MetisX:CXL内存计算-未来数据中心架构

MetisX:CXL内存计算-未来数据中心架构

数据存储前沿技术
发布于 2025-02-11 18:38:10
发布于 2025-02-11 18:38:10
问题意识
- • 内存墙问题的严重性: 随着AI模型的规模继续扩大,数据移动的瓶颈将越来越明显。如何通过CXL等技术打破内存墙,并提高数据传输的效率,是当前急需解决的关键问题。
- • 领域专用架构的必要性: 通用架构已无法满足特定领域(如AI、图数据库、网络)的需求。如何进一步优化领域专用架构,以提高计算和内存的协同效率,是未来计算架构设计的重要方向。
- • 数据中心成本优化的挑战: CXL内存计算虽然为数据中心带来了显著的优化,但如何平衡性能提升与成本控制,以及如何确保数据中心在不断增长的数据需求下保持可扩展性和经济性,依然是未来需要持续优化的方向。

关于 MetisX[1]
MetisX成立于2022年,总部位于首尔。致力于开发基于Compute Express Link (CXL)技术的智能内存解决方案,旨在推动数据为中心的计算发展。MetisX专注于内存和内存为中心的计算架构,其产品通过CXL协议扩展内存容量和带宽,而不增加CPU中的内存通道数量,从而提高系统效率。
背景
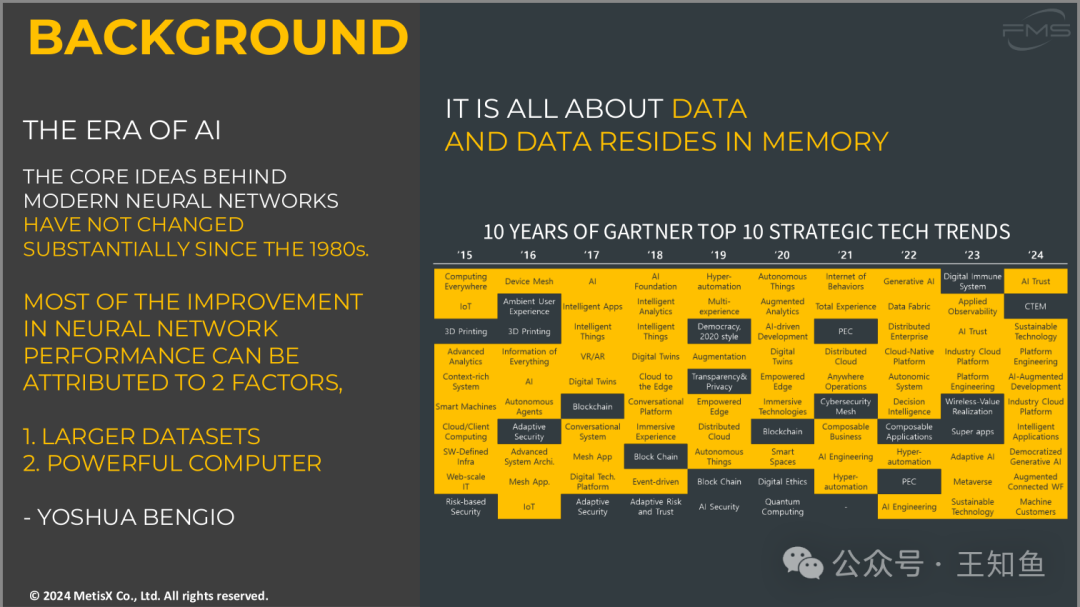
1. AI时代:
现代神经网络的核心思想自1980年代以来并没有显著变化。当前的AI系统仍然基于几十年前提出的深度学习和反向传播等基础理论。
2. 性能提升的两个关键因素:
- 更大的数据集:更多的数据使模型的训练效果更好,预测更准确。
- 强大的计算能力:计算硬件(如GPU和TPU)的进步使复杂模型的训练时间大大缩短。
3. 数据驱动:
AI的进步依赖于数据,数据是AI模型成功的关键,特别是在深度学习领域,数据和存储能力至关重要。
4. Gartner十年科技趋势:
展示了2015-2024年间的科技趋势,从早期的物联网、AI、区块链等技术到最近的生成式AI、AI信任和可持续技术等。

问题意识
1. 数据和AI模型规模的快速增长:
虽然数据量在迅速增加,但AI模型的增长速度更快。图表显示了AI模型参数数量的指数级增长,尤其是从2015年开始,模型大小每4个月翻倍。
2. 内存墙问题:
随着模型规模的增大,内存和计算资源的瓶颈(即“内存墙”)越来越严重,阻碍了性能的进一步提升。
- 带宽、延迟、容量问题限制了数据从内存到CPU的传输速度。
- 计算能力难以跟上数据和模型的增长。
- 高成本:内存非常昂贵,占据了服务器成本的很大一部分。
- 低利用率:内存利用率很低,造成资源浪费。
内存墙问题已经成为数据中心的一大难题,尤其是在处理规模庞大的AI模型时。
Note:继VAST在智能数据平台提出实时计算的远景,AI在业务场景可用性与数据现场的距离再次拉近,这对当前IT系统的性能和时延提出挑战,而“内存墙”是高性能场景绕不开的问题。
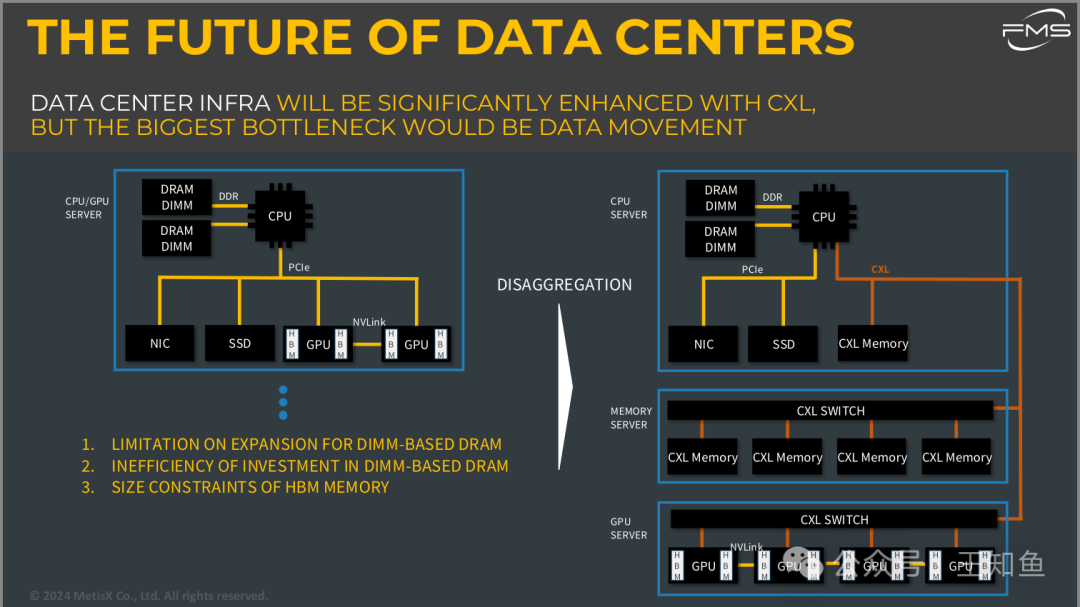
数据中心的未来
1. 当前架构的局限性:
- DIMM扩展限制:基于DIMM(双列直插式内存模块)的DRAM内存扩展受限,难以满足不断增长的需求。
- 效率低下:继续投资于DIMM的成本效益低,随着数据需求增长,传统内存结构难以有效应对。
- HBM(高带宽内存)的尺寸限制:虽然HBM具有较高的带宽,但其物理尺寸限制了在更大规模系统中的应用。
2. 未来的分解架构(Disaggregation):
- CXL的引入:通过CXL技术,数据中心可以将内存资源从CPU服务器中分解(Disaggregation),使得内存和计算资源之间的连接更加灵活,提升资源的利用效率。
- 内存服务器和GPU服务器:未来的架构中,CXL内存可以通过CXL交换机(CXL Switch)连接到多个CPU或GPU服务器,实现共享和高效的数据移动。
3. 瓶颈仍然是数据移动:虽然CXL可以显著提高内存的利用效率和扩展性,但数据移动依旧是一个主要瓶颈,尤其是在大规模AI和高性能计算应用中,数据传输速度对整体性能有着关键影响。
Note:关于数据移动,存储器厂商如Samsung在SSD主控上关注数据移动效率,参考:
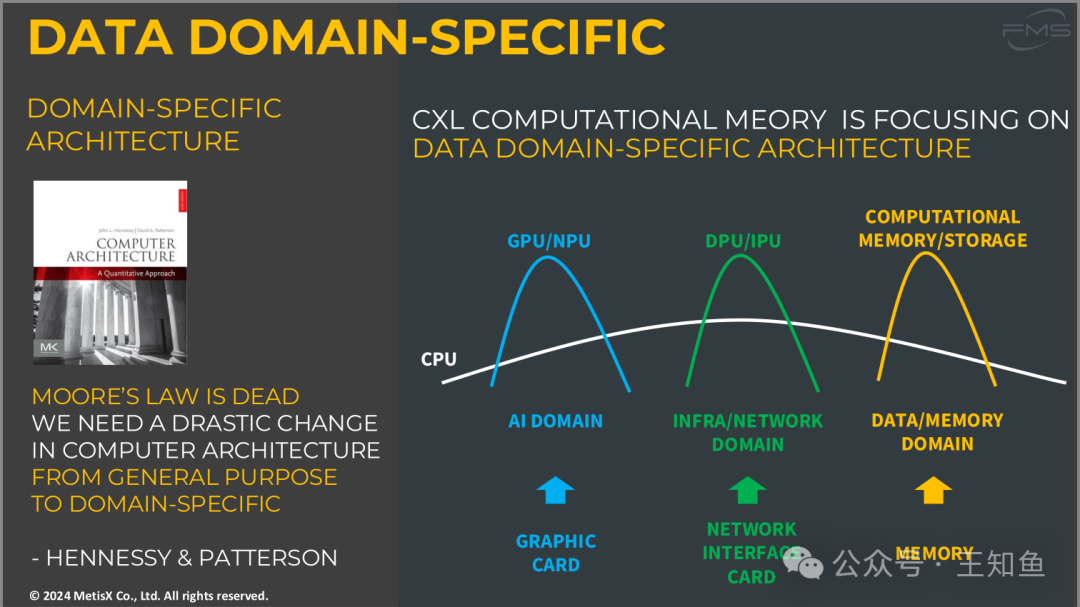
数据领域专用架构(Data Domain-Specific Architecture)
1. 领域专用架构的必要性:
- 摩尔定律已失效:随着摩尔定律的放缓,传统的通用处理器(CPU)的性能增长已无法跟上数据和计算需求的增长。因此,需要转向领域专用架构来提高效率。
- 从通用架构到专用架构的转变:John Hennessy和David Patterson指出,计算架构需要发生重大变化,从通用架构转向为特定领域优化的专用架构,以更好地应对不同类型的计算任务。
2. CXL计算架构的聚焦点:
CXL(Compute Express Link)正在专注于数据领域专用架构,以优化不同领域的计算需求。
- AI领域(GPU/NPU):图形卡和神经网络处理器(NPU)专门针对AI计算进行优化。
- 基础设施/网络领域(DPU/IPU):数据处理单元(DPU)和基础设施处理单元(IPU)用于提升网络和基础设施相关任务的性能。
- 数据/内存领域(存储与内存):新的存储和内存计算架构将用于优化数据密集型的任务,提升内存带宽和效率。
3. 不同领域的计算需求:
不同计算领域的需求差异显著,因此领域专用硬件(如图形卡、网络接口卡和内存等)能够显著提升各自领域的性能,取代通用架构在效率上的不足。
关于John Hennessy和David Patterson
John L. Hennessy 和 David A. Patterson 是计算机科学领域的两位著名学者,他们在计算机架构领域的贡献极为深远,尤其是关于精简指令集(RISC)和计算机体系结构方面的工作。他们共同编写的经典著作《Computer Architecture: A Quantitative Approach》是计算机体系结构的权威教材之一。下面是对他们的简介及其著作的介绍:
John L. Hennessy
- • 背景:Hennessy 是美国计算机科学家、前斯坦福大学校长。他与Patterson合作在1980年代推动了RISC(精简指令集计算机)的发展,这一架构后来成为了现代处理器设计的基础,广泛应用于各类计算设备。
- • 贡献:除了RISC之外,Hennessy在多处理器系统、编译器优化以及处理器性能评估方面的研究也极具影响力。他的研究为当代的高效计算做出了巨大贡献。
David A. Patterson
- • 背景:Patterson 是加州大学伯克利分校的计算机科学教授,同样是计算机体系结构领域的巨擘。除了与Hennessy合作开发RISC,他还对RAID(独立磁盘冗余阵列)技术的提出和推广起到了重要作用,这项技术现已成为存储系统的标准。
- • 贡献:Patterson 的研究在并行计算、存储系统、计算机安全等领域都有深远影响。他也是加州大学伯克利分校提出的RISC-V指令集架构的创始人之一,这一开源架构近年来得到了广泛关注和应用。
《Computer Architecture: A Quantitative Approach》[2]
- • 内容简介:该书首次出版于1990年,至今已出版多版,每一版都紧跟技术发展前沿,详细分析了计算机架构设计的最新挑战和解决方案。书中的方法论着重于用定量分析的方法来评估和设计计算机系统,特别是通过性能、能耗、面积和成本等参数来进行平衡。
- • 影响:这本书是全球范围内计算机架构教学的标准教材,也是计算机系统设计领域的权威参考。它涵盖了从处理器、存储器层次结构到并行计算的各个方面,并通过案例研究和实验室练习帮助读者掌握实际设计和分析技能。
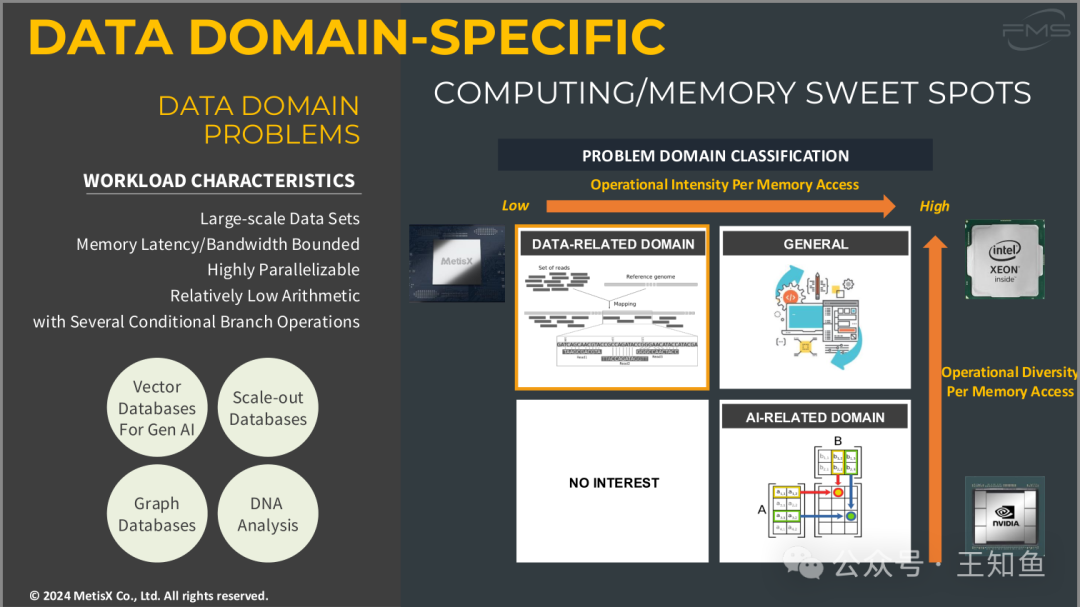
数据领域问题(Data Domain Problems)
- 工作负载特点(Workload Characteristics):
数据领域的工作负载具有以下几个特点:
- 需要处理大规模数据集。
- 内存延迟和带宽是性能的主要限制因素。
- 任务具有高度并行化的潜力。
- 算术计算需求相对较低,但涉及多个条件分支操作。
这些特点表明,数据密集型计算的瓶颈通常是内存访问,而非计算能力本身。
- 应用场景:
典型的数据领域应用包括:
- 向量数据库(Vector Databases for Gen AI)
- 大规模数据库(Scale-out Databases)
- 图数据库(Graph Databases)
- DNA分析(DNA Analysis)
计算与内存的最佳平衡点(Computing/Memory Sweet Spots)
右侧的图展示了不同问题领域的分类(Problem Domain Classification),主要依据每次内存访问的操作强度(Operational Intensity)和操作多样性(Operational Diversity)来区分:
- 数据相关领域(Data-Related Domain):
这一类任务的运算密度较低,且大多数时间花在内存访问上,如基因组映射等。这类任务更多依赖高效的内存管理。
- AI相关领域(AI-Related Domain):
这一类任务需要大量的计算资源(如AI推理、深度学习等),并且每次内存访问涉及多样化的计算操作。这类任务适合高性能计算硬件,如图形处理器(GPU)。
- 通用领域(General Domain):
一些任务既涉及计算也需要良好的内存访问性能,这类任务分布较为广泛,适合使用通用处理器(如Intel Xeon)。
- 没有兴趣的领域(No Interest):
这一块表示当前讨论不涉及的领域,可能指的是那些既不要求高计算性能,也不强调内存性能的任务。
问题分类依据:
- 低运算强度/高内存访问任务:如数据相关领域。
- 高运算强度/高多样性任务:如AI相关领域。
- 中等运算强度和内存访问需求的通用任务:适用于多种应用的通用计算领域。
总结:
强调了在不同领域中,计算与内存之间的需求存在显著差异。数据密集型任务和AI任务的瓶颈分别在于内存带宽与计算能力,因此需要针对这些领域的专用硬件架构,以更好地优化性能。
Note:当前对GPU/计算加速卡的关注可能是短暂过热的,更别说取代通用计算,加速计算优化的是专用场景下计算效率,而绝大部分需求仍然是通用,随着AI工作流的在线方案逐渐成熟,相信通用计算又将迎来新的快车道。
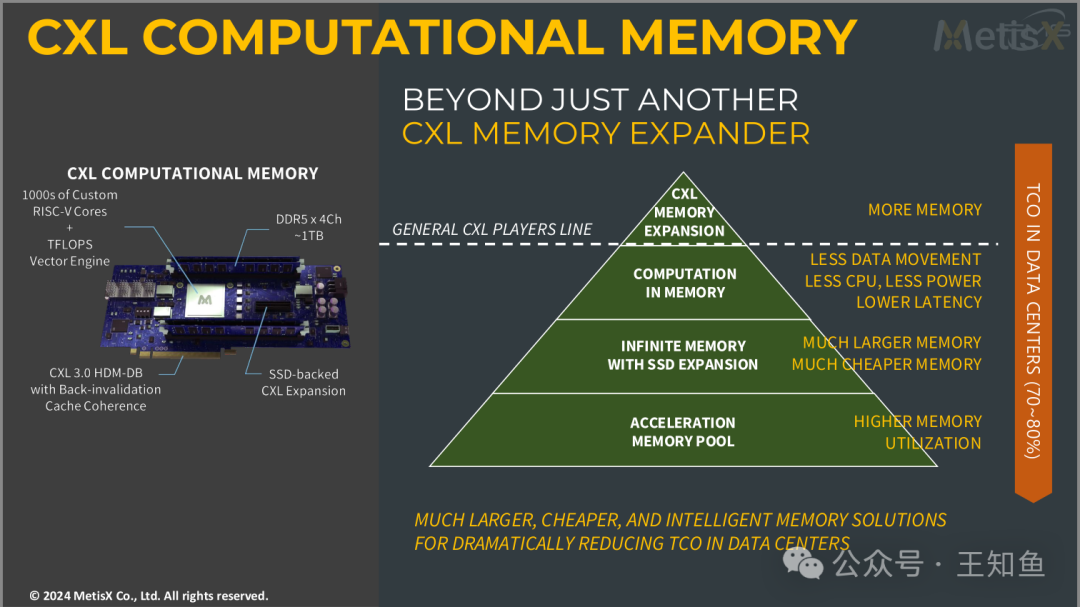
产品:基于CXL的内存计算扩展卡
内存计算卡特点:
- • RISC-V内核与矢量引擎:CXL内存计算配备了成千上万个定制的RISC-V内核和高性能的TFLOPS矢量引擎,能够提供强大的计算能力。
- • DDR5内存支持:具备DDR5(4通道)的内存扩展,支持约1TB的存储容量,为高带宽、低延迟的数据处理提供保障。
- • CXL 3.0:支持CXL 3.0技术,并具有失效缓存一致性(Back-invalidation Cache Coherence)的特性,使得内存和处理器之间的数据一致性得以优化。
- • SSD扩展:通过SSD支持的CXL扩展,可以实现更大规模的内存存储空间,适合处理大规模数据集。
CXL内存计算卡不仅仅是一个普通的内存扩展器,它提供了四层架构来优化数据中心的整体成本和性能:
- • CXL内存扩展:通过CXL实现的基础内存扩展,为系统提供了更多的内存资源,减少了数据移动、降低了CPU的使用率、功耗和延迟。
- • 内存计算(Computation in Memory):通过直接在内存中进行计算,减少数据传输的开销,提高系统效率。
- • SSD扩展下的无限内存:结合SSD的扩展,提供了几乎无限的内存容量,同时降低了内存成本,特别适合大数据和云计算的需求。
- • 加速内存池(Acceleration Memory Pool):通过更高效的内存利用率,加速各种工作负载的执行。
Note:MetisX 内存计算卡与其他厂商CXL内存扩展之间有区别,首当其冲是采用RISC-V作为计算核,与常见FPGA的路线有差异;卡上集成DDR5内存和持久化SSD,则更像是Type2/3的综合方案,与Samsung的Memory-Semantic SSD产品非常接近。
其他厂商的CXL方案,参考:
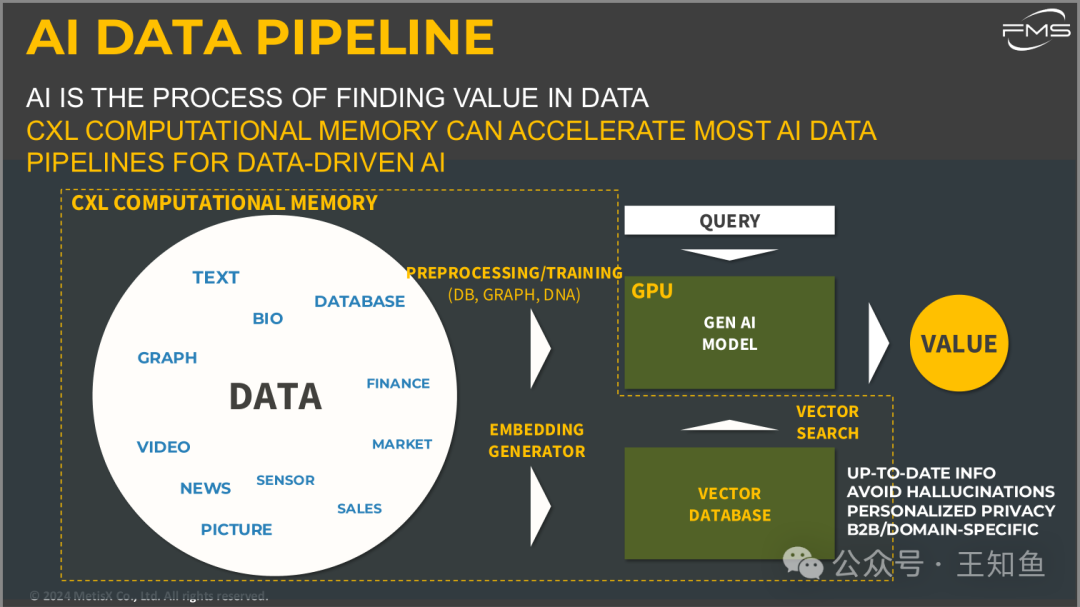
AI数据管道(AI Data Pipeline)
AI数据管道(AI Data Pipeline)以及CXL内存计算如何加速基于数据驱动的AI流程。
1. AI数据管道的定义:
- • AI的核心是从数据中发现价值,即通过处理和分析数据,提取有用的见解和信息。
- • CXL内存计算通过加速AI数据管道的多个阶段,提高了处理效率,特别是在大规模数据集的预处理、嵌入生成和查询阶段。
2. AI管道中的流程:
- • 预处理和训练:在这一阶段,数据通过数据库、图数据或DNA等模型进行预处理和训练。CXL内存计算的优势在于加速这一过程,特别是在处理大规模数据时。
- • 嵌入生成器(Embedding Generator):预处理后的数据被转化为嵌入表示,用于进一步的AI任务。
- • AI生成模型(Gen AI Model):生成式AI模型通过处理这些嵌入和数据,生成结果或做出预测。
- • 向量数据库与向量搜索(Vector Database and Search):通过向量数据库进行查询和搜索,帮助找到数据的相关信息。
3. 生成价值:
最终,通过AI模型处理后的数据将生成价值。这些价值可以体现在:
- • 提供最新的数据信息。
- • 避免AI模型生成错误或“幻觉”。
- • 提供个性化和隐私保护的解决方案。
- • 适用于特定领域或B2B场景。
CXL内存计算如何加速AI数据管道的各个阶段,特别是在处理大量数据的AI应用中,提升预处理和训练效率,支持向量数据库的查询,加速数据驱动的AI应用从数据到价值的生成过程。
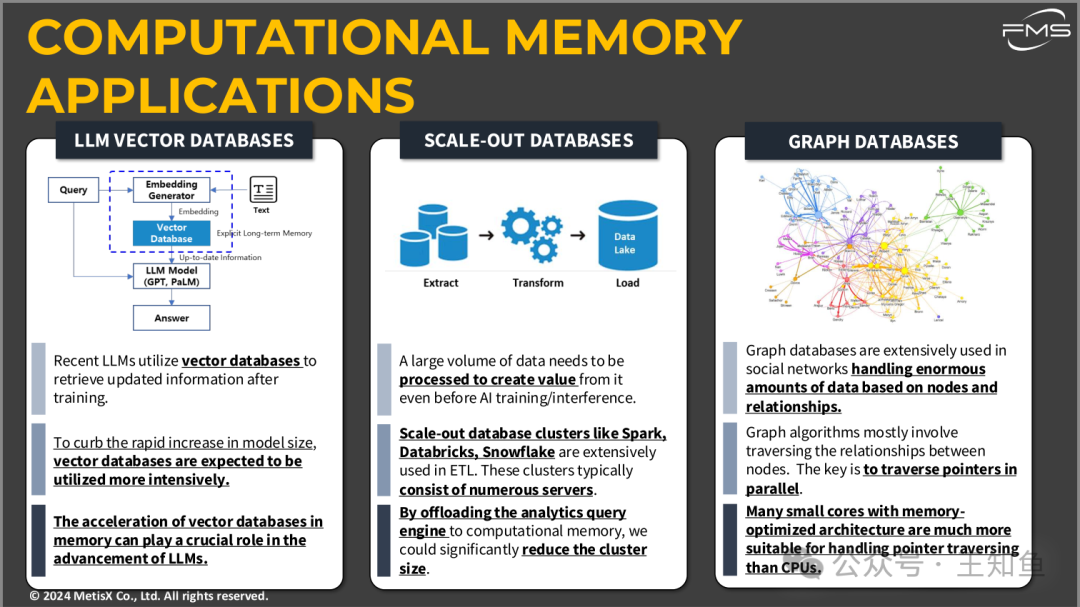
内存计算的应用场景,涵盖了向量数据库、横向扩展数据库(Scale-out Databases)和图数据库的不同应用领域。
1. LLM向量数据库(LLM Vector Databases)
- • 应用背景:最新的大型语言模型(LLMs)如GPT、PaLM,利用向量数据库在训练后检索最新的信息。
- • 重要性:为了抑制模型规模的快速增长,向量数据库将被更加广泛地使用。向量数据库能够加速检索操作,提供高效的嵌入生成和信息查询。
- • 作用:向量数据库加速器在内存中的作用,对于LLM的发展至关重要,它能帮助这些模型从大规模数据中更快速地提取和更新信息。
2. 横向扩展数据库(Scale-out Databases)
- • 数据处理挑战:在AI训练或推理之前,必须对大量的数据进行处理,以便从中提取有价值的信息。
- • 典型应用:类似于Spark、Databricks和Snowflake的横向扩展数据库集群,广泛用于数据提取、转换和加载(ETL)流程。这些集群通常由大量的服务器组成。
- • 优化潜力:通过将分析查询引擎的工作卸载到内存计算,可以显著减少集群的规模,提升处理效率并降低硬件成本。
3. 图数据库(Graph Databases)
- • 应用场景:图数据库被广泛用于社交网络等场景中,处理基于节点和关系的海量数据。
- • 图算法的特点:图算法主要涉及遍历节点之间的关系,而高效的关系遍历是图数据库的重要性能需求。
- • 优化方案:通过使用具有内存优化架构的小核心,能够更高效地并行处理指针遍历任务,这比传统的CPU更适合处理这种关系数据的大规模遍历。
关键要点
- 1. 数据中心面临的挑战包括数据增加、内存墙问题和数据运动瓶颈等。
- 2. CXL 内存计算技术可以解决这些问题,提高计算效率和降低能耗。
- 3. CXL 内存计算技术是一种面向特定领域的架构,可以加速各种人工智能数据管道。
- 4. CXL 内存计算技术可以应用于多种领域,如数据库、图形界面和嵌入式系统等。
- 5. CXL 内存计算技术的优势在于更大、更便宜、更智能的内存解决方案,可以显著降低成本并提高数据中心的利用率。
引用链接
[1] 关于 MetisX: https://metaso.cn/s/PDqrhde
[2] 《Computer Architecture: A Quantitative Approach》: http://url.trylab.site/ComputerArchitecture
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-10-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号