Nat. Commun. | 系统量化大语言模型在临床病例推理中的能力

Nat. Commun. | 系统量化大语言模型在临床病例推理中的能力

DrugAI
发布于 2026-01-06 13:52:56
发布于 2026-01-06 13:52:56
DRUGONE
大语言模型(LLMs)在医学领域展现出令人瞩目的潜力,但其在临床病例中的推理能力、诊断表现以及背后依赖的信息结构仍缺乏系统性的量化评估。研究人员构建了一个覆盖多学科、多步骤推理任务的临床测试体系,用于检测 LLM 在症状分析、检查解读、诊断推理以及治疗建议等关键环节的表现。研究人员对多个前沿 LLM 进行系统评估,发现这些模型能够利用病例描述进行基础推理,但在关键信息提取、因果逻辑、反事实推理和复杂多步骤诊断流程中仍表现有限。研究人员进一步分析模型输出,揭示了其依赖的统计模式、知识偏差及推理链条断裂的来源,并提出一套用于衡量“医学推理能力”的多维度量化指标。该工作为未来开发具备医学推理可靠性的大模型提供了明确方向。

大语言模型在理解自然语言、生成内容以及多模态信息整合方面表现突出,已被应用于医疗问答、病程总结、辅助诊断和治疗建议。然而,与一般知识问答不同,临床推理是一种复杂过程,包括:
- 症状与体征的抽象化
- 病因假设的提出与更新
- 检查与化验单据的解释
- 排除性诊断
- 风险评估
- 治疗决策
这些步骤需要将专业知识、逻辑推理和经验判断结合,而当前 LLM 是否真正具备这些能力仍不清楚。
现有医学评测多聚焦于单项任务,例如医学问答、影像分类或病例选择题。然而,真实临床情境往往涉及跨信息源、多时间维度、多因果链条的复杂推理。因此需要一种能够模拟真实场景并量化 LLM 推理深度与鲁棒性的测试体系。
本研究旨在通过构建包含多阶段推理和真实诊断路径的临床评估框架,全面量化 LLM 在临床病例中的推理表现,并分析限制其能力的核心因素。
方法
研究人员设计了一套面向临床推理的量化框架,包括任务构建、推理标注、模型评估与误差分析四个主要部分。
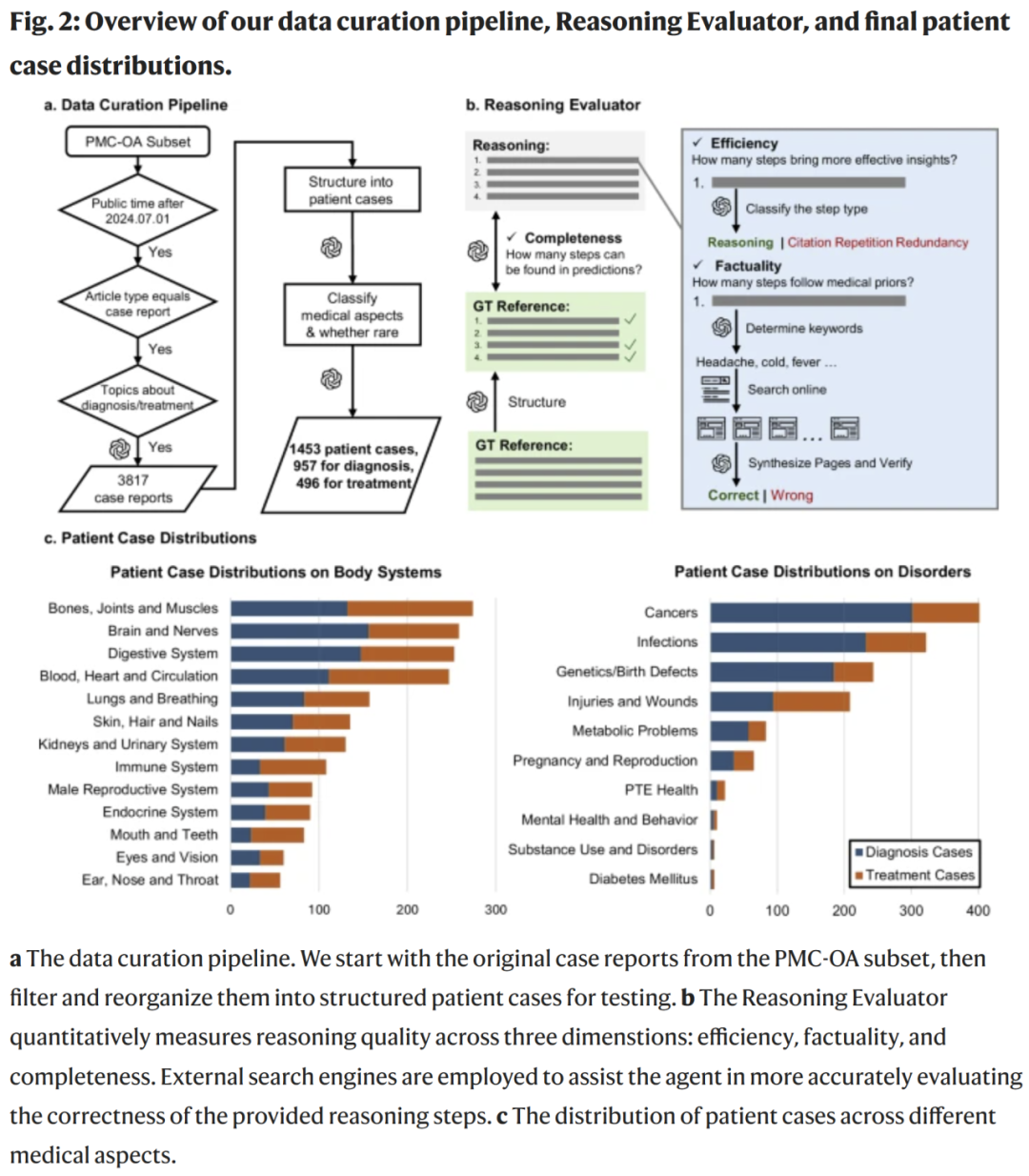
多步骤临床病例任务的构建
研究人员从真实病例中提取关键诊疗步骤,包括:
- 初诊症状描述
- 体格检查
- 化验/影像结果
- 鉴别诊断
- 最终诊断
- 治疗方案
每个病例均经过临床专家审核,以确保信息完整性与推理链条的准确性。
推理标签体系构建
针对每一步,研究人员构建了可量化的推理评价体系,包括:
- 信息提取正确性
- 假设生成能力
- 因果关系判断
- 推理链条连贯性
- 对不确定性的处理方式
- 与临床指南一致性
这些标签使模型输出能够被分解为多个可测推理维度。
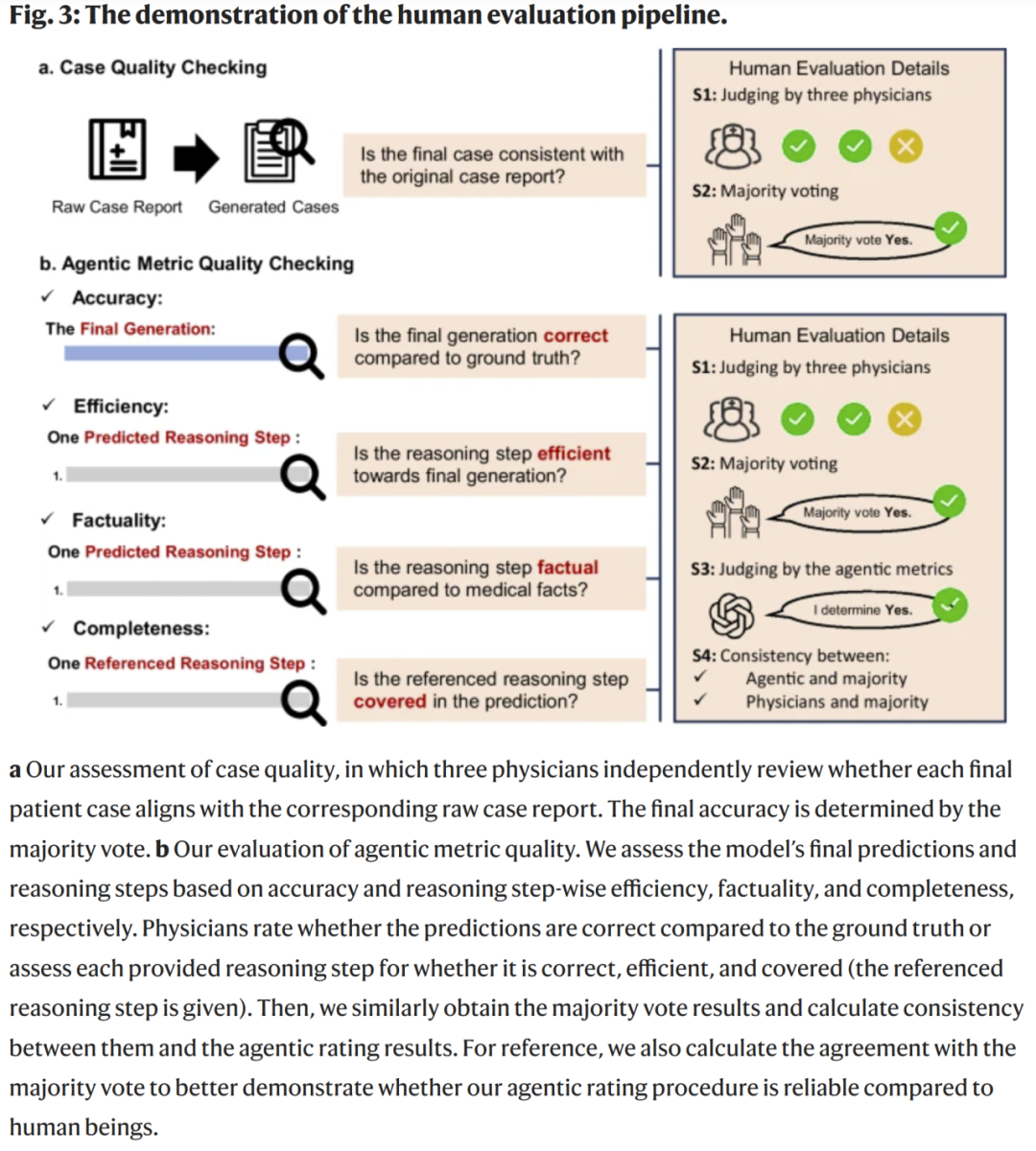
大语言模型测试与评分
研究人员对多个 LLM 进行盲测,模型仅接触病例文本,不提供外部知识来源,确保评估其内生推理能力。
评分方式包括:
- 客观指标(准确率、召回率、多分类指标)
- 推理链评分(由临床专家根据评分体系评价)
- 反事实推理测试(例如修改部分信息并观察模型推理是否合理更新)
错误类型与推理瓶颈分析
研究人员对错误进行分组,包括:
- 信息遗漏
- 逻辑链断裂
- 基于统计模式的“表面推理”
- 幻觉式诊断
- 不合理治疗建议
- 不一致或自相矛盾的推理
通过这些分析,研究人员揭示不同模型在医学推理中的关键限制因素。
结果
模型能识别主要症状,但在细节推理上表现不足
LLM 能从病例描述中提取主要症状(例如胸痛、呼吸困难、发热等),但在处理:
- 病程时间
- 症状演变
- 轻微但关键的细节
时表现不稳定。这会导致模型推理偏离正确诊断路径。
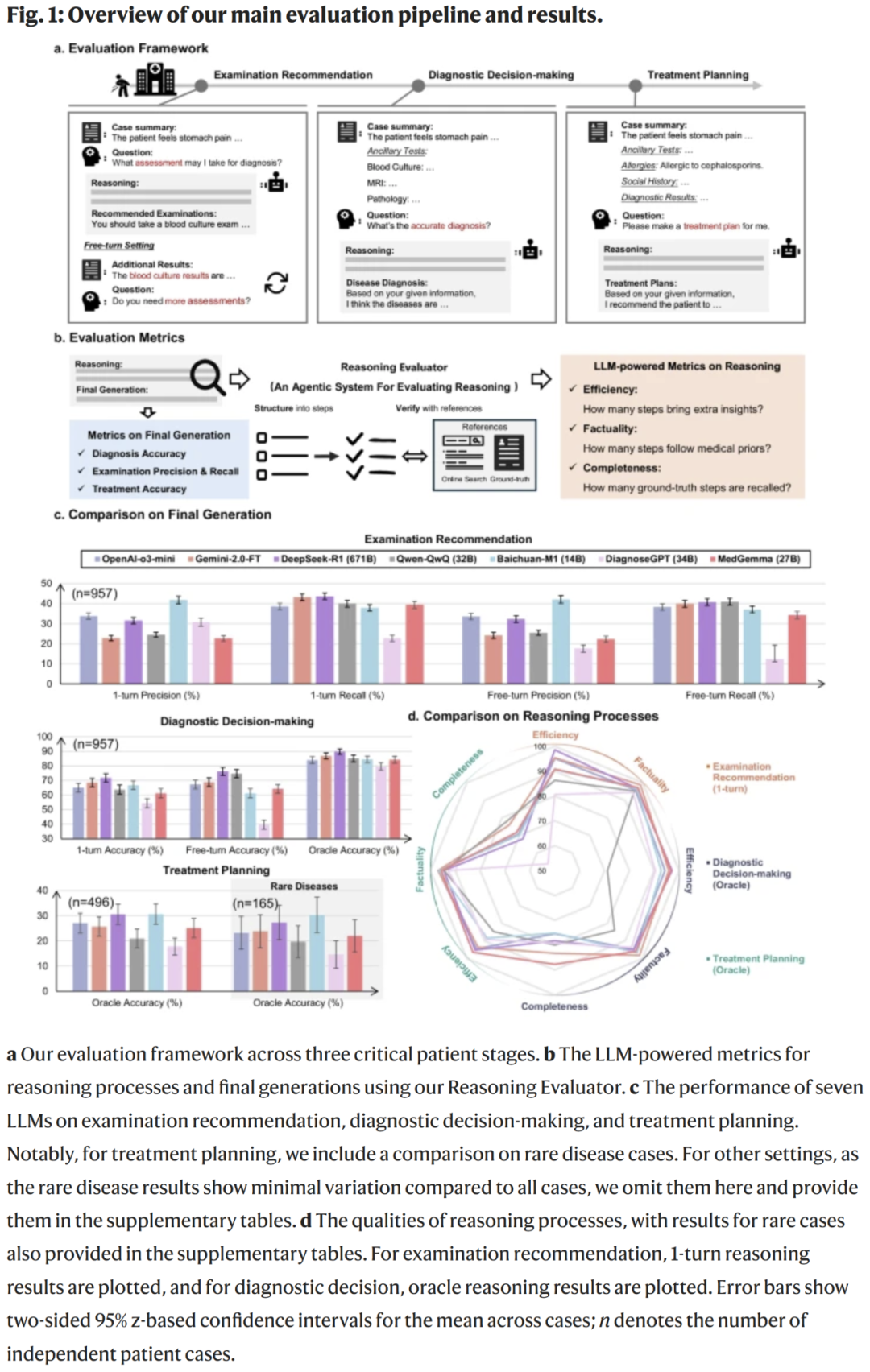
模型在因果逻辑推理中的能力有限
研究人员发现:
- 模型倾向于根据 统计模式 进行“模式匹配式推理”,而不是根据因果证据链
- 修改病例某个关键变量(如年龄、药物史)时,模型更新诊断的能力有限
- 当检查结果与症状冲突时,模型往往无法进行冲突解决
这些现象表明模型缺乏真正的因果结构理解。
在多步骤诊断路径中,模型容易失去连贯性
随着病例信息逐步提供:
- 模型在生成初步假设时表现尚可
- 在整合新的实验室检查或影像信息时,模型常无法正确更新诊断
- 多个模型出现“推理链断裂”或“跳步诊断”
这说明模型缺乏系统整合多源医学信息的能力。
治疗建议的质量变化较大
在治疗步骤中:
- 一些模型能给出与指南一致的治疗方案
- 但许多输出存在不准确甚至风险性建议
- 对药物剂量的理解尤为薄弱
- 对特定人群(孕妇、儿童、老年人)缺乏个体化推理
说明 LLM 尚未具备真正的临床决策能力。
多维度量化指标揭示模型推理结构的缺陷
研究人员提出的推理维度评分显示:
- 信息提取:中等水平
- 初步诊断假设生成:表现良好
- 因果推理:弱
- 检查解释:中等偏弱
- 综合推理链:不稳定
- 治疗决策:高变异性
这反映了当前 LLM 在医学领域的结构性推理限制。
讨论
研究人员指出,大语言模型在处理临床病例时具有一定的语言理解和模式识别能力,但远未达到临床级推理所需的可靠性和精确度。其局限归因于:
- 缺乏真正的医学因果知识结构
- 无法跨诊断步骤保持逻辑一致性
- 基于统计模式的“伪推理”掩盖了真实能力不足
- 对不确定性与冲突信息处理不佳
- 训练数据缺乏高质量、多步骤、多模态的临床推理样本
未来研究方向包括:
- 将 LLM 与医学知识图谱、因果推理模块结合
- 构建真实世界的多步骤医学推理训练集
- 引入多模态医学信息(影像、化验、病历)增强推理
- 在模型输出中加入可解释性与安全监督
- 开发具有推理链验证机制的“可控医学大模型”
研究人员强调,虽然 LLM 已展示潜在价值,但在实际临床应用前仍需大量验证与安全加固,以确保患者安全。
整理 | DrugOne团队
参考资料
Qiu, P., Wu, C., Liu, S. et al. Quantifying the reasoning abilities of LLMs on clinical cases. Nat Commun 16, 9799 (2025).
https://doi.org/10.1038/s41467-025-64769-1
内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号