内存中心化架构:AI推理性能的下一代突破口

内存中心化架构:AI推理性能的下一代突破口

数据存储前沿技术
发布于 2026-05-25 17:00:56
发布于 2026-05-25 17:00:56
阅读收获
- 架构演进逻辑:理解从“计算节点私有内存”向“全局可见共享内存池”转变的技术动因,掌握CXL 2.0/3.x特性在解决内存孤岛与资源闲置中的实际应用。
- 性能优化路径:掌握如何通过控制平面与数据平面解耦,利用内存池化技术实现KV Cache的跨节点共享,从而突破传统RDMA网络在LLM推理中的延迟瓶颈。
- 行业技术趋势:洞察存储厂商(如SK hynix)如何通过软硬件一体化平台(如Niagara),将存储协议下沉至内存层,为超大规模AI集群提供可扩展的硬件参考架构。
全文概览
在当前大模型(LLM)的爆发式增长中,计算能力已不再是唯一的瓶颈,数据在处理器与存储之间的“搬运”开销正成为制约AI集群效率的“内存墙”。传统的分布式架构依赖网络协议进行节点间通信,在高并发推理场景下,频繁的KV Cache交换导致了严重的延迟与带宽浪费。
行业正经历一场从“以网络为中心”向“以内存为中心(Memory Centric)”的架构范式转移。通过CXL(Compute Express Link)技术,内存资源得以从处理器中解耦并池化,实现机柜级的资源共享。这种架构创新究竟是如何将传统的存储访问转化为极速的内存访问?它又将如何重塑AI推理的性能边界?本文将深入剖析以内存为中心的AI机器架构,探讨其在提升系统吞吐量与降低延迟方面的技术逻辑。
👉 划线高亮 观点批注
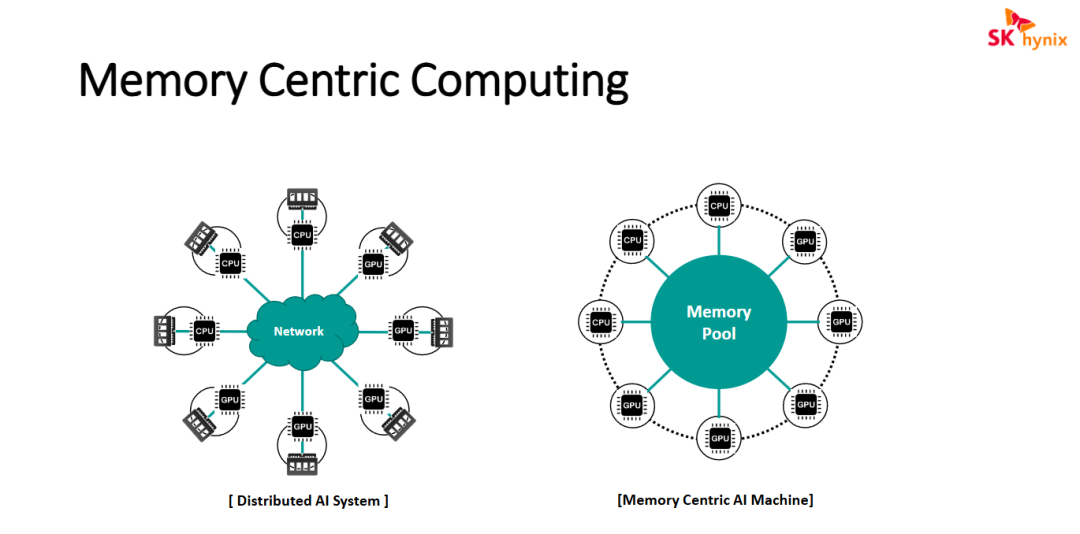
图片展示了从传统的分布式架构向以内存为中心(Memory Centric)架构演进的趋势
- 架构重心转移(从网络到内存池): 传统的 AI 系统架构以网络通信为核心,(为了满足AI推理场景的数据传输可靠性,业界最近推出了高可靠的RDMA网络协议MRC)数据在不同节点的本地存储间搬运,容易产生“数据移动开销”。而内存中心架构将内存从处理器中解耦并池化,使数据处于计算资源的中心位置,大幅降低了访问延迟。
- 资源解耦与共享(Memory Pooling): 在内存中心模式下,CPU 和 GPU 能够动态地从共享内存池中按需获取容量。这种设计解决了传统分布式系统中常见的“内存孤岛”问题,提高了内存利用率,特别适合处理大模型训练等需要超大规模内存容量的 AI 负载。
- 计算效率的提升: 通过内存池化,计算节点可以直接在共享空间内进行数据交互,减少了通过传统网络协议栈进行数据封装和传输的步骤。这体现了行业向高带宽互连技术(如 CXL)演进的技术逻辑,旨在突破当前 AI 计算中的“内存墙”瓶颈。
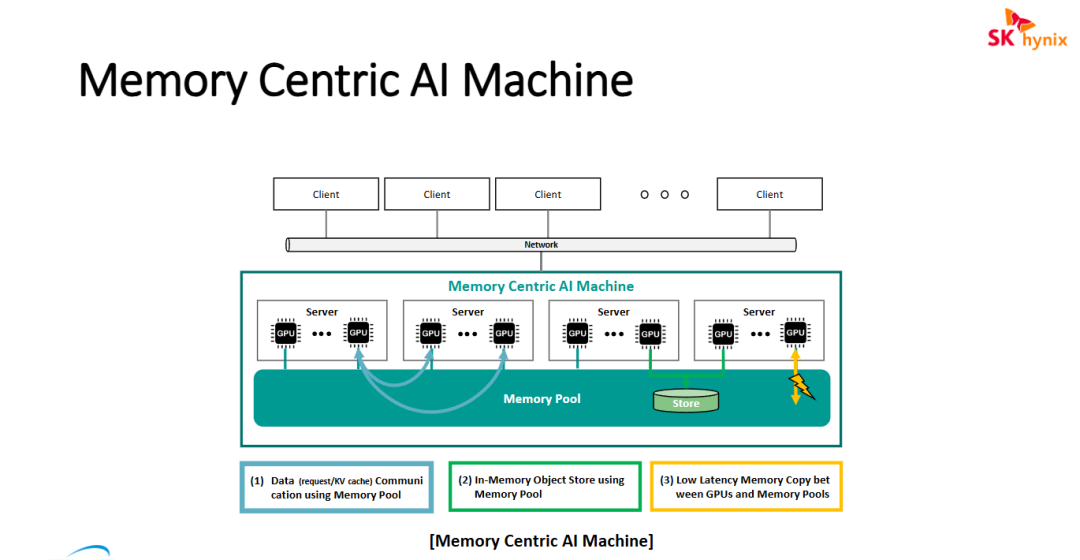
图片展示了名为 "Memory Centric AI Machine"(以内存为中心的 AI 机器) 的技术架构方案。该架构通过解耦内存资源,重构了 AI 计算的交互模式
- KV Cache 的内存池化通信: 该架构针对当前大模型推理的关键痛点,通过内存池实现了 KV Cache 的跨节点共享与通信。这允许不同的 GPU 实例直接在共享内存空间中读取/写入推理状态,极大地降低了分布式推理中的通信开销。
- 基于内存的对象存储(In-Memory Object Store): 架构引入了在内存池内构建对象存储的概念。这种设计将传统的“存储访问”转化为“内存访问”,能够提供远高于传统 NVMe SSD 的 IOPS 和极低的访问延迟,适合高频访问的 AI 训练数据或中间检查点。
- 异构计算的极速互连: 通过强调 GPU 与内存池之间的低延迟拷贝,该方案体现了从“计算节点私有内存”向“全局可见共享内存”的转变。这不仅提升了 GPU 的显存扩展能力,还通过减少数据在 PCle/网络上的搬运次数,显著优化了 AI 集群的整体能效。
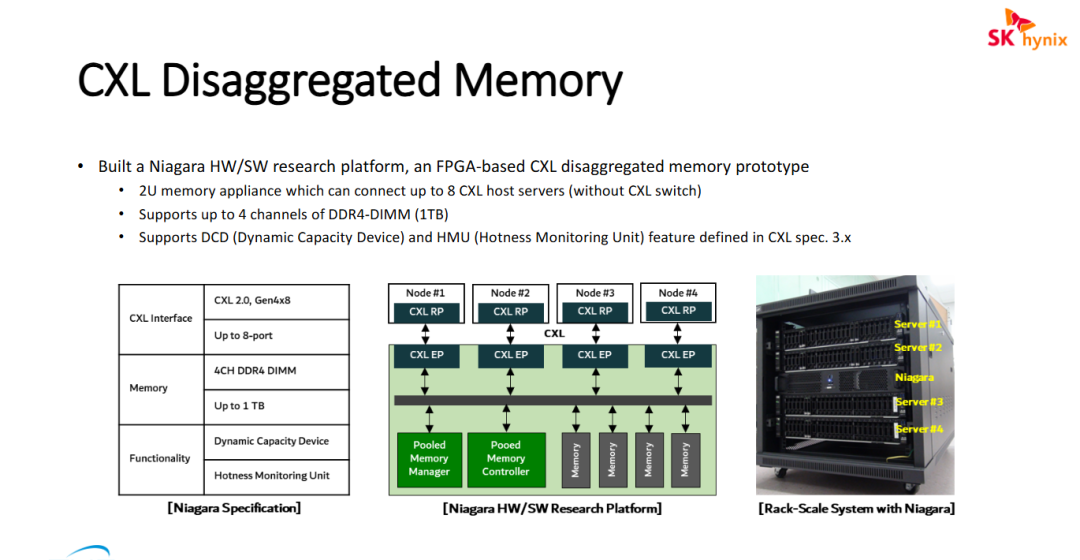
SK hynix 开发的名为 "Niagara" 的 CXL 解耦内存(CXL Disaggregated Memory)软硬件研究平台
- 实现内存的池化与灵活解耦: Niagara 平台通过 CXL 2.0 接口将内存资源从单一服务器中独立出来,形成一个可供多达 8 台服务器共享的 1TB 内存池。这种架构有效解决了“内存墙”和资源闲置问题,提高了数据中心级别的内存利用率。
- 前瞻性支持 CXL 3.x 关键特性: 该原型系统虽然基于 CXL 2.0 物理接口,但已提前实现了 CXL 3.x 的重要功能:DCD 允许按需动态分配内存容量,无需重启系统;HMU 则能实时监测内存数据的访问热度。这些特性对于实现精细化的内存分级存储(Tiered Memory)至关重要。
- 高性能与高扩展性的原型验证: 通过 FPGA 验证了多端口直接连接(Direct-attach)的方案,在不需要昂贵的 CXL Switch 的情况下实现了机柜级(Rack-Scale)的内存池化。这为未来超大规模 AI 计算和内存密集型应用提供了低延迟、可扩展的硬件参考架构。
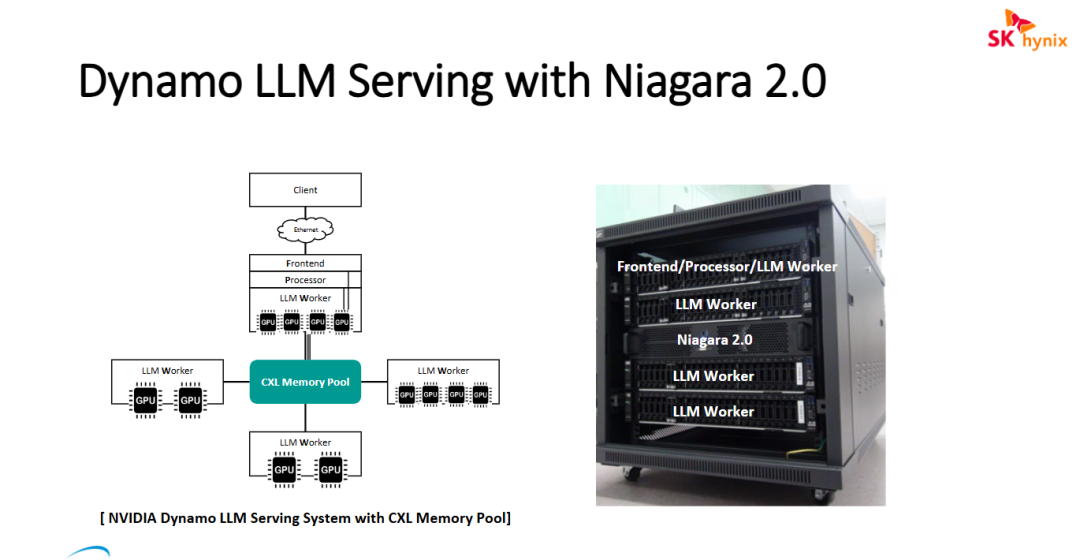
图片展示了 SK hynix 开发的名为 "Dynamo LLM Serving with Niagara 2.0" 的系统架构。该方案通过 CXL 内存池技术优化大语言模型(LLM)的推理服务
- CXL 内存池化赋能 LLM 推理: 该系统利用 Niagara 2.0 实现了基于 CXL 协议的解耦内存池。在 LLM 推理场景中,这允许集群内的多个 GPU 节点共享 TB 级别的内存空间,从而能够高效存储和交换大模型的中间状态(如 KV Cache),打破了单个服务器本地显存容量的限制。
- 软硬件一体化的分布式架构: Niagara 2.0 不仅是一个硬件设备,它与 NVIDIA 的服务框架集成,形成了一个完整的 Dynamo LLM Serving 系统。这种架构将计算(GPU)与大规模内存存储(CXL Memory Pool)解耦,使得计算资源可以根据推理负载动态扩缩,显著提升了机柜级资源的利用率和系统吞吐量。
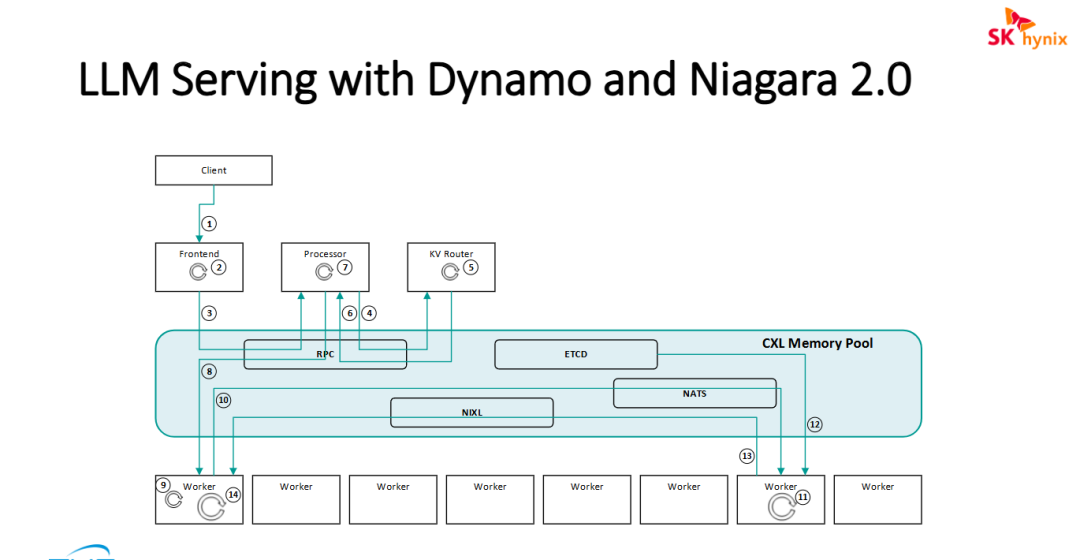
图片展示了一个利用 CXL 内存池(CXL Memory Pool)构建的大语言模型(LLM)推理服务系统的内部工作流和软件组件
序号 | 组件/流向 | 工作内容 |
|---|---|---|
① | Client → Frontend | 客户端发送推理请求(如 OpenAI API 格式)到 Frontend 服务 |
② | Frontend 内部处理 | Frontend 解析请求,进行格式校验、认证、路由决策准备 |
③ | Frontend → Worker (via RPC) | Frontend 通过 RPC 将请求发送到具体 Worker(或经 Router 中转) |
④ | KV Router → Processor | KV Router 向 Processor 查询/同步 KV Cache 元数据(如前缀匹配信息) |
⑤ | KV Router 内部循环 | Router 持续监控各 Worker 的 KV Cache 状态,更新路由表 |
⑥ | Processor → Worker (双向) | Processor(可能是 Planner/调度器)与 Worker 交互,获取负载、KV 状态,下达调度指令 |
⑦ | Processor 内部处理 | Planner 进行 SLA 感知的资源规划,决定请求分配到哪个 Worker |
⑧ | CXL Pool → Worker | 核心路径:Worker 直接从 CXL Memory Pool 读取共享的 KV Cache(通过 Niagara 2.0),无需跨节点传输 |
⑨ | Worker 内部 Prefill | Worker 执行 Prefill 阶段:计算 prompt 的 KV 值,生成初始 token |
⑩ | Worker → NIXL | Worker 通过 NIXL(NVIDIA Inter-GPU Exchange Library)进行 GPU 间 KV 数据高速传输 |
⑪ | Worker 内部 Decode | Worker 执行 Decode 阶段:自回归生成后续 token,复用 KV Cache |
⑫ | CXL Pool ↔ Worker | Worker 将新生成的 KV Cache 写回 CXL 共享池,或从池中读取其他 Worker 缓存的前缀 |
⑬ | NIXL → Worker | NIXL 将 Prefill Worker 的 KV Cache 传输给 Decode Worker(解耦架构下的跨阶段传递) |
⑭ | Worker 内部循环 | Worker 持续处理 token 生成,直到序列完成 |
核心内容总结:
- 基于 CXL 内存池的控制平面与数据平面解耦: 该架构将复杂的 RPC 通信、状态同步(ETCD)以及消息传递(NATS)全部下沉到 CXL Memory Pool 层。通过 CXL 提供的内存级访问速度,解决了传统分布式系统中网络延迟导致的性能瓶颈,实现了控制平面与执行平面的极速交互。
- 针对 LLM 推理的 KV Cache 共享优化: 架构中专门设立了 KV Router 并在内存池内运行相关组件,这表明该系统旨在解决 LLM 长文本推理中的 KV Cache 管理难题。Worker 节点可以利用池化内存直接共享和交换缓存数据,避免了在不同 GPU 或服务器节点间进行昂贵的数据搬运。
- 高度可扩展的软件定义存储架构: 通过 NIXL 等中间件,Niagara 2.0 平台能够透明地管理底层多个 Worker 的内存资源。这种设计不仅提升了单次推理的吞吐量,也为未来部署更超大规模的参数模型提供了灵活的内存扩展底座。
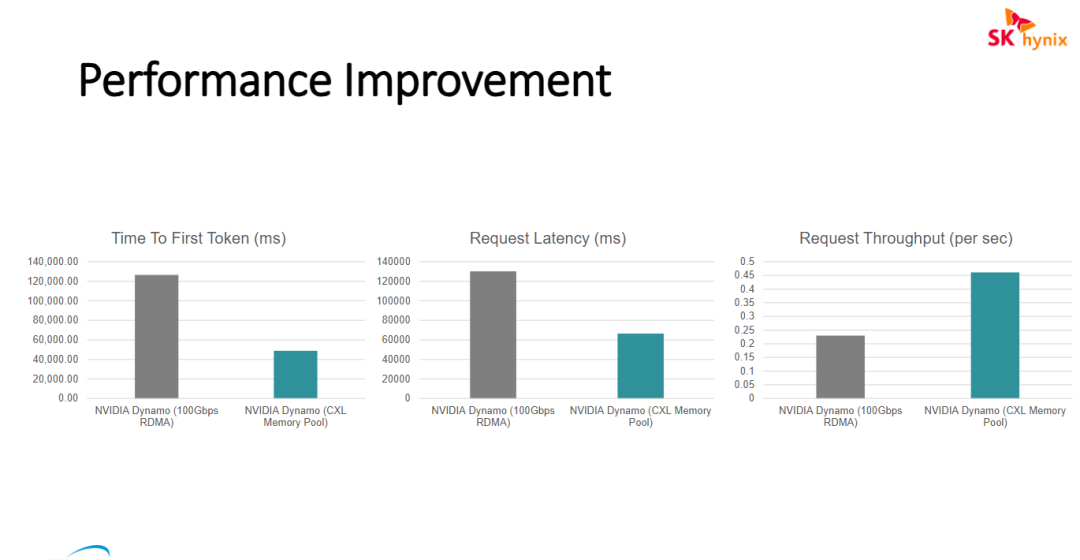
通过三组对比柱状图展示了在 NVIDIA Dynamo 框架下,使用传统的 100Gbps RDMA 网络与使用 CXL Memory Pool(CXL 内存池) 方案在 LLM 推理性能上的量化差异
- CXL 内存池显著优于传统 RDMA 网络通信: 在 LLM 服务场景中,通过 CXL 内存池进行的内存级交互相比于传统的 100Gbps RDMA 高速网络,在各项关键性能指标上均表现出压倒性优势。这验证了池化内存在处理大模型推理中频繁的数据交换(如 KV Cache 共享)时,具有更低的协议开销和更短的路径延迟。
- 推理响应速度与系统吞吐量的双重飞跃: 数据显示,CXL Memory Pool 方案不仅将首字延迟(TTFT)和整体请求延迟降低了一半以上,同时将系统的每秒请求处理能力(吞吐量)提升了约 2 倍。对于需要处理长文本或高并发请求的 AI 应用而言,这种基于硬件架构创新的存储方案是突破现有性能瓶颈的关键。
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- 在机柜级内存池化方案中,如何平衡CXL Switch的硬件成本与系统性能提升带来的投资回报率(ROI)?
- 当控制平面与数据平面完全下沉至内存池时,如何确保在超大规模集群下的系统稳定性与故障隔离能力?
- 随着内存中心化架构的普及,传统的分布式存储厂商应如何调整其产品定位,以应对“存储即内存”带来的市场冲击?
原文标题:Memory Centric AI Machine (DynamoLLM Serving with Memory Pool)
Notice:Human's prompt, Datasets by Gemini-3-Pro
#FMS25 #CXL内存扩展 ---【本文完】---
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号