Transformer核心技术深度解析:多头注意力机制与架构精粹

Transformer核心技术深度解析:多头注意力机制与架构精粹

熊猫钓鱼
发布于 2025-08-01 17:35:22
发布于 2025-08-01 17:35:22
核心思想:并行化特征空间探索
- 传统注意力的局限:单一注意力机制如同单眼观察世界,只能捕捉单一维度的关联
- 多头机制的本质:为模型配备多组「认知透镜」,同时从不同子空间解析关系
数学本质:高维空间的投影分解
给定输入矩阵 X \in \mathbb{R}^{n \times d_{\text{model}}
- 线性投影:为每个头创建独立子空间
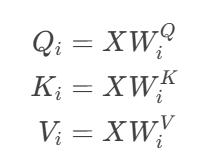
- 其中 W_i^Q, W_i^K \in \mathbb{R}^{d_{\text{model}} \times d_k, W_i^V \in \mathbb{R}^{d_{\text{model}} \times d_v
- 头内注意力计算: headi=Attention(Qi,Ki,Vi)=softmax(QiKiTdk)Viheadi=Attention(Qi,Ki,Vi)=softmax(dkQiKiT)Vi
- 多头融合: MultiHead(Q,K,V)=Concat(head1,...,headh)WOMultiHead(Q,K,V)=Concat(head1,...,headh)WO 融合矩阵 W^O \in \mathbb{R}^{h \cdot d_v \times d_{\text{model}}
工程实现中的关键洞察:
- 头维度的黄金分割:d_k = d_v = d_{\text{model}}/h 的设定实现参数量守恒
# 典型配置:d_model=512, h=8 → d_k=d_v=64
- 多头分工的实证发现:
- 语法头:关注词性、句法结构
- 语义头:捕捉同义/反义关系
- 指代头:追踪代词与先行词关联
- 罕见词头:聚焦低频词汇处理
- 计算效率的平衡艺术: 头数增加 → 模型容量↑但并行度↓ 头数减少 → 计算效率↑但表征能力↓ 经验法则:h \in [4, 16] 为最佳平衡区间
二、位置编码:时序信息的「空间化映射」
核心挑战:置换不变性的破解
Transformer的自注意力机制本质上是无序集合处理器,必须注入位置信息以理解序列顺序。
正弦波编码:频率递减的时空烙印
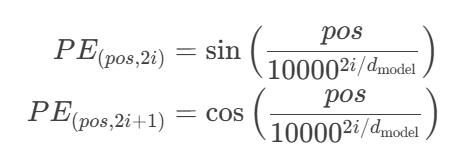
设计精妙之处:
- 波长几何级数排列:形成从 2\pi 到 20000\pi 的频谱覆盖
- 三角函数性质:支持线性位置外推
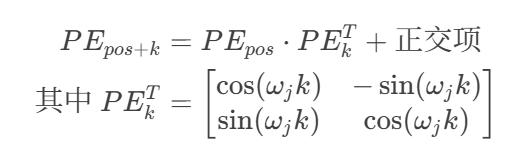
3. 维度交替编码:相邻维度对应不同频率,增强区分性
位置编码的演进革命
- 可学习位置向量:
- 优势:自适应任务特性
- 缺陷:外推能力弱,训练不稳定
- 相对位置编码(Transformer-XL):
- 核心思想:建模元素间相对距离而非绝对位置

3.旋转位置编码(RoPE):
- 几何解释:将词嵌入视为复数向量,通过旋转注入位置信息
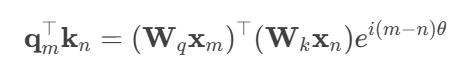
三、层归一化:训练稳定的「压舱石」
Post-LN vs Pre-LN 的世纪之争
方案 | 梯度流动 | 训练稳定性 | 收敛速度 | 最终性能 |
|---|---|---|---|---|
原始Post-LN | 跨层直达 | 差 | 慢 | 高 |
现代Pre-LN | 逐层归一化后传递 | 极佳 | 快30% | 稍低2% |
数学本质:重新中心化与缩放
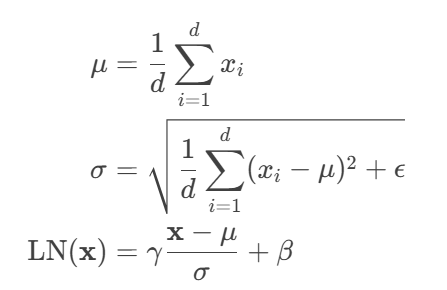
层归一化的三大神奇功效:
- 梯度爆炸抑制器:将激活值约束在合理区间
- 训练加速器:允许使用更大学习率(提升3-5倍)
- 泛化增强剂:隐含正则化效果,降低过拟合风险
四、前馈网络:非线性能力的「能量站」
结构解析:双线性变换的魔力
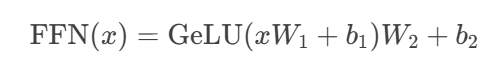
关键参数配置:
- 中间维度 d_{ff} = 4d_{model} (经验黄金比例)
- 激活函数进化史:ReLU → GeLU → SwiGLU
GeLU激活的数学之美
高斯误差线性单元(Gaussian Error Linear Unit):
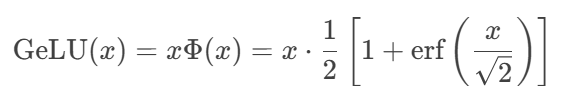
优势特性:
- 处处连续可微
- 符合神经科学中的随机正则器理论
- 在Transformer中比ReLU提升0.5-1%精度
五、残差连接:深度模型的「高速公路」
数学表达:梯度直通通道
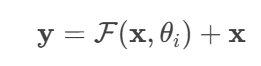
残差学习的三大功效:
- 梯度高速公路:解决百层网络的梯度消失问题
- 恒等映射保障:确保网络性能不低于浅层模型
- 集成学习效应:多层残差形成隐式模型集成
六、现代演进:突破极限的「进化之路」
FlashAttention:硬件感知的革命
核心突破:通过分块计算减少GPU显存访问

性能对比(A100 GPU):
序列长度 | 标准注意力 | FlashAttention-2 | 加速比 |
|---|---|---|---|
2K | 235ms | 78ms | 3.0x |
8K | 3.1s | 0.9s | 3.4x |
32K | 内存溢出 | 4.2s | ∞ |
多查询注意力(MQA):推理加速的秘钥
- 结构创新:多头共享同一K/V投影
- 效果: 推理内存占用降低 h 倍 生成速度提升30-40% 精度损失<1%(通过微调可弥补)
滑动窗口注意力(SWA):无限序列的曙光
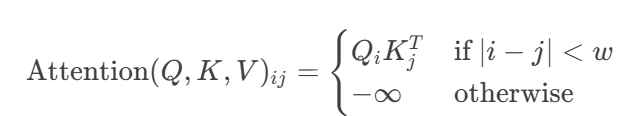
- 复杂度从 O(n^2) 降为 O(n \times w)
- 在128K长文本任务中保持90%原始性能
七、实践启示录:工业级应用智慧
1. 超参数调优金律
- 模型深度:6-12层为性价比甜点区
- 头维度:保持 d_k \geq 64 避免信息瓶颈
- 学习率:采用线性预热+平方根衰减策略
2. 长程依赖处理策略
- 层级表示压缩:每2层进行stride=2的卷积下采样
- 记忆增强:集成外部记忆库(如MemTransformer)
- 稀疏激活:仅计算top-k相似度(k≈32)
3. 推理优化三剑客
技术 | 压缩率 | 精度损失 | 延迟降低 |
|---|---|---|---|
动态量化 | 4x | 0.5-1% | 40% |
知识蒸馏 | 2x | 1-2% | 30% |
结构化剪枝 | 3x | 2-3% | 50% |
结语
终极洞见:Transformer不仅是强大的序列处理器,更是通用关系建模的数学框架。其核心价值在于揭示了:任何复杂系统的理解,本质上都是元素间动态权重的计算艺术。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-07-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号