洛克菲勒 + 耶鲁团队联合实证:AlphaFold3 进军药物发现,颠覆者还是好帮手?

洛克菲勒 + 耶鲁团队联合实证:AlphaFold3 进军药物发现,颠覆者还是好帮手?

DrugIntel
发布于 2025-12-17 14:24:45
发布于 2025-12-17 14:24:45

自AlphaFold2以近实验级精度破解蛋白质结构预测难题并斩获2024年诺贝尔化学奖以来,深度学习驱动的结构生物学已迈入新的发展阶段。AlphaFold3(AF3)作为新一代旗舰模型,突破了单一蛋白质结构预测的局限,实现了蛋白质-配体共折叠的直接预测,为将其开发为新型AI分子对接工具、革新虚拟筛选流程提供了可能。然而,AF3在配体发现核心任务中的真实性能、适用边界及与传统分子对接技术的优劣对比,始终缺乏系统性的多维度验证。近期发表于bioRxiv的预印本论文,通过回顾性筛选、大规模实验验证、样本外泛化测试及前瞻性筛选四大核心任务,对AF3的配体发现能力进行了全面的评估,为其在药物研发中的定位提供了权威答案。
研究背景与核心科学问题
技术演进与行业期待
蛋白质结构预测技术的突破已深刻改变药物研发的范式。AlphaFold2构建的包含2亿余个蛋白质的结构数据库,已广泛应用于靶点验证、相互作用解析及机制研究。在此基础上,AF3通过扩散模型等技术创新,实现了从蛋白质序列和配体结构直接生成复合物结构的能力,无需传统对接的构象采样与力场优化步骤,被寄予厚望成为虚拟筛选的革命性工具。
关键科学疑问
尽管AF3展现出巨大潜力,但其在配体发现中的实际应用仍面临三大核心疑问:
- AF3在配体活性富集、结合构象复现等关键任务中的性能是否优于传统基于物理力学的分子对接工具?
- AF3的性能优势(若存在)是源于对蛋白质-配体相互作用的真实学习,还是数据集偏差或训练集记忆导致的虚假繁荣?
- AF3在真实药物发现场景中(如新型靶点、未见过的配体结构)能否稳定输出有效成果,其泛化能力与计算效率是否满足实际应用需求?
为解答这些问题,研究团队设计了覆盖43个药物靶点、超过10000个蛋白-配体复合物的多维度测评体系,以DOCK3作为传统对接的基准参照,全面解析AF3的性能边界。
核心研究结果与深度解析
一、回顾性测评:DUDE-Z数据集上的优势与偏差
1. 构象复现与活性富集表现
在经典的DUDE-Z基准测试中,AF3表现出显著的性能优势:
- 配体构象复现精度突出:86%(37/43)的靶点中,AF3能复现实验晶体中的配体构象(配体RMSD < 2Å),且结合口袋预测精度均满足口袋RMSD < 2Å的标准。
- 活性富集能力领先:在93%(40/43)的靶点上,AF3的ipTM(界面预测TM分数)和mPAE(平均预测对齐误差)评分在logAUC指标上优于DOCK3,平均提升幅度分别达27和31。
- 物理合理性验证:经PoseBusters筛选去除化学或结构不合理的构象后,AF3的富集优势依然保持,Pearson相关系数达0.91-0.99,证明其优势并非源于构象生成的 artifacts。
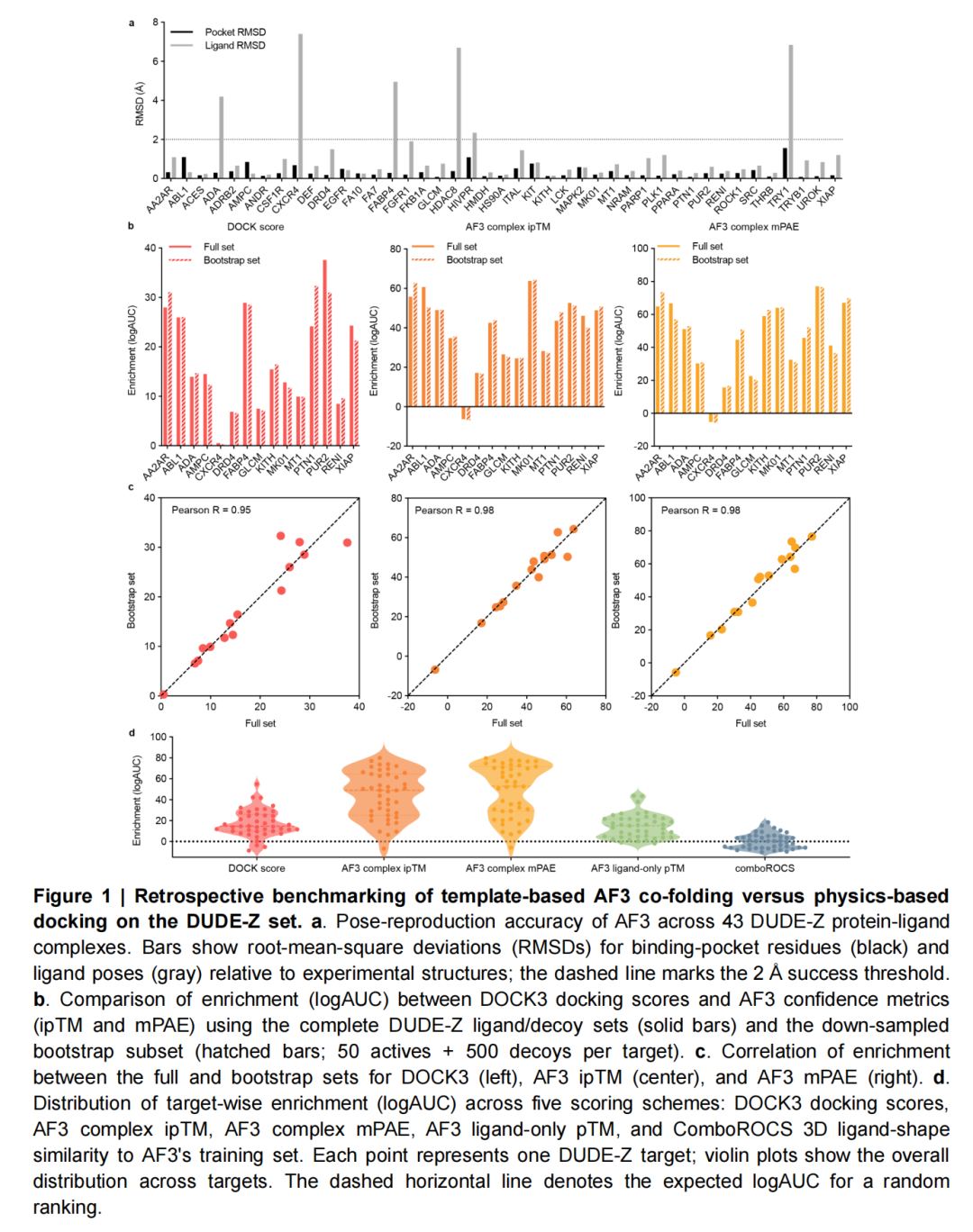
2. 数据集偏差的关键发现
深入分析揭示了AF3优势背后的隐藏因素:
- 配体-only偏差显著:仅输入配体SMILES序列(不提供蛋白质信息),AF3的pTM仍能在84%(36/43)的靶点上实现非随机富集,47%(20/43)的靶点表现优于或等同于DOCK3。
- 偏差来源:DUDE-Z等计算生成的诱饵集存在配体层面的固有偏差,AF3通过学习配体自身的化学特征(而非蛋白质-配体相互作用)即可区分活性分子与诱饵。
- 结论:DUDE-Z更适合作为AI模型的早期验证工具,而非真实虚拟筛选的可靠基准,其固有的数据集偏差会高估深度学习模型的真实性能。
二、大规模实验数据集验证:无偏差场景下的性能反转
为排除数据集偏差干扰,研究团队采用三个无偏差的大规模实验数据集(σ₂受体、D₄多巴胺受体、AmpC β-内酰胺酶,共2500余个测试分子)进行验证,结果呈现显著反转:
1. 整体富集能力:传统对接更胜一筹
- DOCK3在AUC(整体富集)指标上全面领先AF3:σ₂受体(77.28 vs 65.66/67.01)、D₄受体(70.80 vs 61.64/62.87)、AmpC酶(76.36 vs 63.11/62.29)。
- 配体-only偏差消失:实验数据集中,活性分子与非活性分子的配体-only pTM分数分布几乎完全重叠,证明实验数据集无配体层面固有偏差,更贴近真实筛选场景。
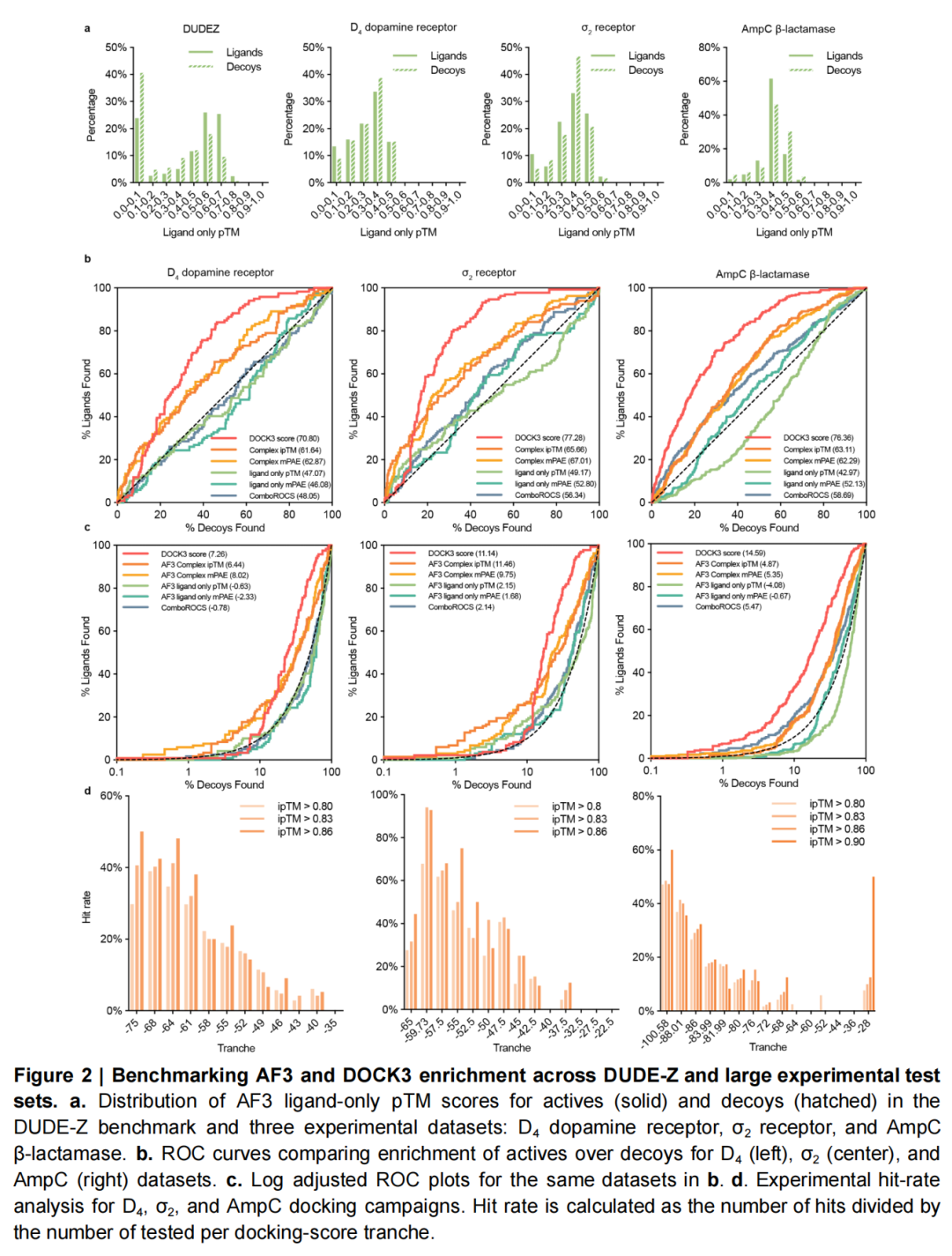
2. 早期富集优势与后处理筛选价值
AF3在特定场景下仍展现独特价值:
- 早期富集表现突出:在σ₂和D₄受体数据集上,AF3的logAUC和EF₁₀(Top 10%富集因子)指标有些优于DOCK3,意味着其能在筛选初期快速锁定高潜力分子。
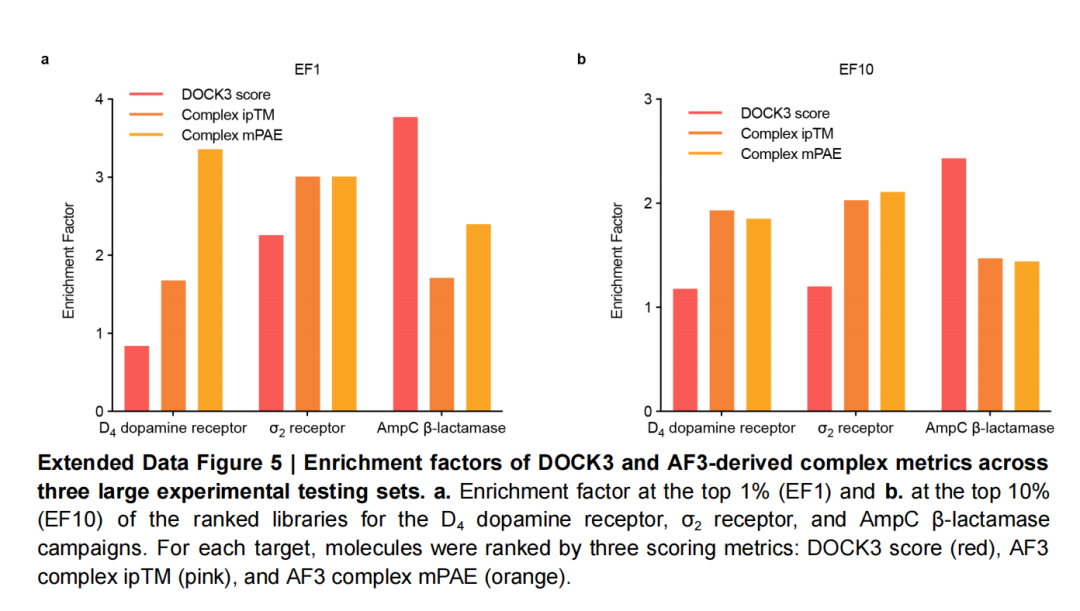
- 后处理筛选效果显著:将AF3的ipTM分数作为DOCK3对接后的二次筛选工具,可大幅提升命中效率:σ₂受体(34%→68%)、D₄受体(39%→66%)、AmpC酶(26%→47%),核心原因是ipTM能有效过滤对接产生的假阳性分子。
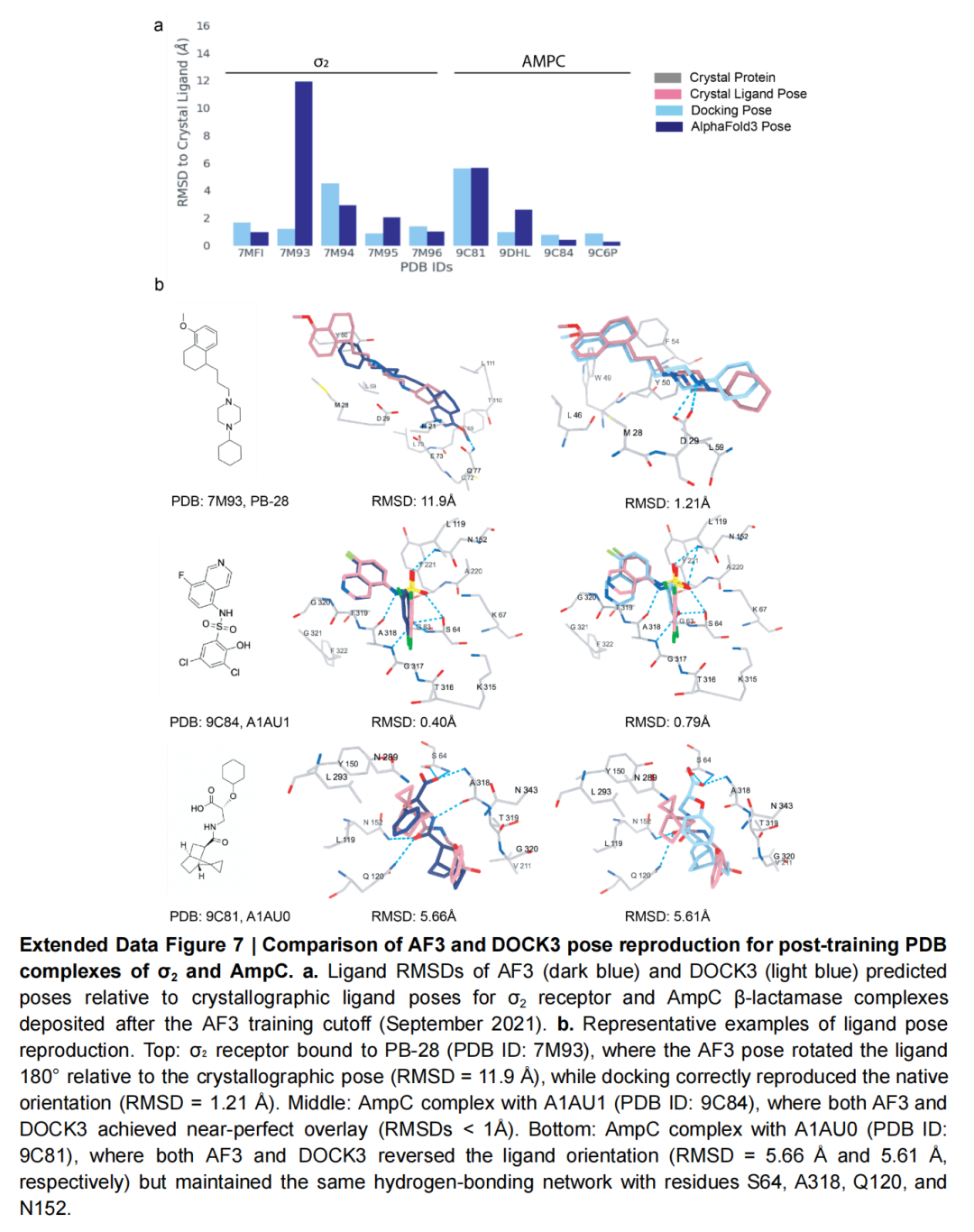
3. 构象复现的细节差异
在AF3训练 cutoff后新增的9个晶体结构中,DOCK3的构象复现成功率(6/9)高于AF3(4/9)。典型案例中,AF3对PB-28与σ₂受体复合物的预测出现180°旋转(RMSD=11.9Å),而DOCK3准确复现了与晶体结构一致的盐桥相互作用(RMSD=1.21Å),揭示AF3在关键相互作用识别上的不足。
三、样本外泛化测试:训练集依赖与记忆效应
1. 新颖配体与靶点的预测性能
对8559个AF3训练和验证 cutoff后(2023年1月-2024年12月)新增的蛋白-配体复合物测试发现:
- 泛化能力有限:对于化学新颖的配体(与训练集Tanimoto系数≤0.35),AF3同时准确预测口袋和配体构象的成功率仅40%,59%的案例表现为“口袋正确但配体定位错误”。
- 训练集相似性依赖显著:AF3的预测精度与配体-口袋3D相似性(ComboROCS×PS-Score)强相关,当相似性阈值≤0.35时,构象预测成功率仅19.1%,证明其性能高度依赖训练集相似性。
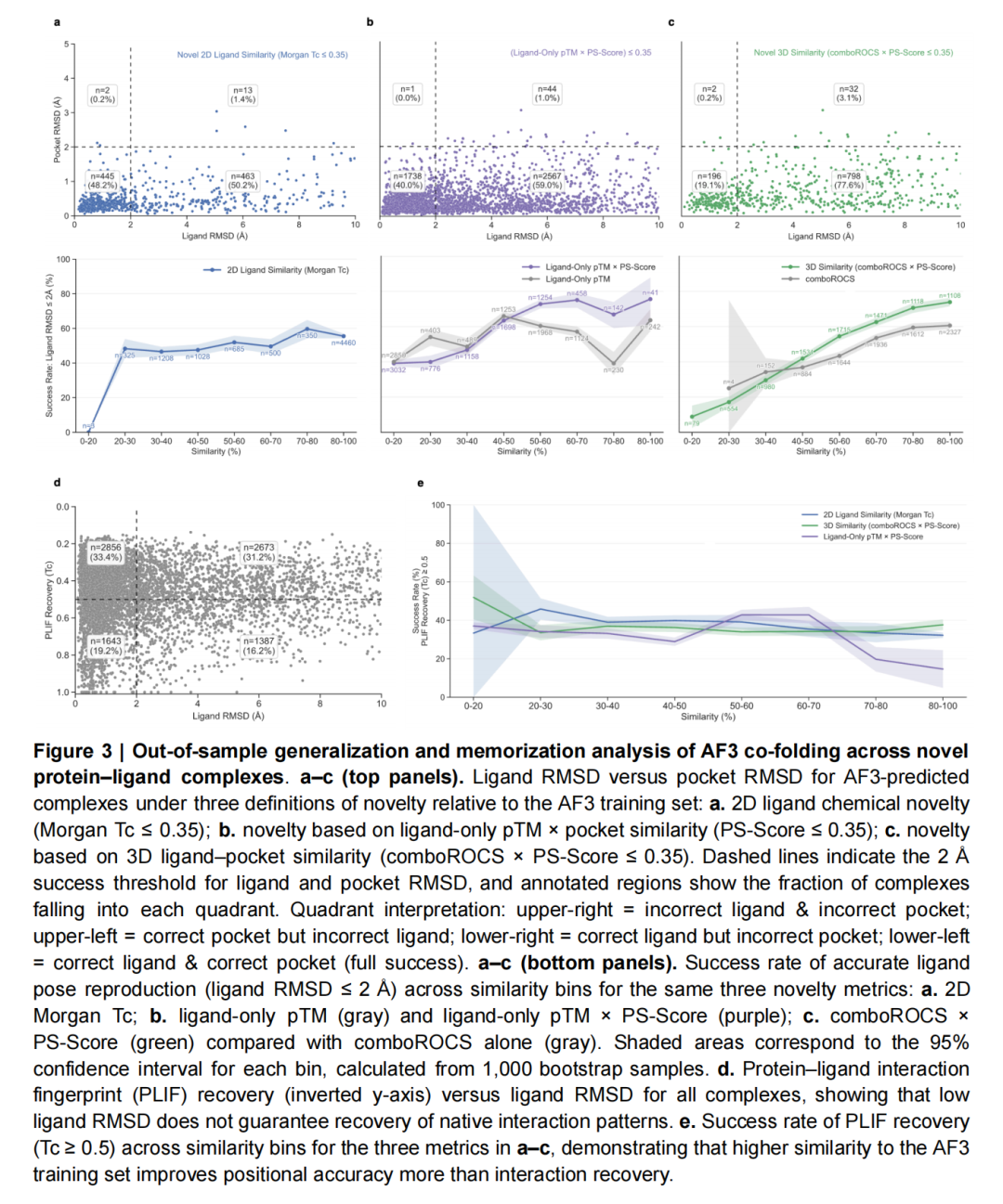
2. 分子识别机制的深层缺陷
进一步分析揭示了AF3的核心局限:
- 相互作用复现不足:即使配体构象RMSD < 2Å,仍有63%(2856/4499)的复合物未能复现至少50%的蛋白质-配体相互作用(如氢键、盐桥)。
- 记忆而非学习:AF3的成功更多源于对训练集中空间位置的记忆,而非对分子识别原理的掌握。Škrinjar, P等人的实验中,即使破坏结合口袋结构(如去除、倒置或填充苯丙氨酸残基),AF3仍能预测出与野生型相似的配体构象,进一步佐证其记忆特性。
四、前瞻性筛选:σ₂受体上的实战对决
1. 筛选结果与性能对比
在针对σ₂受体(AF3训练集中无该靶点)的前瞻性头对头筛选中,69万余个阳离子化合物的筛选结果呈现鲜明对比:
- 命中效率:DOCK3的命中率(25%,27/108)是AF3(13%,15/114)的近两倍。
- 排名靠前分子的活性:AF3的Top5命中分子Ki值范围为13-131 nM,与DOCK3的39-199 nM相当,其中AF3发现了亲和力达13 nM的强效结合剂,证明其在优质分子识别上的潜力。
- 化学多样性:DOCK3筛选出42013个独特Bemis-Murcko骨架,显著多于AF3的31479个,揭示AF3在化学空间探索上的局限性。
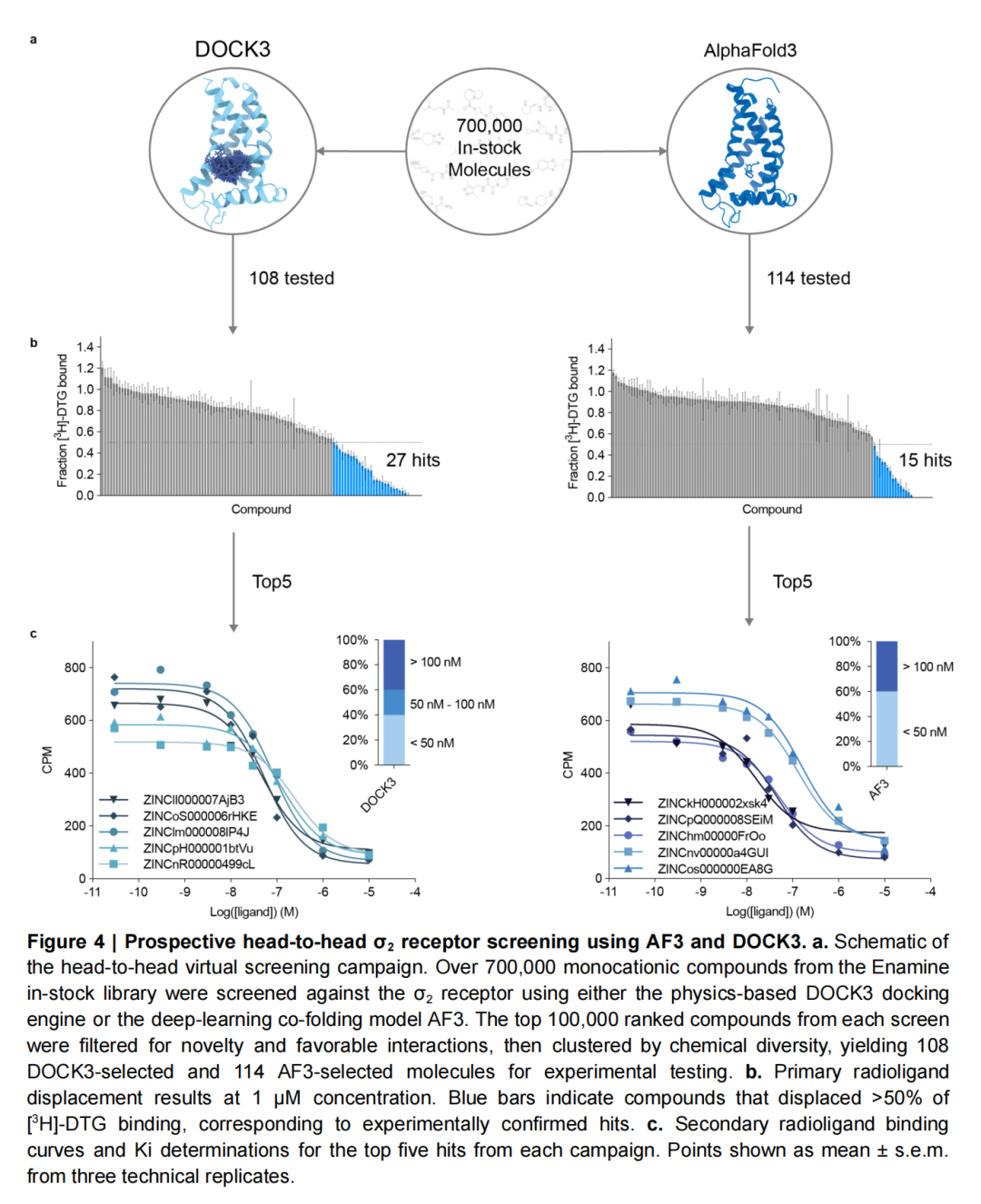
2. 计算效率的巨大差距
AF3的高算力需求成为其实际应用的关键障碍:
- 硬件与时间成本:AF3完成筛选需23000小时A100 GPU运算,而DOCK3仅需673小时CPU运算, 运行时间相差34倍,硬件成本相差200倍,综合效率差距达6700倍。
- 筛选偏差:AF3存在显著的阳离子偏好,506个测试化合物中,中性配体在Top1%、Top5%中均无分布,Top10%中仅占1%,限制了其对多样化化学空间的探索。
3. 辅助筛选的优化潜力
后续优化测试显示:
- 配体-only pTM可作为假阳性过滤器: ligand-only pTM > 0.5的分子命中率从20%降至13%,可用于剔除潜在假阳性。
- Boltz-2 重打分提升效率:Boltz-2(AF3的改进版本)的结合可能性评分和IC50预测模块可将整体命中率从19%分别提升至30%和44%,展现出混合策略的优化空间。
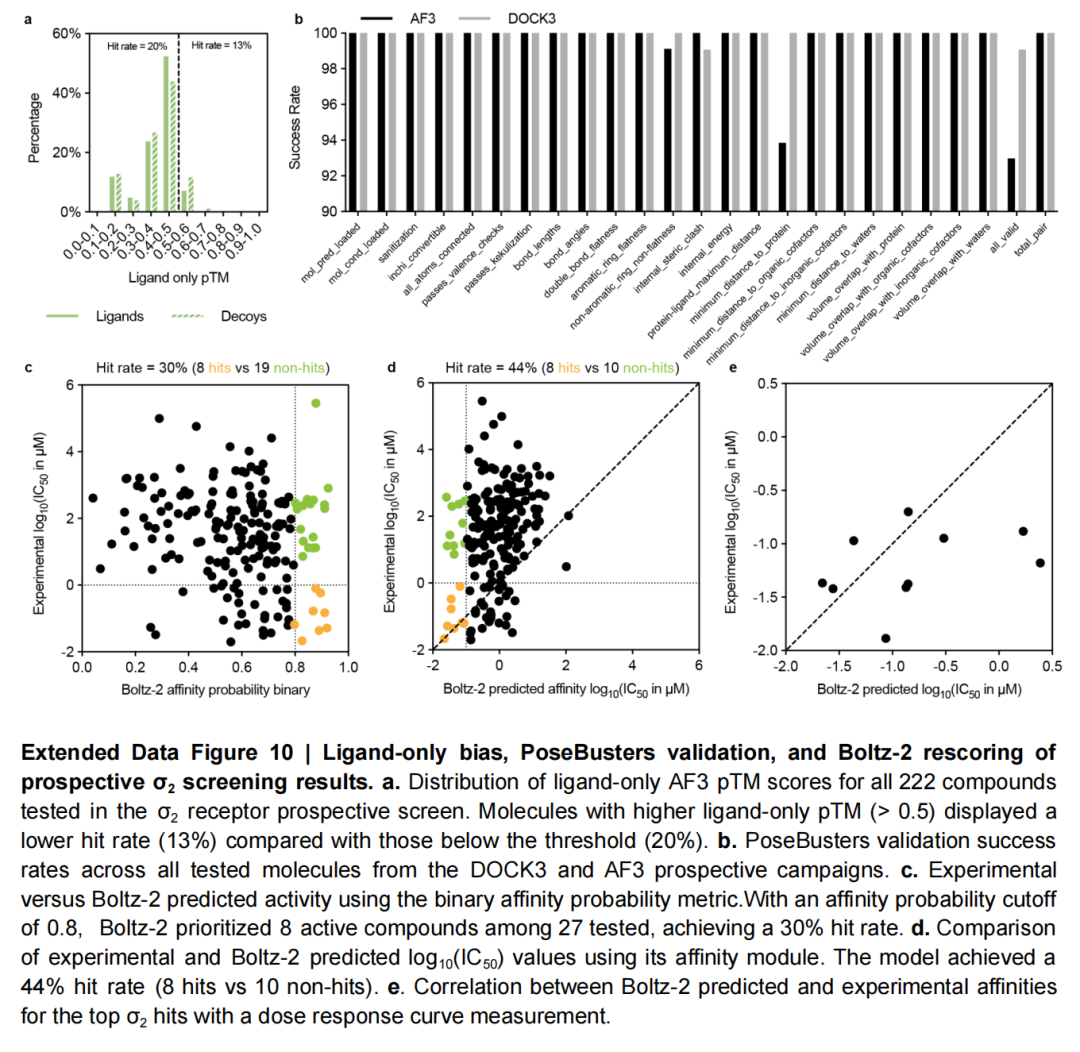
核心结论与行业启示
1. AF3的定位:互补工具而非替代者
研究通过多维度验证,明确了AF3在药物发现中的核心定位:
- 优势场景:早期富集(快速锁定高潜力分子)、对接后二次筛选(过滤假阳性)、无实验结构时的复合物生成(模板无关性)、操作便捷性(无需力场参数化与搜索空间调优)。
- 局限场景:超大规模虚拟筛选(算力限制)、新颖配体与靶点(泛化能力不足)、整体命中效率(低于传统对接)。
- 核心结论:AF3是传统分子对接互补工具,而非替代者,其价值在于融入混合筛选 workflow,而非单独作为筛选引擎。
2. 深度学习配体发现的未来方向
基于研究结果,未来深度学习共折叠模型的发展需聚焦三大方向:
- 训练数据多样化:扩充与现有PDB结构差异大的蛋白-配体复合物,减少训练集依赖。AISB Network的联邦学习与OpenBind计划(五年生成50万新结构)是重要探索,Pearl模型已通过合成数据训练实现性能提升。
- 混合筛选策略:采用 传统对接+AI 重打分 的混合模式,如DOCK3处理亿级化合物库,AF3或Boltz-2对Top1-5%分子重排序,兼顾规模与精度。
- 模型架构革新:从 空间位置记忆 转向 分子识别原理学习,提升对氢键、盐桥等关键相互作用的理解,减少对训练集相似性的依赖。
3. 基准测试体系的重要升级
研究还构建了动态更新的基准测试框架,通过ComboROCS(配体3D相似性)和APoc(口袋相似性)量化新颖性,相关脚本已开源(https://github.com/lyulab/benchmarking-af3)。该框架缓解了深度学习模型评估中 训练集与测试集边界模糊 的核心问题,为后续模型迭代提供了可靠的评估标准。
文献信息
- 标题:AlphaFold3 for Structure-guided Ligand Discovery
- 预印本平台:bioRxiv
- DOI:10.64898/2025.12.04.692352
- 核心团队:洛克菲勒大学、耶鲁大学、得克萨斯大学西南医学中心联合研究
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号