为什么 RAG 比微调更适合企业?

为什么 RAG 比微调更适合企业?

臻成AI大模型
发布于 2026-02-02 13:43:58
发布于 2026-02-02 13:43:58
你有没有发现,现在的AI越来越聪明了?
它不仅能回答你关于公司制度的问题,还能准确说出某个法条的修改时间,或者从一份复杂的财务报表中提取关键数据。
这背后到底隐藏着什么秘密?

从死记硬背到智能检索
答案就在RAG技术里。
RAG,全称检索增强生成(Retrieval-Augmented Generation),可以说是给AI装上了外接大脑。
传统的大语言模型就像一个博学的教授,知识虽然丰富,但都是死记硬背来的。
它只知道训练时见过的东西,对于之后发生的事一概不知。而RAG技术就像是给这位教授配了一个超级助理,这个助理能在几秒钟内从图书馆、互联网、各种数据库中找到最相关的信息,然后递给教授。
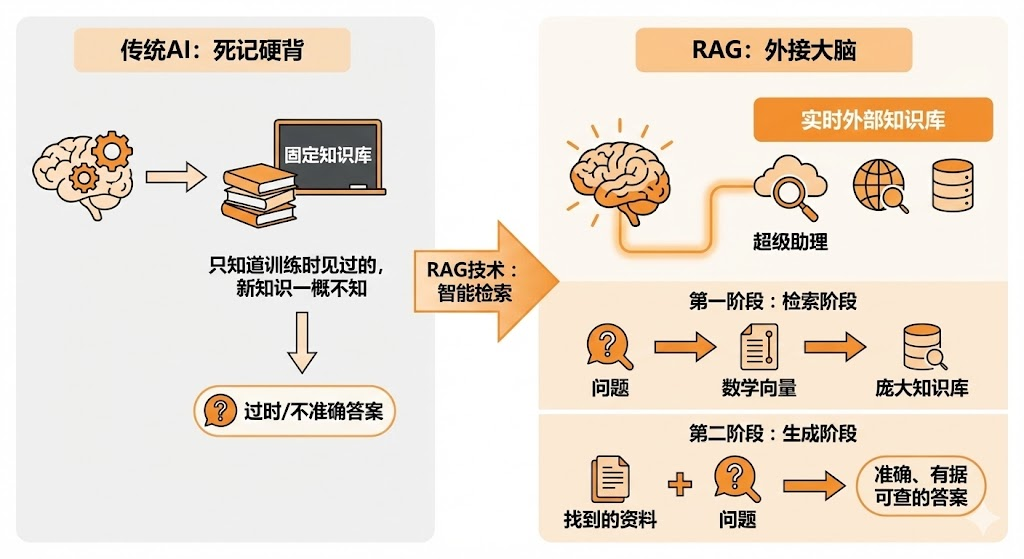
更具体地说,RAG采用了双阶段架构。
第一阶段是检索阶段,AI先将你的问题转换成数学向量,然后在庞大的知识库中进行语义搜索,找到最相关的资料。
第二阶段是生成阶段,AI把找到的资料和你的问题一起处理,给出准确、有据可查的答案。
这就像是在AI的大脑旁边又装了一个硬盘,里面存储着随时可以调用的外部知识。
AI既保持了自己原有的思考能力,又能随时获取最新的、准确的信息。
RAG 的跨越
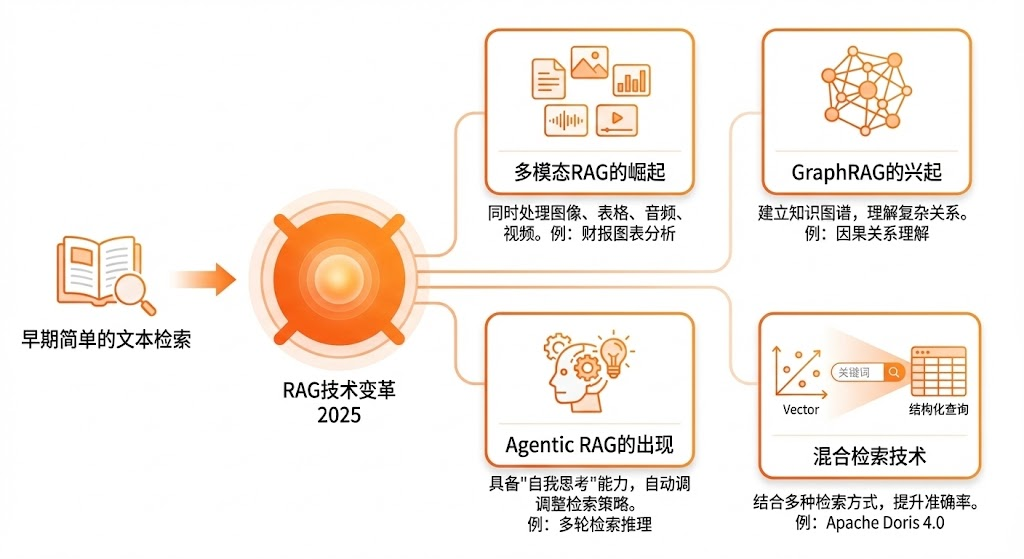
2025年,RAG技术已经发生了根本性的变革。
早期简单的文本检索已经进化为多模态融合的复杂系统。
首先是多模态RAG的崛起。
现在的RAG不再局限于文字,它能同时处理图像、表格、音频、视频等各种类型的数据。
比如,在分析一份包含图表的财报时,AI不仅能理解文字说明,还能看懂图表中的数据趋势。
其次是GraphRAG的兴起。
传统的RAG就像是在一堆文档中翻书,而GraphRAG更像是建立了一个知识图谱,它能理解事物之间的复杂关系。
比如问苹果公司的供应链问题对股价的影响,它不仅能找到相关信息,还能理解供应链、股价、问题之间的因果关系。
更重要的是Agentic RAG的出现。
这种系统具备了自我思考的能力,它会根据问题的复杂性自动调整检索策略。
对于简单问题快速检索,对于复杂问题则采用多轮检索和推理。
还有混合检索技术,它结合了向量搜索、关键词搜索、结构化查询等多种检索方式,大大提升了检索的准确性和召回率,例如 Apache Doris 4.0。
就像一个经验丰富的图书管理员,既能根据书名查找,也能根据主题分类,还能根据关键词索引。
为什么RAG比微调更适合企业?
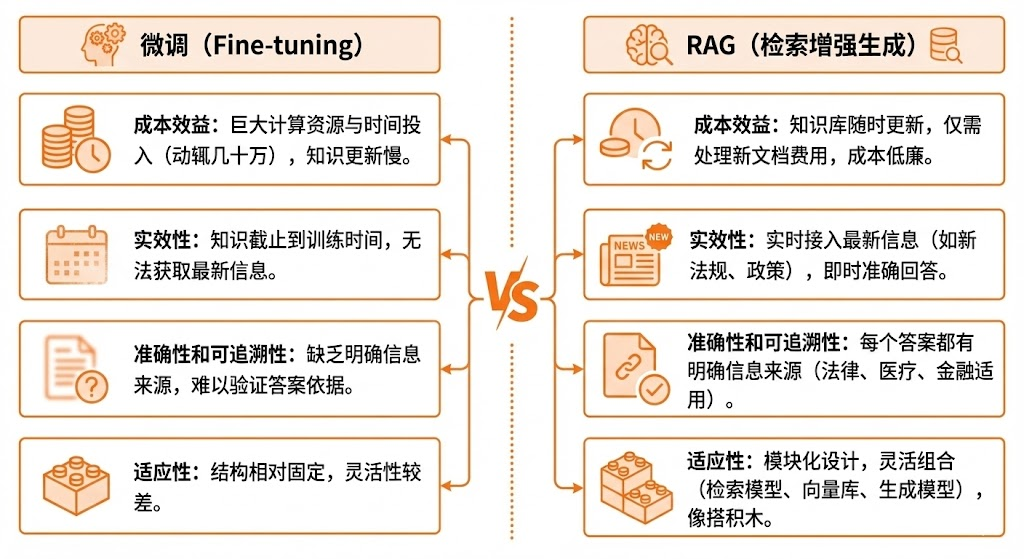
很多人会问,为什么不直接让AI学会这些知识,而要用RAG这么复杂的技术?
这涉及到成本效益的考量。
微调一次AI需要巨大的计算资源和时间投入,成本动辄几十万,而且知识更新周期长。而RAG系统的知识库可以随时更新,成本仅仅是处理新文档的费用。
更重要的是实效性。
传统AI的知识截止到训练时间,而RAG可以实时接入最新信息。比如新发布的法规、新出台的政策,RAG第二天就能准确回答相关问题。
还有准确性和可追溯性。
RAG的每个答案都有明确的信息来源,这在法律、医疗、金融等对准确性要求极高的领域至关重要。医生可以查看AI诊断建议的参考依据,律师可以验证AI法律意见的出处。
从技术架构上看,RAG的模块化设计让它具有极强的适应性。
企业可以根据具体需求灵活选择不同的检索模型、向量数据库、生成模型,就像搭积木一样组合出最适合自己业务的系统。
结语
RAG技术的进化还在继续。
随着AI Agent技术的成熟,未来的RAG系统将更加智能和自主。它们不再是被动响应查询,而是能够主动理解用户需求,智能规划检索策略,甚至主动发现和纠正错误。
更重要的是,RAG正在从单纯的检索增强生成工具,演进为AI应用的基础设施。无论是智能客服、知识管理、决策支持,还是创意辅助,RAG都在发挥着越来越重要的作用。
在这个信息爆炸的时代,我们不需要一个什么都懂的AI,而需要一个能在海量信息中快速、准确找到答案的智能助手。RAG技术正是这样一个"智能图书管理员",它不仅知道在哪里找到我们需要的信息,还能理解信息的含义,并将其准确传达给我们。
对于每一个想要在AI时代保持竞争力的企业和个人来说,理解RAG技术,掌握RAG应用,就是掌握未来智能应用的钥匙。RAG不仅是技术的革新,更是思维方式的重构——从"知道所有答案"到"知道在哪里找到答案",这才是真正的智能所在。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号