源而取得成功,我们将这种范式称为测试时扩展(Snell等人,2024;Welleck等人,2024)。沿着一个轴,链式思考(Chain-of-Thought)(Wei等人,2022)的深度通过增加思考步骤来延长单一推理轨迹;代表性模型包括o1(Jaech等人,2024)、DeepSeek R1(Guo等人,2025)、Kimi K1.5(Team等人,2025)、Qwen3(Yang等人,2025a)和Grok-4(xAI,2025),这些模型通常依赖大规模强化学习和大量样本,以及更简单的微调方法,如STILL-2(Min等人,2024)、s1(Muennighoff等人,2025)和LIMO(Ye等人,2025)。沿着互补的轴,并行生成通过增加轨迹数量并聚合它们来扩展:自一致性(Self-Consistency)(Wang等人,2023)和Best-of-N(Brown等人,2024;Irvine等人,2023)采样多个候选并通过投票或评分选择,而REBASE(Wu等人,2024)则通过树状结构探索扩展广度。Chen等人(2024a)分析了复合AI系统中的并行生成。这两个轴可以结合使用,在部署约束下权衡计算与准确率,它们支撑了许多近期以推理为中心的系统。
A.2 高效推理
推理的测试时扩展通过自适应采样和更丰富的聚合来寻求更好的准确率-计算权衡。在并行轴上,早期停止自一致性(Early-Stopping Self-Consistency, ESC)、推理感知自一致性(Reasoning-Aware Self-Consistency, RASC)、自适应一致性(Adaptive-Consistency)、动态投票(Dynamic Voting)和Dynasor通过减少所需样本数量同时保持准确率,实现了更高效的自一致性(Li等人,2024;Wan等人,2025;Aggarwal等人,2023;Xue等人,2023;Fu等人,2024)。在CoT深度轴上,高效的CoT微调方法引导生成更短、更高效的链(Chen等人,2024b;Luo等人,2025;Hou等人,2025),而Dynasor-CoT(Fu等人,2025)和DEER(Yang等人,2025b)则无需额外训练即可优化推理。其他工作改进了聚合:排名投票(ranked voting)(Wang等人,2025)收集排名候选列表以进行更细致的偏好聚合,似然加权评分(Soft-SC)(Wang等人,2024)在没有单一答案占主导时利用模型概率,以及验证增强投票(verification-augmented voting)使用外部工具过滤逻辑不一致的路径(Toh等人,2024)。互补地,Hassid等人(2025)表明,在多个样本中偏好较短的CoT链可以提高准确率。DeepConf利用局部置信度通过过滤低置信度轨迹来提高准确率;在在线生成中,当局部置信度低于阈值时,它进一步执行早期终止,减少token使用。
A.3 置信度估计
置信度估计技术通过直接量化模型输出的可靠性提供了一个互补的方向。越来越多的研究提出了诸如token级熵和不确定性分数(Fadeeva等人,2024)、基于KL散度的自确定性(Kang等人,2025)以及在微调期间学习的特殊置信度token(Chuang等人,2024;Zhao等人,2025)等指标。同样,Dynasor(Fu等人,2024)使用语义熵(Farquhar等人,2024)作为置信度信号。这些信号已应用于重新排序(Jain等人,2024)、选择性生成(Ren等人,2023)以及高风险领域的拒绝机制(Han等人,2024),并且与原始序列概率相比,它们始终表现出更好的校准性(Geng等人,2024)。
将置信度整合到测试时推理中提供了一种在聚合前评估单个轨迹质量的方法。最近使用全局置信度的结果表明,全局置信度是在序列级别计算的,并在事后应用于在完成的候选者之间进行排名或选择,将多样本推理与置信度感知选择相结合可以在使用更少生成token的同时优于多数投票(Kang等人,2025)。相比之下,DeepConf依赖于轻量级的局部置信度信号,该信号在每个轨迹中更新并触发低置信度轨迹的实时剪枝,从而产生更节省token的并行生成和更高的准确率。
B 消融研究
B.1 共识阈值消融
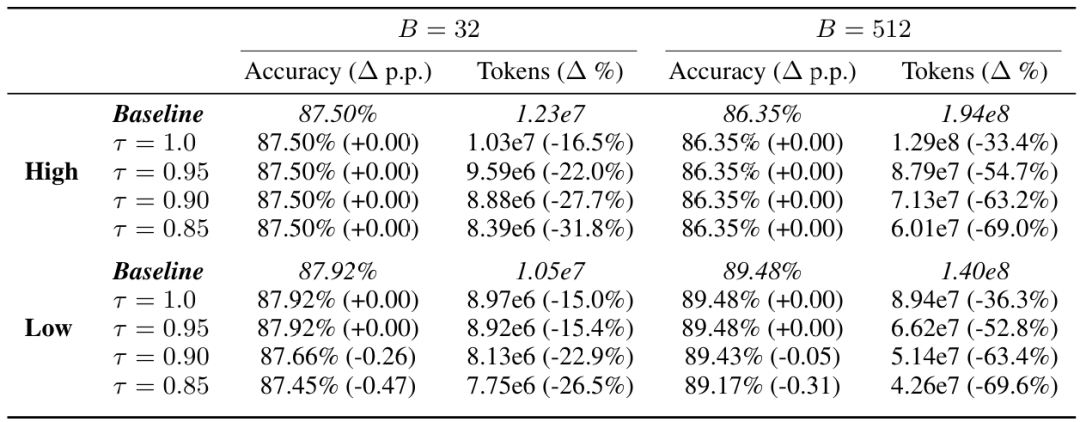
我们在在线算法2中对共识阈值τ进行消融,使用仅基于预算(不使用进行早期停止)作为表3中的基线。在生成条预热轨迹后,我们在每次新轨迹生成前检查模态一致性,如果一致性超过τ,则停止为该问题生成更多样本。我们在AIME24上使用Qwen3-32B进行评估。τ=0.95实现了最佳平衡:它完全保持准确率,同时在B=32/512时节省了15.4%/52.8%的token(DeepConf-low)和22.0%/54.7%(DeepConf-high)。保守的τ=1.0在不降低准确率的情况下削弱了节省。更激进的阈值(τ=0.90,0.85)将节省提高到69.6%,但在DeepConf-low中导致准确率下降(例如,在τ=0.90时下降0.26个百分点),而DeepConf-high即使在τ=0.85时也能保持完美准确率,显示出更大的鲁棒性。由于DeepConf-high在设计上已经保留了更大的轨迹池,改变τ对最终投票的影响较小。此外,在B=512时的token节省比在B=32时更大,因为自适应停止仅适用于=16条预热轨迹之后。在B=512时,它可以截断最多剩余的496次生成,而在B=32时最多只能消除16次。因此,相同的早期终止率在更高预算下转化为更大的相对token减少。总体而言,τ=0.95提供了最佳权衡,在零准确率损失的情况下将token减少一半以上。
表3:共识阈值消融(Qwen3-32B @ AIME24)。我们在投票预算下报告准确率和token使用情况。准确率变化以百分点(p.p.)表示,token变化以百分比变化表示,两者均相对于相同B下的仅预算基线(无自适应早期停止)测量。token计数以科学记数法显示。
在这里插入图片描述
在这里插入图片描述
B.2 预热采样大小消融
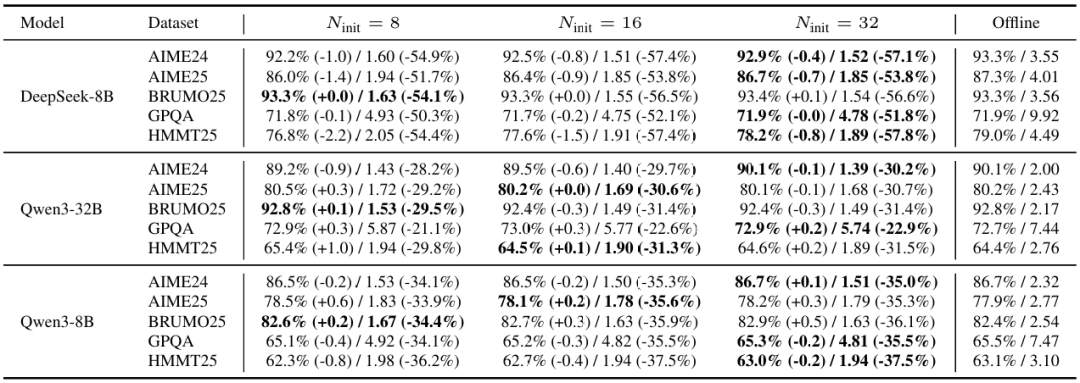
表4比较了在投票预算下,使用在线DeepConf方法的不同预热大小(在DeepConf-low设置下,按置信度保留前η=10%)。在模型和数据集上,我们观察到:增加稳定了用于设置阈值s的经验置信度分布,在实践中通常使在线准确率更接近离线基线(更小);然而,阈值-准确率关系取决于模型和数据集,不一定单调改善。在token方面,净效应由两个因素驱动:(i)更大的固定预热成本,因为所有条轨迹都运行到完成;(ii)预热后剩余条轨迹的早期终止率。由于这些因素相互权衡,总token使用量也不一定随单调变化。经验上,预热大小之间的很小(通常≤1.0个百分点)。因此,我们采用作为平衡的默认值:足够接近离线基线,同时避免过多的预热开销。
表4:固定投票预算下预热大小的影响(在线,DeepConf-Low)。每个在线单元格报告准确率(%)(∆以p.p.表示)和Token使用量(×10⁸)(相对∆以%表示),两者均相对于的离线基线(保留前η=10%;最低组置信度)描述。粗体标记了在线准确率最接近离线基线(最小)的预热大小。最后一列标记为"离线",报告了下的基线(准确率/Token)
在这里插入图片描述
在这里插入图片描述
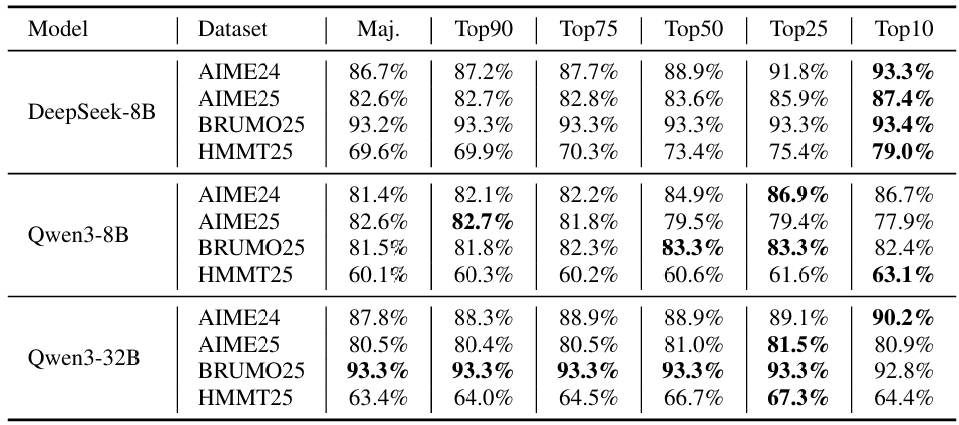
B.3 过滤百分比消融
表5研究了使用最低组置信度指标(组大小2,048)时保留百分比变化的影响。保留率η从顶部90%扫掠到顶部10%。对于每个模型-数据集对,我们在离线设置中扫掠投票大小并报告达到的最佳准确率。在DeepSeek-8B、Qwen3-8B和Qwen3-32B中,更激进的过滤(更小的顶部百分比,保留更少的轨迹)通常在大多数情况下产生更高的准确率,尽管最佳η可能因数据集而异。例如,顶部10%经常实现最佳性能,但对于某些模型-数据集组合,顶部25%或顶部50%可能是最优的,表明理想的过滤阈值取决于任务特性。从机制上看,过滤器优先丢弃低置信度(通常是错误的)轨迹,将投票集中在更高置信度的证据上,从而平均提高准确率。
表5:使用组大小为2048的最低组置信度,不同过滤大小的最佳准确率(%)
在这里插入图片描述
在这里插入图片描述
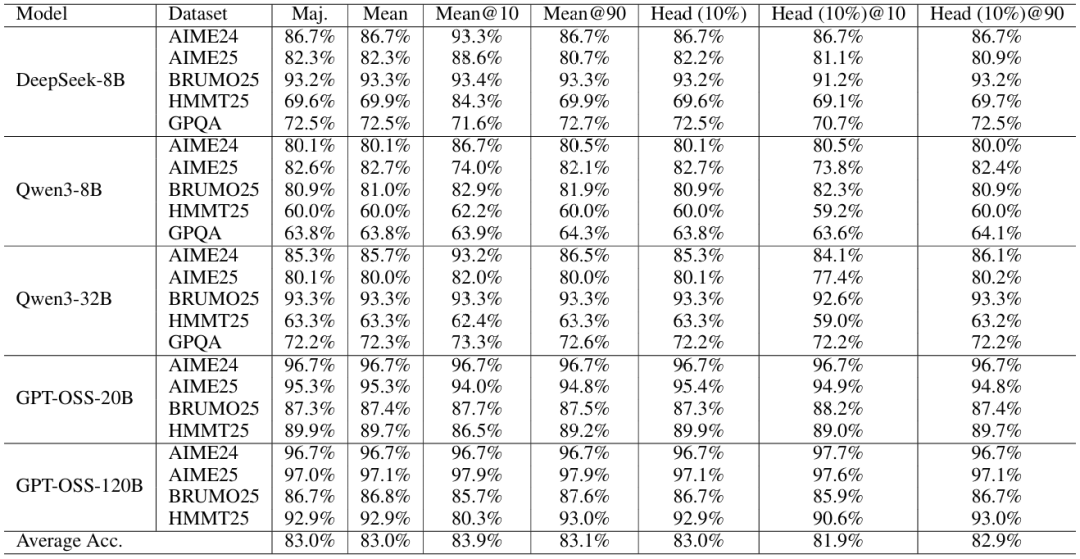
B.4 置信度指标消融
在这个离线消融中,我们报告了每个模型-数据集对在投票大小下的准确率(表6、7、8和9)。我们比较了仅在如何计算每轨迹置信度分数以及是否在投票前进行过滤方面不同的聚合规则。"多数投票"表示不使用置信度加权的标准多数投票。"平均"计算整个轨迹的平均轨迹置信度并使用它来加权投票。"L(w)"表示组大小为w的最低组置信度。"B(q%)"表示底部百分比置信度,它保留底部q%最不置信的组,并从这些选定的组计算平均置信度用于投票权重。对于位置置信度计算,"头部(q%)"仅使用每个轨迹中前q%的token计算置信度,而"尾部(q%)"从最后q%的token计算置信度。"尾部(2k)"无论总轨迹长度如何,都使用最后2,048个token的固定窗口。"@η%"后缀表示过滤机制,在应用相应投票方法前仅保留按置信度排名的前η%轨迹。例如,"平均@10%"首先选择置信度最高的前10%轨迹,然后应用置信度加权投票,而"尾部(2k)@90%"在投票前基于尾部置信度保留前90%的轨迹。
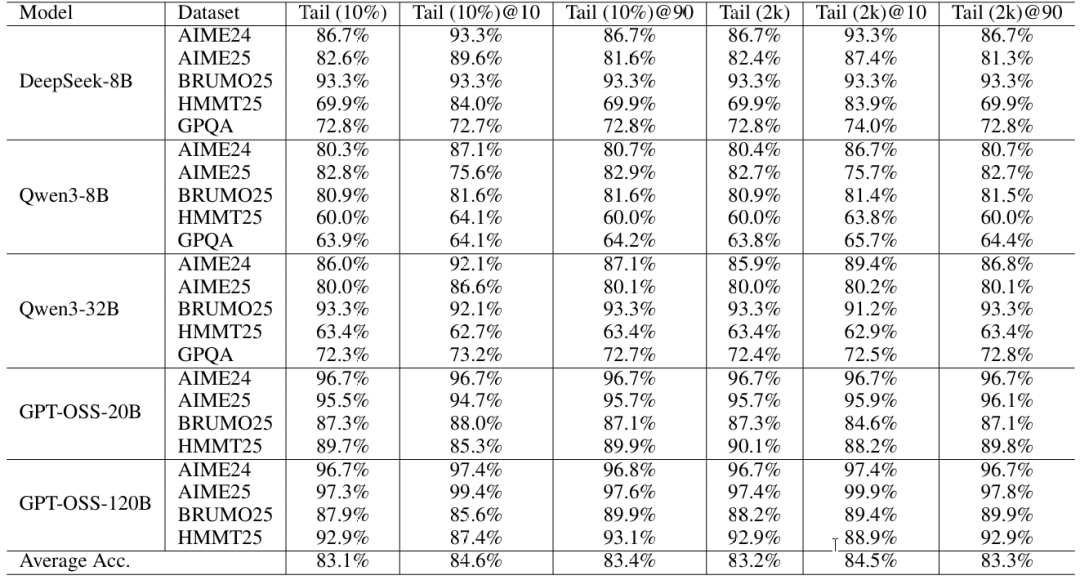
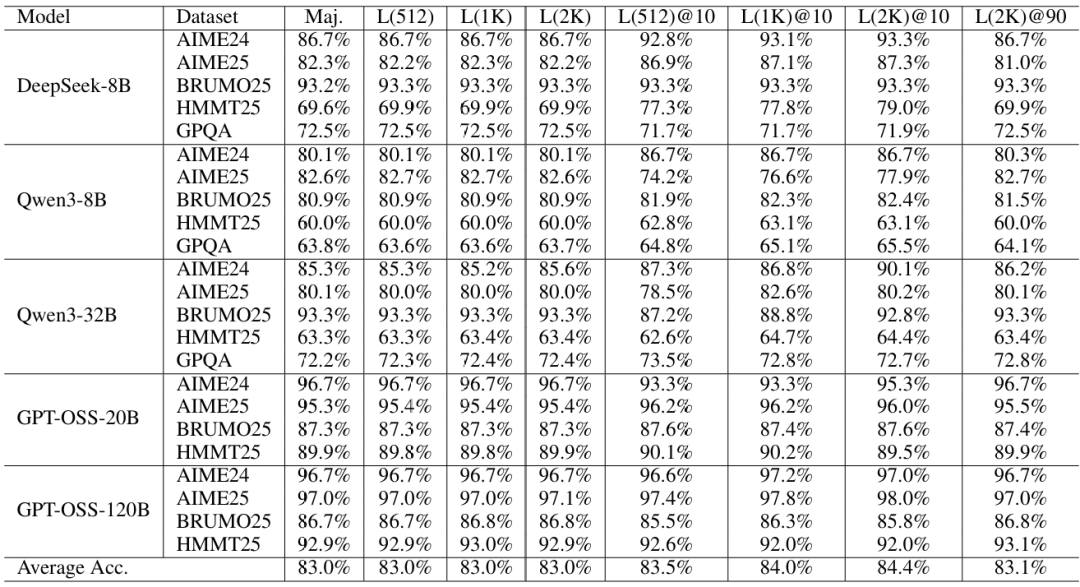
在模型和数据集上,基于头部的置信度与最终正确性相关性较弱,通常与普通多数投票匹配;应用基于头部的过滤甚至平均会损害性能,这反映出早期token主要由设置、释义和探索性规划主导,缺乏判别信号。相比之下,基于尾部和平均的信号通常会产生增益。值得注意的是,在DeepSeek-8B AIME25上,一种尾部变体仅使用8B模型就达到了89.6%的准确率,而在GPT-OSS-120B AIME25上,"尾部(2k)@10%"达到了99.9%。从概念上讲,最低组置信度(LGC)指标是底部百分比置信度的极端情况(它在滑动组上取最小值),但它仍然具有竞争力:在23个模型-数据集对中,LGC(2k窗口)与10%过滤的平均准确率为84.4%,而底部-10%@10%为84.0%,底部-50%@10%为84.0%,高于平均@10%的83.9%。基于尾部的变体是特别可靠的默认选择,"尾部(10%)@10%"和"尾部(2k)@10%"的平均准确率分别为84.6%和84.5%。总体而言,包括尾部、底部和最低在内的局部置信度信号不逊于全局平均轨迹置信度,并且在各种设置中平均提供相等或更好的准确率。
表6:投票大小=512时的准确率(%)。多数投票=多数;平均:平均轨迹置信度;@η=按置信度保留前η%。头部(10%):前10% token。
在这里插入图片描述
在这里插入图片描述
C 离线DeepConf的扩展行为
离线方法应用置信度过滤,然后进行置信度加权多数投票(第3.2节),使用最低组置信度在两种保留设置下进行。我们在5种模型配置和4个数据集(AIME24/AIME25/BRUMO25/HMMT25)上进行评估,总计20个实验设置,对于每种方法,我们变化。结果如图8所示。
保留前90%的轨迹始终与无权重多数投票相匹配或略微优于它,方差较低(-0.21%~+0.73%,平均+0.17%)。
保留前10%在大多数数据集上产生显著增益(20个设置中的12个;+0.26%~+9.38%),在剩余8个设置上有下降(-4.69%~ -0.31%);总体平均改进为+1.22%。这些退化来自于置信度集中在错误答案上的罕见情况("自信错误")。
两种设置都显著优于单样本基线(;即,无投票):前90%提供一致的增益(+5.83%~+16.88%,平均+10.57%),而前10%提供更大的增益(+5.26%~+20.94%,平均+11.62%)。
总体而言,当稳定性至关重要时,前90%是一个安全的选择,而前10%则提供更高的平均性能,但偶尔会出现退化。这些结果证明了使用最低组置信度的离线方法在不同模型规模和数学推理基准测试中的可靠性。我们还在附录E中报告了GPQA-Diamond的结果。
表7:投票规模=512时的准确率(%)@η=按置信度保留前η%。尾部(2k):最后2,048个token;尾部(10%):最后10%的token。
在这里插入图片描述
在这里插入图片描述
表8:投票规模=512时的准确率(%)多数投票=多数;L(x)=具有x个token滑动窗口的最低组置信度;@η=按最低置信度保留前η%。
在这里插入图片描述
在这里插入图片描述
D 在线DeepConf的扩展行为
我们在图9中评估在线设置中的准确率-成本权衡,其中成本计算所有生成的token,包括从早期停止轨迹中部分生成的token。每个问题都使用条轨迹进行预热,以校准共识阈值τ(第3.3节):我们将τ设置为DeepConf-low(前10%)设置的90th百分位,为DeepConf-high(前90%)设置的10th百分位;一旦当前组置信度低于阈值,轨迹就会实时停止。
表9:投票规模=512时的准确率(%)。多数投票=多数;B(q%)=2,048个token滑动窗口内的底部q%置信度;@η=按底部置信度保留前η%。
在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
图8:扩展行为:使用最低组置信度的离线方法在不同模型和数据集上,模型准确率与投票规模的关系。
对完成轨迹的聚合始终使用置信度过滤加上置信度加权多数投票。我们从两个角度将DeepConf与多数投票基线进行比较。
在匹配预算下。我们在表10中将自适应DeepConf-high和DeepConf-low与投票预算为512的多数投票进行比较。在各种模型和数据集上,DeepConf-low产生的成本降低最大,在时比多数投票少43-84%的token,同时通常匹配或提高准确率(例如,DeepSeek-8B/AIME24:-77.9% token,±5.8个百分点;Qwen3-32B/AIME24:-66.8%,+4.7个百分点)。DeepConf-high更为保守,节省约16-59%的token,准确率基本不变。DeepConf-low的显著例外包括Qwen3-8B/AIME25(-4.4个百分点)以及GPT-OSS BRUMO/HMMT上的几个<1个百分点的下降;在GPQA-Diamond上,DeepConf-low仍然节省55-65%的token,准确率变化混合(在±1.5个百分点内)。总体而言,DeepConf-low提供了最佳的效率-准确率权衡,而当最小化准确率变化至关重要时,DeepConf-high是更安全的选择。
表10:在线设置中DeepConf的基准测试。在投票规模512下,AIME24、AIME25、BRUMO25、HMMT25、GPQA-Diamond(可用时;GPQA-Diamond仅适用于DeepSeek/Qwen)上的多数投票和自适应DeepConf-(high/low)的准确率(%)和token(×10⁸)。
在这里插入图片描述
在这里插入图片描述
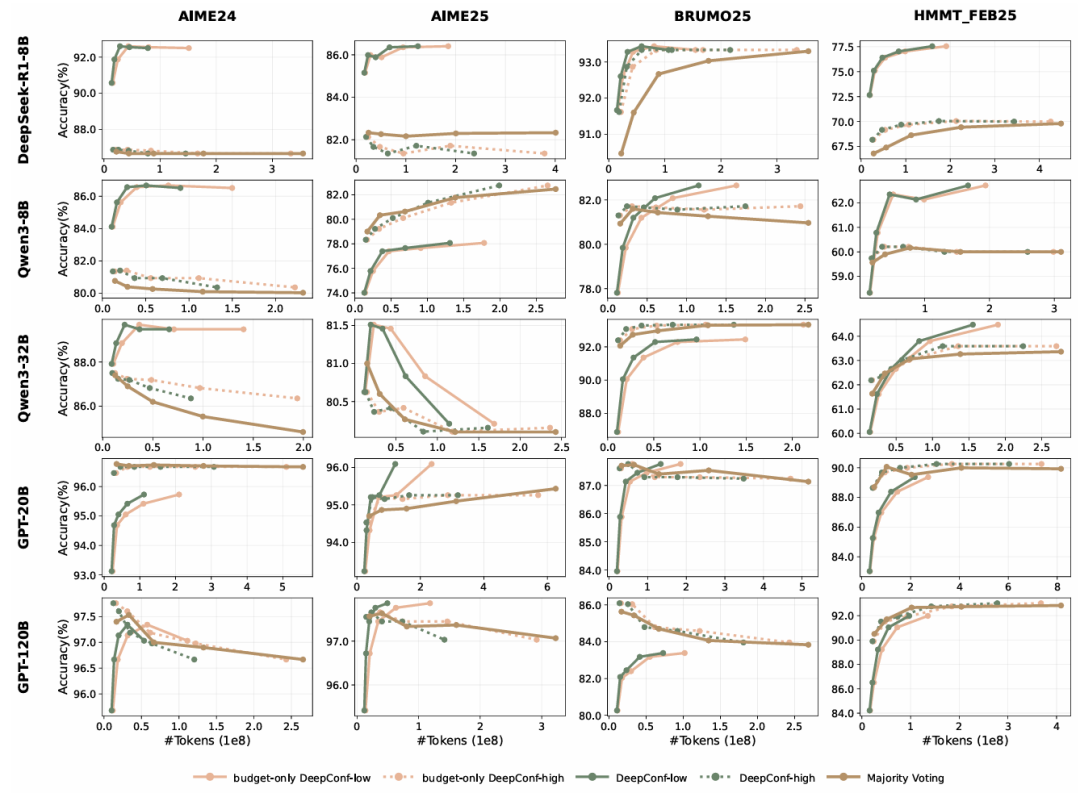
在可比准确率下。我们在两种过滤机制下,将自适应DeepConf(当模态答案达到≥0.95 + 置信度时早期终止,否则继续到预算上限)与仅基于预算的DeepConf(始终运行到完整预算上限)进行比较:High保留置信度最高的前90%轨迹,而Low仅保留前10%。我们在AIME24/AIME25/BRUMO25/HMMT25数据集上对预算规模进行实验(图9)。
与多数投票基线相比,自适应DeepConf-low通常在保持匹配准确率的同时实现19-96%的token减少,而自适应DeepConf-high则以接近等效的性能提供13-84%的节省。然而,在范围内存在几个例外,其中无法在减少token消耗的同时匹配多数投票准确率:DeepConf-low:Qwen3-8B/AIME25、Qwen3-8B/BRUMO25、Qwen3-32B/BRUMO25、GPT-20B/AIME24、GPT-20B/BRUMO25、GPT-20B/HMMT25、GPT-120B/BRUMO25、GPT-120B/HMMT25;DeepConf-high:DeepSeek-8B/AIME25。
总体而言,DeepConf-low过滤在成功案例中提供了最显著的效率增益,而当最小化准确率下降至关重要时,DeepConf-high过滤代表了更为保守的选择。与仅基于预算的DeepConf相比,自适应DeepConf始终主导token-准确率Pareto前沿:在相同的投票集成规模下,它在不牺牲准确率的情况下消耗更少的token(例如,DeepSeek-8B/AIME24@512:Low为0.782×10⁸ VS 1.512×10⁸ token;GPT-120B/HMMT25 @512:High为2.782×10⁸ VS 3.679×10⁸)。因此,当优先考虑计算效率时,我们将自适应DeepConf作为默认配置。
在这里插入图片描述
在这里插入图片描述
图9:扩展行为:使用在线DeepConf在不同模型和数据集上,模型准确率与token成本的关系。
E GPQA-DIAMOND结果
在本节中,我们展示了我们的方法应用于GPQA-Diamond数据集上的DeepSeek-8B、Qwen3-8B和Qwen3-32B的性能。使用最低组置信度的离线结果如图10所示。我们的方法在峰值准确率方面匹配或超过多数投票基线。在Qwen3-8B和Qwen3-32B上,保留前10%优于基线,而在DeepSeek-8B上,保留前90%大致匹配基线,保留前10%表现略低。总体而言,保留前90%代表更安全的选择,始终匹配或超过基线准确率,而保留前10%通常获得更大的增益,但偶尔可能表现不佳。与每个问题仅生成一个答案相比,两种变体都提供了约6%的明显平均改进。
在线方法的性能如图11所示。与固定方法相比,自适应策略在相同投票预算下始终实现更大的token使用减少。与离线结果一致,DeepConf-high通常以保守方法保持多数投票准确率,而DeepConf-low追求更大的计算节省,但在DeepSeek-8B上可能表现不佳。这些结果与4.2和4.3节中报告的发现一致。
在这里插入图片描述
在这里插入图片描述
图10:扩展行为:GPQA-Diamond上不同方法的模型准确率与预算规模的关系。
在这里插入图片描述
在这里插入图片描述
图11:扩展行为:GPQA-Diamond上不同方法的模型准确率与token成本的关系。
## F 实验设置
在线DeepConf超参数。表12总结了我们运行中使用的设置(和投票预算B),包含两种配置:DeepConf-low()和DeepConf-high()。
生成超参数。我们在下面列出了所有实验中使用的每个模型的解码超参数。对于每个模型,我们固定温度、top-p、top-k和最大生成长度,并使用每个模型的原生分词器。短横线(-)表示该控制未应用(例如,如果top-k为—,采样仅使用top-p截断)。
表11:实验中使用的生成超参数。不同模型使用不同的解码设置。短横线(—)表示该选项未应用。
在这里插入图片描述
在这里插入图片描述
提示模板。对于Qwen3和GPT-OSS,我们在每个问题提示后附加相同的指令:"请逐步推理,并将最终答案放在\boxed{}内"。对于GPT-OSS,我们还保留提供商的官方系统提示并启用reasoning_effort=high设置。对于DeepSeek-8B,我们使用官方系统提示并将问题放在用户消息中。
在所有情况下,最终答案应出现在\boxed{}内,并在后处理中提取。解码仅在生成结束序列标记或达到最大生成长度时终止。
表12:在线DeepConf(算法2)的超参数。表示离线预热中使用的初始轨迹数量;η是形成的过滤百分位(我们将保留前η%的轨迹);τ是在线共识阈值;B是最大预算(轨迹数量)。

在这里插入图片描述
在这里插入图片描述
G 对vLLM的最小编辑以支持DeepConf
G.1 环境和提交
我们在以下设置中对vLLM进行最小修改以实现DeepConf并进行评估:
- vLLM: 提交 31f09c615f4f067dba765ce5fe7d00d880212a6d;
- Python: 3.12.0;
- CUDA: 12.8.
G.2 做了哪些更改(高层级)
我们仅在vLLM中修改了两个地方:
- 扩展LogprobsProcessor以维护滑动窗口置信度并暴露check_conf_stop()。
- 在output_processor.py中,在构建RequestOutput之前插入单个提前停止检查。
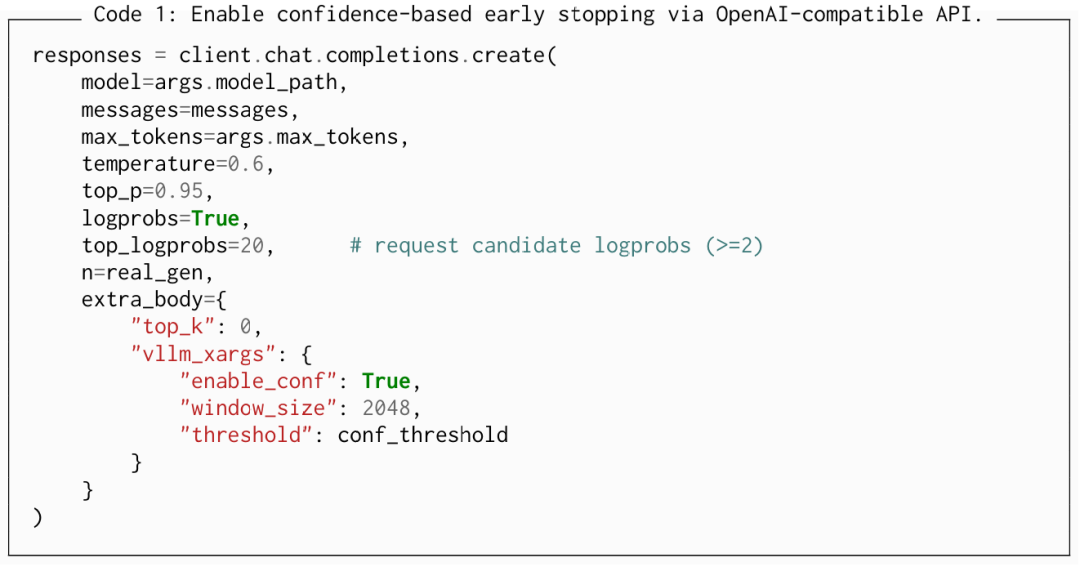
G.3 如何启用(OpenAI兼容API)
该功能通过OpenAI兼容的chat.completions端点按请求切换。参数通过extra_body["vllm_xargs"]传递并由vLLM转发到SamplingParams.extra_args。
代码1:通过OpenAI兼容API启用基于置信度的提前停止。
在这里插入图片描述
注释:除非logprobs=True且top_logprobs>=2,否则提前停止逻辑不活跃。window_size是置信度窗口长度;threshold是我们方法使用的截止阈值。top_k=0(可选)禁用top-k截断。
精确编辑(复制粘贴指南)
不需要补丁工具;将以下代码片段复制到指定文件中。建议固定到上述提交以避免API漂移。
G.4 文件:vllm/v1/engine/logprobs.py
步骤1:导入。在顶部附近添加:
from collections import deque
from typing import Optional, List
步骤2:扩展数据类。在class LogprobsProcessor内部添加:
# --- 用于基于置信度的提前停止的字段
conf_grouped: float
conf_list: Optional[List[float]]
conf_group_list: Optional[deque]
conf_group_size: int
conf_threshold: Optional[float]
步骤3:从请求初始化。在from_new_request(...)中,紧接在return cls(...)之前插入:
if hasattr(request.sampling_params, "extra_args") \
and request.sampling_params.extra_args is not None \
and request.sampling_params.extra_args.get("enable_conf", False):
conf_group_size = request.sampling_params.extra_args.get("window_size", 2048)
conf_threshold = request.sampling_params.extra_args.get("threshold", 17)
conf_grouped = 0.0
conf_group_list = deque(maxlen=conf_group_size)
conf_list = []
else:
conf_group_size = -1
conf_threshold = None
conf_grouped = 0.0
conf_group_list = None
conf_list = None
然后在return cls(...)调用中包含以下字段:
1 conf_group_size=conf_group_size,
2 conf_grouped=conf_grouped,
3 conf_list=conf_list,
4 conf_threshold=conf_threshold,
5 conf_group_list=conf_group_list,
步骤4:停止检查辅助方法。在类内部添加此方法:
def check_conf_stop(self) -> bool:
"""如果置信度窗口触发提前停止,则返回True。"""
if self.conf_group_list is None or len(self.conf_group_list) == 0:
return False
# 需要完整窗口;当移动平均低于阈值时触发。
return (len(self.conf_group_list) >= self.conf_group_size and
self.conf_grouped / len(self.conf_group_list) < self.conf_threshold)
步骤5:在采样期间更新置信度。在_update_sample_logprobs(...)末尾(在附加logprob字典之后)添加:
if self.conf_list is not None:
# logprobs[0]是采样的token;使用剩余候选
if len(logprobs) > 1:
new_conf = -sum(logprobs[1:]) / len(logprobs[1:])
else:
new_conf = 0.0
self.conf_list.append(new_conf)
if len(self.conf_group_list) < self.conf_group_size:
self.conf_group_list.append(new_conf)
self.conf_grouped += new_conf
else:
self.conf_grouped -= self.conf_group_list.popleft()
self.conf_group_list.append(new_conf)
self.conf_grouped += new_conf
G.5 文件:vllm/v1/engine/output_processor.py
步骤6:在解码循环中调用停止检查。在以下代码后立即插入:
req_state.logprobs_processor.update_from_output(engine_core_output)
插入:
# 基于置信度的提前停止(我们的)
if req_state.logprobs_processor.check_conf_stop():
finish_reason = FinishReason.STOP
stop_reason = f"<gconf<{req_state.logprobs_processor.conf_threshold}>"
(保持后续构建RequestOutput的逻辑不变。)
G.6 附加说明
- 除非enable_conf=True且logprobs>0(我们使用top_logprobs=20),否则该功能不活跃。
- 置信度是固定窗口(window_size)上候选对数概率的负平均值的移动平均。
- 触发时,我们设置FinishReason.STOP并将stop_reason注释为<gconf>以供追踪。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号