人工智能 | Nat.Med | 自我提升的生成基础模型在合成医学图像生成和临床应用中的研究

人工智能 | Nat.Med | 自我提升的生成基础模型在合成医学图像生成和临床应用中的研究

生信菜鸟团
发布于 2025-03-06 21:40:37
发布于 2025-03-06 21:40:37
JingDu_Cover.png
Basic Information
- 英文标题:Self-improving generative foundation model for synthetic medical image generation and clinical applications
- 中文标题:自我提升的生成基础模型在合成医学图像生成和临床应用中的研究
- 发表日期:11 December 2024
- 文章类型:Article
- 所属期刊:Nature Medicine
- 文章作者:Jinzhuo Wang | Jia Qu
- 文章链接:https://www.nature.com/articles/s41591-024-03359-y
Abstract
Para_01
- 在许多临床和研究环境中,高质量医学影像数据集的匮乏限制了人工智能(AI)临床应用的潜力。
- 这一问题在较少见的疾病、代表性不足的人群以及新兴的成像模式中尤为突出,在这些情况下,多样且全面的数据集往往不足。
- 为了解决这一挑战,我们引入了一种称为MINIM的统一医学图像-文本生成模型,该模型能够基于文本指令合成多种器官的医学图像,涵盖不同的成像模式。
- 临床医生的评估和严格的客观测量验证了MINIM合成图像的高质量。
- 当面对以前未见过的数据域时,MINIM表现出增强的生成能力,展示了其作为通用医学AI(GMAI)的潜力。
- 我们的研究结果显示,MINIM的合成图像有效补充了现有的数据集,提升了多项医学应用中的表现,如诊断、报告生成和自我监督学习。
- 平均而言,MINIM在眼科任务中提升了12%,在胸部任务中提升了15%,在脑部任务中提升了13%,在乳腺相关任务中提升了17%的表现。
- 此外,我们展示了MINIM在准确预测MRI图像中的HER2阳性乳腺癌方面的潜在临床效用。
- 通过大规模回顾性模拟分析,我们展示了MINIM利用肺癌计算机断层扫描图像准确识别靶向治疗敏感的EGFR突变的临床潜力,这可能有助于提高5年生存率。
- 尽管这些结果令人鼓舞,但在更多样化和前瞻性的设置中进一步验证和改进将极大地增强模型的普适性和鲁棒性。
Main
Para_01
- 大型医疗保健数据集的可用性对于推动人工智能(AI)模型开发和临床应用至关重要。
- 然而,隐私问题引发了重要的伦理和法律问题,使得共享此类数据变得困难。
- 高质量医学影像数据集的匮乏阻碍了尖端AI技术在医学和医疗保健应用中的整合。
- 为了解决这一挑战,数据增强和使用带有生成式AI的合成图象已成为关键解决方案。
- 生成式AI已在医学影像研究领域取得了重大突破,增强了对医疗记录和图象的分析,并改进了诊断和治疗计划。
- 最近的努力表明,生成式AI可以合成高质量的胸部X光影像,形态上保留三维(3D)脑部影像和二维(2D)病理组织学和皮肤病学影像。
- 因此,生成式AI提高了医学影像的理解,并改善了下游分析。
Para_02
- 生成对抗网络(GAN)尤其被广泛用于生成合成医学图像,在增强AI模型的数据可用性方面取得了显著进展1。
- 此外,基于GAN的新管道还结合了分割技术,以进一步减少所需的训练数据集规模,这适用于数据稀缺的场景,例如罕见疾病的病例2。
- 这些研究显示,在单一医学成像模式内,生成式人工智能可以生成高质量的合成图像,这些图像是支持医学影像研究的宝贵资源。
Para_03
- 然而,传统的基于GAN的图像生成在生成具有不同维度的图像方面存在困难,因此通常仅限于单一成像模式。
- 对单一成像模式的探索有限以及缺乏对不同医学成像模式之间关系的研究进一步阻碍了广泛多模态医学图像数据集的充分利用和通用医学生成模型的发展。
Para_04
- 这里介绍了一个统一的医学图像-文本生成模型,称为MINIM。
- MINIM整合了多种模态和器官的配对医学图像及其文字描述,包括光学相干断层扫描(OCT)、眼底、胸部X光和胸部计算机断层扫描(CT)。
- 我们的研究展示了MINIM根据文字描述生成每个器官和成像模式高质量合成图像的能力。
- 我们评估了MINIM基于文本输入生成合成图像的性能,并将其与其他近期的生成模型在不同医学成像场景下进行了比较16,17,18,19。
- 我们还通过纳入额外的磁共振成像(MRI)脑部和乳腺成像数据集来探索模型的适应性,这使我们能够评估MINIM在持续学习和整合新医学知识方面的潜力。
Results
MINIM’s framework overview
MINIM的框架概述
Para_01
- 为了开发一个多功能且可泛化的医学图像-文本生成模型,我们使用了包括OCT、眼底、胸部X光和胸部CT在内的多种医学成像模式,并将其与相应的文本描述作为训练数据(方法)。
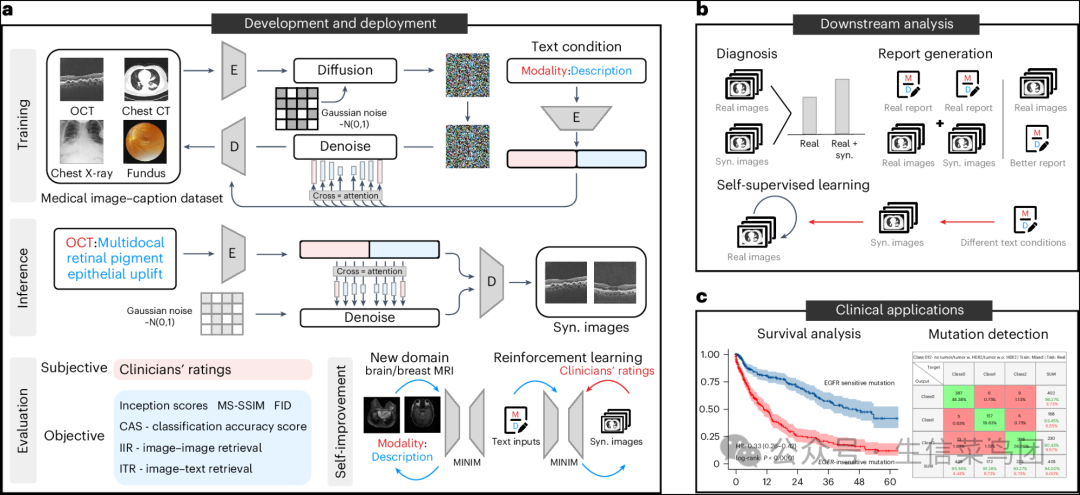
- 我们的模型MINIM通过两个主要阶段运行:一个初始发展阶段,该阶段将所有医学图像和文本描述整合到一个稳定的扩散模型中;以及一个部署阶段,在此阶段基于文本输入生成合成图像(图1a)。
- 为了全面评估MINIM的能力,我们进行了多方面的评估:(1) 通过客观指标和临床医生的主观评估来评价合成图像的质量;
- (2) 探索合成图像在诊断、报告生成和自监督学习中的下游应用(图1b);
- (3) 通过基于人类反馈的强化学习(RLHF)和迁移学习对MINIM实施自我改进策略(图1a);
- 以及(4) 将MINIM应用于检测突变和生存分析等临床任务(图1c)。
Fig. 1: Schematic illustration of our generative system for medical image synthesis.
Fig__1__Schematic_illustration_of_our_generative_system_for_medical_image_synthesis_.png
Fig__1__Schematic_illustration_of_our_generative_system_for_medical_image_synthesis_.png
- 图片说明
◉ MINIM的发展和部署。训练是通过配对的不同模态和器官的图像和报告上的潜在稳定扩散模型进行的。◉ 在部署中,MINIM能够根据多样的文本描述生成高质量的合成图像。◉ 合成图像是通过临床医生的主观评估和多个客观指标进行评估的。◉ 合成图像可以用作额外的训练资源,并且在三种场景中得到展示,包括诊断、报告生成和自我监督学习。◉ 合成图像可以辅助临床应用,包括精确预测乳腺癌MRI图像中的HER2突变和肺癌CT图像中的EGFR突变,并提高生存分析。◉ Syn.,合成。
Quality evaluations
质量评估
Para_01
- 为了测试MINIM生成的合成图像的质量,我们进行了全面的评估,包括主观评估和客观评估。
- 我们首先进行了临床医生的主观评价,随后使用了弗雷歇 inception 距离(FID)20、inception 分数(IS)21 和多尺度结构相似性指数测量(MS-SSIM)22 等客观指标来衡量保真度、多样性和质量。
- 此外,我们将分类准确性评分(CAS)、零样本图像-图像检索(IIR)和图像-文本检索(ITR)方法纳入评估,以评估合成图像的实际效用和相关性。
- 所有评估都在OCT、眼底图像、胸部X光片和胸部CT上进行。
- 有关训练细节和比较的图像-文本生成模型,请参见方法部分。
Subjective assessment from clinicians
临床医生的主观评估
Para_01
- 我们邀请了针对相应成像模式的专业临床医生评估合成图像是否在临床上准确和有用(图2a)。
- 临床医生根据1到3分的评分标准对合成图像进行评分:1分表示低质量图像;2分表示高质量图像但与报告无关;3分表示高质量图像且与报告高度一致。
- 我们进行了三轮评分,并通过计算得分3的图像所占百分比来总结结果。
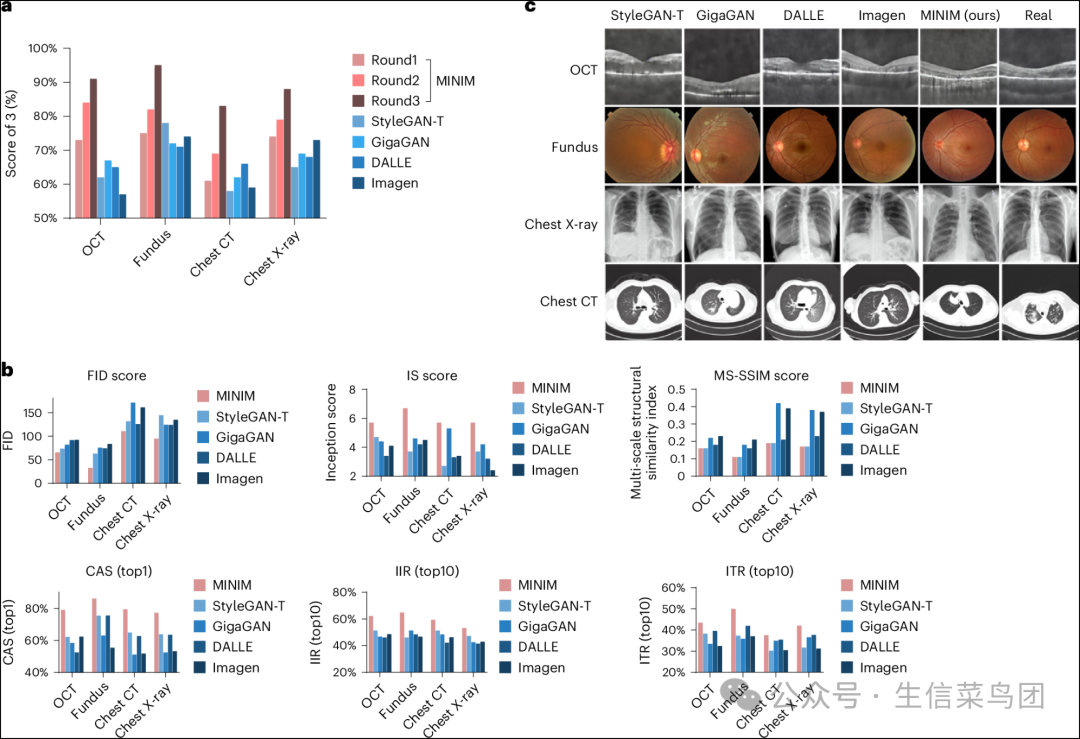
- 在第一轮中,MINIM 达到了平均 70.75% 的评分(OCT 为73%,眼底成像为75%,胸部CT为61%,胸部X光为74%),而最好的竞争生成模型(StyleGAN-T)达到了平均 65.75% 的评分(OCT 为62%,眼底成像为78%,胸部CT为58%,胸部X光为65%)。
- 在第三轮中,实施了强化学习(RL)(方法部分),MINIM 的表现有了显著提升,达到了平均 89.25% 的评分(OCT 为91%,眼底成像为95%,胸部CT为83%,胸部X光为88%)。
Fig. 2: Evaluations of generated synthetic images.
Fig__2__Evaluations_of_generated_synthetic_images_.png
Fig__2__Evaluations_of_generated_synthetic_images_.png
- 图片说明
◉ 临床医生对生成的合成图像进行了三轮评分。评分1表示低质量图像;评分2表示高质量图像但与报告无关;评分3表示高质量图像且与报告一致。根据评分结果,我们训练了两阶段RL策略模型,并将其迭代应用于MINIM。◉ 使用MINIM和其他文本到图像生成模型,通过六种客观指标(FID、IS、MS-SSIM、CAS、IIR和ITR)进行的客观评估性能比较。◉ 使用不同方法生成的合成图像的演示。
Objective image quality assessment
客观图像质量评估
Para_01
- 我们采用了客观指标来定量评估生成图像的保真度、多样性和整体质量。
- 这些图像应该显示出强大的多样性,以涵盖广泛的病理变异,同时不因过度拟合训练数据而失去多样性,同时也保持与真实图像的高度保真度,如低FID、低MS-SSIM和高IS得分所示(扩展数据图1)。
- 对于每一对合成图像和真实图像,计算了FID,而IS和MS-SSIM则在合成图像之间独立计算。
- 我们报告了MINIM和其他竞争性文本到图像生成方法的平均结果(图2b)。
- 我们的研究结果显示,MINIM的表现(OCT的FID:65.3,IS:5.7±0.42,MS-SSIM:0.16±0.03;眼底的FID:32.7,IS:6.7±0.43,MS-SSIM:0.11±0.03;胸部X射线的FID:110.4,IS:5.7±0.37,MS-SSIM:0.19±0.06;胸部X射线的FID:94.8,IS:5.7±0.38,MS-SSIM:0.17±0.04)远远超过了其他生成方法。
- MINIM和其他生成方法的合成图像样本表明,MINIM可以在所有设置下生成更逼真的图像(图2c)。
CAS performance
CAS性能
Para_01
- CAS 是评估合成数据的一个新兴指标。
- CAS 衡量了仅使用合成样本训练的模型对真实测试数据进行分类的准确性。
- 对于四种模态和器官中的每一种,我们使用 MINIM 为每个类别标签生成了比真实数据集多十倍的合成图像(方法部分)。
- 并报告了使用每种真实数据集中随机选取的 1/10 图像的测试集上的 CAS。
- 图 2b 显示,MINIM 在不同数据集上的一致性准确率方面优于其他生成方法(OCT 的一致性准确率为 79.09%,眼底的一致性准确率为 86.16%,胸部 CT 的一致性准确率为 79.42%,胸部 X 光的一致性准确率为 77.23%)。
Performance on zero-shot IIR
零样本信息检索的表现
Para_01
- 为了进一步验证MINIM生成图像的质量,我们采用了零样本IIR方法。
- 使用真实图像作为查询,该评估旨在检索与查询图像类别密切相关的候选合成图像。
- 查询图像和候选图像都被输入到一个针对其成像模式预训练的图像编码器中,
- 利用余弦相似性根据特征相似度对候选图像进行排名。
- 对于每个查询,我们在前10名候选图像中报告了与查询的真实图像属于同一类别的合成图像的数量,
- 使用precision@k指标,其中k=10。
- 图2b展示了MINIM在每个案例中优于其他生成模型的结果(OCT为62.25%,眼底为64.83%,胸部CT为59.44%,胸部X光为53.17%)。
- 这些结果表明了MINIM在生成图像质量方面的优越性。
Performance on zero-shot ITR
零样本ITR的表现
Para_01
- 为了评估合成图像是否对应于临床上相关且准确的文本,我们进行了零样本ITR。
- 在这种方法中,查询图像嵌入被映射到文本嵌入空间,以检索与图像最相关的文本印象。
- 我们使用精度@k(k=10)计算检索精度,其中对于每个与查询图像类别相同的文本印象,会获得一个准确性分数。
- 图2b展示了MINIM相对于其他生成模型的优越结果(OCT为43.41%,眼底为49.93%,胸部CT为37.53%,胸部X光为42.04%)。
Self-improving strategies
自我提升策略
RL from clinicians’ ratings
基于临床医生的评分
Para_01
- RLHF策略采用了一种合成循环的方法来迭代增强MINIM的性能,这种方法涉及利用临床医生的评分或反馈来创建一个持续学习的闭环。
- 我们的两阶段RLHF策略首先由一组临床医生评估合成图像与相应提示文本报告的质量。
- 然后使用临床医生的反馈来训练一个奖励模型,该模型模仿临床医生的评分。
- 这个奖励模型被纳入MINIM中,作为指导模型训练和提高整体性能的附加监督层。
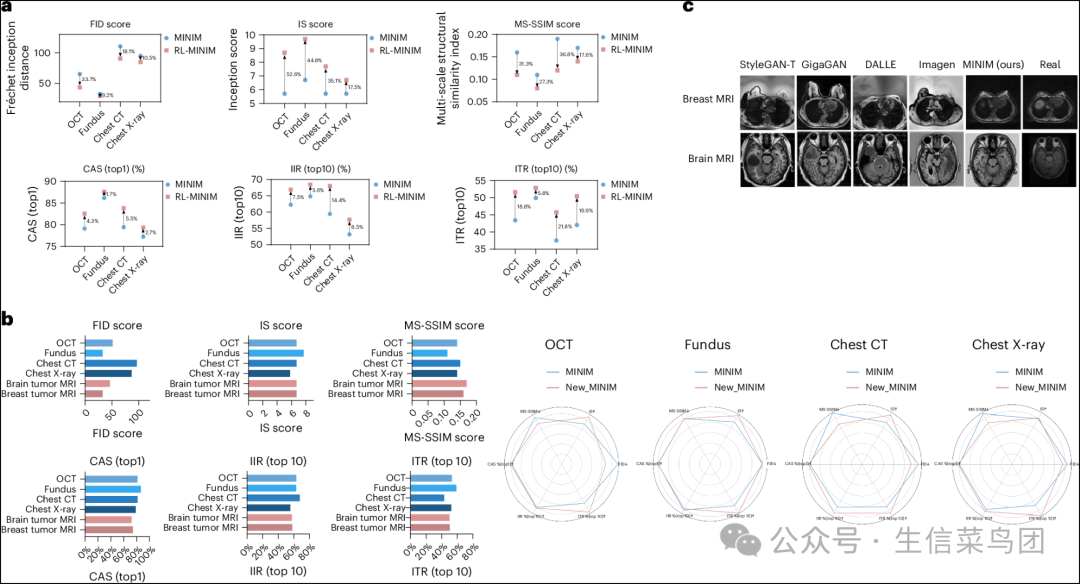
- 我们比较了RLHF整合如何通过六个主观指标(图3a)改善图像生成,与其他四种数据增强方法相比。
- 值得注意的是,所有五种方法,包括MINIM,在其原始生成模型的基础上都有所改进,其中两阶段RLHF策略表现出最显著的提升(例如,对于OCT,FID降至43.3对65.3;IS升至8.7±0.37对5.7±0.42;以及MS-SSIM降至0.11±0.06对0.16±0.03)。
- 这些结果突显了将人类反馈整合到RL过程中的价值,显著提高了生成模型在多个指标上的性能。
Fig. 3: Self-improvement evaluations.
Fig__3__Self-improvement_evaluations_.png
Fig__3__Self-improvement_evaluations_.png
- 图片说明
◉ a, 使用RLFH生成图像的六项主观结果,基于临床医生的评分。◉ b, 通过容纳来自新领域的图像-文本配对数据,MINIM生成能力的性能提升。◉ c, 使用MINIM和其他生成方法在新领域展示合成图像。
Transfer learning
迁移学习
Para_01
- MINIM相对于先前的专业模型的一个主要优势是它能够利用来自不同器官和成像模式的图像-文本配对医学数据。
- 在新一轮开发中加入了乳腺和脑部MRI数据集后,我们评估了先前训练过的模态的表现(图3b,右面板)。
- 我们观察到六个模态都有明显的改进,FID从65.3下降到了51.3,IS从5.7±0.42增加到了6.7±0.48,MS-SSIM从0.14±0.03提高到了0.16±0.03。
- 这些发现突显了MINIM的持续学习潜力,这得益于不断整合新的医学数据。
Para_02
- 对合成的大脑和乳房磁共振图像(图3b,左面板)的客观评估表明,MINIM可以在将这两种成对模态的数据集与现有的四种成对模态的数据集混合时,在这两个领域生成高质量的合成图像。
- 我们展示了由MINIM生成的合成图像与其他基于相同文本指令生成的生成模型所生成的图像的比较(图3c),观察到MINIM可以生成具有增强的真实性和保真度的图像。
- 更多根据不同描述条件生成的例子见扩展数据图5和图6。
Downstream applications using synthetic images
使用合成图像的下游应用
Diagnosis
诊断
Para_01
- 我们证明了向训练数据集添加合成数据可以显著提高医学诊断性能。
- 使用Swin变换器分类器24对多类诊断模型进行了训练,并为每种模式提供了诊断标签。
- 我们将仅使用真实数据集训练的模型结果与使用由各种比例的合成图像组成的混合数据集训练的模型结果进行了比较。
- 仅使用真实数据的基线top-1分类准确性为:OCT为0.64,眼底为0.74,胸部CT为0.58,胸部X光为0.59。
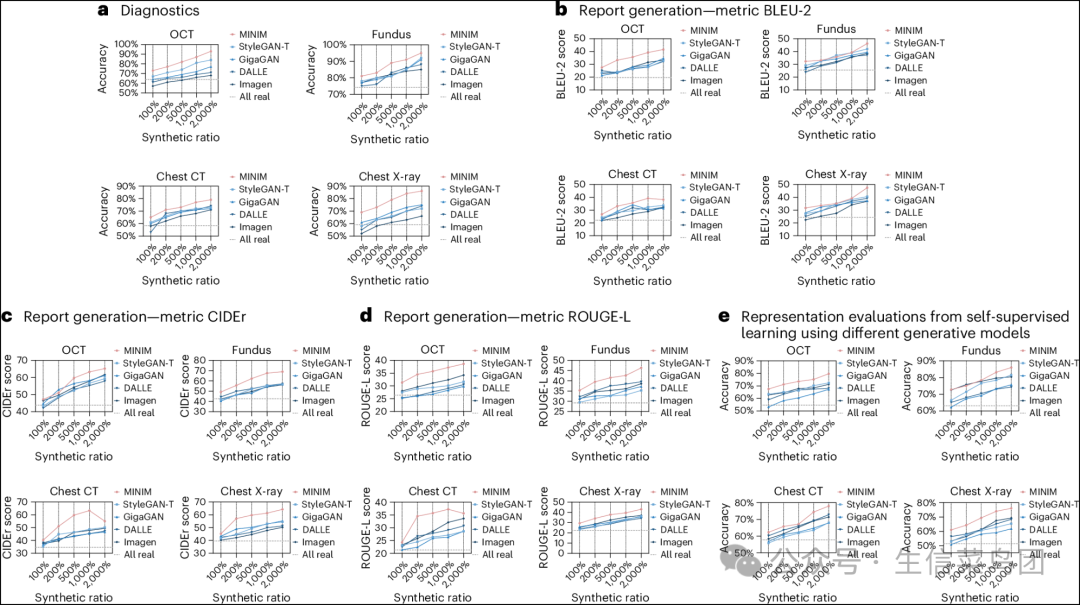
- 值得注意的是,在合成数据与真实数据比例为1:1的情况下,top-1分类准确性提高到:OCT为0.73,眼底为0.81,胸部CT为0.65,胸部X光为0.69。
- 通过增加合成数据的比例,我们观察到了top-1分类准确性平行提升,最终在合成数据与真实数据比例为20:1的情况下达到了平均准确性:OCT为0.93,眼底为0.95,胸部CT为0.79,胸部X光为0.86(图4a)。
- 为了进一步验证合成数据的有效性,我们专门针对诊断性能较差的类别合成了OCT图像。
- 混淆图可视化了模型在真实数据上的分类结果(扩展数据图4),结果显示四种诊断(术后黄斑孔、脉络膜和视网膜变性、视网膜血管炎和眼内炎)的表现明显不如其他诊断。
- 随后,我们为这四种诊断各自生成了100张定制的OCT图像,并邀请眼科医生通过选择典型图像来进一步训练模型。
- 这种迭代方法导致了诊断效果的显著改善(扩展数据表4),展示了合成数据增强训练数据集并解决特定诊断挑战的能力。
- 此外,该模型成功诊断了常见疾病的非典型病例,包括视网膜静脉阻塞(RVO)、脉络膜新生血管(CNV)和糖尿病视网膜病变(DR),展示了其识别疾病表现广泛谱的能力(扩展数据图5a)。
Fig. 4: Synthetic images serve as data augmentation.
Fig__4__Synthetic_images_serve_as_data_augmentation_.png
Fig__4__Synthetic_images_serve_as_data_augmentation_.png
- 图片说明
◉ 通过将来自MINIM和其他生成模型的合成图像融入真实数据中,对诊断任务的表现进行了比较。◉ 通过将来自MINIM和其他生成模型的合成图像融入真实数据中,在三个指标上对报告生成任务的表现进行了比较。◉ 通过将来自MINIM和其他生成方法的自监督学习表示进行比较。◉ ,
Report generation
报告生成
Para_01
- 为了生成报告,我们整理了在真实数据集中出现超过10次的文本描述,最终每种模态生成了60份图像报告。
- 针对每份报告生成了合成图像,从而创建了一个相对于真实数据集收集过程而言更为可控和平衡的合成数据集。
- 使用CLIP+GPT-2框架25,我们为每种模态训练了一个报告生成模型,并使用BLEU-n、CIDEr和ROUGE-L得分等指标(图4b-d)评估了其输出与临床医生提供的注释的一致性。
- 与我们的诊断发现一致,合成数据与真实数据(比例为20:1)的结合提高了性能,对于OCT、眼底、胸部CT和胸部X光片分别获得了38.6、46.3、35.6和43.0的ROUGE-L得分,而仅使用真实数据时,对应的得分分别为26.4、29.2、21.3和22.6。
- 扩展数据图5b展示了生成的OCT报告的一些精选示例,展示了该模型能够捕捉到眼科医生可能会忽略的疾病信息。
- 此外,这些示例还展示了合成数据不仅作为一种增强策略,还可以作为丰富和完善医学影像报告工具的潜力。
Self-supervised learning
自监督学习
Para_01
- 自我监督学习允许模型通过在辅助目标上预训练从无标签数据中推导出有意义的表示,这种方法在医学影像领域特别有益,在该领域中无标签数据丰富而标记成本高昂。
- 为了评估我们模型合成图像在自我监督预训练中的有效性,我们对来自不同模态的图像进行了增强,并使用了孪生网络分支来学习不变特征。
- DenseNet-121模型在辅助任务上进行了预训练,这些任务涉及将分类层微调至可用训练数据的100%到2000%。
- 我们的研究结果表明,使用合成和真实图像进行微调的模型始终优于仅使用真实图像进行微调的模型,顶级精度显著提高,OCT达到了79.7,眼底图像达到了86.0,胸部CT达到了78.0,胸部X光达到了76.1,相比初始精度分别为54.7、63.1、57.8和51.4(图4e)。
Clinical applications using synthetic images
使用合成图像的临床应用
EGFR mutation detection in lung cancer
肺癌中的EGFR突变检测
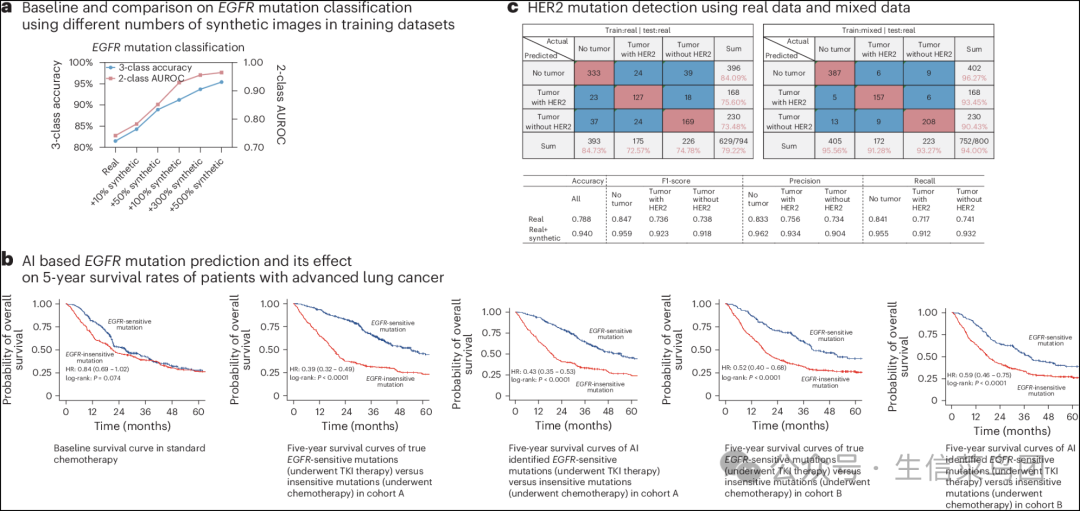
Para_01
- 我们调查了合成图像是否可以提高使用胸部CT扫描(图5a)进行EGFR(https://www.ncbi.nlm.nih.gov/gene/1956)突变分类的前1名准确率。
- 采用Swin变换器将真实的CT图像分类为三种EGFR突变类型:野生型、敏感型和耐药型。
- 仅使用真实数据的基线性能达到了平均前1名准确率为81.5%。
- 通过逐步将合成数据纳入训练集,我们观察到分类准确率有了显著提升。
- 引人注目的是,训练集中合成数据与真实数据的比例为1:1时,分类准确率提高到了91.2%,而当该比例达到5:1时,准确率进一步提升至95.4%。
- 在此之后,增加更多的合成数据并未带来明显的改进。
- 在后续的二元分类任务中,结合EGFR野生型和耐药型突变,合成数据的加入同样增强了模型性能,使用受试者工作特征曲线下的面积(AUROC)来衡量。
- AUROC从仅使用真实数据时的74.2%提高到合成数据扩展五倍时的96.5%。
- 这些趋势突显了合成数据在提高AI模型预测EGFR突变检测准确性方面的价值。
Fig. 5: AI-based mutation prediction performance and its effect on 5-year survival rates of patients with advanced lung cancer.
Fig__5__AI-based_mutation_prediction_performance_and_its_effect_on_5-year_survival_rates_of_patients_with_advanced_lung_cancer_.png
Fig__5__AI-based_mutation_prediction_performance_and_its_effect_on_5-year_survival_rates_of_patients_with_advanced_lung_cancer_.png
- 图片说明
◉ 基线和使用不同数量的合成图像进行EGFR突变预测的性能对比。◉ 从左到右:接受标准化疗患者的基线生存曲线;队列A中真实EGFR敏感突变(接受TKI治疗)与EGFR不敏感突变(接受化疗)的5年生存曲线;队列A中AI识别出的EGFR敏感突变(接受TKI治疗)与EGFR不敏感突变(接受化疗)的5年生存曲线;队列B中真实EGFR敏感突变(接受TKI治疗)与EGFR不敏感突变(接受化疗)的5年生存曲线;队列B中AI识别出的EGFR敏感突变(接受TKI治疗)与EGFR不敏感突变(接受化疗)的5年生存曲线。◉ 通过向训练数据集添加合成图像来预测HER2突变的性能。
Para_02
- 我们进一步在一个回顾性临床研究中使用两个独立的患者队列验证了这些结果(方法)。
- 我们评估了我们的模型对晚期肺癌患者基于EGFR突变预测他们是否能从酪氨酸激酶抑制剂(TKI)靶向治疗中受益的能力。
- 我们首先确定了接受标准化疗患者的基线生存曲线(图5b)。
- 然后,利用我们的模型预测,我们识别出具有EGFR敏感突变的患者(接受TKI治疗)并与那些具有EGFR耐药突变的患者(接受化疗)相比,比较了他们的生存率。
- 在第一组患者(队列A)中,EGFR敏感突变的五年总生存率(OS)高出29.5%(EGFR敏感突变,53.4%(95%置信区间(CI):47.5-60.1%);EGFR耐药突变,23.9%(95%CI:19.3-29.5%)),并且中位生存时间更长(EGFR敏感突变,54.7个月(95%CI:45.4-未定);EGFR耐药突变,18.8个月(95%CI:16.6-21.1))(图5b)。
- 五年无进展生存率(PFS)和客观缓解率(ORR)也分别从12.2%提高到41.6%(扩展数据图2a,b)和从12.3%提高到30.9%(扩展数据图3a,b)。
- 我们在第二组患者(队列B)中确认了类似的结果,五年OS增加了14.7%(EGFR敏感突变,41.0%(95%CI:32.2-52.2%);EGFR耐药突变,26.3%(95%CI:21.6-32.1%))并且中位生存时间更长(EGFR敏感突变,40.6个月(95%CI:36.4-63.2);EGFR耐药突变,18.1个月(95%CI:16.2-21.0))(图5b)。
- 我们的模型对队列A(EGFR敏感突变,0.12(4/327),EGFR耐药突变,0.018(6/321))和队列B(EGFR敏感突变,0.028(4/142),EGFR耐药突变,0.04(6/316))的预测误差率都很低。
- PFS和ORR也分别从19.1%提高到44.7%(扩展数据图2c,d)和从18.9%提高到33.1%(扩展数据图3c,d)。
- 注:在扩展数据图中,a、b、c、d 分别表示不同的子图。
HER2 status detection in breast cancer
乳腺癌中的HER2状态检测
Para_01
- 鉴于HER2状态的复杂性及其在确定HER2靶向治疗结果中的关键作用,我们的目标是探索是否将来自我们模型的合成图像整合进来可以提高HER2状态分类的准确性。
- 我们首先建立了一个仅基于真实数据集训练的基线模型,该模型区分三个类别(无肿瘤/HER2阳性肿瘤/HER2阴性肿瘤)的分类准确率约为79.2%(图5c,左面板)。
- 随着以2倍、3倍、5倍和10倍于真实图像比例逐步加入带有文本描述的合成图像,我们观察到分类准确率有了显著提升,在合成图像与真实图像比例为10:1时达到峰值94.0%(图5c,右面板)。
Discussion
Para_01
- 我们提出了一种统一的医学图像-文本生成模型(MINIM),该模型是在各种模态和器官(OCT、眼底、胸部X光、胸部CT、脑部MRI和乳腺MRI)配对的医学图像及其文本描述上训练的。
- 我们展示了MINIM在给定文本描述的情况下,能够为每种器官和成像模态生成高质量的合成图像的能力。
- 生成的数据可以作为开发AI模型的补充资源,尤其是在由于隐私或成本原因导致数据不足的情况下。
- 我们的研究结果表明,基于真实和合成数据训练的AI模型具有增强的预测能力,在罕见疾病的诊断、报告生成和自监督学习方面尤其有益。
- 从临床角度来看,我们证明了MINIM可以显著提高乳腺HER2突变的检测率。
- 此外,我们在一项临床研究中应用了MINIM进行EGFR突变靶向治疗,并在两个独立队列中展示了5年生存率的改善。
Para_02
- 我们的评估旨在展示肺癌和乳腺癌分类准确性中的临床相关性和我们AI模型的优势。
- 对于肺癌,我们重点关注了EGFR突变分类,因为这对确定TKI靶向治疗的适用性至关重要,这种治疗方法显著改善了晚期非小细胞肺癌患者的生存率。
- 通过评估该模型在三类(野生型、敏感型和耐药型)和二类(敏感型对比耐药型+野生型)分类任务中的表现,我们证明了该模型在准确预测EGFR状态方面的稳健性,这对于指导靶向治疗决策至关重要。
- 我们的AI驱动方法为传统基于活检的EGFR突变检测提供了一种非侵入性、高效且可扩展的替代方案,最终改善了患者预后并扩大了精准医疗的可及性。
Para_03
- 乳腺癌是全球女性中最常见的癌症,对女性健康构成了相当大的威胁。
- HER2是一种用于确定HER2靶向治疗获益的关键生物标志物。
- 传统上,只有HER2扩增或过表达被用来预测从HER2靶向治疗中获得生存获益的增强。
- 我们的模型解决了这一局限性,通过提供一种更全面和细致的方法来分类HER2状态。
- 通过利用真实和合成的数据集,我们的模型识别了与HER2阳性肿瘤相关的微妙模式,这些模式可能无法通过常规方法检测到。
- 这种更准确地分类HER2状态的能力可以更好地识别出将从HER2靶向治疗中受益的患者,最终改善HER2阳性乳腺癌患者的治疗结果和生存率。
Para_04
- 尽管在GANs方面取得了进展,但由于训练数据有限,生成高质量的医学影象仍然存在挑战。
- MINIM通过整合文本和影像数据解决了这一局限性,有效地扩展了输入空间并提升了生成影象的质量。
- 此外,通过使用配对的图像和文本输入来训练模型,也缓解了关于生成影象临床相关性的担忧,确保输出与附带文本中描述的临床背景紧密一致。
Para_05
- 另一个长期存在的问题是合成数据在多大程度上能够提升预测模型的表现。
- 在这里我们提供了证据,表明所提出的生成模型可以通过强化学习和迁移学习自我改进(图1a),实现持续学习,并解决适应新数据领域的问题。
- 这些发现对开发能够在各种应用中随着时间的推移进行适应和学习的生成式人工智能模型具有重要意义。
Para_06
- 我们认识到本研究存在几个需要关注的局限性。
- 首先,所使用的数据集规模相对较小,主要来源于高加索人和中国人群体。
- 这种有限的人口统计范围,加上研究中来自已发表数据集的样本量适中,可能会导致偏差。
- 为了缓解这一问题,未来模型的迭代版本应纳入更多来源的数据,确保不同性别和种族群体得到全面代表。
- 这种扩展不仅会增强模型的鲁棒性,还会提高其在更广泛人口统计学中的适用性。
Para_07
- 另一个重要的限制在于CLIP文本编码器的令牌长度所施加的约束43。
- 目前,我们的训练仅限于OCT和胸部X光报告的部分内容,这可能会无意中忽略关键的图像特征信息。
- 为了解决这个问题,我们建议整合更多详细的文字信息,包括发现和临床细节。
- 这种丰富将增强模型的条件能力,使其能够更细致和全面地分析医学图像及其伴随的文本报告。
Para_08
- 第三个关注领域是文本和图像对齐的挑战,尤其是在处理较长提示时。
- 这种对齐困难可能通过创新方法得到改善,例如采用基于人类反馈训练的奖励模型。
- 这样的方法可能会提高文本-图像对齐的精确度,使模型在处理复杂且较长的提示时更加有效。
- 除了这些挑战外,还存在模型过拟合的风险。
- 为了对抗这一点,我们强调需要精心制定策略,例如在微调过程中整合对抗损失并自适应地管理学习率,特别是在有限数据的约束下。
- 持续的人类监督和反馈是这一过程的关键组成部分,确保模型保持准确性和可靠性。
Fig. 6: A two-stage RL strategy using human ratings.
Fig__6__A_two-stage_RL_strategy_using_human_ratings_.png
Fig__6__A_two-stage_RL_strategy_using_human_ratings_.png
- 图片说明
◉ 第一阶段涉及从生成模型生成合成图像。◉ 生成的图像随后传递给一个‘接收选择器’,它作为一个分类模块运行。◉ 第二阶段引入了一个主动选择过程。◉ 再次,合成图象被输入系统,但这次,‘接收选择器’分类模块根据分类结果决定传递哪些图像。
Methods
Dataset descriptions and ethical approvals
数据集描述和伦理批准
Para_01
- 我们收集了来自多个医疗机构的OCT数据和报告,以建立一个广泛的数据库(扩展数据表1,左)。
- 我们将中国眼科图像调查中的图像-报告对结合起来,并根据患者识别信息随机拆分数据,以构建训练集和验证集(11,438个数据对)。
- 我们使用温州医科大学附属眼视光医院的数据进行外部验证(2,287个数据对)。
- 除了公共数据集中包含报告的OCT图像外,我们还组装了一个高质量的数据集,包括13,725个配对的图像-文本OCT样本。
Para_02
- 视网膜眼底图像来自中国生物年龄调查联盟的研究队列(扩展数据表1,中间部分),包括来自中国唐山市河北医科大学亚健康人群研究的北部中国队列,以及来自中国广东省广州市南方医院和珠海人民医院的南部中国队列。
- 共有59,420对图像和文字参与了我们的研究。
Para_03
- 胸部CT和X光图像来自华西医院和广州医科大学(扩展数据表1,右侧)。
- 对于每个带有医疗记录的患者,我们选择了10张CT图像和10张X光图像,总共产生了3745名患者的74900组配对数据。
Para_04
- 脑MRI数据集来自多个中心,包括中国16家医院的1960名患者。
- 这些患者共同贡献了总计30800张标注了肿瘤的图像,其中包括13859张T1通道图像和16941张T2通道图像。
Para_05
- 乳腺肿瘤影像数据集来自广州国家实验室和中山大学附属第一医院(如扩展数据图6所示),涵盖了3,694名被诊断为乳腺MR图像的患者。
- 这些患者共提供了34,506张标注的肿瘤图像和35,000张正常的乳腺图像,其中包括16,017张T1通道图像、6,129张T2通道图像和47,360张增强对比T1通道图像。
- 值得注意的是,3,200张图像包含了HER2基因的信息,这些信息专门用于训练模型将HER2基因表达与MRI特征相关联。
- 其余图像作为额外的数据集来训练稳定扩散模型,确保其性能稳健可靠。
Para_06
- 研究获得了所有参与医院或研究所的机构审查委员会/伦理委员会的批准。
- 所有涉及的患者均签署了同意书。
- 该研究遵循《赫尔辛基宣言》的原则,并符合中国疾病预防控制中心以及中国卫生法律法规的政策。
Image grading from clinicians
临床医生的图像评分
Para_01
- OCT和眼底图像通过了一个分级系统,该系统包含多层受过训练的分级员,分级员的专业水平逐步提高,用于验证和纠正图像标签。
- 每张导入数据库的图像最初都有一个标签,这个标签与患者最近的诊断相匹配,并且检查了每对报告。
- 第一级分级员由医学学生和眼科住院医生组成,他们参加了并且通过了解释课程的审查。
- 这一级别的分级员对真实患者的图像进行了初步的质量控制,并排除了包含严重伪影或明显图像分辨率降低的图像。
- 第二级分级员由五位拥有至少10年视网膜亚专业实践的眼科医生组成,他们独立地对每张图像及其对应的报告进行分级。
- 记录了反映玻璃体、视网膜、色素上皮(RPE)和脉络膜以及各种视网膜疾病诊断(包括脉络膜新生血管(活动性或以视网膜下纤维化形式存在)、黄斑水肿、玻璃疣、视网膜静脉阻塞、增殖性玻璃体视网膜病变和其他在OCT扫描中可见的病理)的图像的存在与否。
- 最后,第三级由两位资深独立视网膜专家进行验证,每位专家都有超过20年的临床视网膜经验,他们验证了每张图像的真实标签和相应的报告。
- 为了弥补分级过程中的人为错误,一个验证子集中的993次扫描由两位眼科医生分级员单独分级,对于临床标签中的分歧,由一位资深视网膜专家仲裁。
- 对于胸部X光片、胸部CT、脑部MRI和乳腺MRI图像,所有模式最初都通过去除所有低质量或无法读取的扫描来进行质量控制。
- 类似于先前的眼科图像分级,这里的诊断随后由三位放射学专家医师进行分级,这些医师至少有10年的实践经验。
- 为了弥补任何分级错误,评估集也由另一位专家检查。
Para_02
- 在评估基于人工智能的EGFR突变状态预测时,我们使用了来自中国成都的西部医院或广州医科大学第一附属医院的两个独立回顾性队列的晚期肺癌患者(III期或IV期)。
- 这两个队列的部分描述已发表48,49。
- 我们使用截至2014年的患者进行训练。
- 我们使用了2015年至2020年连续的患者进行5年生存率评估(队列A:西部医院;队列B:广州医科大学第一附属医院)。
- 我们使用Kaplan-Meier生存曲线比较了EGFR敏感突变患者与EGFR不敏感突变患者的生存率。
- 所有患者接受了标准化疗,如果他们进行了肿瘤组织活检并进行了EGFR基因测序以确定EGFR突变状态,则还接受了TKI治疗。
- 由三位高级肿瘤学家组成的评估委员会向计算机科学家提供了匿名且去识别化的队列A和队列B患者,用于基于人工智能的EGFR突变状态预测。
MINIM’s framework and implementation details
MINIM的框架和实现细节
错误!!! - 待补充
Para_02
- 其中 βt 是一个线性噪声调度器,定义为 βt=βmin+t×(βmax−βmin)/T , iT 是纯噪声输入。
- 然后,MINIM 学习使用 U-Net 架构和跨注意力机制来逆转扩散过程,这些机制应用于模态信息和描述信息。
Para_03
- 其中({\mu }_{\theta })是由输入文本和图像之间的交叉注意力的输出预测的,并且在不同的U-Net层中整合了交叉注意力机制。
- 在U-Net编码器和解码器的浅层中,MINIM在图像嵌入({U"}{{shallow"}}({i"}{t"}))和模态信息嵌入EBERT (m)之间应用交叉注意力,在U-Net编码器和解码器的深层中,MINIM在图像嵌入Udeep (it)和模态信息嵌入EBERT (d)之间应用交叉注意力。
- 交叉注意力函数定义为:
Para_04
- Q是由U-Net特征得出的,而K和V是由相应文本嵌入(EBERT(m)或EBERT(d))得出的。
Para_05
- 在推理过程中,图像的生成是通过从随机噪声 iT 开始的迭代去噪过程。
- ,
Para_06
- 其中 z ~ N(0,I) 并且 ({\sigma }{t"}^{2}={\beta }{t"})。这种顺序交叉注意力方法允许 MINIM 首先整合特定模态的信息,然后通过更详细的描述信息来优化特征。
- 通过连接模态和描述信息,该模型可以学会区分一般模态特征和文本中描述的具体图像细节,这可能有助于实现更准确和可控的医学图像生成。
Para_07
- 为了优化MINIM生成医学图像,我们使用了来自通用领域的预训练U-Net参数,并用四种不同的医学图像模态以及它们对应的文本描述微调了模型。
- 所有代码都是用PyTorch实现的。
- 微调实验是在配备了八个NVIDIA A100 GPU的高性能计算集群上进行的。
- 通过调整超参数、初始化和周期,我们提高了生成医学图像的能力。
- 所有输入图像是以512×512像素的分辨率重新缩放的,并且以每批128张的方式处理。
- 在这种配置下,微调一个模型大约需要10小时完成1000个训练步骤,或者4天完成10000个步骤。
- 我们从HuggingFace获得了用于SD管道(版本1.4)和CLIP(ViT-large)的U-Net模型权重。
- 我们的实现使用了‘transformers’和‘diffusers’库。
- 由于内置的安全检查器对医学提示的高误报率,我们在生成过程中禁用了它。
- 为了合成医学图像,我们采用了自由指导比例设置为4.0的分类器,并将推理步骤设为100,使用默认的噪声调度器,该调度器涉及扩散模型的伪数值方法。
- 最佳表现的模型被选为我们选择的生成模型(图1a)。
Comparative methods and ablation study
比较方法和消融研究
Para_01
- 我们比较了MINIM与AI社区最新的文本到图像生成模型,包括Imagen18、DALLE19、GigaGAN17和StyleGAN-T16。
- 他们在发布检查点上预训练的模型在我们的数据集上进行了微调。超参数的使用遵循他们原始论文中的说明。
- 我们进行了一项消融研究来选择MINIM的最佳超参数。
- 合成图像的质量通过所有数据集上的三个指标(FID、IS和MS-SSIM)的平均值进行评估(扩展数据表2)。
- 结果表明,随着训练步数的增加,合成图像的质量显著提高,在20,000次训练步骤时,FID下降到57.91,MS-SSIM改善到0.18,IS上升到5.89,这是我们进一步实验的选择。
- 我们还检查了不同模型初始化和图像分辨率的影响。
- U-Net和CLIP模型的随机权重初始化导致性能较差,这从更高的FID分数可以看出。
- 此外,生成较低分辨率的图像(256 × 256)会导致生成质量变差。
- 总之,通过全MINIM模型实现了最佳性能,该模型使用预训练权重,并在512 × 512图像分辨率下训练了20,000步。
- 这种配置展示了三个指标之间最好的平衡。
- 扩展数据表3呈现了使用不同配置在诊断各种眼疾时利用合成OCT图像的分类性能比较。
- 该表突出了随着训练步数增加,准确率的提升。
- 最初,原始SD模型的随机准确率为0.51。
- 经过10,000次训练步骤后,模型在准确性方面取得了实质性改进:CNV分类为0.82,DME为0.84,DRUSEN为0.88,正常情况为0.91。
- 此外,该表调查了不同模型初始化和图像分辨率对分类性能的影响。
- U-Net和CLIP模型的随机权重初始化以及较低分辨率的图像(256 × 256)导致的结果不如全MINIM模型。
- 全MINIM模型经过20,000步训练后表现出卓越的平均准确率0.94,几乎与其在真实数据上的表现相匹配。
- 这证明了MINIM模型在生成高质量合成图像方面的稳健性和可靠性,适用于准确的多类诊断。
RL implementation details
强化学习实现细节
Para_01
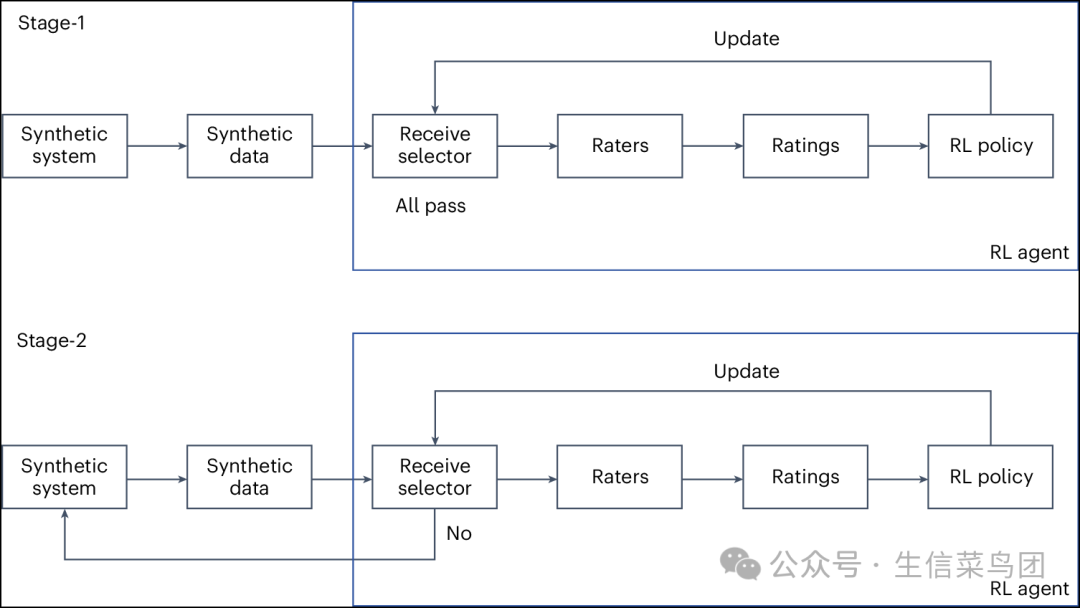
- 我们介绍了一个两阶段的RLHF框架,该框架使用合成数据迭代地训练一个代理(图6)。
- 该框架旨在利用合成图像和放射科医生评分的优点,从而生成高质量的数据,在现实世界数据稀缺、昂贵或难以获取的情况下尤其有益。
- 第一阶段涉及从MINIM模型生成合成图像。
- 生成的图像随后传递给一个接收选择器,该选择器作为分类模块运行。
- 在这个阶段,分类模块被设计为让所有实例无筛选地通过。
- 随后,人类评估者对合成数据进行评估,并将其评估编码为1到3之间的评分,其中1表示‘图像质量太低’;2表示‘图像质量符合标准,但与报告不符’;3表示‘图像质量符合标准并且总体上与报告一致’。
- 这些评分用于更新RL策略,从而完成这一阶段的闭环。
- 根据以下方程更新RL策略π:
Para_02
- R(s,a) 表示状态-动作对 (s,a) 的评分,α 是学习率。
Para_03
- 第二阶段引入了一个主动选择过程。同样,合成图像被输入到系统中,但这次,"接收选择器"分类模块根据分类结果决定传递哪些图像。
- 只有选定的图像被转发给人类评价者进行评估。未被选中的实例被丢弃。
- 人类评价者的评分更新了RL策略,类似于第一阶段,但使用了不同的学习率。
- 选择性过滤将策略更新集中在高质量图像上,这对于提高学习效率和效果至关重要。
- 更新后的策略表示为:
Para_04
- 其中 (\beta) 是与 ({\rm{\alpha }}) 不同的学习率,反映了两个阶段之间的不同数据分布。
- ({P"}{\rm{selected"}({x"}{i"})}) 是实例 ({x"}_{i"}) 被‘接收选择器’选中的概率;
- (P"}_{\pi }({as")) 是在当前策略 (\pi) 下状态 (s) 采取行动的概率;
- ({V"}_{\pi }(s)) 是策略 (\pi) 下状态 (s) 的价值函数。
- 在这个公式中,项 (R(s,a)-{V"}_{\pi }(s)) 表示时间差分误差,这是一种衡量结果与智能体期望之间的差异的方法50。
Implementations for downstream analysis
下游分析的实现
Para_01
- 为了评估合成数据在诊断中的有效性,我们选择了在训练集中出现次数超过五次的类别标签。
- 然后,我们使用Swin变换器模型对相应的图像和标签进行了多类分类诊断模型的训练。
- 首先,对于训练数据集中的每个文本描述,使用微调后的MINIM生成了与训练图像数量相等的合成图像,并将它们映射到文本对应的诊断结果。
- 这些图像随后在Swin变换器分类模型的训练阶段作为附加输入被纳入。
- 为了评估生成的诊断结果,我们使用了准确率、F1分数和AUC作为评估指标。
- 在进一步的扩展实验中,生成的合成图像的数量从100%,200%,500%,1,000%增加到了2,000%,并对每种变化的结果进行了报告。
Para_02
- 实验设置如下:使用合成数据生成每个图像模态的报告。文本描述频率超过10的被选中,连同它们对应的图像,形成真实数据集。
- 随后,这些文本描述用于生成合成图像,作为CLIP+GPT2基于图像描述模型训练阶段的附加输入。
- 接下来,使用独立的测试数据集生成相应的报告,并将这些报告与实际情况进行比较。
- 为了评估生成的报告与实际情况报告之间的差异,我们采用了已建立的自然语言生成指标。
- 这些指标包括BLEU(1-4g),CIDEr和ROUGE-L。
- 在进一步扩展实验中,生成的合成图像数量从100%,200%,500%,1,000%和2,000%不等,每种变化的结果都相应地进行了报告。
Para_03
- 在我们评估使用合成数据的自监督学习方法时,我们采用了孪生网络架构。
- 对于每种图像模态,我们将两种不同的合成图像增强引入到网络的不同分支。
- DenseNet-121的自监督预训练模型进行了线性探测,仅对分类层在100%,200%,500%,1,000%和2,000%的训练数据上进行微调,同时保持其他模型权重不变。
- 报告了使用真实数据与不同数量的合成数据以及仅使用真实数据的Top-1分类准确率(图4e)。
- ,
Data availability
Para_01
- 对发育和验证数据集的使用有限制,这些数据集是出于本研究的目的,在参与者允许的情况下使用的。
- 去标识化的数据可能应合理要求从相应作者处提供用于研究目的。
Code availability
Para_01
- 用于重现结果的代码可以在 https://github.com/WithStomach/MINIM 获取。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号