全球数据泄露事件分析:隐私保护的紧迫性
原创
全球数据泄露事件分析:隐私保护的紧迫性
原创
C4rpeDime
发布于 2024-12-28 18:29:14
发布于 2024-12-28 18:29:14
引言
在数字化时代,数据泄露事件不仅是技术问题,更是社会问题。随着互联网的普及和数据的快速增长,个人信息的保护变得愈发重要。本文将探讨数据泄露对个人隐私的影响,分析数据泄露事件的全球性与严重性,并详细讨论Telegram社工库与数据泄露的关系,以及近几年国内外大规模数据泄露事件的具体案例。
数据泄露对个人隐私的影响
数据泄露事件的后果是多方面的,包括个人隐私受损、金融安全受威胁、企业形象受损以及法律责任和处罚。社会信任危机也是数据泄露事件频发后的一个严重后果,它会导致整个社会对数据安全的信任危机,客户可能会对企业和互联网服务失去信任,这对互联网行业的发展和整个社会的信息化进程将带来严重阻碍。此外,数据泄露还可能导致心理健康问题,受害者可能会经历焦虑、抑郁等情绪困扰。
数据泄露事件的全球性与严重性
2024年全球窃密泄密事件频发,涉及多个国家及关键行业,如电信、医疗和云服务。这些事件不仅给国家、企业和个人带来了巨大影响,也引发了全球对国家安全、数据安全和个人隐私保护的深刻反思。各国政府和国际组织开始加强合作,制定更为严格的数据保护法规,以应对日益严重的数据泄露问题。
Telegram社工库与数据泄露
1. Telegram社工库的定义与功能
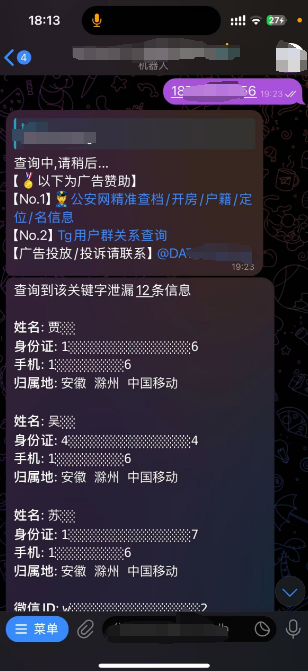
Telegram社工库是一个非法的数据交易和共享平台,其功能包括数据存储和查询。社工库中存储的数据种类繁多,包括个人信息如姓名、电话号码、地址和邮箱等,这些信息来源多样,可能包括黑客攻击、钓鱼网站、恶意软件等非法手段。社工库的存在使得个人信息的安全性面临更大威胁,黑客和犯罪分子可以轻易获取大量敏感信息。
01.png
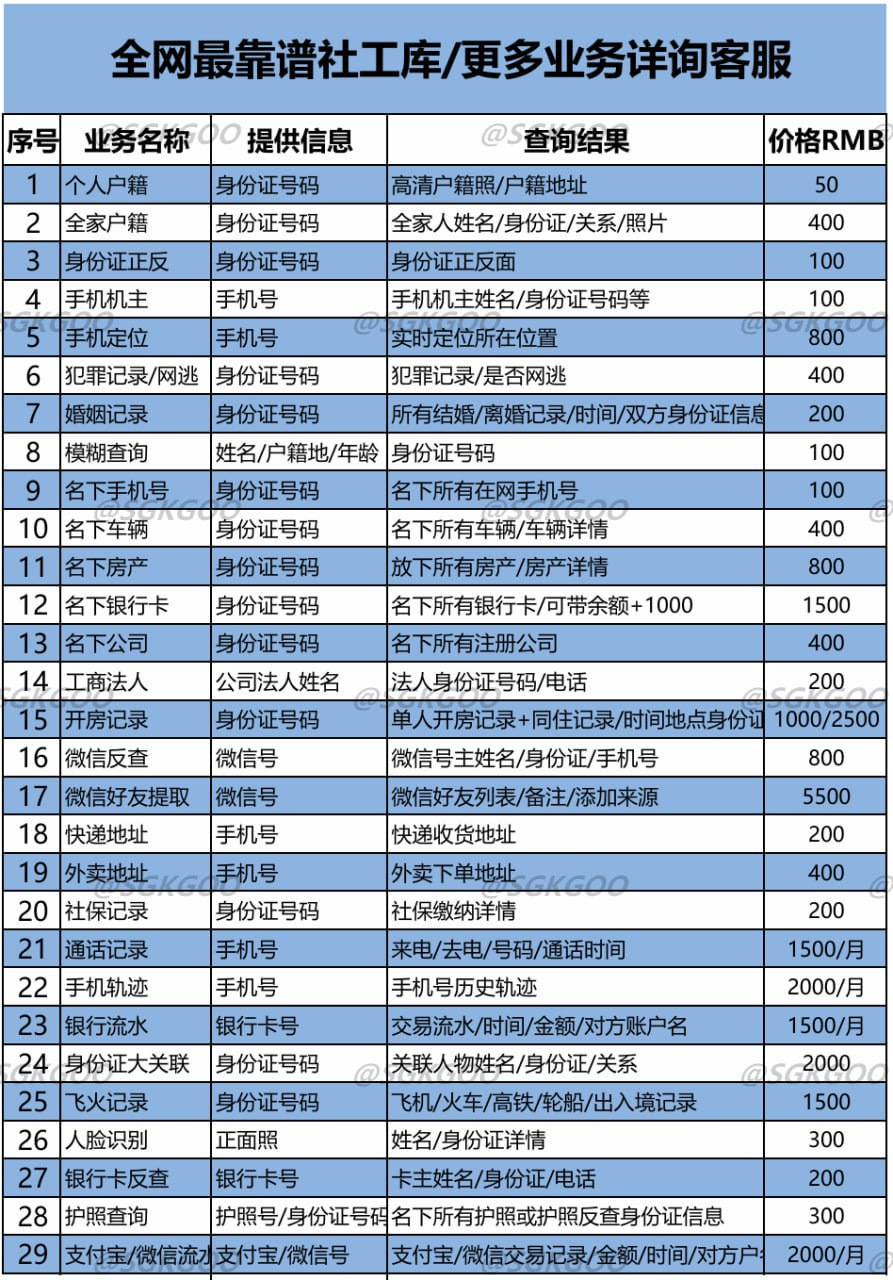
2. Telegram中的个人信息交易
Telegram社工库中的个人信息交易涉及各种价格和服务范围,这些交易对个人隐私构成严重威胁。个人信息的非法交易不仅侵犯了个人隐私,还可能导致金融诈骗、身份盗窃等犯罪行为。社工库的活跃使得个人信息的价值被进一步抬高,导致更多的网络犯罪行为。
02.png
3. Telegram社工库的法律与道德问题
Telegram社工库侵犯个人隐私的行为面临法律后果,包括刑事责任。同时,社会对此类行为的道德谴责也是不容忽视的,因为它破坏了社会信任和个人安全感。各国法律对数据泄露的惩罚力度逐渐加大,旨在遏制此类行为的蔓延。
近几年国内大规模数据泄露事件
1. 2024年国内外数据泄露事件概览
2024年,全球窃密泄密事件频发,涉及多个国家及关键行业,如电信、医疗和云服务。这些事件不仅给国家、企业和个人带来了巨大影响,也引发了全球对国家安全、数据安全和个人隐私保护的深刻反思。各国政府开始加强对数据保护的立法和执法力度,以应对日益严重的数据泄露问题。
2. 具体案例分析
- DemandScience数据泄露:影响了近1.22亿个独特的企业电子邮件地址,包括电子邮件、物理地址、电话号码、雇主、工作头衔等敏感商业联系信息。这一事件引发了对企业数据保护措施的广泛讨论。
- Snowflake客户数据被盗:攻击者“正在积极尝试在网络犯罪论坛上出售被盗客户数据”,UNC5537 已针对全球数百个组织发起攻击。这一事件突显了云服务安全的重要性。
3. 国内数据泄露事件
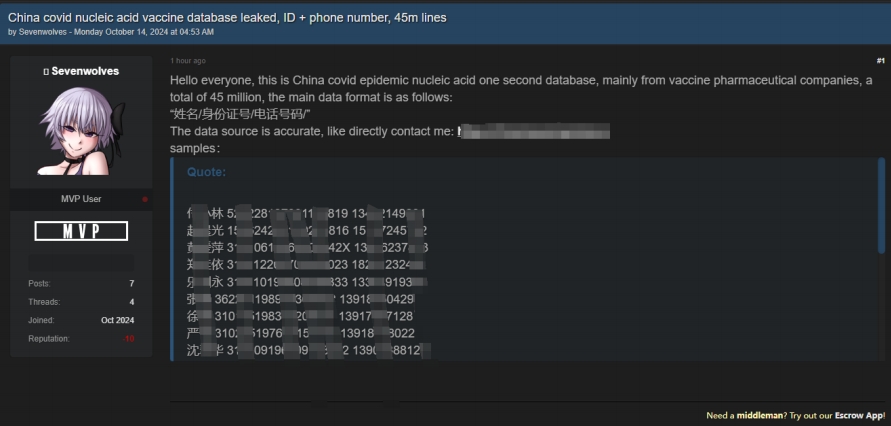
1、**冠状病毒肺炎核酸疫苗数据库泄露
发布时间:2024.10.14
泄露数量:45,000,000
售卖/发布人:Sevenwolves
事件描述:2024.10.14某暗网数据交易平台有人宣称正在售卖一份**冠状病毒肺炎核酸疫苗数据库。卖家称此份数据包含的字段有:姓名,身份证号,手机号。该份数据总量为4500万条。
01.jpg
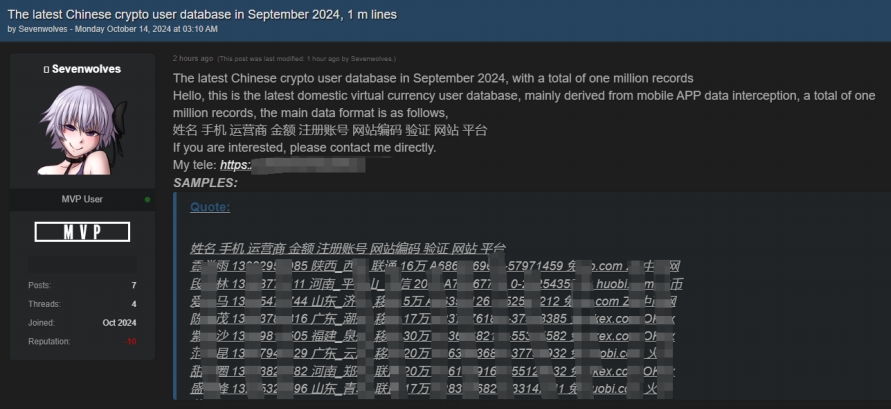
2、中国加密货币用户数据泄露
发布时间:2024.10.14
泄露数量:1,000,000
售卖/发布人:Sevenwolves
事件描述:2024.10.14某暗网数据交易平台有人宣称正在售卖一份中国加密货币用户数据。此份数据的数据字段有:姓名、手机、运营商、金额、注册账号、网站编码、网站、平台。该份数据的总量为100万条。
02.jpg
3、中国**贷款平台用户数据泄露
发布时间:2024.10.20
泄露数量:41,000
售卖/发布人:Sevenwolves
事件描述:2024.10.20某暗网数据交易平台有人宣称正在售卖一份中国**贷款平台用户数据。此份数据的数据字段包含:姓名、电话、身份证号码、银行卡号、联系人、联系电话,数据总量为4.1万条,此份数据的价格为2000美元。
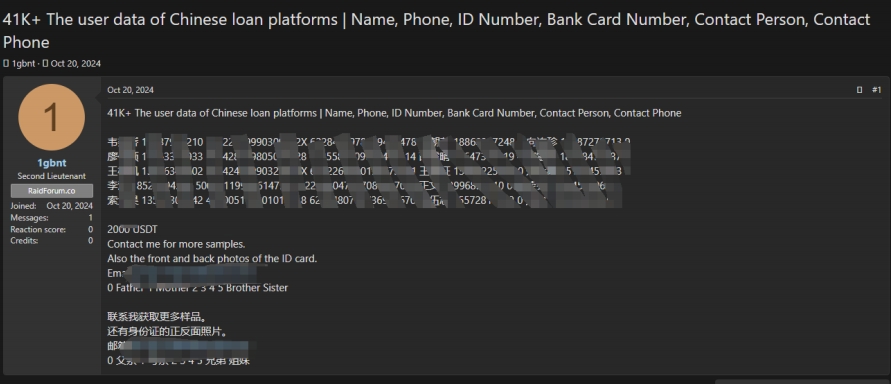
03.jpg
4、**市服务业职业技能培训学校数据泄露
发布时间:2024.10.31
泄露数量:21,337
售卖/发布人:i****y
事件描述:2024.10.31某暗网数据交易平台有人宣称正在售卖一份**市服务业职业技能培训学校数据。此份数据的数据字段包含:姓名、性别、年龄、身份证号等,数据总量为21337条,此份数据的价格为50美元。
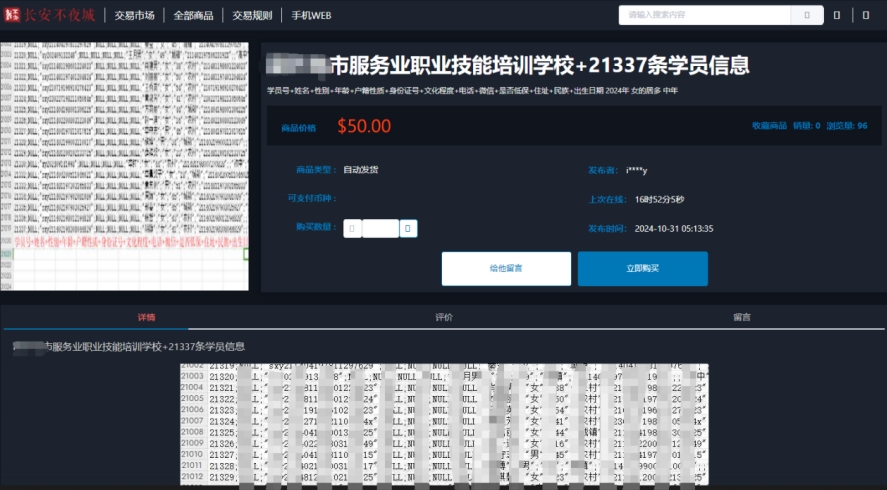
04.jpg
5、中国***航空机票数据泄露
发布时间:2024.10.31
售卖/发布人:a**0
事件描述:2024.10.31某暗网数据交易平台有人宣称正在售卖一份中国***航空机票数据。此份数据包含的数据字段有:姓名,手机号、身份证号、票号。此份数据的价格为340美元。
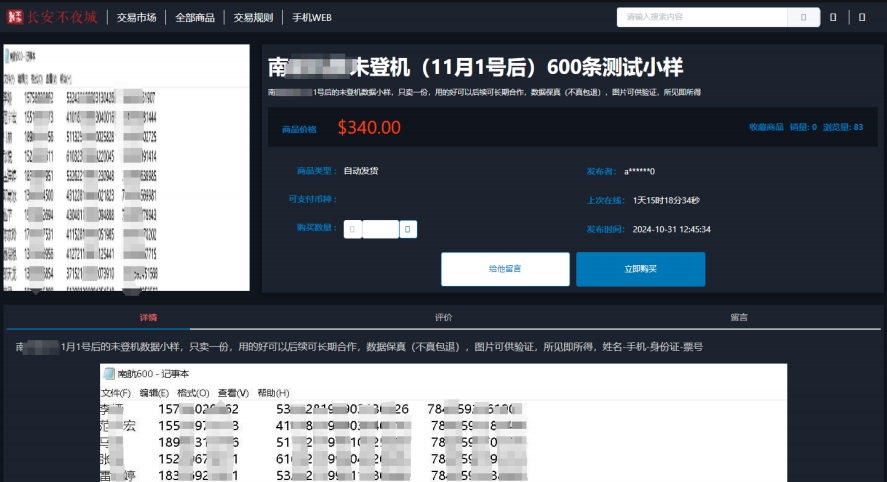
05.jpg
数据泄露对个人隐私的影响
1. 个人信息泄露的后果
个人信息泄露可能导致金融诈骗、信用欺诈和网络身份盗窃等严重后果。受害者不仅面临经济损失,还可能经历长时间的心理创伤。
2. 个人隐私保护的挑战
数据泄露的预防与应对需要个人、企业和政府的共同努力。个人隐私保护的法律与技术手段也在不断发展,以应对日益复杂的数据泄露威胁。企业应加强内部数据管理,提升员工的安全意识,防止数据泄露事件的发生。
数据保护的法律案例与实践
1. 国内外数据保护法律概览
《数据安全法》的实施对个人信息保护产生了积极影响,同时个人信息保护的国际法律框架也在不断完善。各国在数据保护方面的立法逐渐趋同,形成了全球范围内的法律合规要求。
2. 典型案例分析
- 杭州互联网法院个人信息保护案例:杭州互联网法院公布了个人信息保护的十大典型案例,其中包括儿童个人信息保护和金融借款合同中的个人信息保护问题。这些案例为个人隐私保护提供了重要的法律参考和启示。
- 数据安全法执法案例:《数据安全法》实施以来,已有多个企业因违反数据安全规定而受到行政处罚,这些案例对企业数据安全管理提供了重要启示。企业应重视合规性,建立健全数据保护机制。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号