OCP 2024:Celestial AI公司Photonic Fabric实现高速计算及内存互连

OCP 2024:Celestial AI公司Photonic Fabric实现高速计算及内存互连

光芯
发布于 2025-04-08 17:12:23
发布于 2025-04-08 17:12:23
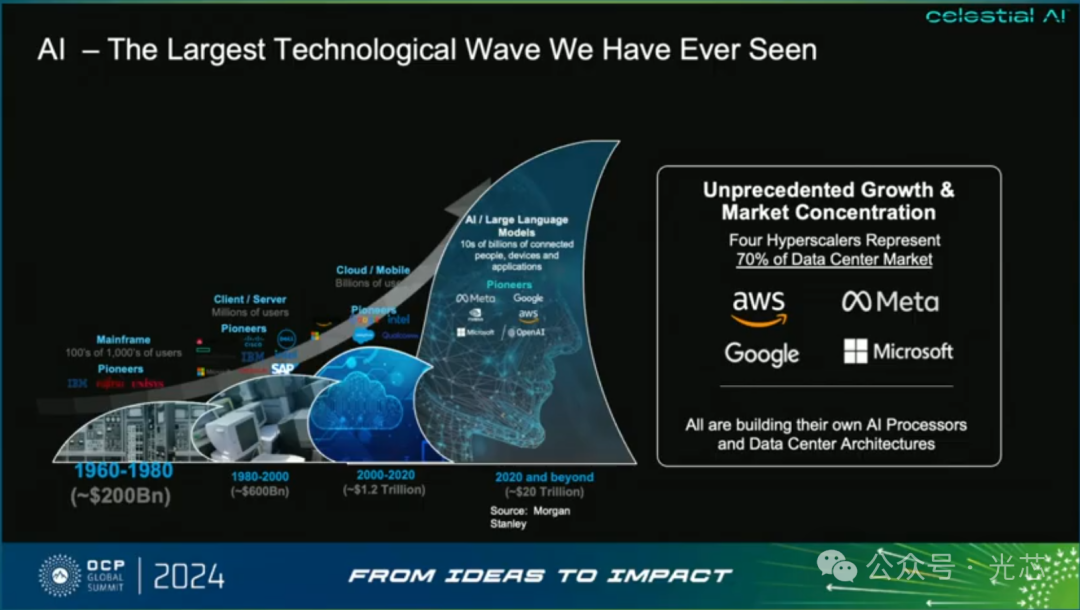
分享一下Celestial AI在OCP 2024上可能报告。虽然花了点时间研究了他家的技术,但还是没整明白😂,这里就只做一些基本翻译。
相比于其他家做短距高密光互连CPO的公司来说,Celestial AI的最大区别之处我理解就在于不止是服务于GPU之间的互连,还致力于打破内存墙,为compute-compute 和compute-memory都提供了高速互联。
Celestial AI认为AI数据中心的瓶颈主要在于内存及互连带宽而非算力(带宽受限系统),他们的Photonic Fabric就是为了解决算力升级与内存拓展的矛盾。

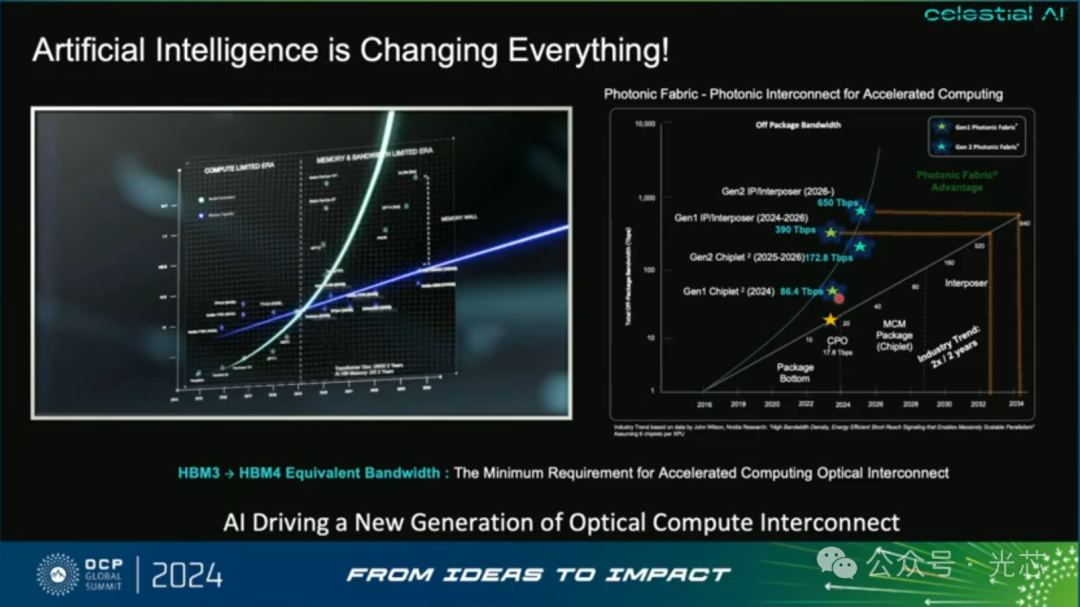
具体的技术核心有4个:
① 热稳定的硅光电吸收EA调制器
热稳定使得PIC芯片可以和100W级的核弹头XPU进行芯片间的封装。电吸收调制没有干涉过程,所以对温度更不敏感。不过GeSi EAM只能工作到L波段,在O波段工作不了。
② 先进封装
通过把TSMC流片的4/5nm CMOS Driver和TIA电芯片以2.5D或3D集成的方式,实现EIC和PIC的高密封装,可以根据客户的需求提供定制化的封装方案(CoWoS-S, CoWoS-L等)。
③ 去DSP直驱
先进封装大大缩短了射频链路,因此可以在无DSP情况下实现高SNR低BER的高速传输。
④ 全栈式电-光-电链路优化(去Gearbox)
与现有的电信号协议无缝对接,兼容现有协议,提供了完整的电-光-电链路管理和优化,包括前向纠错(FEC)、循环冗余校验(CRC)和FLIT重传(FLIT Replay),这些功能有助于确保数据在光链路中的完整性和可靠性。
链路优化这一段感觉挺有意思的,但可惜我不懂这一块。翻译一下就是他们不止在器件和封装上做了创新,在数据链路上也做了创新。传统的数据链路中需要gearbox,将芯片内部的并行IO与片外通信的Serdes进行速率调整实现匹配。他们通过在每个通道上生成优化时延的Flit(流量控制单元)信号,去掉了Gearbox,不管UCIE以16G还是32G的信号进来,经过Photonic Fabric之后都会以56G的信号发送出去。无需Gearbox减少了一部分能耗,更重要的是带来了时延上的大幅优化。


相比铜缆方案,光互连方案能够实现更大封装外的带宽(物理空间不受限,可以在asic上,也可以在asic之间)、更低时延、更低功耗、更长距离(50m vs 1m)、更高效的远程内存访问(RDMA,10pJ/bit vs 60pJ/bit)、更简单的系统连接提供更高的可靠性。功耗这里,PIC和EIC加起来的功耗是2.4pJ/bit,外置光源的功耗是0.7pJ/bit。

具体的实现方案如下。每个芯粒上有2个HBM(64G)和4个DDR(2T),通过系统级封装(SiP)的Photonic Fabric ASIC互联,ASIC包含了内存控制器、光互连组件和网络Switch。HBM3e作为DDR的高速写入缓存(write through cache),这意味着它可以提供接近DDR内存的带宽和延迟,同时具有HBM3E的容量和成本效益。 整个Photonic Fabric模块具有2.07Tb的内存容量,7.2Tbps的带宽和100ns的时延。
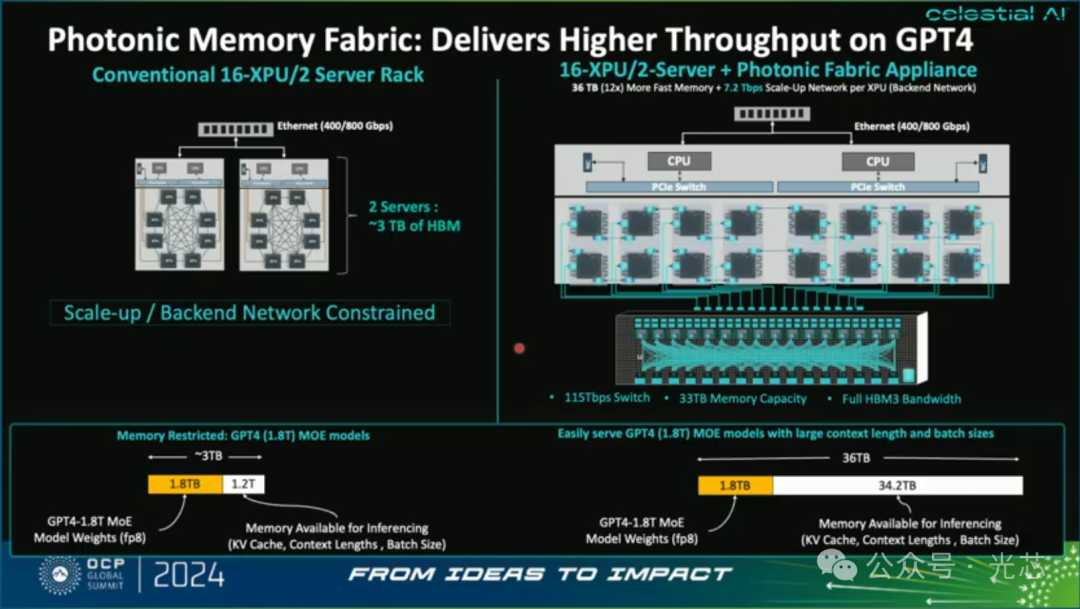
将16个Photonic Fabric模块组成一台2U的设备,可以提供33TB的共享内存容量(内存池化)以及115Tbps的网络交换速率,提供16个XPUs的all to all全连接。这里选取16个GPU是因为它可以支持10万亿参数的深度学习推荐模型。

回到光互连本身,他们的CPO方案单个芯粒可以实现14.4Tbps的速率,功耗为2.4pJ/bit(不考虑外置光源)。比现在的4Tbps 的OIO(Ayar labs)要高3.6倍,下一代还要继续翻倍到28.8Tbps。印象中他们的EAM说是可以达到112Gbps,所以是集成了128通道?采用垂直耦合,是一种大规模量产的成熟工艺。
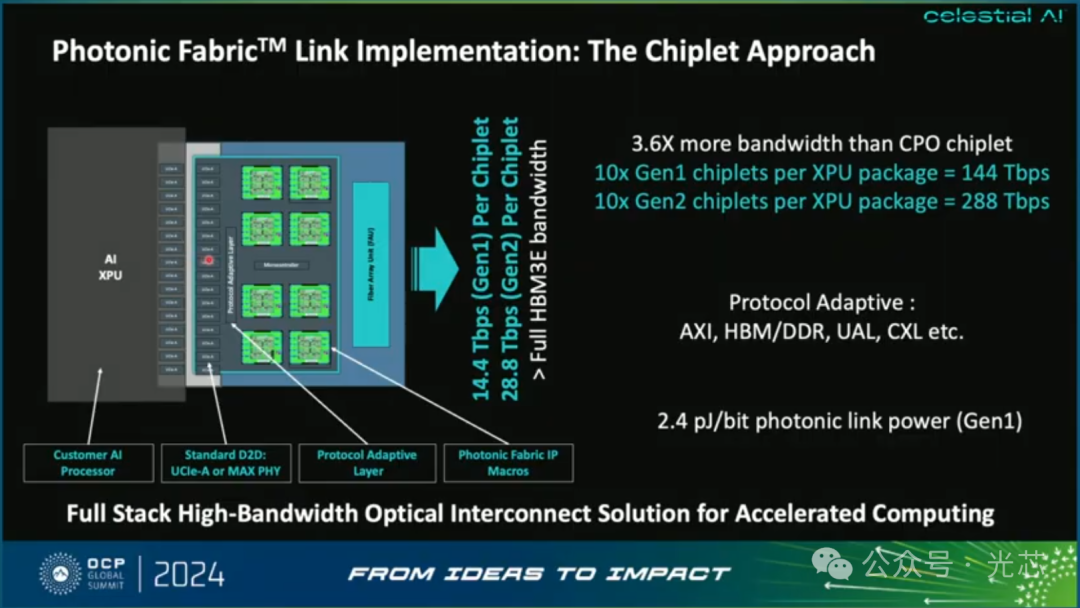

下图是采用Photonic Fabric组建算力集群的例子,只需要16个GPU搭配Photonic Fabric Appliance,就可以提供跟原有铜缆方案56个GPU组网的相同性能,降低了71%的XPU成本和功耗,实现了更高的计算密度,内存资源的拓展与计算资源的解耦和12.5倍的深度学习推荐模型性能加速。如果采用128个Photonic Fabric组建双层的网络架构实现超大规模的集群,那优势就更大了。



以GPT-4为例,传统方案只能提供3T的缓存,1.8T用于储存数据,1.2T用于推理,而Celestial AI就可以提供34.2TB的推理缓存。
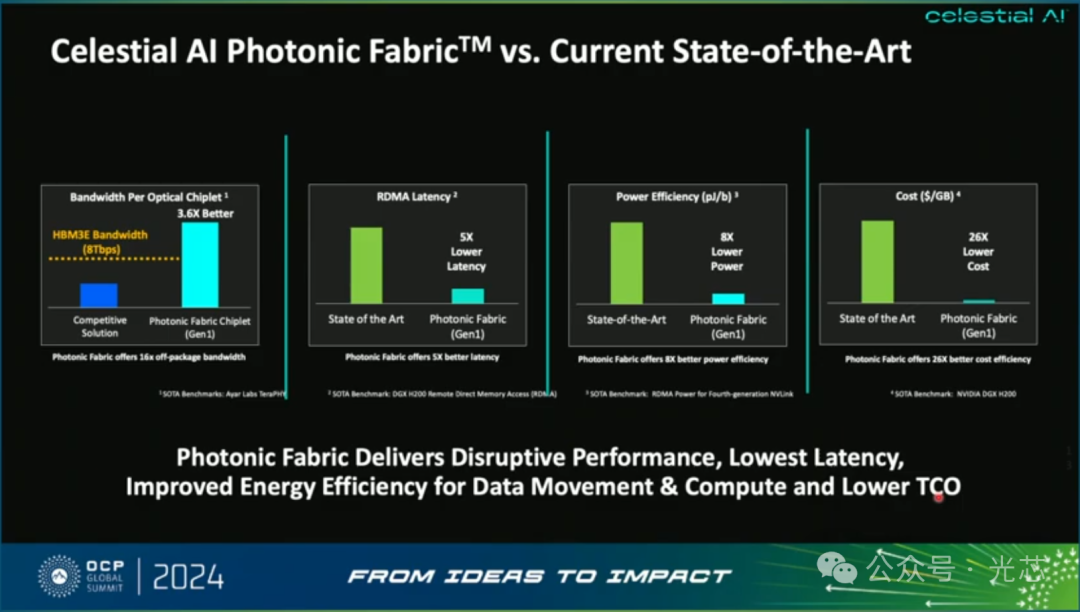
最后总结了他们方案的优势:
◆单芯片14.4Tbps的通信速率,比竞品高3.6倍
◆远程内存访问时延比现有方案降低5倍
◆功耗比现有方案降低8倍
◆成本($/GB)降低26倍
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-10-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号