AAAI 2026 | 华中科大联合清华等提出Anomagic:跨模态提示零样本异常生成+万级AnomVerse数据集(附代码)
原创
AAAI 2026 | 华中科大联合清华等提出Anomagic:跨模态提示零样本异常生成+万级AnomVerse数据集(附代码)
原创
CoovallyAIHub
发布于 2026-03-24 13:08:19
发布于 2026-03-24 13:08:19
导读
现有零样本异常图像生成方法大多仅依赖文本提示引导扩散模型,语义控制力有限,生成的异常掩码精度也不够高。
华中科技大学联合湖南大学、清华大学、中科院自动化所团队提出 Anomagic,核心思路是跨模态提示编码——同时融合视觉参考(异常图像+掩码)和文本描述来引导 Stable Diffusion 的修复式生成,并通过对比式掩码精炼策略提升异常掩码的像素级精度。
为支撑训练,团队构建了 AnomVerse 数据集,从13个公开数据集中汇集了12,987个异常-掩码-描述三元组,覆盖131种缺陷类型和5大领域,论文称其为目前同类最大的异常生成训练集。在VisA数据集上,Anomagic的生成质量(IS 2.16 / IL 0.39)超越所有零样本和少样本方法,集成到SOTA检测器INP-Former++后P-F1达到54.00%,超越少样本方法AnoGen(52.61%)。
论文标题:Anomagic: Crossmodal Prompt-driven Zero-shot Anomaly Generation 作者: Yuxin Jiang, Wei Luo, Hui Zhang, Qiyu Chen, Haiming Yao, Weiming Shen, Yunkang Cao 机构: 华中科技大学 / 湖南大学 / 清华大学 / 中国科学院自动化研究所 代码: https://github.com/yuxin-jiang/Anomagic
一、零样本异常生成为什么需要跨模态提示?
异常图像生成的目标是合成高质量的缺陷样本,用于增强下游异常检测模型的训练。零样本方法不需要真实异常图像,具有更强的实际适用性,但面临两个核心挑战:
1.1 单模态提示的语义控制力不足
目前最具代表性的零样本方法 AnomalyAny 仅通过文本提示操纵 Stable Diffusion 的注意力矩阵来生成异常。但文本提示受限于 CLIP 的 77 token 上限,难以精确描述复杂缺陷的细节特征。同时,纯文本引导缺乏对异常区域位置和形态的直接视觉参照,导致生成结果在空间定位上不够精确。
1.2 异常掩码精度不够
异常生成不仅要产出逼真的异常图像,还需要提供精确的像素级异常掩码——这对下游检测模型的训练至关重要。现有方法通常从注意力图或启发式后处理中提取掩码,边界粗糙,与实际异常区域对齐不佳。
Anomagic 的解决思路:(1) 引入跨模态提示编码(CPE),同时利用视觉参考(异常图像+掩码)和文本描述构建联合条件,为扩散模型提供更丰富、更精确的语义引导;(2) 设计对比式异常掩码精炼策略,通过比较输入正常图像和生成异常图像的像素级差异来获取精确掩码。
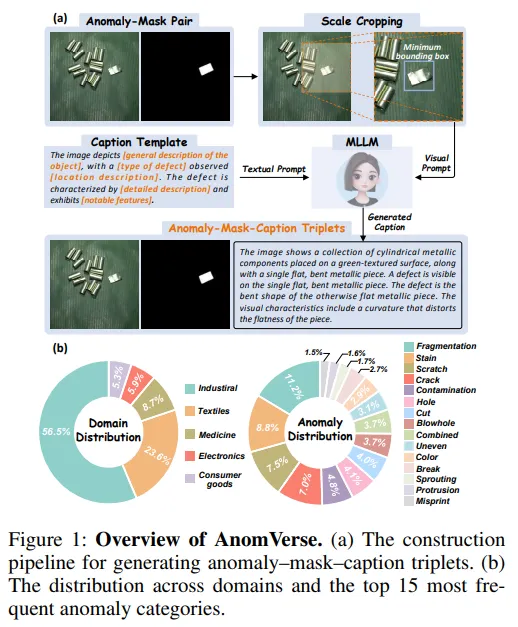
二、AnomVerse数据集:12,987个异常-掩码-描述三元组
screenshot_2026-03-20_11-29-55.png
图片来源于原论文
训练跨模态异常生成模型需要大量的(异常图像, 掩码, 文本描述)三元组,但现有公开数据集通常只有图像和掩码,缺乏对异常的文本描述。Anomagic 团队构建了 AnomVerse 来填补这一空白。
2.1 数据来源与规模
AnomVerse 从 13个公开数据集(包括 MVTec AD、VisA、MANTA 等)中汇集异常样本,覆盖5大领域:
领域 | 占比 |
|---|---|
工业 | 56.5% |
纺织 | 23.6% |
消费品 | 8.7% |
医学 | 5.9% |
电子 | 5.3% |
总计 12,987 个样本,涵盖 131 种缺陷类型。相比此前最大的同类数据集 MMAD(8,366 个样本),AnomVerse 大了约 55%。
2.2 文本描述的自动生成
为每个异常样本生成结构化描述的流程:
- 视觉提示:用异常掩码裁剪出最小包围框,放大异常区域细节;
- 文本模板:设计结构化描述模板——"The image depicts [物体描述], with a [缺陷类型] observed [位置描述]. The defect is characterized by [详细描述] and exhibits [特征描述]."
- MLLM 生成:将裁剪后的视觉提示和模板输入多模态大模型(Doubao-Seed-1.6-thinking),自动生成每个样本的详细文本描述。
这种视觉提示+结构化模板+MLLM的组合确保了描述的质量和一致性。
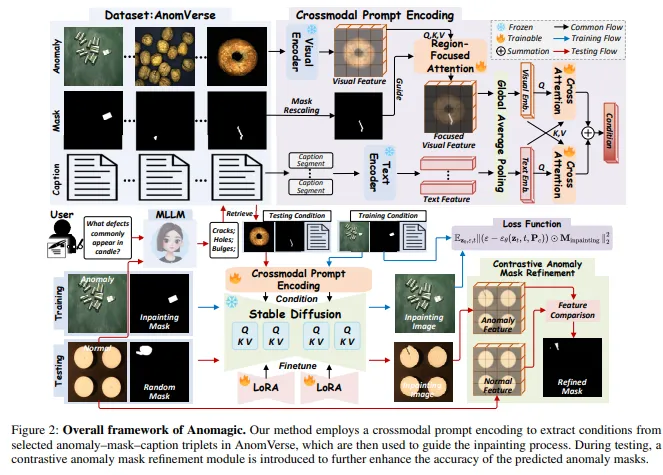
三、Anomagic方法:跨模态提示编码+修复式生成+对比掩码精炼
3.1 跨模态提示编码(CPE)
CPE 是 Anomagic 的核心模块,从三元组(异常参考图像 I^ref、掩码 M^ref、文本描述 t^ref)中提取联合条件:
(1)区域聚焦视觉引导
用预训练 CLIP 图像编码器提取参考异常图像的特征图 F,然后通过区域聚焦注意力机制,利用异常掩码 M^ref 抑制背景区域的注意力权重(乘以大常数 C 做衰减),使视觉特征聚焦于异常区域。
(2)细粒度文本语义
异常描述文本通常较长,超过 CLIP 的 77 token 上限。Anomagic 采用分层编码策略:将长文本切分为语义连贯的片段,分别用 CLIP 文本编码器编码,再通过 mean-pooling 聚合为全局文本嵌入 P_t,保留长距离依赖。
(3)跨模态融合
视觉特征 P_v 和文本嵌入 P_t 通过模态专属交叉注意力块进行双向融合,得到统一的跨模态条件 P_c,作为扩散模型的输入条件。仅注意力模块和融合模块可训练,CLIP 编码器冻结。
3.2 修复式生成训练
Anomagic 基于 Stable Diffusion v1.5(OpenCLIP ViT-H/14),通过 LoRA 微调其交叉注意力层:
- 训练时从 AnomVerse 采样三元组,对参考异常图像的掩码区域做膨胀得到修复掩码,将正常区域遮盖后送入扩散模型;
- 损失函数仅在修复掩码区域计算,模仿模型在掩码内生成与跨模态条件一致的异常,掩码外保持原图;
- 推理时输入正常图像 + 随机掩码 + 从 AnomVerse 检索最相关的跨模态条件,生成异常图像。
3.3 对比式异常掩码精炼
修复式生成保证了异常仅出现在掩码区域内,但生成的异常可能未完全填满初始粗掩码。Anomagic引入对比精炼策略:
- 计算输入正常图像和生成图像异常的像素级差异;
- 使用预训练的MetaUAS模型检测两张图像之间的差异区域;
- 以0.9为阈值生成精炼后的二值掩码M_r。
精炼后的掩码与生成的异常区域严格对齐,为下游检测模型提供更准确的训练标注。
3.4 推理流程
用户只需提供一个简单的问题(如“腰果中常见的缺陷有哪些?”),Anomagic 通过 MLLM 生成语义回复(如“裂纹、孔洞、凸起、划痕”),再从 AnomVerse 中检索最相关的三元组作为跨模态条件,实现零样本异常生成。也支持用户自定义表单提示、文本提示或跨模态提示。
screenshot_2026-03-20_11-30-10.png
图片来源于原论文
四、实验:生成质量与下游检测双重验证

screenshot_2026-03-20_11-30-21.png
图片来源于原论文
4.1 生成异常质量
论文在 VisA 数据集上评估生成质量(IS 最小图像质量,IL 即 Intra-Cluster LPIPS 最小多样性):
方法 | 类型 | 是 | 伊利诺伊州 |
|---|---|---|---|
AnoGen | 样本少 | 2.10 | 0.39 |
梦境 | 零样本 | 1.85 | 0.37 |
RealNet | 零样本 | 1.86 | 0.37 |
异常 | 零样本 | 1.94 | 0.33 |
异常的 | 零样本 | 2.16 | 0.39 |
- Anomagic 的 IS(2.16)为最高,IL(0.39)与少样本方法 AnoGen 并列最高,IS 超越 AnoGen(2.10);
- IS 比零样本第二名 AnomalyAny(1.94)高出+0.22,IL 高出+0.06。
4.2 下游异常检测性能
论文采用了与常规方法不同的评估范式:不用简单的U-Net检测器,而是将生成的异常图像集成到当前SOTA检测方法INP-Former++中进行训练增强,在VisA上评估:
方法 | I-ROC | I-F1 | 专业版 | P-F1 |
|---|---|---|---|---|
补丁核心 | 95.10 | 94.10 | 91.20 | 44.70 |
RD4AD | 96.00 | 94.30 | 70.90 | 42.60 |
恐龙异常 | 98.90 | 96.20 | 95.30 | 48.60 |
AnoGen(少样本) | 99.09 | 96.55 | 95.62 | 52.61 |
梦境 | 99.03 | 96.58 | 95.59 | 51.94 |
RealNet | 99.03 | 96.75 | 95.70 | 52.87 |
异常 | 99.01 | 96.48 | 95.57 | 50.76 |
异常的 | 99.08 | 96.77 | 95.92 | 54.00 |
关键发现:
- Anomagic的P-F1达到54.00%,比少样本方法AnoGen的52.61%高出+1.39%,比零样本方法AnomalyAny的50.76%高出+3.24%;
- PRO达到95.92%,为所有方法中最高;
- I-F1达到96.77%,同样最高;
- 论文特别指出,Anomagic 是零样本方法,但却在 P-F1 和 PRO 上超越了使用真实异常图像训练的 AnoGen。
4.3 消融实验
CPE 和 LoRA 的贡献(VisA 上 INP-Former++ 增强后):
CPE | 罗拉 | 是 | 伊利诺伊州 | I-ROC | I-F1 | 专业版 | P-F1 |
|---|---|---|---|---|---|---|---|
— | — | 1.85 | 0.375 | 99.03 | 96.58 | 95.59 | 51.94 |
✓ | — | 2.16 | 0.394 | 99.04 | 96.71 | 95.88 | 53.87 |
✓ | ✓ | 2.16 | 0.394 | 99.07 | 96.77 | 95.92 | 54.00 |
- 基线(无CPE无LoRA)即为DRAEM的水平;
- 加入CPE后IS从1.85提升至2.16(+0.31),P-F1从51.94%提升至53.87%(+1.93%),说明跨模态提示编码是生成质量提升的核心驱动力;
- 加入LoRA后P-F1进一步提升至54.00%(+0.13%),收益相对较小,但正向贡献增加。
4.4 生成效率
方法 | 单张生成时间 | 硬件 |
|---|---|---|
异常 | 〜3分钟 | — |
异常的 | ~1.2秒 | A100 GPU |
Anomagic的端到端生成精度(包括异常生成和掩码精炼)在512×512分辨率下约1.2秒,比AnomalyAny快约150倍。
五、总结与思考
论文贡献
Anomagic 提出了跨模态驱动提示的零样本异常生成框架:CPE模块边界融合和文本描述构建联合条件,修复式扩散生成在掩码内合成异常,对比掩码精炼策略提升掩码准确性。连接的AnomVerse数据集(12,987个三元组,131种缺陷,13个来源数据集)为跨模态异常生成训练提供了参考基础。在VisA上集成到INP-Former++之后,P-F1达到54.00%,在P-F1、PRO、I-F1上超越所有零样本和少样本基线。
几点思考
1.跨模态与单模态提示的本质差异
与近似文本工作AnoStyler(纯驱动风格迁移)相比,Anomagic的核心差异引入了视觉作为附加条件。这使得生成的异常不仅在图像上与文本一致,还在纹理、形态上与异常图像相似。代价是需要AnomVerse这样的三元组数据集作为库,而AnoStyler拓扑标签和缺陷类型文本。两种方案各有参考适用场景:有参考异常库时使用Anomagic效果更好,完全从零开始时AnoStyler 更灵活。
2. 评估范式的差异含义
Anomagic选择将生成的异常集成到SOTA检测器INP-Former++中评估,而不是用简单的U-Net检测器(AnoStyler等方法的评估方式)。这意味着Anomagic和AnoStyler的下游检测数据不能直接横向对比——检测器的基础能力不同,提升幅度的意义也不同。的评估范式更接近实际应用场景(增强以往的强检测器),但也使得方法间的纯生成质量贡献更难分割。
3.AnomVerse的价值社区
12,987个带构造文本描述训练的异常三元组,覆盖131种缺陷类型,是目前同类最大的数据集。这不仅服务于Anomagic的,也为其他需要异常文本描述的研究(如多模态异常检测、异常相关的VQA)提供了基础资源。
4.生成速度的工程意义
1.2 秒/张 vs AnomalyAny 的 3 分钟/张,150 倍的速度差异在工业场景中具有意义——批量生成数千张训练样本时,Anomagic 完成瞬间,而 AnomalyAny 需要数天。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号