YOLOv11助力结肠镜检查:精准息肉检测新突破
原创
YOLOv11助力结肠镜检查:精准息肉检测新突破
原创
CoovallyAIHub
发布于 2025-03-06 09:56:34
发布于 2025-03-06 09:56:34

论文题目:Polyp detection in colonoscopy images using YOLOv11 论文链接:https://arxiv.org/pdf/2501.09051
一、摘要
直肠癌(CRC)是全世界最常见的癌症之一。它始于结肠内壁的息肉。要预防 CRC,就必须及早发现息肉。结肠镜用于检查结肠。一般来说,内窥镜顶端的摄像头拍摄的图像由专家手动分析。随着机器学习的兴起,各种传统的机器学习模型已被广泛使用。最近,深度学习模型因其在泛化和学习小特征方面的优势,在息肉检测中显示出更大的有效性。这些用于物体检测的深度学习模型可分为两种不同类型:单级和两级。一般来说,两阶段模型比单阶段模型具有更高的准确性,但单阶段模型的推理时间较短。因此,单级模型易于用于快速物体检测。YOLO是成功用于息肉检测的单级模型之一。由于其推理时间较短,它引起了研究人员的关注。迄今为止,研究人员已经使用了不同版本的 YOLO,随着版本的更新,模型的准确性也在不断提高。本文旨在了解最近发布的YOLOv11在检测息肉方面的有效性。我们分析了YOLOv11所有五个模型(YOLO11n、YOLO11s、YOLO11m、YOLO11l、YOLO11x)的性能,并使用Kvasir数据集进行了训练和测试。使用了两个不同版本的数据集。第一个版本是原始数据集,另一个版本是使用增强技术创建的。分析了使用这两个版本数据集的所有模型的性能。
二、引言
根据2022年全球癌症统计数据,直肠癌(CRC)是仅次于肺癌的第二大癌症死因。它是仅次于肺癌和女性乳腺癌的第三大常见癌症。截至2022年,新增病例达1,926,118例。这些数据表明了研究预防该疾病的重要性。
CRC起病于结肠内壁的息肉。因此,早期发现息肉是预防CRC的最佳方法。它常见于老年人群。大多数息肉是非癌性的,但其中一些会导致CRC。为了避免这种情况,医生必须手动检查息肉。医生会将带有摄像头的内窥镜插入结肠进行检查。这就是结肠镜检查。这是一个耗费大量人力和时间的过程。在结肠镜检查过程中,不同位置存在不同大小的息肉给医生带来了挑战。如果结肠上有皱纹,则更难将息肉与结肠本体区分开来。这些挑战有时会导致早期发现 CRC的失败。同时,这也是一项劳动密集型且成本高昂的工作。随着机器学习技术的发展,研究人员正试图实现多发性结肠炎检测过程的自动化。其主要思路是利用各种深度学习模型,直接从摄像头馈送的图像中检测息肉。
迄今为止,各种深度学习模型已被用于诊断CRC和其他癌症 。基于Faster RCNN、MRCNN、组合U-Nets和YOLO等模型的CNN模型在息肉检测中显示出了有效性。在本文中,我们试图了解最近发布的YOLOv11模型在息肉检测中的有效性。
三、相关工作
YOLO是最近在物体检测、分割和分类任务中最受追捧的算法之一。它由 Redmon等人于2016年首次提出。他们将分类问题的表述改为回归问题。该模型直接从图像像素预测类的边界框坐标和概率。与R-CNN和DPM等两阶段模型相比,这降低了模型的复杂性。YOLO的主要优势在于只需一眼就能快速识别物体。
各种版本的YOLO已被用于息肉检测。Guo等人将YOLOv3结构与主动学习相结合用于息肉检测。在将假阳性图像作为阴性样本进行多次再训练后,他们降低了假阳性率。他们在结肠镜检查视频上实现了1.5%的误报率。Cao等人利用特征提取和融合模块与YOLOv3的整合,检测出了小息肉。他们的模型融合了高级特征图和低级特征图的语义信息。Pacal等人在YOLOv3上使用了增强技术和迁移学习。他们还使用了SiLU激活函数和完全交叉联合损失函数来提高性能。该模型在SUN poly和PICCOLO数据库上进行了训练和测试。Lee等人引入了基于YOLOv4的多尺度网格,以有效检测小息肉。他们使用Autoaugment创建了不同尺度的图像,mAP达到了98.36。Wan等人在YOLOv5的骨干网络顶端添加了一个自注意模块。他们还使用马赛克方法进行数据扩增。通过这种方法,他们在准确度方面达到了Faster R-CNN的性能。
Qian等人试图通过使用生成对抗网络(CGAN)创建相似图像来解决数据集较小的问题。他们还对YOLOv4模型进行了修改,增加了扩张卷积和跳过连接,使用其扩展数据集的准确率达到了92.37%。Carrinho等人也使用YOLOv4 进行息肉检测。他们广泛分析了不同的正则化、数据预处理和数据增强方法。他们试验了FP32、FP16和INT8量化水平。Karamn等人使用ABC优化算法来优化YOLO模型的超参数。他们将F1分数提高了2%,将mAP提高了3%。Ghose等人使用了经过微调的YOLOv5模型。他们使用数据增强技术来增加图像数量,从而提高模型的性能。Mehrshad和ali使用了由5个不同的公开数据集组成的集体数据集,即Kvasir-SEG、CVC-ClinicDB、CVC-ColonDB、ETIS和EndoScene。他们使用YOLOv8进行息肉检测,取得了令人印象深刻的95.6%的精确度、91.7%的召回率和92.4%的F1得分。
在本文中,我们将使用YOLOv11进行息肉检测,它建立在YOLOv8模型的基础上,在COCO数据集上显示出更高的mAP,使用的参数减少了22%。我们将使用原始数据集和扩增数据集来研究5种不同YOLO模型的性能。
四、材料和方法
数据集描述
我们在工作中使用了Kvasir数据集。该数据集最初有1000张图像。图像是通过挪威Vestre Viken健康信托基金(VV)的内窥镜设备收集的。该数据集包含从720x576到1920x1072不同尺寸的注释图像。
数据预处理
在这项工作中,我们使用了roboflow提供的两个版本的Kvasir数据集。起初,我们使用的是不带增强功能的简单数据集(V6)。它有原始的1000张图像。它的大小仅调整为640*640。数据集分为训练数据(800张图片)、测试数据(100张图片)和验证数据(100张图片)。我们使用了roboflow的另一个版本的KVASIR seg数据集(V5),以进一步提高模型的性能。该数据集使用了增强功能。使用了图像翻转(水平和垂直)、90度旋转(顺时针和逆时针,上下颠倒)、裁剪(缩放0%到20%)、旋转(-15%到+15%)、剪切(水平和垂直±15°)、亮度变化(-25%到+25%)和模糊效果。增强后的图像总数为2600张。进一步分为训练数据集(2400张图像)、测试数据集(100张图像)和验证数据集(100张图像)。
YOLOv11的架构
最近发布的YOLOv11在架构上做了一些重要改进。它借鉴了之前版本的优点,并引入了一些架构上的改进。除了传统的物体检测任务外,它还可用于姿态估计和实例分割。YOLO模型由三个部分组成:骨干、颈部和头部。YOLOv11也遵循了这一原则。它建立在YOLOv8模型的基础上。
1)骨干:主干利用卷积层、空间金字塔池化-快速(SPPF)块和跨阶段部分空间保留(C2PSA)块从输入图像中提取特征。卷积层使用西格玛加权线性单元(SiLU)作为激活函数。SPPF块将图像分割成网格,并从网格中独立提取特征,利用最大池化处理多尺度图像。它还会进一步合并来自不同尺度的信息。该模块还有助于保持速度。
2)颈部:C2PSA模块使用两个位置敏感注意模块。PSA模块在处理输入张量的同时,还处理位置敏感注意。它有助于选择性地关注更精细的细节。该模块还能合并输入张量和注意力层的输出。对特征图的不同部分进行操作的两个PSA模块被连接在一起。
YOLOv11使用C3K2模块代替YOLOv8的C2F模块。C3K2模块在起点和终点有两个卷积层,中间有多个C3K模块。它采用较小的3*3内核来捕捉基本特征。它改进了早期版本的CSP(Corss Stage Partial)瓶颈。小内核系列用于处理独立的特征图,并在卷积后进行合并,从而改进了特征表示。
3)头部:由C3k2块和最终卷积层组成。它使用三个尺度的特征图进行多尺度预测——小尺度(P3)、中尺度(P4)和大尺度(P5)。这有助于检测不同大小的物体。最后,最终检测层会给出类别预测和边界框。
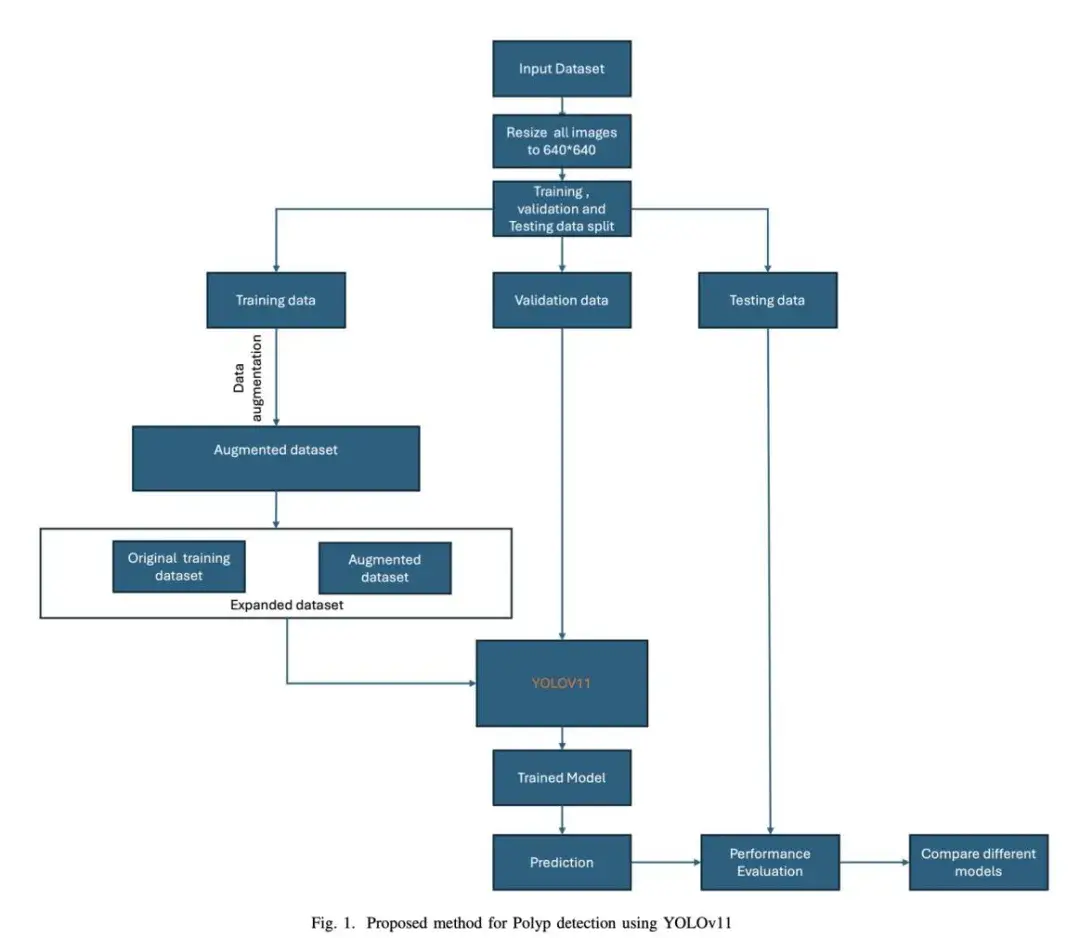
YOLOv11的主要优势在于以较低的复杂度提高了预处理能力,优化了速度,并可适应云平台和边缘设备等不同的部署场景。图 1 描述了利用YOLOv11进行息肉检测的拟议方法。
五、Coovally AI模型训练与应用平台
如果你也想要进行模型改进或模型训练,Coovally平台满足你的要求!
Coovally平台整合了国内外开源社区1000+模型算法和各类公开识别数据集,无论是YOLO系列模型还是Transformer系列视觉模型算法,平台全部包含,均可一键下载助力实验研究与产业应用。

而且在该平台上,无需配置环境、修改配置文件等繁琐操作,一键上传数据集,使用模型进行训练与结果预测,全程高速零代码!
动图封面
如果你想要另外的模型算法和数据集,欢迎后台或评论区留言,我们找到后会第一时间与您分享!
六、实验
使用矩阵
我们使用了三种不同的矩阵来评估模型的性能。

精确度表示实际检测到的息肉与检测到的息肉实例的比率。较高的精确度可以减少错误的息肉检测。另一方面,召回率是检测到的息肉与所有息肉实例的比率。这将向我们展示模型在所有实例中检测息肉的有效性。对于医疗案例,我们希望召回值相对较高,因为这有助于及时发现疾病。F1分数在这两者之间取得了平衡。它使用精确度和召回率为模型的整体性能打分。
实验装置
我们使用谷歌colab pro+ 平台进行所有实验。使用的是T4 GPU的运行类型。它使用Tesla T4 GPU和16 GB内存。它有一个英特尔(R)至强(R)CPU @ 2.20GHz处理器,磁盘空间为236 GB,内存为52 GB。
训练和测试
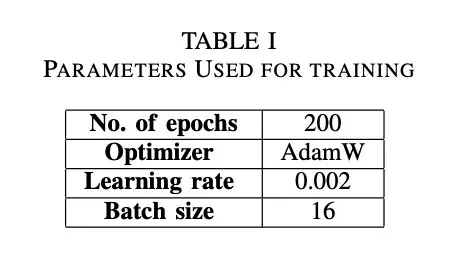
YOLO-v11有五种不同类型的模型,即YOLO11n、YOLO11s、YOLO11m、YOLO11l和YOLO11x。所有五个模型都在上一节详述的两个数据集版本上进行了训练。训练时间为200 epochs。早期停止训练的耐心时间为20 epochs。使用AdamW作为优化器。训练所用的训练参数详见表 1。对于 YOLO11x,为了避免谷歌实验室GPU内存的限制,使用了8个批次。
七、结果与讨论
我们首先对由1000张图像组成的原始数据集进行了实验。每个模型得到的结果见表 II。
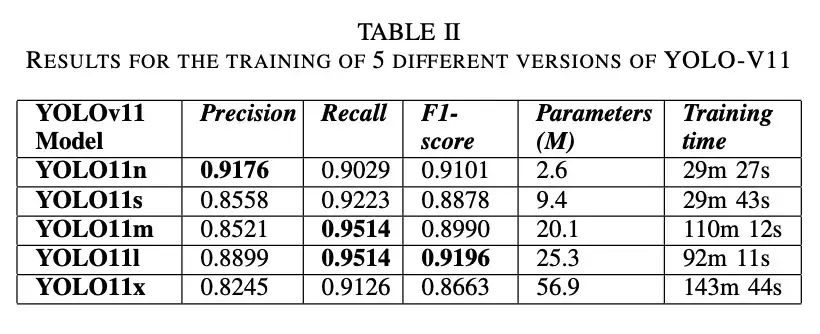
图 2 显示了使用原始数据集训练的YOLO模型的预测结果。
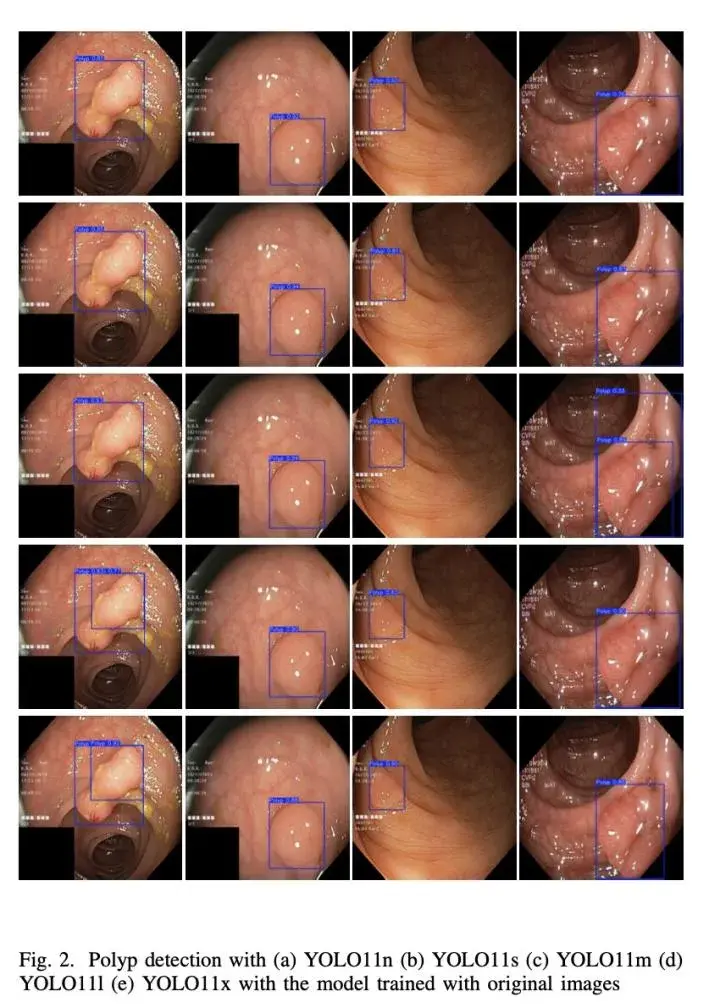
图 3 显示了YOLO11n在训练和验证中的不同损失。从表中可以看出,YOLO11l 的F1分数最高,略高于YOLO11n(0.95%)。YOLO11l的召回率高 4.85%,但精确度低2.77%。YOLO11l使用的参数约为YOLO11n的9倍,F1分数略高(0.95%)。YOLO11x的F1分数是所有五个模型中最低的。该模型性能较差的原因可能是可用来训练拥有5690万个参数的大型模型的数据集较小。这促使我们用更大的数据集来训练模型,从而提高模型的性能。这可以通过图像翻转、旋转、模糊等增强技术来实现。
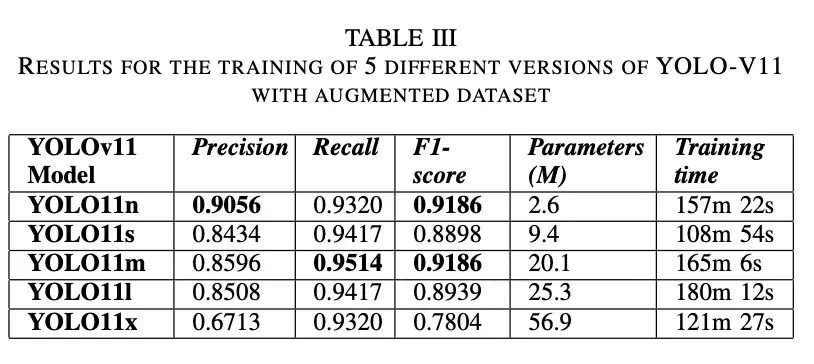
为此,我们使用了来自roboflow (V5)的KVASIR seg数据集。与之前的训练类似,我们进行了200 epochs为20的历时训练。表 III 详细列出了YOLOv11的所有五个模型使用扩展数据集获得的结果。YOLO11n的精确度(0.9056)和F1分数(0.9326)最高,但YOLO11m的召回分数(0.9514)最高。与使用原始图像训练的模型相比,YOLO11n的召回率和F1分数分别提高了3.22%和0.93%。YOLO11m模型的召回分数最高,为 0.9514,但精确度(0.8596)比YOLO11n低。YOLO11n模型在扩展数据集上的表现要好于原始数据集。图3显示了所有五个模型的预测结果。考虑到两个版本数据集的结果和使用的参数数量,我们可以说YOLO11n在息肉检测方面表现最好。
八、结论与未来展望
本文试图分析YOLOv11的五个模型对息肉检测任务的影响。我们使用了来自roboflow的两个不同版本的KVASIR seg数据集。第一个版本有1000张原始图像,第二个版本有2400张图像。第二个版本使用了增强技术来增加图像数量。我们测试了两个版本的数据集,以训练和测试5个不同版本的 YOLOv11(YOLO11n、YOLO11s、YOLO11m、YOLO11l、YOLO11x)。如果考虑到F1分数与所用参数数量的关系,YOLO11n在两个数据集中的表现都相当不错。在增强数据集中,召回率和F1分数分别提高了3.2%和0.93%,但精确度降低了1.3%。在医学成像中,提高召回率的同时保持合理的精确度至关重要,因此我们可以肯定地说,YOLO11n可用于息肉检测。它的轻量级和卓越性能使其成为所有五个模型中最适合用于云和边缘设备的模型。从实验中可以看出,该模型的性能可以通过增强来提高。未来,我们将探索各种优化技术来提高模型的性能。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号