LLM 系列(九):RAG 番外篇-从文档到向量

LLM 系列(九):RAG 番外篇-从文档到向量

由于出差,断更一周,还请各位读者海涵~
在上一篇 LLM 系列(八):RAG 篇中,我大概阐述了 RAG 的基本流程和原理,本篇则是进一步针对 RAG 中的前期过程(文本切分和 Embedding)进行拆解,期望是能够通过此篇能够让各位读者在 RAG 落地上具备更高的参考价值。
这趟 RAG 的构建之旅,其起点并非高深的算法,而是看似平淡无奇的数据工程——如何将散落在企业各个角落的原始文档,一步步转化为大模型可以理解和利用的结构化知识。本文作为 RAG 知识构建的番外篇,将细致入微地描绘这一转化过程的全貌:从一份原始的 PDF 或网页,到最终成为向量数据库中一个可被精准检索的 知识向量。这条路径的质量,直接决定了整个 RAG 系统的成败。
一、文档是如何变成知识的?
RAG 系统中的外部大脑:文档的角色
在 RAG 架构中,文档扮演着“外部大脑”或“权威知识库”的角色。它的核心使命是为 LLM 提供一个事实的基石(grounding),当模型需要回答问题时,它不再仅仅依赖于自己内部模糊的、可能过时的记忆,而是可以查阅这些外部文档来获取最相关、最准确的信息。
这个过程具体表现为:系统将从文档中检索到的 事实 片段,连同用户的问题一起,打包成一个更丰富的提示(prompt)喂给 LLM。这种做法带来了两个立竿见影的好处:首先,它极大地减少了模型幻觉的概率;其次,它让模型的回答变得可以溯源,用户可以清楚地看到答案是基于哪些文档生成的,这对于需要高可信度的企业应用场景至关重要。
知识从哪里来?五花八门的文档来源
企业知识的形态是复杂多样的,它们散落在不同的系统和媒介中。一个强大的 RAG 系统必须具备从这些异构源头汲取知识的能力。常见的文档来源包括:
- • 非结构化数据:这是最常见的知识载体,如 PDF 报告、Word 文档(.docx)、技术手册(Markdown)、纯文本文档(.txt)以及海量的网页(HTML)。
- • 半结构化数据:这类数据具有一定的组织形式,例如 CSV 表格、JSON 文件、Notion 页面、Confluence 知识库等。
- • 结构化数据:直接来源于业务系统,如从 Mysql 等关系型数据库中导出的数据,或是通过 API 接口获取的实时信息。
为了应对这种复杂性,像 LangChain 这样的开发框架提供了丰富的 文档加载器(Document Loaders) 。这些加载器就像是特制的 数据插头 ,每一种都针对特定的数据源,能够高效地读取内容并将其转换为统一的格式。LangChain 官方支持的加载器列表非常庞大,从常见的 PDF、网页,到 Slack 聊天记录、Figma 设计文件,甚至 Bilibili 视频字幕,几乎无所不包。
这种广泛的覆盖揭示了一个深刻的现实:对于 RAG 应用开发者而言,首要的挑战往往不是算法,而是数据集成。所谓的 “文档”,其实是对一个混乱、异构数据世界的便捷抽象。一个 RAG 项目的成败,很大程度上取决于能否打通连接到企业内部各个“知识孤岛”的数据管道。
核心目标:从“原始数据”到“可检索的知识单元”
数据加载进来后,我们便开启了整个流程的核心目标:将这些大小不一、格式混乱的原始数据,转化为一系列干净、语义连贯、尺寸统一的文本片段。这些片段在技术上被称为 “块”(Chunks) 或 “知识单元”(Knowledge Units)。
可以把这个过程想象成准备烹饪的食材。原始文档就像是刚从地里挖出来的土豆,上面还带着泥土,大小也不一。我们需要先把它洗干净(清洗),然后切成大小均匀的块(切分),这样才能方便后续的烹饪(向量化和检索)。这个预处理步骤是整个 RAG 流程的基石,因为这些“知识单元”的质量,将直接决定后续检索的精准度和最终生成答案的质量。
预处理:给知识“梳洗打扮”
将原始文档转化为高质量的知识单元,是 RAG 系统工程中最具挑战也最关键的一步。这个过程包含两个核心环节:拆分(Chunking)与清洗(Cleaning)。
核心挑战:如何切分得“恰到好处”?
拆分(Chunking)面临一个经典的困境:知识单元既要足够小,以适应 Embedding 模型和 LLM 的上下文窗口限制;又要足够大,以保留完整的语义信息。
- • 块太小:如果一个块只有半句话,它就失去了上下文,语义不完整。模型很难理解它的真实含义。
- • 块太大:如果一个块包含多个不相关的主题,它内部就会充满“噪声”,稀释了核心信息,导致在检索时虽然被匹配到,但大部分内容对回答问题并无帮助,反而会干扰 LLM 的判断。
经验法则是:如果一段文本在没有上下文的情况下,人类能够理解其含义,那么语言模型大概率也能理解。这为我们追求“恰到好处”的切分提供了方向。
拆分策略大比拼
为了实现理想的切分,社区发展出了多种策略,从简单粗暴到智能精细,各有其适用场景。
- • Level 1: 固定尺寸拆分 (Fixed-Size Chunking) 这是最简单直接的方法,按照固定的字符数或 Token 数来切割文本。通常会设置两个关键参数:
chunk_size(块大小)和chunk_overlap(块重叠);重叠部分的存在是为了在两个连续的块之间保留一定的上下文,防止信息在边界处被完全切断。然而,这种“一刀切”的方式非常“天真”,它完全无视文本的自然结构,很可能在句子中间、一个完整的概念描述到一半时就强行分割,破坏语义完整性。 - • Level 2: 递归字符拆分 (Recursive Character Splitting) 这是目前最常用、也是最推荐的起点策略。它的高明之处在于,它试图尽可能地尊重文本的自然结构。其工作原理是,提供一个按优先级排序的分隔符列表,比如
["\n\n", "\n", " ", ""]。它会首先尝试用最高优先级的“换段符” (\n\n) 来分割文本。如果分割后的块仍然大于设定的chunk_size,它就会在这些大块上,用次一级优先级的“换行符” (\n) 继续分割。这个过程会递归地进行下去,直到所有块都符合尺寸要求。这样做的效果是,它会优先保持段落的完整,其次是句子的完整,最后才是单词的完整。 - • Level 3: 按文档结构拆分 (Document-Specific Splitting) 对于那些自身就带有明确结构的文件格式,如 Markdown 和 HTML,我们可以利用其内在结构来进行更智能的分割。例如,对于 Markdown 文件,我们可以将每个标题(如
#一级标题,##二级标题)作为天然的分割点。LangChain 框架中的MarkdownHeaderTextSplitter就是为此而生,它可以确保每个标题下的所有内容形成一个独立的、上下文完整的知识单元。 - • Level 4 & 5: 语义与智能体拆分 (Semantic and Agentic Splitting) 这代表了更前沿的探索方向。语义拆分不再依赖于字符或结构,而是通过计算句子之间 embedding 的相似度来决定分割点。当它检测到文本的语义主题发生了显著变化时,就在此处进行分割,从而生成语义上高度内聚的块。而智能体拆分则更进一步,它让一个 LLM Agent 来扮演“文档分析师”的角色,由模型自己来判断如何分割才是最合理的,这模拟了人类在处理长文档时的推理过程。
清洗的艺术:去除噪音,保留精华
清洗的目标是去除文档中的无关信息(如广告、导航栏、脚本代码),同时保留有价值的结构和内容。
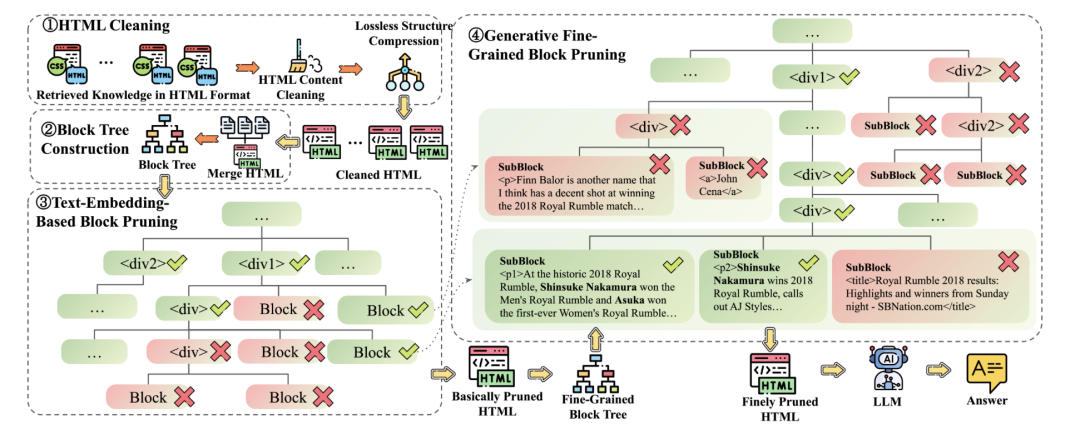
- • HTML 清洗:提取正文 vs. 保留结构 处理网页内容时存在两种哲学。传统方法是使用 BeautifulSoup 或 Readability.js 这样的库,将 HTML 中的所有标签、脚本和样式全部剥离,只提取出“纯文本”正文。这种方法简单有效,但代价是丢失了所有版式结构信息。而前沿的研究,如 HtmlRAG,则提出了一个相反的观点:粗暴地剥离标签会导致严重的信息损失,例如,表格、列表、代码块会退化成一堆难以理解的混乱文本。HtmlRAG 的精细化处理流程包括: 这种精细化处理的背后,是一个至关重要的因果关系:糟糕的解析是下游幻觉的直接源头。如果解析过程错误地将一个表格的行列关系打乱,或者将页眉页脚的内容混入正文,那么产出的知识单元本身就是错误的“事实”。当 LLM 被喂给这些错误信息作为权威来源时,它必然会生成一个混乱、不准确甚至完全错误的答案。因此,高质量的解析是 RAG 系统对抗幻觉的第一道,也是最关键的一道防线。
WX20250803-132126@2x
- • 清洗:只移除真正无用的标签(如
<script>,<style>)和冗余属性。 - • 压缩:合并多余的嵌套结构,如将
<div><div><p>text</p></div></div>简化为<p>text</p>。 - • 剪枝:基于内容与查询的相关性,智能地移除整个 HTML 树中的无关分支。
• Markdown 清洗:重点在于保留其结构化元素。例如,一个 Markdown 表格应该被识别并作为一个整体来处理,而不是被拆散成零散的文本行,代码块和列表也应同理。

如何处理复杂元素?
现实世界的文档远不止纯文本。如何处理表格、代码和图片,是衡量一个 RAG 系统成熟度的重要标准。下表总结了处理这些复杂元素的一些最佳实践。
表1:复杂文档元素处理最佳实践
元素类型 | 推荐处理策略 | 关键考量 |
|---|---|---|
表格 | 1. 整体处理:避免将一个表格分割到多个知识单元中。2. 结构化转换:在向量化之前,将表格转换为更清晰的 Markdown、JSON 或 CSV 格式。3. 自然语言摘要:使用 LLM 生成一段描述表格内容的自然语言摘要。4. 专用模型处理:TableRAG 等前沿方法建议将表格数据存入可供 SQL 查询的数据库中,以支持更复杂的推理。 | 核心目标是保护表格的行列结构,这承载了其核心语义。简单的文本提取会彻底破坏这种结构。将其转换为结构化格式是目前最稳妥的检索方案。 |
代码 | 1. 代码感知分割:基于函数、类或逻辑块进行分割,而非任意字符数。LangChain 为多种编程语言提供了专用的分割器。2. 使用专用 Embedding 模型:选择在代码上训练过的模型,能更好地捕捉代码的句法和语义。 | 代码具有严格的语法结构,必须得到尊重。在函数或语句中间分割会使其失去意义。代码块的上下文通常由其作用域(函数或类)定义。 |
图片/图表 | 1. 图像描述/摘要:使用多模态 LLM(如 GPT-4V, LLaVA)为图片或图表生成详细的文本描述,然后将这段描述文本进行向量化 。2. 多模态 Embedding:使用像 CLIP 这样的模型,它可以将图片和文本嵌入到同一个向量空间中,从而实现直接的“以文搜图”或“以图搜图” 。 | 这是多模态 RAG 的核心领域。选择生成描述还是使用多模态 Embedding 取决于具体应用。生成描述更灵活,因为产出的是标准文本,但可能丢失图像的细微差别;多模态 Embedding 更直接,但要求整个技术栈都能处理图像向量。 |
向量化:文字如何拥有“数学灵魂”
经过预处理,我们得到了一批高质量的知识单元。下一步,就是将这些文本转化为机器能够理解和比较的数学形式——这个过程就是向量化(Vectorization),也常被称为嵌入(Embedding)。
什么是 Embedding?
向量化,就是利用一个深度学习模型(即 Embedding 模型),将一段文本转换成一个由数百甚至数千个数字组成的列表,这个列表就是向量(Vector)。 打个比喻:Embedding 就像是为每一段文字分配了一个独特的“语义 GPS 坐标”。在由这些坐标构成的高维空间中,意思相近的文本,它们的坐标点在空间中的距离也会非常接近。例如,“苹果公司的最新财报”和“iPhone 制造商的季度收入”这两段话,它们的向量就会靠得很近。正是这种“语义相近,空间相邻”的特性,使得基于向量的**语义搜索 **成为可能,这也是 RAG 系统能够从海量知识中快速找到最相关信息的核心能力。
向量模型怎么选?
选择一个合适的 Embedding 模型,是决定 RAG 检索效果的关键决策。这通常需要在开源与商业、性能与成本之间做出权衡。
• 开源 vs. 商业 API
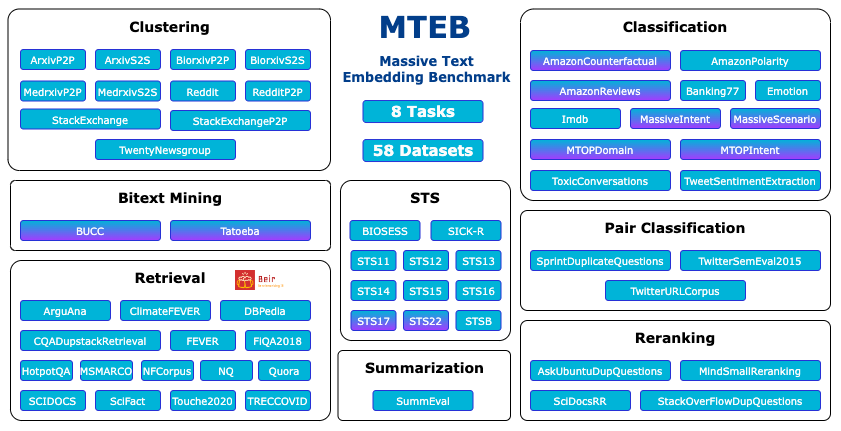
对于 MTEB 排行榜,一个常见的误区是直接选择平均分最高的模型 。然而,对于 RAG 应用来说,Retrieval(检索)这项任务的得分才是最需要关注的指标。一个模型可能因为在分类、聚类等任务上表现优异而总分很高,但其检索能力可能平平。一个优秀的开发者会优先筛选出在检索任务上表现优异的模型,因为这直接关系到能否为 LLM 找到最优质的上下文。
- • 开源模型 (如 BGE, GTE, E5 系列)
- • 优点:完全控制权,数据无需离开私有环境,保障了数据隐私;在拥有计算资源的情况下,大规模使用时成本可能更低;可以在自有数据上进行微调以提升特定领域的表现。
- • 缺点:需要自行部署、管理和优化模型服务,这对技术团队有一定要求。
- • 权威参考:Hugging Face MTEB (Massive Text Embedding Benchmark) 排行榜是业界公认的、用于比较各类开源 Embedding 模型性能的黄金标准。
- • 商业 API (如 OpenAI, Cohere)
- • 优点:通常提供顶级的性能;使用极其简单,只需一个 API 调用;无需管理任何基础设施,服务稳定可靠。
- • 缺点:按 Token 计费的模式在用量大时会变得昂贵;需要将数据发送给第三方服务商。
- • 维度的权衡:越大越好吗?向量维度(如 384, 768, 1024)指的是构成一个向量的数字个数。维度的选择是一个典型的权衡:
- • 高维度:通常能捕捉到更丰富、更细微的语义信息,可能带来更高的检索精度。但代价是,它们需要更大的存储空间、更多的计算资源来进行相似度比较,从而导致更高的成本和延迟。
- • 低维度:存储和计算成本更低,检索速度更快。但可能无法完全捕捉文本的复杂语义,有损失精度的风险。
在工程化落地过程中的策略往往是,从一个中等且性价比高的维度(如 768)开始,只有当评估发现检索质量成为瓶颈时,再考虑增加维度。
表2:主流 Embedding 模型实用对比
为了帮助开发者在繁多的模型中做出选择,下表对当前最受欢迎的几个模型系列进行了实用性对比。
模型系列 | 提供方/来源 | 核心优势 | 成本模型/投入 | 典型维度 |
|---|---|---|---|---|
text-embedding-3-small/large | OpenAI | 顶尖性能,API 简洁,支持自定义维度以平衡成本与性能。 | API 按 Token 计费 | 1536 (small), 3072 (large) |
Embed v3 | Cohere | 专为检索任务优化,支持多语言,提供不同类型的模型(如 english, multilingual)。 | API 按 Token 计费 | 1024 |
BGE (BAAI General Embedding) | 北京智源人工智能研究院 (BAAI) | 在 MTEB 检索任务上持续名列前茅,中英文效果俱佳,完全开源。 | 自行部署(计算成本) | 1024 |
GTE (General Text Embeddings) | 阿里巴巴达摩院 | 强大的开源模型,性能与模型大小均衡,常被用作高质量的基线模型。 | 自行部署(计算成本) | 768 / 1024 |
入库:为知识安“家”
当所有知识单元都被转换成向量后,我们需要一个地方来妥善地存储和管理它们,并支持高效的查询。这个“家”,就是向量数据库(Vector Database)。
向量数据库:海量向量的“超级管家”
向量数据库是一种专门为存储、索引和查询海量高维向量而设计的数据库系统。它的核心能力是执行极其快速的 近似最近邻(Approximate Nearest Neighbor, ANN)搜索。
当一个用户问题被转换成查询向量后,如果要在数百万甚至数十亿的知识向量中找到最相似的几个,通过逐一比较(精确搜索)的方式是完全不可行的,会耗费巨大的计算资源和时间。ANN 搜索则通过构建巧妙的索引结构(如 HNSW、IVF-PQ 等算法),能够在牺牲极小的精度的前提下,以毫秒级的速度找到“足够好”的近似匹配结果。这使得实时语义搜索成为可能。
主流选择对比
市面上有多种向量数据库可供选择,其中 Milvus、FAISS 和 Weaviate 是最具代表性的三个。
- • Milvus
- • 定位:一个为大规模生产环境设计的高性能、高可用的开源向量数据库。它采用分布式架构,可以轻松扩展以支持数十亿级别的向量数据,并提供高吞吐量的查询服务。
- • 最适用场景:大型企业级应用,对性能、可扩展性和系统稳定性有极高要求。可以把它看作是向量数据库领域的“重型工业引擎”。
- • FAISS (Facebook AI Similarity Search)
- • 定位:它本质上是一个库(Library),而不是一个完整的数据库。FAISS 提供了业界最高效的 ANN 算法实现,但它不负责数据的存储、持久化、服务化等数据库管理功能。开发者需要自己围绕这个库来构建服务。
- • 最适用场景:学术研究、算法原型验证,或者那些希望对底层拥有最大控制权、并愿意自行构建基础设施的专家团队。它的 “轻量级”和“研究友好” 体现在它专注于核心算法,没有数据库系统的额外开销。
- • Weaviate
- • 定位:一个功能丰富的开源向量数据库,提供了更多开箱即用的能力。它强调定义清晰的数据 Schema,并且原生支持 混合搜索(Hybrid Search),即同时结合传统的关键字搜索和向量语义搜索,以提升检索的全面性。
- • 最适用场景:需要将结构化元数据过滤与向量搜索深度结合的应用,或是希望快速实现强大的混合搜索能力而无需自行搭建的场景。它像是“功能完备、自带电池”的解决方案。
这三者的选择,不仅仅是技术特性的比较,更深层次地反映了项目所处的阶段和团队的开发哲学。选择 FAISS 意味着“自己动手,丰衣足食”,适合研究和原型阶段;选择 Weaviate 意味着追求“全面的解决方案”,适合功能丰富的 MVP 或中型应用;而选择 Milvus 则代表着“为海量规模而生”,是超大规模生产部署的终极选择。
总结
本篇从五花八门的原始文档(如 PDF、网页)出发,通过精细的清洗和策略性的切分,将其转化为一个个蕴含上下文的知识片段。接着,我们借助强大的 Embedding 模型,为每个片段赋予了独特的“数学灵魂”——向量。最后,这些向量被妥善地安置在专为高速检索设计的向量数据库中,静静等待着被唤醒,为 LLM 提供精准的知识弹药。
知识库已经建好,但真正的 RAG 才刚刚开始。当用户提出一个问题时,系统是如何从数百万个向量中,瞬间找到最相关的那几个?“检索”和“重排”之间有什么区别?LLM 最终又是如何将这些零散的知识片段,融合成一段通顺、准确、令人信服的回答?
敬请期待本系列的下一篇文章:《LLM 系列十:RAG 番外篇-向量检索与召回排序》,我们将深入探讨 RAG 的“检索”与“生成”环节,揭示知识被唤醒并最终服务于用户的完整链路。
腾讯云开发者
