ICCV 2025 | 北大王选所推出AnyPortal:像素级操控视频背景,前景细节100%保留!

ICCV 2025 | 北大王选所推出AnyPortal:像素级操控视频背景,前景细节100%保留!

AI生成未来
发布于 2025-11-17 15:23:09
发布于 2025-11-17 15:23:09
解读:AI生成未来

文章链接:https://arxiv.org/pdf/2509.07472 主页:https://gaowenshuo.github.io/AnyPortal/ Git链接:https://github.com/gaowenshuo/AnyPortalCode
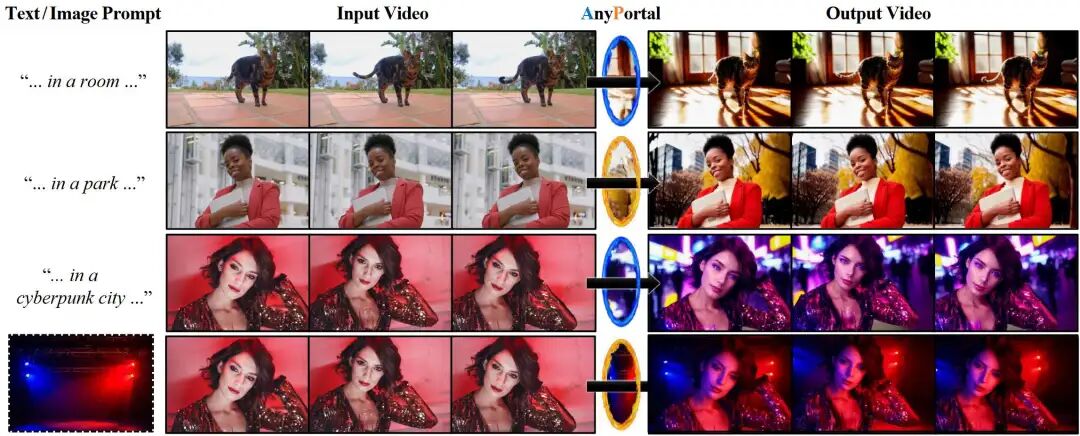
图 1.ANYPORTAL,这是一个用于高一致性视频背景替换和前景重新照明的免训练框架。给定输入的前景视频和背景的文本或图像提示,本方法在和谐的照明下生成具有目标背景的视频,同时保持前景视频细节和内在属性
图 1.ANYPORTAL,这是一个用于高一致性视频背景替换和前景重新照明的免训练框架。给定输入的前景视频和背景的文本或图像提示,本方法在和谐的光照下生成具有目标背景的视频,同时保持前景视频细节和内在属性
亮点直击
- AnyPortal,一个高效且无需训练的视频背景替换框架。
- 设计了一个模块化流程,该流程集成了最新的预训练图像和视频扩散模型,以结合其优势生成逼真且连贯的视频。
- 提出了一种新颖的精炼投影算法(Refinement Projection Algorithm),该算法能够在紧凑的隐空间中实现像素级的细节操控,从而确保精确的前景保留。
总结速览


解决的问题
- 核心挑战:现有视频生成技术难以实现精细化的细节控制,无法精确对齐用户意图,特别是在视频背景替换任务中。
- 具体问题:
- 前景一致性:替换背景时,难以保持前景主体(如人物、物体)的像素级细节和外观一致性,容易出现非预期的改变。
- 时序照明一致性:难以在视频序列中保持照明效果的时序连贯性。
- 资源限制:专业绿幕流程成本高昂;基于数据驱动的视频方法缺乏高质量的配对视频数据集,且模型训练需要巨大的计算资源。
提出的方案
- 方案名称:AnyPortal —— 一个零样本(zero-shot)、无需训练(training-free) 的视频背景替换框架。
- 核心思路:协同利用预训练的图像扩散模型和视频扩散模型的各自先验知识,无需额外训练。
- 关键创新:提出了 Refinement Projection Algorithm (RPA, 精炼投影算法) ,该算法能在隐空间中进行像素级的细节操控,确保前景细节的高度一致性。
应用的技术
- 预训练模型利用:
- 图像扩散模型 (IC-Light) :用于实现高质量的背景生成和照明 harmonization(协调),使前景与背景的光照融为一体。
- 视频扩散模型:用于提供强大的时序先验,保证生成视频的时序连贯性和动态真实性。
- Refinement Projection Algorithm (RPA) :
- 一种专门为视频模型设计的算法,通过在隐空间中计算一个投影方向,来同时保证输入前景细节的高一致性和生成背景的高质量。
- 克服了直接将图像控制方法(如DDIM反转)应用于视频模型时存在的计算成本高、隐空间压缩导致操控质量下降等问题。
- 模块化流程:
- 首先生成一个由IC-Light进行了照明协调的粗粒度视频。
- 然后利用预训练的视频扩散模型增强其时序一致性。
- 在整个过程中,RPA算法确保对前景的像素级精确控制。
达到的效果
- 高质量输出:能够生成具有自然光照和高度时序一致性的高质量视频,实现“虚拟传送”效果。
- 精确控制:实现了对前景细节的像素级保护,避免了不必要的外观改变。
- 高效实用:
- 无需训练:完全基于预训练模型,避免了收集配对数据和训练模型的开销。
- 计算高效:可在单块24GB消费级GPU上高效运行,降低了使用门槛。
- 灵活通用:支持通过文本描述或背景图片来指定目标环境。其模块化设计易于集成最新的图像/视频生成模型,具有良好的可扩展性。
方法
零样本视频背景替换
如下图2所示,本文的框架分为三个阶段:(1) 背景生成;(2) 光照协调;(3) 一致性增强。输入是一个前景视频 和一个描述背景的提示词 。
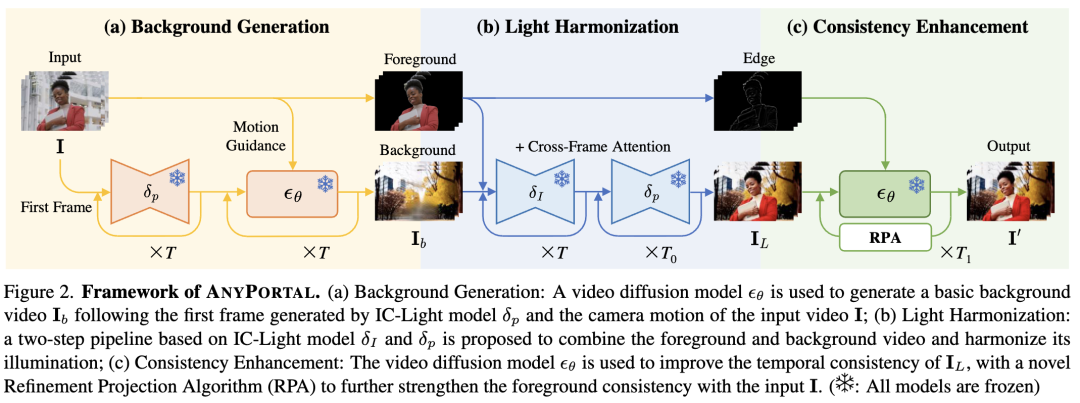
在第一阶段,借助预训练的视频扩散模型 生成一个背景视频 ,该视频与 的相机运动相匹配。第二阶段基于我们提出的两步IC-Light流程,在新的背景中协调前景物体的光照,以产生一个粗粒度视频 。第三阶段引入了一种新颖的精炼投影算法(RPA),该算法解决了帧间的不一致性问题,并细化前景细节以匹配 的细节,最终生成视频 。
本文的方法是零样本且模块化的,完全利用了预训练扩散模型 和 的强大生成能力,无需任何训练或推理时优化。这使得我们能够在单块24GB内存的GPU上生成令人印象深刻的视频。此外,本文的方法充分受益于快速发展的视觉扩散研究,因为它可以在最新的预训练模型上一旦可用就进行实施,以提升性能。
背景生成
为了将前景与背景无缝集成,第一阶段生成一个基本的背景视频 ,该视频与背景提示词 相对应,并且关键的是,与 的相机运动相匹配。遵循Diffusion-As-Shader (DAS),这是一个基于ControlNet的视频生成框架,它用第一帧和引导视频的运动(追踪的3D点)来指导视频扩散模型。具体来说, 作为引导视频。为了获得第一帧,我们将IC-Light应用于 的第一帧 ,得到 。将DAS应用于后端视频扩散模型,基于 和 生成 。如下图3所示, 具有与输入 相同的相机运动,但其前景物体可能与 显著不同,不能直接用作本文的视频背景替换结果。最后,使用ProPainter移除前景物体,获得基本背景视频 。

光照协调
首先使用图像分割模型BiRefNet从 中提取前景物体 。现在,对于 的每一帧,我们有一个背景提示词 ,一个背景图像 和一个前景图像 。我们尝试了应用图像引导和文本引导的IC-Light来组合它们。然而,两者都没有产生合理的结果。如下图4(a)(b)所示,图像引导的结果 光照协调不足(缺少背光效果),而文本引导的结果 具有强烈的光照效果,但由于缺乏图像引导,存在时间不一致和背景相机运动不匹配的问题。

为了在 和 的光照效果之间取得平衡,同时利用来自 的时间一致视觉引导,本文提出了一个两步协调流程,如图2(b)所示。第一步,获得图像引导结果 。第二步,采用SDEdit的思想,通过使用 对其去噪来细化 的光照。具体来说,我们使用DDPM前向过程向 添加 步()的噪声,然后在 和 的条件下使用 对其去噪 步。如图4(c)所示,前景光照得到了很好的增强。然而,这种逐帧处理无法确保风格一致性(例如,海滩外观不一致以及两帧中棕榈叶位置的变化)。为了缓解这个问题,我们对 和 采用了跨帧注意力。将 的自注意力层替换为跨帧注意力层,其中所有帧从第一帧聚合键和值特征,而不是从它们自身聚合。结果,风格一致性得到加强,如图4(d)所示。请注意,我们的流程允许通过 来调整光照效果,即较大的 会产生具有强烈光暗效果的结果。
一致性增强
前面生成的视频 仍然存在两个问题:1) 即使引入了跨帧注意力以实现全局风格一致性,帧间仍然存在像素级的抖动。2) 的前景细节与 的前景细节不完全匹配。因此,旨在利用视频扩散模型 的能力来改善帧间时间连续性和前景细节一致性。前面类似,高层思路是使用SDEdit,通过使用 对 进行 步()的去噪来细化其时间一致性。还对 应用了基于边缘的ControlNet以保留 的主要结构,如图2(c)所示。然而,ControlNet仅提供粗略的结构引导,无法保持图5(b)中的身份信息。因此,我们提出了一种精炼投影算法(RPA)来在像素级强制前景细节的一致性。
关键思想是在SDEdit去噪过程中,将前景的高频细节(因为帧的高频信息通常描述其边缘和纹理,而低频信息表征其颜色和光照)从 转移到 。如前面分析,紧凑的3D隐空间阻碍了在像素域的直接高频细化。因此,我们首先将隐空间表示解码回像素域以应用细化,然后将细化后的视频编码回隐空间。为了避免3D VAE固有重建误差导致的质量下降,RPA计算一个零误差投影方向来指导编码。具体来说,RPA包含两个部分:前景细化和带有RPA的DDIM去噪。
前景细化。 为避免噪声干扰,遵循常见做法在公式(2)中的无噪声隐空间表示 上操作。首先将 解码回视频 。随后,将 和 分解为它们的低频(LF)和高频(HF)分量。在细化视频 的前景区域,我们结合 的LF分量和 的HF分量。 的背景区域设置为修复后的 (使用ProPainter移除了前景物体)。细化细节总结在算法1中。
带有RPA的DDIM去噪。 希望将细化后的视频 重新编码回隐空间作为 ,以在DDIM去噪过程中替换原始的 。理想情况下,除了细化后的HF细节, 应与 相比保持不变。然而,有两个地方可能引入误差。首先,编码和解码不是严格可逆的;其次,VAE的随机性导致不可避免的差异。实际上,VAE输出隐空间表示的均值和标准差:,并且 通过重参数化采样:,其中 ,这引入了随机性。随着DDIM去噪迭代,这种随机性和误差会累积,导致如下图5(c)所示的模糊背景。

RPA使用一个确定性的 来代替随机的 ,该 经过计算以确保对 的完美重建。具体来说,假设一个完美重建 。注意 和 都是可获得的,因此可以确定性地计算 。然后,对于细化后的视频 ,获得 ,最终的投影解为 。在算法2中总结了提出的RPA。关键见解是,如果不应用细化(即 ),此投影将使 完全等于 。这种对齐属性确保了结果视频的背景区域几乎保持不变,仅细化了前景细节,这也由图5(d)验证。
实验
实现细节。使用 CogVideoX 作为视频扩散模型 εθ,并使用 IC-Light作为图像背景替换模型 δp 和 δI。我们设定 T = 20,并将强光照效果和弱光照效果的 (T₀, T₁) 分别设为 (0.7T, 0.7T) 和 (0.4T, 0.4T),以满足不同场景的需求。所有实验均在单个 NVIDIA 4090 GPU 上进行,并为 CogVideoX 启用了 CPU 卸载。测试视频统一调整为 480×720 分辨率,并裁剪为 49 帧以符合 CogVideoX 的规格要求。每个视频的推理时间约为 12 分钟(若关闭 CPU 卸载且 GPU 内存更大,还可进一步加速)。
基线方法。由于目前极少有其他工作完全针对我们所研究的零样本视频背景替换任务,我们选择了以下最相关的基线方法进行比较:
- IC-Light:一种先进的图像背景替换模型。逐帧应用该模型。
- TokenFlow:一种先进的零样本文本引导视频编辑模型。
- Diffusion-As-Shader (DAS):一种多功能视频生成控制模型。使用其运动迁移功能,该功能通过将输入视频的运动迁移到所提供的第一帧图像来生成新视频。此处,我们使用 IC-Light 生成第一帧。 请注意,以上所有基线方法均为基于扩散的零样本编辑方法,以确保公平比较。
评估。构建了一个包含 30 个样本和提示词的测试集用于评估,并采用以下指标:
- Fram-Acc:基于 CLIP 的余弦相似度在与目标提示词相比高于源提示词的视频帧中所占的比例,用于衡量背景是否成功被编辑。
- Tem-Con:基于 CLIP 的连续帧间余弦相似度,用于衡量时间一致性。
- ID-Psrv:生成视频前景细节的保持程度,通过生成视频与输入视频中人脸(如适用)的身份损失来衡量。
- Mtn-Psrv:生成视频运动的保持程度,通过生成视频与输入视频之间的点运动跟踪相似度来衡量。使用 SpatialTracker进行点跟踪。
对于用户研究,邀请了 24 位参与者。参与者被要求基于以下四个标准从四种方法中选出最佳结果:
- User-Pmt:结果与提示词的匹配程度。
- User-Tem:结果的时间一致性。
- User-Psrv:前景细节和运动保持的完整程度。
- User-Lgt:前景重新打光的质量。
与先进方法的比较
下图6对所提方法与其他基线方法进行了可视化比较。IC-Light本质上是一种图像扩散模型,因此天生存在时间不一致性问题。此外,它倾向于对主体进行过度重新打光,甚至改变固有属性(如衣服和头巾的颜色)。TokenFlow表现出有限的编辑能力和不足的前景细节控制能力,而 DAS则无法保持对前景运动动态和固有外观属性的控制。相比之下,本文的方法在实现高质量背景替换和前景重新打光的同时,确保了时间一致性和前景细节一致性。

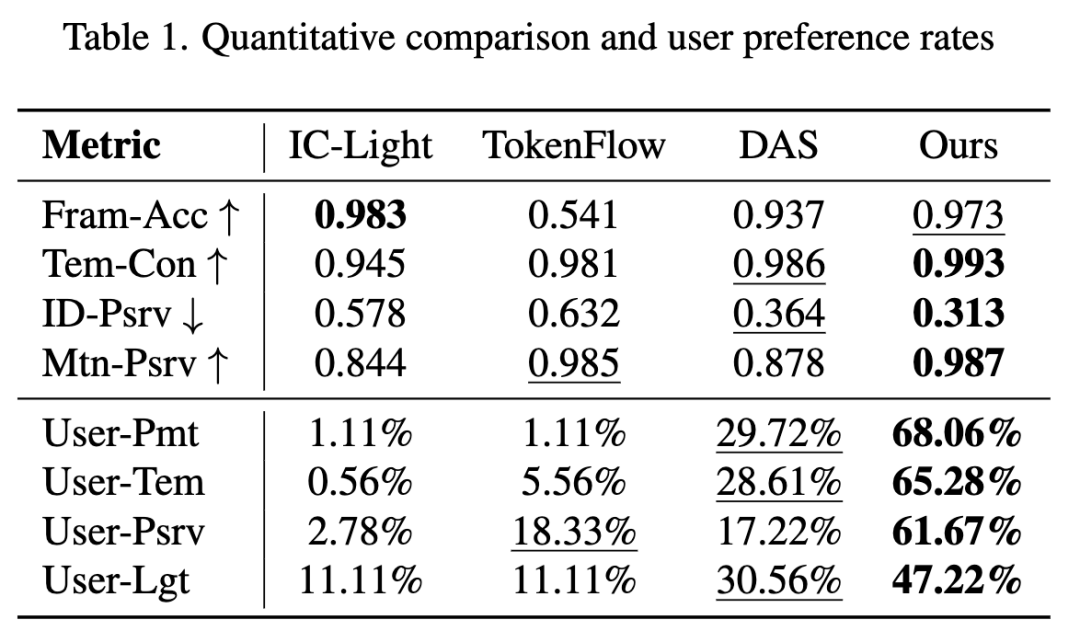
下表1给出了定量评估结果。IC-Light 实现了最佳的 Fram-Acc,这是因为它专门针对背景替换任务进行了训练,无需考虑时间一致性。本文的方法取得了第二佳的 Fram-Acc,并在所有其他指标和用户偏好上均获得最佳结果,在单帧重新打光质量和整体视频流畅性之间取得了良好平衡。
消融研究
为验证不同模块对整体性能的贡献,我们系统地禁用了框架中的特定模块。结果报告于上图4、5,下图7、8及下表2。


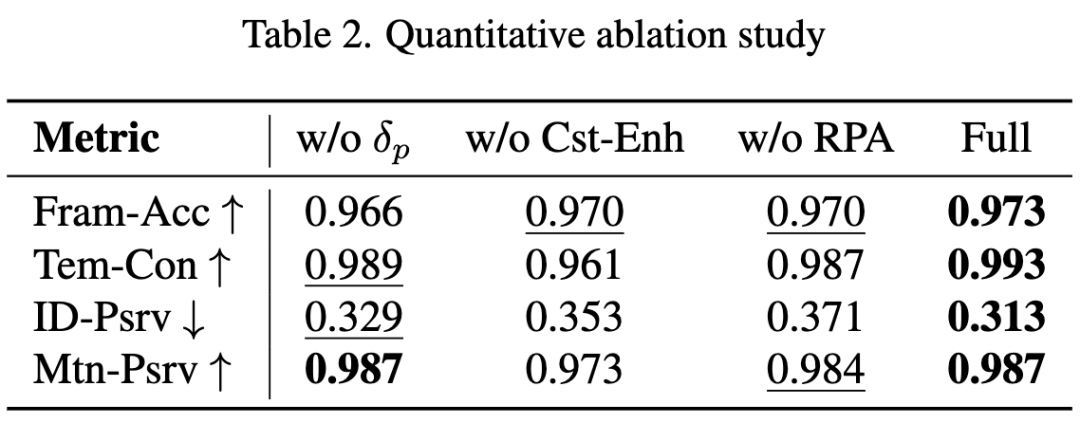
- 两步协调。在图像协调阶段,采用IC-Light的δ和δ为视频提供改进的照明,使前景能更好地融入背景。如表2所示,朴素的一步协调(即不使用δ或)会导致视频模型生成光照不够自然的前景。随着增大,δ在实现更自然前景光照中的作用逐渐增强,如图7所示。
- 跨帧注意力。图4研究了跨帧注意力注入的效果。禁用跨帧注意力会导致生成结果中出现严重的帧间外观差异(例如海滩上突然出现脚印),降低时间一致性。
- 时间先验。一致性增强(Cst-Enh)阶段优化了第二阶段生成的视频的前景细节和整体时间一致性。如表2所示,不使用Cst-Enh时,Tem-Con显著下降。如图8所示,的背景中岩石存在不一致问题。通过利用视频扩散模型的强先验,该问题在第三阶段结果中得到有效解决。
- RPA。RPA对隐变量进行高频细节细化。不使用RPA时,身份差异会增大,如表2和图5(b)所示。通过解码和编码进行朴素的高频细节细化会导致背景模糊,如图5(c)所示。我们设计的RPA提供了一种确定性采样方案,能很好地保留背景区域等未细化区域,如图5(d)所示。
更多结果
图像引导的视频背景替换。本文的方法可轻松适配图像提示。在第一阶段,使用δ和用户提供的背景场景图像生成第一帧,后续阶段则与文本提示完全相同。图像引导结果如下图1和图9所示。


与Light-A-Video的比较。在下图10中进一步提供了与同期工作Light-A-Video的视觉对比。两种方法均基于CogVideoX,生成质量相当。然而,Light-A-Video的CogVideoX实现仅能对现有背景进行重新打光,而本文的方法能生成新的背景内容。

局限性
尽管ANYPORTAL表现出良好的效果,但仍存在若干局限性(图11为一个典型示例):

(1)低质量输入(如低分辨率/模糊视频)会减少高频细节的迁移,导致结果模糊(例如图11中头发部分);(2)前景-背景边界不清晰会导致修复结果不匹配,并在主体周围产生扩大化的模糊区域;(3)快速运动会对扩散模型带来挑战,在左臂等部位引发伪影。
结论与展望
AnyPortal,一个用于视频背景替换与前景光照调整的零样本框架。该方法无需任务特定训练,即可实现高度时间一致性与细节保真度。具体而言,通过整合运动感知视频扩散模型以生成背景,扩展图像Relighting模型并引入跨帧注意力机制,同时提出细化投影算法(Refinement Projectation Algorithm)在隐空间中保持前景细节。实验表明,本方法在光照融合与时间一致性方面均优于现有方法。
未来的一个可能方向是探索将大型视频扩散模型中的时序先验知识拓展至更多视频编辑任务中,例如颜色调整、风格化、人脸属性编辑与视频修复等。
参考文献
[1] ANYPORTAL: Zero-Shot Consistent Video Background Replacement
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、在看、转发,让更多人受益。同时,欢迎给个星标⭐,以便第一时间收到我的最新推送。每一个互动都是对我最大的鼓励。让我们携手并进,共同探索未知,见证一个充满希望和伟大的未来!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号