谷歌最新大模型 DiffusionGemma 续集:Unsloth 把它压到 18GB,单卡飙到 2000+ Token/s

谷歌最新大模型 DiffusionGemma 续集:Unsloth 把它压到 18GB,单卡飙到 2000+ Token/s

Ai学习的老章
发布于 2026-06-24 11:11:30
发布于 2026-06-24 11:11:30
大家好,我是 Ai 学习的老章
前几天介绍过 DiffusionGemma,当时 vLLM 在 H100 上跑出 1000+ tok/s 已经够炸裂了,结果不到三天,Unsloth 直接把它压成 GGUF,丢进 llama. cpp,单卡 2000+ tok/s 起飞——而且最低 18GB RAM 就能跑
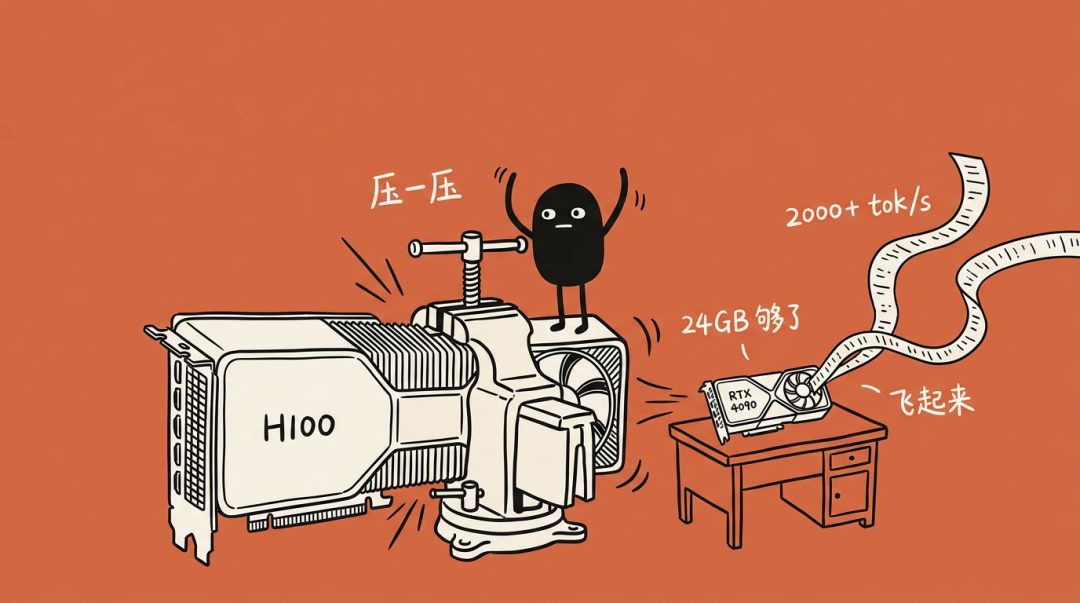
这次有什么新东西
简单说三句话:
- GGUF 来了:Unsloth 把 DiffusionGemma-26B-A4B-it 量化成 5 个 GGUF 版本,最小 16GB,24GB 显卡一张就吃得下
- llama. cpp 上车:Daniel Han(Unsloth 创始人)给 llama .cpp 提了 PR #24423,新增了
llama-diffusion-cli专用运行器 - 2000+ tok/s 实测:Unsloth 官方在 RTX 6000 上跑出了 2000+ tokens/s 的单请求速度,比 vLLM 在 H100 上的 1000 tok/s 还快一倍
也就是说,扩散式大模型从"云端 H100 专属"直接下沉到了"消费级 24GB 显卡",门槛低到离谱
用一张图直观感受一下这三天的变化:

DiffusionGemma 三天进化对比
量化版本怎么选
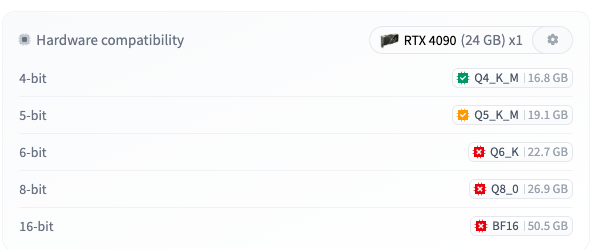
Unsloth 这次给了 5 档量化,从 BF16 全精度到 Q4_K_M 都覆盖了:
量化 | 体积 | 备注 |
|---|---|---|
BF16 | 47 GB | 全精度参考版,不建议日常用 |
Q8_0 | 25 GB | 接近无损,推荐,单张 32GB+ 显卡(如 RTX 6000 Pro / V100 32G)够用 |
Q6_K | 21 GB | 折中选择 |
Q5_K_M | 18 GB | 内存敏感场景可选 |
Q4_K_M | 16 GB | 最小,单张 24GB 显卡(4090/3090/RTX 6000)即可塞下 |
❝注意是"塞下",不是"跑得动";Unsloth 官方推荐总内存(RAM + VRAM)≥ 18 GB,这是包含 KV Cache 和 canvas 状态缓冲区的最低要求
我个人的选择建议:
- 24GB 单卡(4090/3090/RTX 6000) → Q4_K_M(16GB 模型 + 8GB 留给 KV cache)
- 32GB 单卡(RTX 6000 Pro/V100 32G) → Q8_0(精度最优)
- Apple Silicon 统一内存(M2 Max/M3 Max 32G+) → Q4_K_M 或 Q5_K_M
- 纯 CPU + 大内存(64GB+) → Q8_0,速度慢但精度稳
跑法一:llama. cpp 原生路线
这条路线适合喜欢命令行、想看清楚每个参数的玩家;关键点:必须用 PR #24423 分支,不是 main——DiffusionGemma 是块扩散架构,标准的 llama-cli 和 llama-server 还跑不起来
1. 编译专用分支
git clone https://github. com/ggml-org/llama. cpp
cd llama. cpp
gh pr checkout 24423
# CUDA 编译(Apple Mac/Metal 改成 -DGGML_CUDA=OFF)
cmake -B build -DGGML_CUDA=ON
cmake --build build -j --config Release --target llama-diffusion-cli
注意编译目标是 llama-diffusion-cli 这个新二进制,不是 llama-cli;这是 Daniel Han 在 PR 里专门加的,因为扩散模型生成路径完全不同
2. 下载 GGUF
pip install -U "huggingface_hub[cli]"
hf download unsloth/diffusiongemma-26B-A4B-it-GGUF \
--local-dir unsloth/diffusiongemma-26B-A4B-it-GGUF \
--include "Q4_K_M" # 24GB 显卡用这个
如果想跑 Q8_0 把 *Q4_K_M* 改成 *Q8_0* 即可
3. 启动对话
./build/bin/llama-diffusion-cli \
-m unsloth/diffusiongemma-26B-A4B-it-GGUF/diffusiongemma-26B-A4B-it-Q4_K_M.gguf \
-ngl 99 -cnv -n 2048
参数解读:
-ngl 99:所有层卸到 GPU(纯 CPU 跑改-ngl 0)-cnv:开启多轮对话模式-n 2048:目标 token 数;这个参数会自动推导--diffusion-blocks数量并扩展 batch / context 大小,所以你只需要管这一个长度参数
熵边界采样器(Entropy-Bound)默认开启,这是 DiffusionGemma 推荐的标准配置——温度 0.8 → 0.4 线性衰减、熵上限 0.1、最大去噪步数 48;直接用就行,调反而会掉分
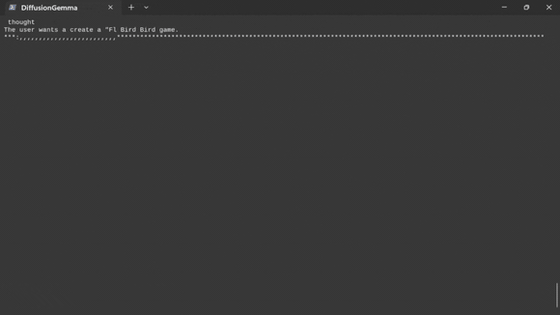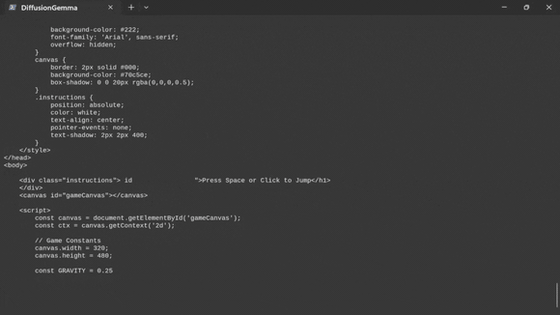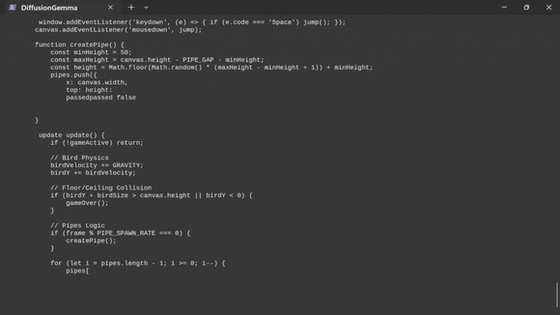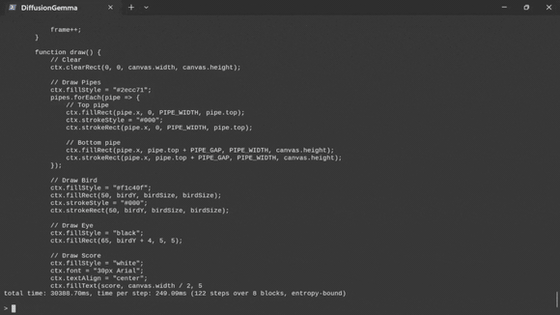
下面是 llama-diffusion-cli 启动后的样子:

llama-diffusion-cli 启动界面
llama-diffusion-cli 启动界面
跑法二:Unsloth Studio 一键路线(推荐新手)
如果你不想折腾 cmake 编译,Unsloth 6 月 12 号刚推了一个更新——Unsloth Studio 已经内置 DiffusionGemma 支持,不用自己编 llama. cpp
Unsloth Studio 是个开源的本地 AI Web UI,相当于 Ollama + Open WebUI 的合体,但是把推理和训练做到了一个面板里;MacOS / Windows / Linux 都支持
安装(任选一行):
# MacOS / Linux / WSL
curl -fsSL https://unsloth. ai/install .sh | sh
# Windows PowerShell
irm https://unsloth. ai/install .ps1 | iex
启动 Web UI:
unsloth studio -H 0.0.0.0 -p 8888
然后浏览器打开 http://127.0.0.1:8888,第一次会让你设个密码(保护本地账户),登进去之后到 Studio Chat 标签页搜 "DiffusionGemma",选量化版本下载,就能直接对话
最舒服的是:所有扩散采样参数自动配好,不用记那串 entropy bound、temperature schedule、canvas length;新手党直接起飞
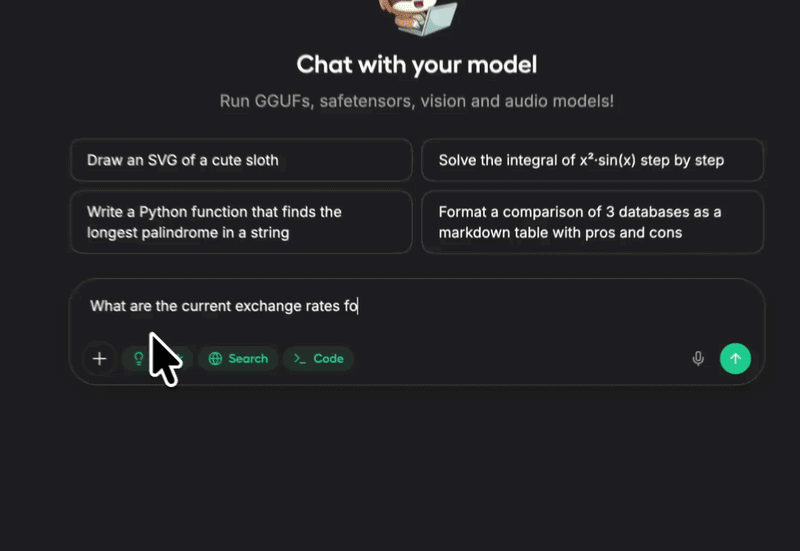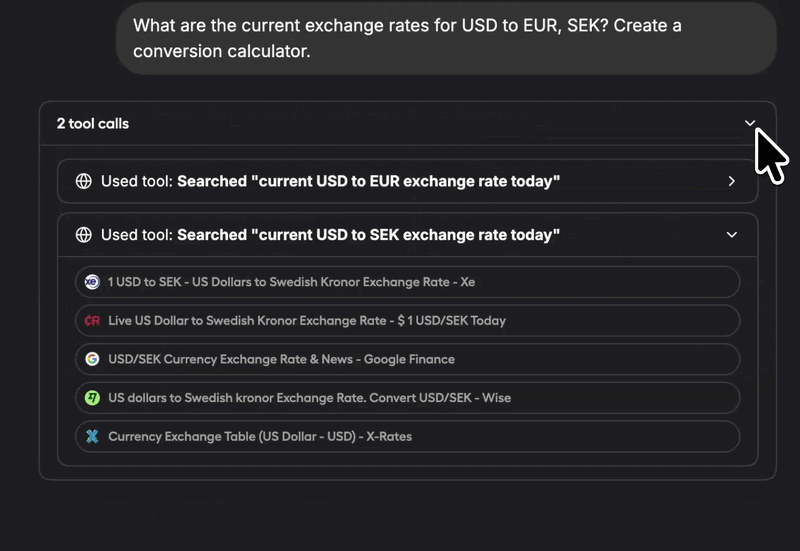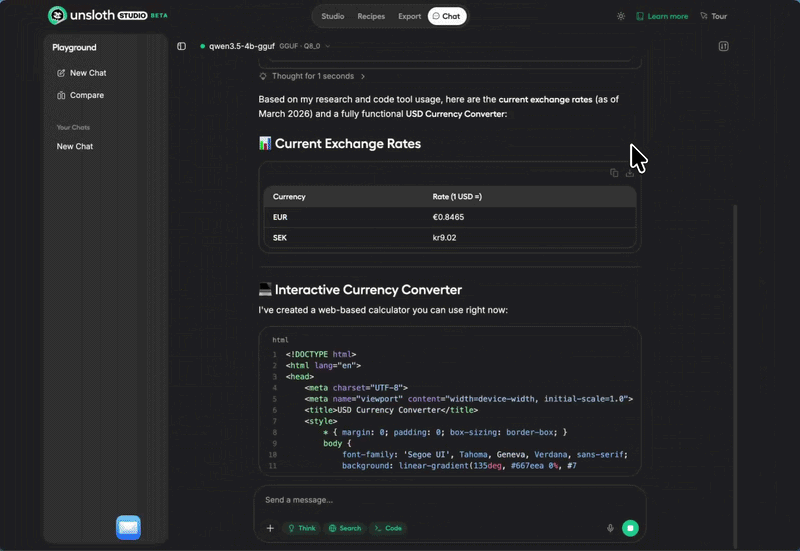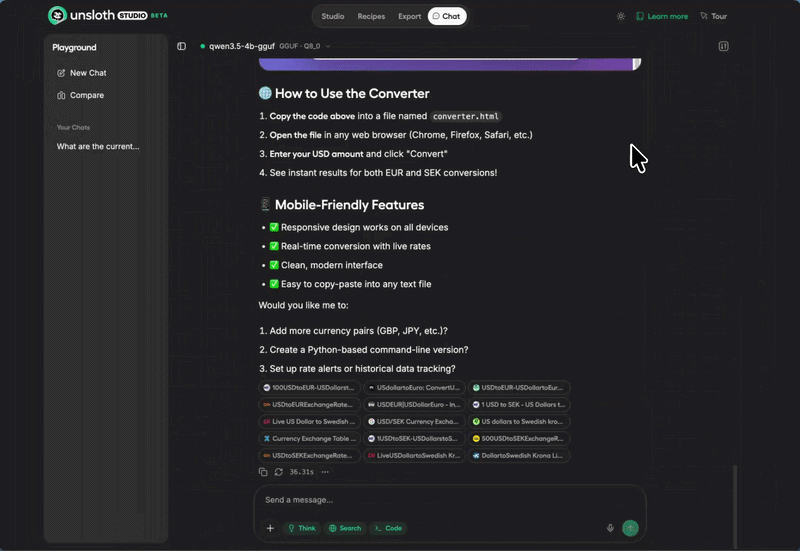
下面是 Unsloth Studio 里跑 4-bit GGUF DiffusionGemma 并带可执行代码输出的实际效果:
DiffusionGemma 在 Unsloth Studio 里运行
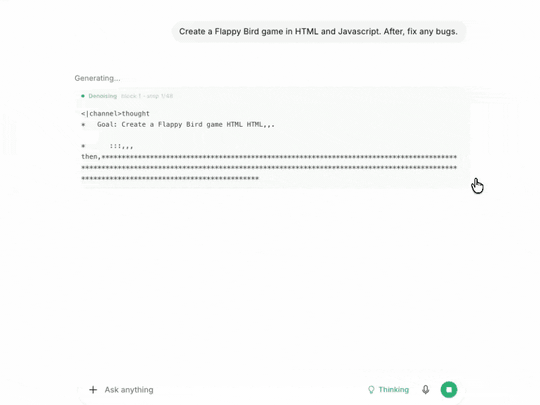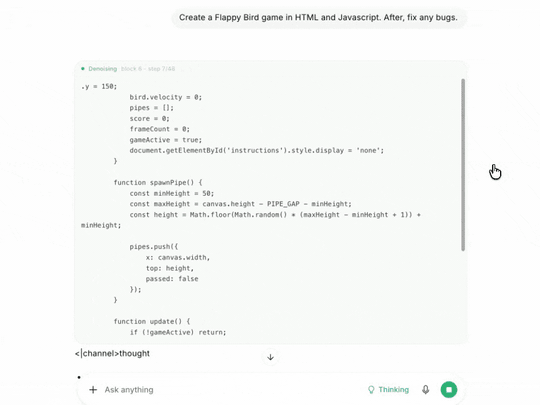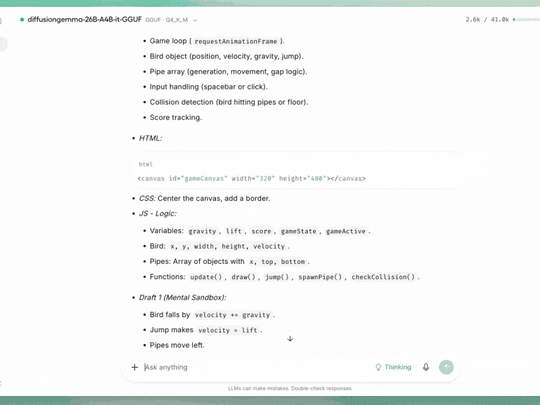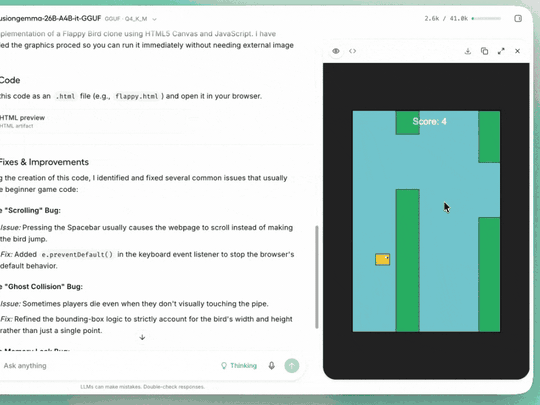
王炸功能:实时看扩散去噪
这是我觉得 DiffusionGemma 这次最值得玩的东西——加一个 --diffusion-visual 参数,可以亲眼看到 256 个 token 怎么从噪声一点点收敛成答案:
./build/bin/llama-diffusion-cli \
-m unsloth/diffusiongemma-26B-A4B-it-GGUF/diffusiongemma-26B-A4B-it-Q4_K_M.gguf \
-ngl 99 -cnv -n 2048 --diffusion-visual
效果是这样的:
diffusion-visual 实时去噪
整个画布上的字符在屏幕上反复擦写、收敛、定型,最后一次性"啪"地全部清晰——这才是扩散语言模型的灵魂可视化;flicker-free 设计,不会糊屏,scrollback 也不会乱
我自己看了三分钟才反应过来:原来"扩散模型生成文本"不是一个比喻,它真的就在你眼前像图像扩散模型一样工作
微调也能玩了
更狠的是 Unsloth 把 DiffusionGemma 的微调链路也打通了;官方 demo 是用数独数据集 finetune,下面这张前后对比图很说明问题——基础模型解数独完全瞎填,微调之后能稳定解出每一道:
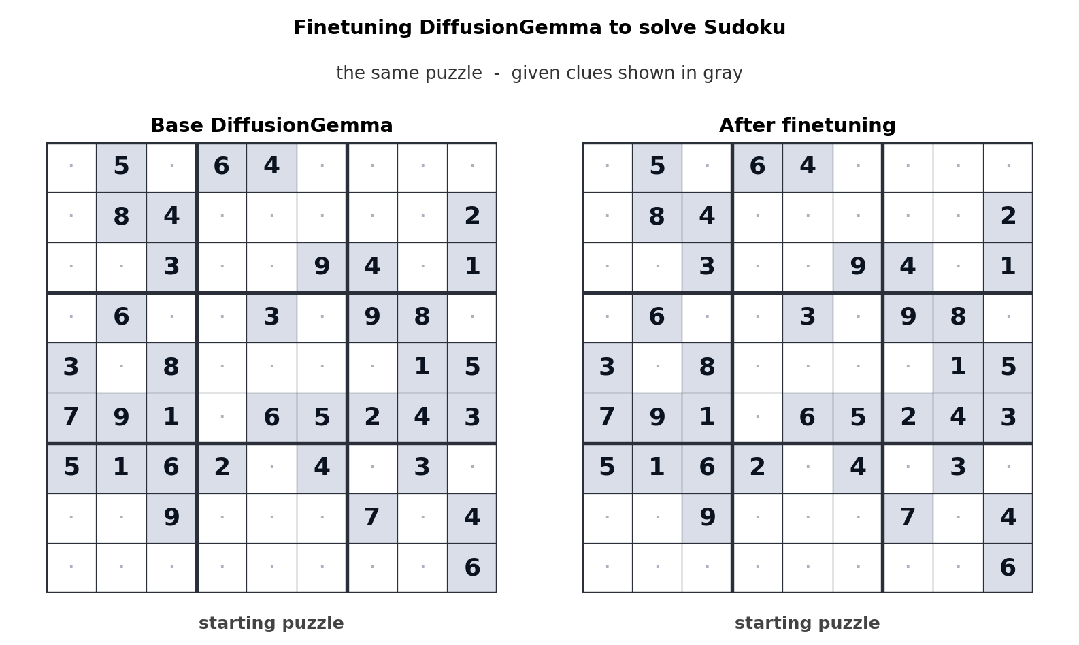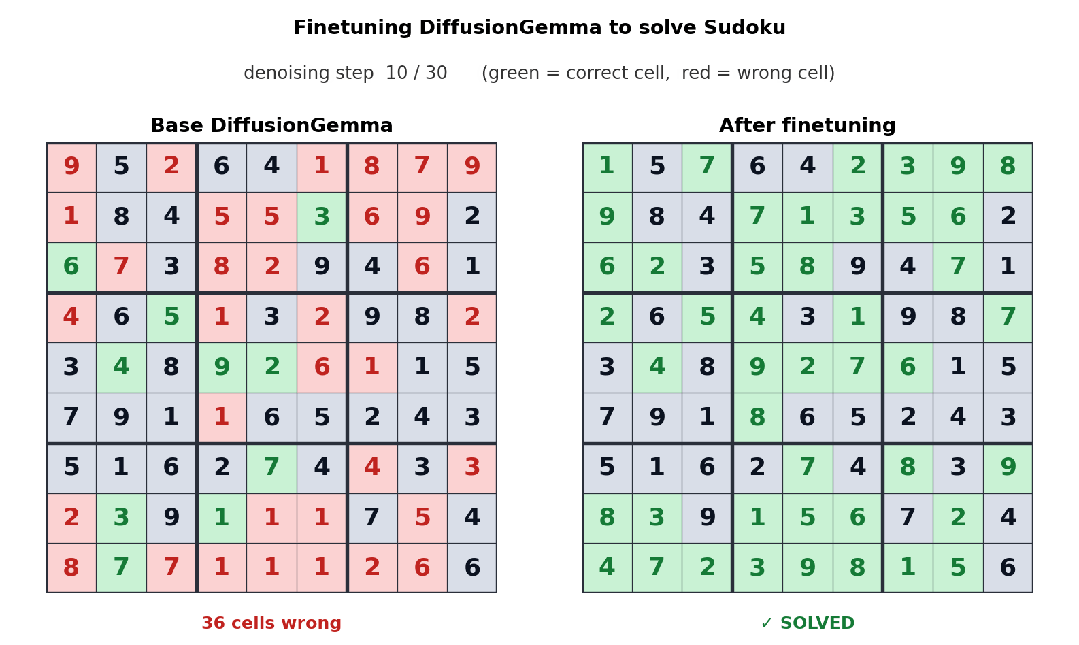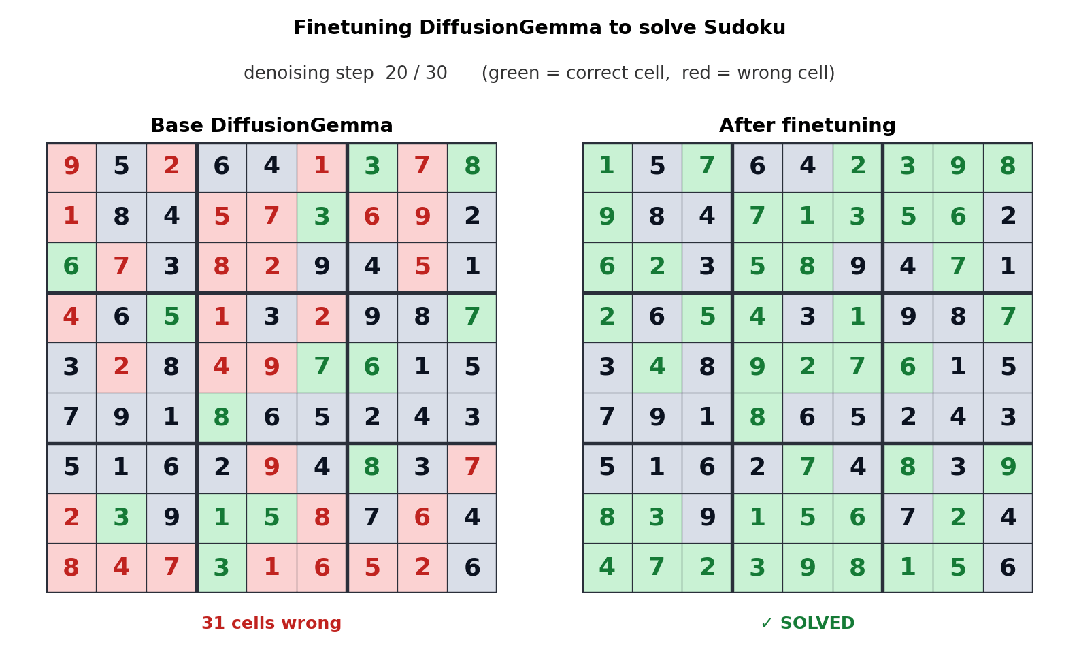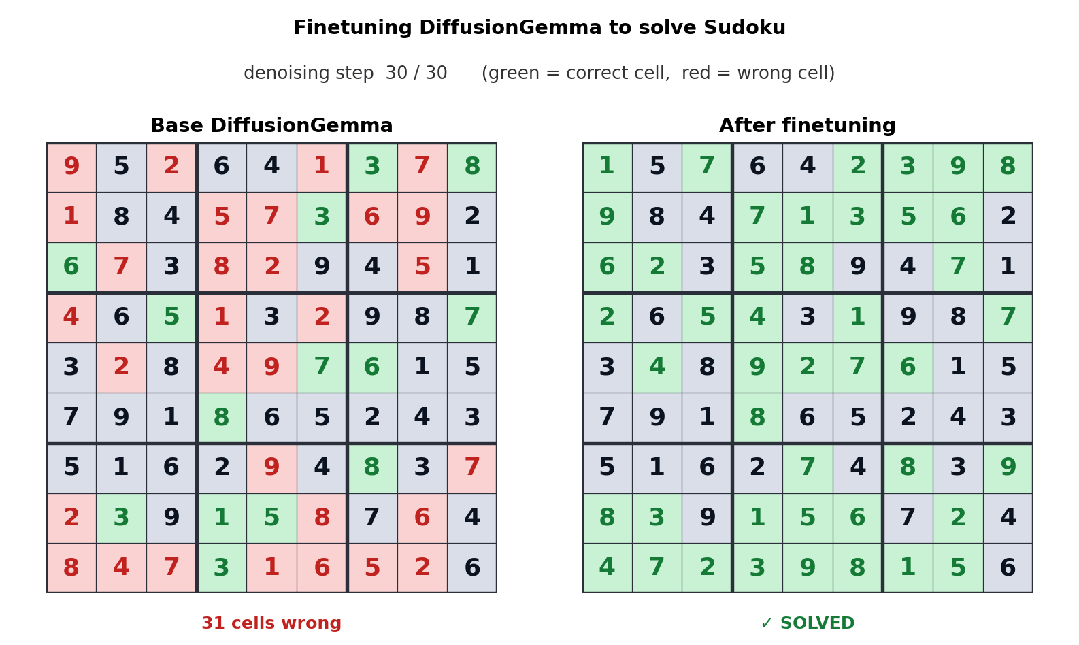
Sudoku 微调前后对比
Sudoku 微调前后对比
官方提供了 Colab 笔记本(A100 即可),扩散采样器、温度调度、熵阈值这些扩散专属参数全部预置;如果你手头有领域数据(金融文档、医疗报告、代码库),完全可以拿这套直接 SFT,把 DiffusionGemma 微调成你领域的快速生成专家
速度的代价
老板要冷静,2000+ tok/s 听起来很爽,但有几个固有局限要提前知道:
首 Token 延迟(TTFT)依然偏高:扩散模型必须先把整个 256 token 的 canvas 去噪到位才会吐出第一个字;如果你做的是流式聊天 / 实时打字效果,TTFT 会让用户感觉"卡了一下"——这是架构层面没法绕开的代价
并发上不去:扩散模型每路对话都要维护一块 canvas × vocab_size 的状态缓冲区,显存占用是 AR 模型的好几倍;本地单用户场景没问题,多并发服务直接劝退
精度比 Gemma 4 略低:MMLU Pro 77.6% vs 82.6%、AIME 2026 69.1% vs 88.3%、Codeforces ELO 1429 vs 1718——拿速度换了大约 5-15% 的精度;如果你做的是奥数级推理或竞赛编程,老老实实跑 Gemma 4 自回归版
llama. cpp PR 还没合并主线:PR #24423 目前在 draft 状态,被 ggml-gh-bot 标记"过大",社区也对 per-model server 设计有讨论;短期内你只能在 Unsloth 的 PR 分支或 Unsloth Studio 里玩,原生 llama. cpp 还得等
谁适合
场景 | 是否推荐 |
|---|---|
24GB 单卡本地推理(4090/3090) | ✅ 强烈推荐,Q4_K_M 起飞 |
Apple Silicon 大内存机器 | ✅ 推荐,Metal 默认支持 |
私有领域知识 SFT | ✅ 推荐,扩散微调链路已通 |
想体验扩散语言模型可视化 | ✅ 必玩 --diffusion-visual |
高并发 API 服务 | ❌ 别碰,AR 模型更合适 |
奥数 / 竞赛级推理任务 | ❌ 跑 Gemma 4 26B AR 版 |
流式聊天 / 实时打字效果 | ❌ TTFT 太慢 |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号