Live VLM WebUI:在NVIDIA Jetson上实现实时视觉语言模型测试与部署

Live VLM WebUI:在NVIDIA Jetson上实现实时视觉语言模型测试与部署

GPUS Lady
发布于 2026-01-05 11:57:23
发布于 2026-01-05 11:57:23
在人工智能飞速发展的当下,视觉语言模型(VLM)已逐渐走向边缘部署,从 4B 到 90B + 参数的各类模型层出不穷,为实时视觉分析场景带来了无限可能。然而,传统测试工具往往存在缺乏实时流支持、跨平台基准测试能力不足、硬件监控集成缺失等问题。NVIDIA 推出的 Live VLM WebUI 应运而生,以 WebRTC 实时流为核心,打造了一站式 VLM 实时评估与部署界面,完美解决了上述痛点。
一、核心亮点与适用场景
(一)核心优势
Live VLM WebUI 是一款专为实时视觉语言模型评估设计的便捷界面,其核心优势体现在以下方面:
- 多源视频输入灵活适配:支持 WebRTC 摄像头流(稳定)和 RTSP 网络摄像头流(Beta 版),满足桌面端、边缘设备等不同场景的视频采集需求。
- 多后端兼容无缝切换:兼容 Ollama、vLLM、SGLang 等本地推理框架,同时支持 NVIDIA API Catalog 等云 API 服务,可根据需求选择本地部署或云端调用。
- 实时交互与监控一体化:提供交互式提示词编辑器,支持 8 种预设提示词和自定义输入,同时集成 GPU/CPU 利用率、显存 / 内存占用等硬件监控数据,实时掌握模型运行状态。
- 跨平台部署广泛兼容:支持 Jetson 系列边缘设备、x86_64 PC、Apple Silicon Mac、Windows(WSL2)等多种平台,适配从边缘计算到桌面端的各类硬件环境。
(二)适用场景
- 模型基准测试:可测试不同 VLM 模型的帧处理延迟、目标检测精度、OCR 性能、多语言支持能力,通过统一硬件指标横向对比模型优劣。
- 机器人视觉开发:为机器人系统提供目标识别、场景理解、人机交互等视觉能力支撑,助力机器人导航与决策功能 prototyping。
- 边缘 AI 应用原型:在 Jetson 等边缘设备上快速验证 VLM 模型部署可行性,为智能监控、工业质检等边缘场景提供快速开发工具。
- 计算机视觉流水线替代:在特定场景下可替代或增强传统计算机视觉流水线,如智能城市中的视频检索与摘要生成。
二、支持的模型与硬件要求
(一)兼容的开源 VLM 模型
Live VLM WebUI 支持主流开源视觉语言模型,覆盖不同参数规模,满足从轻量化部署到高精度推理的各类需求:
开发者 | 模型名称 | 支持参数规模 |
|---|---|---|
阿里巴巴 | Qwen 2.5 VL | 3B、7B、32B、72B |
阿里巴巴 | Qwen 3 VL | 2B、4B、8B、30B、32B、235B |
谷歌 | Gemma 3 | 4B、12B、27B |
元宇宙 | Llama 3.2-Vision | 11B、90B |
元宇宙 | Llama 4 | 16×17B、128×17B |
微软 | Phi-3.5-vision | 4.2B |
NVIDIA | Cosmos-Reason1 | 7B |
NVIDIA | Nemotron Nano 12B V2 VL | 12B |
(二)硬件与环境要求
- 支持设备:Jetson AGX Thor 开发者套件、Jetson AGX Orin(32GB/64GB)、Jetson Orin Nano(8GB),以及 PC(RTX 显卡)、Mac(M3)、Windows(WSL2+RTX 显卡)等设备。
- 系统版本:Jetson 设备需搭载 JetPack 6(L4T r36.x)或 JetPack 7(L4T r38.x);其他设备需满足对应操作系统的 Python 环境要求。
- 存储需求:建议配备 NVMe SSD,Live VLM WebUI 容器本身需约 4GB 存储空间,本地部署模型时需额外预留模型下载空间(如 Gemma 3:4B 约需数 GB)。
三、Jetson 设备安装步骤
(一)步骤 1:部署 VLM 后端(以 Ollama 为例,Jetson 专属配置)
首先需在 Jetson 设备上安装 Ollama 作为本地 VLM 后端,执行以下命令:
# Jetson 设备(Linux 系统)安装 Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 下载 Jetson 适配的轻量型推荐模型(Gemma 3:4B,运行流畅)
ollama pull gemma3:4b
# 可选:下载其他适配 Jetson 的模型
# ollama pull llama3.2-vision:11b(Jetson AGX Orin/Thor)
# ollama pull qwen2.5-vl:7b(Jetson Orin 系列)Jetson Thor 专属注意事项:JetPack 7.0 用户需安装 Ollama 0.12.9 版本(0.12.10 存在 GPU 推理兼容性问题):
# 卸载现有 Ollama(若已安装)
sudo systemctl stop ollama
sudo rm /usr/local/bin/ollama
# 安装 Ollama 0.12.9 适配版本
curl -fsSL https://ollama.com/install.sh | OLLAMA_VERSION=0.12.9 sh(二)步骤 2:安装 Live VLM WebUI(Jetson 容器化部署)
通过 Git 克隆仓库并启动 Jetson 专属 Docker 容器,命令如下:
# 克隆仓库
git clone https://github.com/nvidia-ai-iot/live-vlm-webui.git
cd live-vlm-webui
# 启动 Jetson 适配的 Docker 容器(自动检测 Jetson 型号与 JetPack 版本)
./scripts/start_container.sh(三)步骤 3:访问 Web 界面(本地 / 局域网)
容器启动后,通过浏览器访问以下地址(Jetson 设备需连接网络):
- 本地访问(Jetson 设备外接显示器):https://localhost:8090
- 网络访问(同一局域网 PC / 平板):https://<Jetson 设备 IP 地址>:8090(如 https://10.110.50.252:8090)
Jetson 专属小贴士:Jetson Orin Nano 用户建议通过同一局域网的 PC 远程访问 Web 界面,减少设备本地资源占用,获得更流畅的操作体验。
(四)步骤 4:证书信任与权限授予
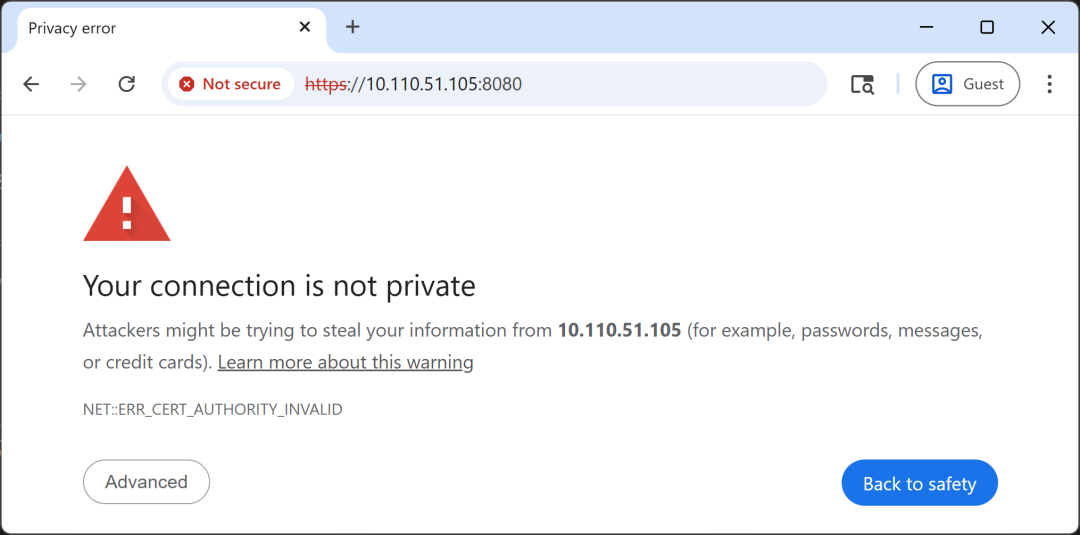
首次访问时,浏览器会提示 “连接不安全”(因使用自签名 SSL 证书),需按以下步骤操作:
- 点击 “Advanced”(高级)→ “Proceed to <IP 地址 > (unsafe)”(继续访问)。
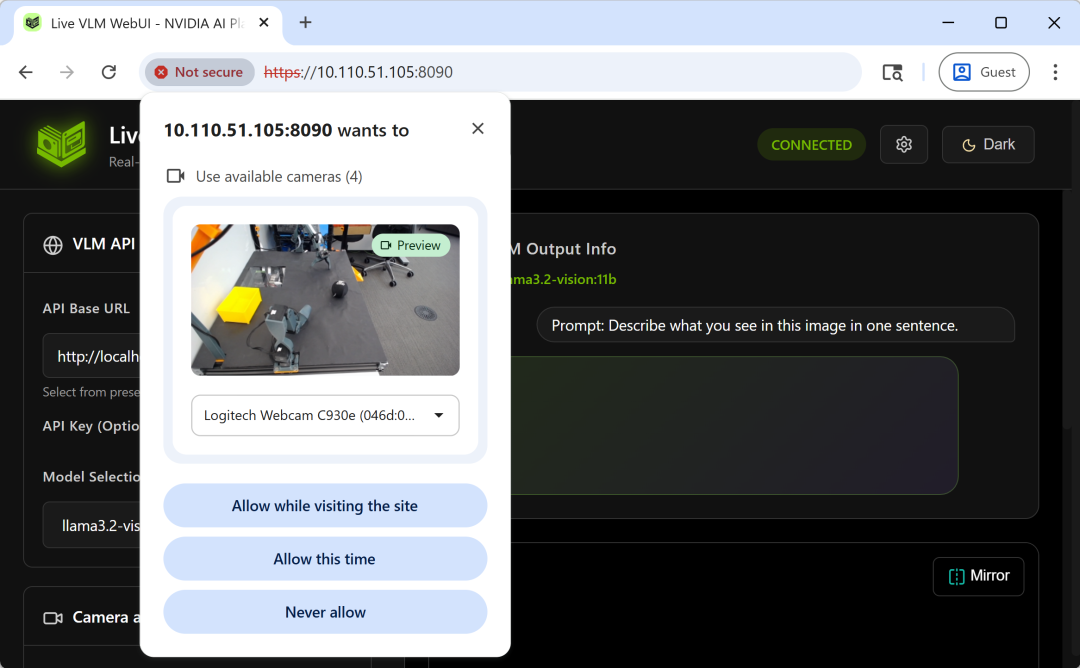
- 当浏览器请求摄像头权限时,选择 “Allow while visiting the site”(访问期间允许),确保 Jetson 外接摄像头正常采集视频流。
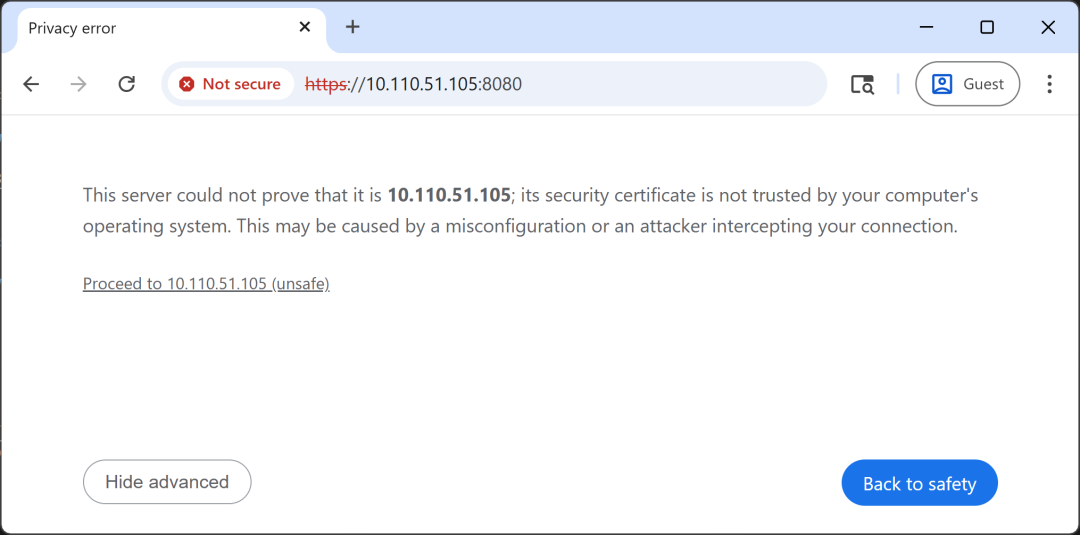
3. 收到提示时允许摄像头访问
四、Jetson 设备功能使用指南
(一)核心配置与启动分析(Jetson 优化设置)
- VLM API 配置验证:界面会自动检测 Jetson 本地运行的 Ollama/vLLM 后端,默认 API 地址为 http://localhost:11434/v1(Ollama)或 http://localhost:8000/v1(vLLM),无需手动配置。若使用云 API,需手动输入 API 端点和密钥。
- 模型选择:在 “Model Selection” 下拉菜单中选择已下载的 Jetson 适配模型(如 gemma3:4b),建议根据 Jetson 型号选择对应参数模型(避免算力不足导致卡顿)。
- 摄像头设置:在 “Camera Selection” 中选择 Jetson 外接的 USB 摄像头或网络摄像头,支持分析过程中实时切换设备。
- 启动分析:点击 “Open Camera and Start VLM Analysis” 按钮,系统默认每 30 帧分析一次(Jetson Orin Nano 建议设为 60 帧,平衡性能与延迟)。
(二)提示词自定义与实时优化(边缘场景适配)
提示词编辑器支持预设提示词和自定义输入,适配 Jetson 常见边缘场景(如工业质检、设备巡检):
- 预设提示词(8 种,适配边缘需求)场景描述:“用一句话描述图像内容” 目标检测:“列出图像中所有物体,用逗号分隔” 行为识别:“描述人物的活动和行为” 安全监控:“是否存在安全隐患?用‘ALERT: 描述’或‘SAFE’回答”(适配边缘安防场景) 情绪检测:“描述可见人物的面部表情和情绪” 无障碍描述:“为视障人士提供详细场景描述” OCR 文本识别:“读取并转录图像中所有可见文本”(适配工业设备铭牌识别) 是非问答:“仅用 Yes 或 No 回答:是否有人物出现?”
- 自定义提示词(Jetson 边缘场景示例)针对工业质检场景,可输入 “检测图像中零件是否存在划痕,回答‘合格’或‘不合格:划痕位置’”;针对设备巡检场景,可输入 “识别设备指示灯颜色,列出异常指示灯位置”。
(三)Jetson 专属参数调整(平衡算力与性能)
- 帧处理间隔:Jetson Orin Nano 建议设为 60 帧,Jetson AGX Orin/Thor 可设为 30-45 帧,避免频繁分析导致 GPU 过载。
- 最大令牌数:边缘场景建议设为 50-100(短回答),减少显存占用和推理时间;需详细描述时可设为 256。
- 镜像显示:点击 “Mirror” 按钮开启镜像模式,方便调试 Jetson 外接摄像头的拍摄角度。
(四)实时监控与结果查看(Jetson 硬件专属监控)
- 分析结果展示右侧主面板显示实时视频流和分析结果,支持 Markdown 格式输出;顶部显示推理延迟(Jetson Orin Nano 运行 gemma3:4b 约 7-8 秒 / 帧,AGX Orin 约 1-2 秒 / 帧)、平均延迟、分析次数等指标。
- Jetson 硬件监控左侧面板底部专属显示 Jetson 设备的 GPU 利用率、显存占用(如 12.1/48.0 GB)、CPU 利用率、系统内存使用情况,实时掌握边缘硬件负载状态(需提前安装 jetson-stats 工具)。
五、Jetson 设备常见问题排查
- 摄像头无法访问确保使用 HTTPS 协议访问,且已授予摄像头权限;Jetson 设备需确认摄像头已正确接入 USB 端口(可通过
lsusb命令验证)。 - 无法连接 VLM 后端检查 Ollama 是否在 Jetson 上正常运行(执行
curl http://localhost:11434/v1/models验证),并开放 11434 端口(Ollama)或 8000 端口(vLLM)。 - GPU 监控显示 “N/A”Jetson 设备需安装 jetson-stats(
sudo pip3 install -U jetson-stats),重启设备后生效;Docker 容器需确保挂载 jtop socket(启动脚本已默认配置)。 - 推理性能卡顿更换更小参数模型(如 gemma3:4b 替代 llama3.2-vision:11b)、增加帧处理间隔、减少最大令牌数,或通过
jtop工具关闭 Jetson 设备上其他占用 GPU 的进程。 - JetPack 版本不兼容Live VLM WebUI 仅支持 JetPack 6/7,若使用 JetPack 5.x 需升级系统,或通过 Docker 容器自动适配 Python 环境。
六、总结
专为 Jetson 设备深度优化的 Live VLM WebUI,以其轻量化部署、强硬件适配、实时交互与监控一体化的优势,成为边缘端 VLM 模型评估与部署的专属利器。无论是开发者在 Jetson 上进行模型基准测试,还是工程师搭建基于 Jetson 的机器人视觉原型,亦或是企业部署边缘 AI 应用,Live VLM WebUI 都能提供高效、直观的操作体验。其开源特性(Apache 2.0 许可证)支持二次开发,可轻松集成到 ROS 2 等机器人框架或 Jetson 专属计算机视觉系统中,为 Jetson 边缘设备的视觉语言模型落地应用提供全方位赋能。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号