【论文阅读-域自适应】Can We Evaluate Domain Adaptation Models Without Target-domain Labels?

【论文阅读-域自适应】Can We Evaluate Domain Adaptation Models Without Target-domain Labels?

zstar
发布于 2024-05-24 13:18:11
发布于 2024-05-24 13:18:11
论文概述
本文是域自适应领域的一篇工作,发表在ICLR 2024,poster。 论文链接:https://openreview.net/forum?id=fszrlQ2DuP 开源代码:https://github.com/sleepyseal/TransferScore
域自适应(Domain Adaptation)是迁移学习的子领域,目的是把分布不同的源域(Source Domain)和目标域(Target Domain)的数据,映射到一个特征空间中,利用其它领域数据来增强目标领域训练。该文章是进一步涉及更细分领域无监督域自适应(Unsupervised domain adaptation, UDA)。
无监督域自适应(Unsupervised domain adaptation)目的是对源域上训练的模型进行调整以适应未标记的目标域。然而由于目标域没有标签,因此很难有效评估UDA 模型的性能。对此,本文提出了一种迁移分数(Transfer Score)的评估指标。在此基础上,主要实现了三个新的任务:
- 选择最优的UDA模型
- 优化UDA模型的超参数
- 识别UDA模型训练到多少epoch表现最佳。
个人总结:作者挺会包装的,说白了这篇论文就是提出了一个评估指标,后面三个任务只是模型调参的必经过程。
1. 提出动机
概述中已提到,本文提出的迁移分数TS分数指标主要用来度量UDA模型的有效性,换言之是度量源域和目标域的域差异。那么,难道之前就没有类似指标了吗?当然是有的,作者比较了两种比较常用的度量指标MMD和PAD。
1.1 MMD
MMD(Maximum Mean Discrepancy),指代最大均值差异,用于衡量源域和目标域之间的分布差异,计算公式如下:
其中:
,
:分别代表源域和目标域样本集
:映射到某个特征空间的核函数
:核函数所对应的再生核希尔伯特空间(RKHS)
上式表示在再生核希尔伯特空间中,两个分布的均值嵌入之间的距离。MMD 越大,说明源域与目标域之间的分布差异越大。
1.2 PAD
Proxy A-Distance(PAD)也是用来衡量源域和目标域之间的分布差异的指标,计算公式如下:
其中,
:二元分类器在区分源域和目标域样本时的错误率。
当源域和目标域之间的分布非常不同,分类器可以轻松区分样本来源,此时错误率
低,对应的
接近 2,表示分布差异较大; 当源域和目标域之间的分布非常相似,分类器难以区分样本来源,错误率
高,对应的
接近 0,表示分布差异较小。
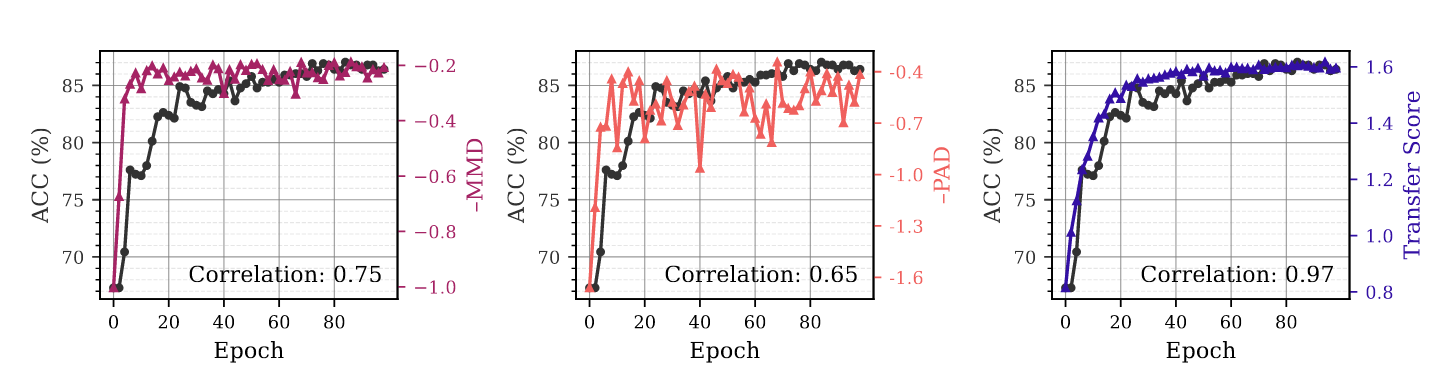
为了证明作者提出的TS(Treansfer Score)比MMD和PAD更能真实反应源域和目标域之间的分布差异,作者借助训练过程中模型的准确率ACC作为真值来进行性能评估,结果如下图所示,可以看到蓝色的TS和黑色的ACC更加接近,说明了该指标评估的科学性。
2.具体方法
下面看TS这个指标具体是怎么算的。
2.1 衡量模型类别划分的均匀性
首先,作者从模型的权重参数出发。作者认为,对于一个分类任务而言,想要让源域能够顺利泛化到目标域,首先要使模型公平的对待每个类别,即在进行分类时,不能使某个类别的权重特别大,使最终结果偏向于该类别。
对此,作者用
来衡量该均匀性,计算公式如下:
表示值越小表示分类器的可迁移性越高,其中
的计算公式如下:
这里的K指代特征的维度。
下面结合代码来理解,我对作者关于这部分的源码加了注释:
for k, v in classifier.head.named_parameters():
if "weight" in k:
u = uniformity(v)
# 计算分类器的均匀性
def uniformity(weight):
# 权重重塑
# 如果权重的维度大于 2(通常是卷积层的权重),将其重塑为二维矩阵。第一维保持不变(对应于输出通道数),第二维是展平的输入通道和核的维度。
if weight.dim() > 2:
weight = weight.view(weight.size(0), -1)
# 权重通过 L2 范数进行归一化
weight_ = F.normalize(weight, p=2, dim=1)
# 计算两个权重向量之间余弦相似度
cosine = torch.matmul(weight_, weight_.t())
n=cosine.size(0)
cosine=cosine.flatten()[:-1].view(n-1,n+1)
cosine=cosine[:,1:]
# 将余弦相似度转换为角度
theta=torch.acos(cosine)
# 计算理想的均匀分布角度 theta0,这是在完美均匀分布的情况下,任意两个向量之间的角度
theta0=torch.acos(torch.tensor(-1/(n-1)))
# 计算每个实际角度与理想角度的差异
dif=theta-theta0
u1=dif.abs()
u2=dif.mul(dif)
u1_loss=torch.mean(u1)
u2_loss=torch.mean(u2)
return u2_loss.item()看代码就比较容易理解,公式中的
就是实际权重的分布,
就是理想的均匀分布,代码中转换成角度的形式方便计算。
第二个公式的推导过程,作者在附录中进行了证明,过程如下:

2.2 衡量特征的可迁移性和可区分性
这一节从模型提取到的特征角度出发,主要从特征的可迁移性和可区分性两方面衡量。
首先是可迁移性。作者引入了前人工作的一个论点:“对于一个好的 UDA 模型,特征空间应该为每个类别呈现出不同的簇,这表明具有更好的可迁移性和可区分性。”对于这一点,从直观上来说并不是特别容易理解。总之,把这一点看成是一条正确的公理,那么为了衡量特征的可迁移性,就转换成是否每个类别呈现出不同的簇。
为此,作者通过Hopkins来进行计算。 Hopkins统计量是一个用于度量数据集的聚类倾向的指标。如果数据点在高维空间中呈现明显的聚类趋势,则Hopkins统计量会接近于1;如果数据点是均匀分布的,则该值接近于0.5。
Hopkins的计算公式如下:
结合代码,可以更容易理解计算细节,Hopkins统计量相关代码如下:
# 提取目标领域特征
X = features.cpu().numpy()
# 使用5%的样本进行Hopkins统计量计算
sample_size = int(X.shape[0] * 0.05)
# 在特征空间中生成均匀随机样本
X_uniform_random_sample = uniform(X.min(axis=0), X.max(axis=0), (sample_size, X.shape[1]))
random_indices = sample(range(0, X.shape[0], 1), sample_size)
X_sample = X[random_indices]
# 使用最近邻算法计算距离
neigh = NearestNeighbors(n_neighbors=2)
nbrs = neigh.fit(X)
u_distances, u_indices = nbrs.kneighbors(X_uniform_random_sample, n_neighbors=2)
u_distances = u_distances[:, 0]
w_distances, w_indices = nbrs.kneighbors(X_sample, n_neighbors=2)
w_distances = w_distances[:, 1]
u_sum = np.sum(u_distances)
w_sum = np.sum(w_distances)
H = u_sum / (u_sum + w_sum) # 计算Hopkins统计量简单概括一下,就是生成均匀随机特征样本,通过最近邻算法计算每个X_sample到最近邻目标样本的距离得到
,用同样的方式计算每个均匀随机样本X_uniform_random_sample到最近邻目标样本的距离得到
,带入公式进行计算。由于KNN计算比较慢,因此在代码中,作者计算Hopkins时,选取了5%的样本。
Hopkins的局限在于,比如很多样本单独形成一个蔟,并没有聚在一起,Hopkins值依然很高。于是作者利用可区分性来进行补充,主要从类别角度考虑,通过互信息来衡量。
在聚类中,互信息可以用来评估聚类结构与真实数据标签之间的一致性。高互信息值表明聚类结果与真实数据标签高度相关,计算公式如下:
在代码中,作者通过信息熵损失来计算一致性。
im_loss = [] # 存储信息熵损失
iter_num = len(train_target_iter)
with torch.no_grad():
for i in range(iter_num):
x_t, = next(train_target_iter)[:1]
x_t = x_t.to(device)
# 获取模型预测和特征
y, output_f = classifier(x_t, require_feature=True)
if features.size()[0] == 1:
features = output_f
else:
features = torch.cat((features, output_f), dim=0)
output_test = y
# 计算模型预测的软最大值
softmax_out = nn.Softmax(dim=1)(output_test)
entropy_loss = torch.mean(entropy(softmax_out))
# 计算类别分布的总体熵损失
msoftmax = softmax_out.mean(dim=0)
gentropy_loss = torch.sum(-msoftmax * torch.log(msoftmax + 1e-6))
entropy_loss -= gentropy_loss
im_loss.append(entropy_loss.item())
M = sum(im_loss) / len(im_loss)2.3 迁移分数计算
综合上述各部分,得到迁移分数计算公式如下:
这里的
和前文有区别,这里表示类别总数。由于均匀性越大表示偏差越大,可转移性越低,因此这里添加了负号。
3.实验
3.1 数据集
作者用了四个域迁移数据集:
- Office-31
- Office-Home
- VisDA-17
- DomainNet
3.2 对比方法
作者使用ResNet-50和ResNet-101作为基础分类器,对比的方法有:
- 对抗性UDA方法 DANN、CDAN、MDD
- 矩匹配法 DAN、CAN
- 基于范数的方法 SAFN
- 自训练方法 FixMatch、SHOT、CST、AaD
- 重加权方法 MCC
- 最近的UDA工作 C-Entropy、SND、ATC、DEV
3.3 任务一的表现
任务一是证明TS能够更科学的评估迁移效果,和概述中的图像类似

3.4 任务二的表现
任务二是通过TS辅助模型超参数调优,从这三张散点图基本也可以看出,ACC和TS呈现正相关的关系。

3.3 任务三的表现
任务三是通过TS来保存最优模型,下表中Last指代保存最后一个epoch的模型,ours表示保存最优TS的模型。个人感觉这个实验意义不是很大,正常来说一个模型训多了都会过拟合,导致在验证中结果下降。中间保存的模型大概率都是比最后保存的性能要好。

总结
该论文的贡献主要在于提出了一个TS指标,更加客观准确地评价了域迁移的能力。总体来说,思维逻辑比较清晰,工作量也挺大,不过从创新性角度来说,也比较有限。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-05-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号