JEDEC:从Llama到多模态,硬件如何推动人工智能的边界?

JEDEC:从Llama到多模态,硬件如何推动人工智能的边界?

数据存储前沿技术
发布于 2025-02-11 19:57:53
发布于 2025-02-11 19:57:53
全文概览
大语言模型(LLM)和多模态模型的崛起,AI对计算资源的需求呈指数级增长。从Llama-2到Llama-Next,模型的复杂性不断提升,从单一的文本处理扩展到视频、图像和音频的多模态处理。这种趋势不仅推动了算法和模型的创新,也对硬件基础设施提出了前所未有的挑战。本文深入探讨了AI硬件的发展趋势,特别是算力集群、内存扩展、网络带宽等关键技术的演进,揭示了AI系统设计中的核心问题与解决方案。通过分析Llama系列模型的硬件需求以及AI基础设施的优化方向,本文为读者提供了一个全面了解AI硬件技术发展的窗口,帮助理解未来AI技术突破的关键驱动力。
第一节:Llama系列模型的硬件需求
- Llama-2 65B的训练资源400 PF/s的计算能力、10 TB内存、4k GPU。
- Llama系列的多模态演进从Llama-2的纯文本处理,到Llama-Next的多模态支持(文本、视频、图像、音频)。
第二节:AI基础设施的挑战
- 网络带宽与延迟大规模GPU集群中的数据传输瓶颈。
- 内存与存储管理内存容量与计算能力的平衡。
- 故障容忍与容灾能力硬件故障对长时间计算任务的影响。
第三节:AI系统设计的复杂性
- 多维度优化计算、网络、内存、封装、连接性、散热等领域的协同创新。
- 软硬件协同设计AI系统性能提升的关键。
第四节:内存技术的创新
- 分层内存架构HBM与外部DRAM的结合,优化性能与容量的平衡。
- Fabric Attached Memory通过MemLink和网络技术实现内存共享与扩展。
第五节:未来AI硬件的发展方向
- 内存技术高性能、大容量、高可靠性的需求。
- 系统设计软硬件协同优化的重要性。
- 互连技术高速连接与数据传输的关键作用。
阅读收获
- AI硬件需求的复杂性了解AI模型对计算资源、内存、网络带宽等多方面的需求,以及这些需求如何推动硬件技术的创新。
- 分层内存架构的优势认识到分层内存设计如何在高性能与高容量之间取得平衡,满足大规模AI计算的需求。
- 软硬件协同设计的重要性理解AI系统性能的提升不仅依赖于硬件升级,还需要软件与硬件的紧密配合。

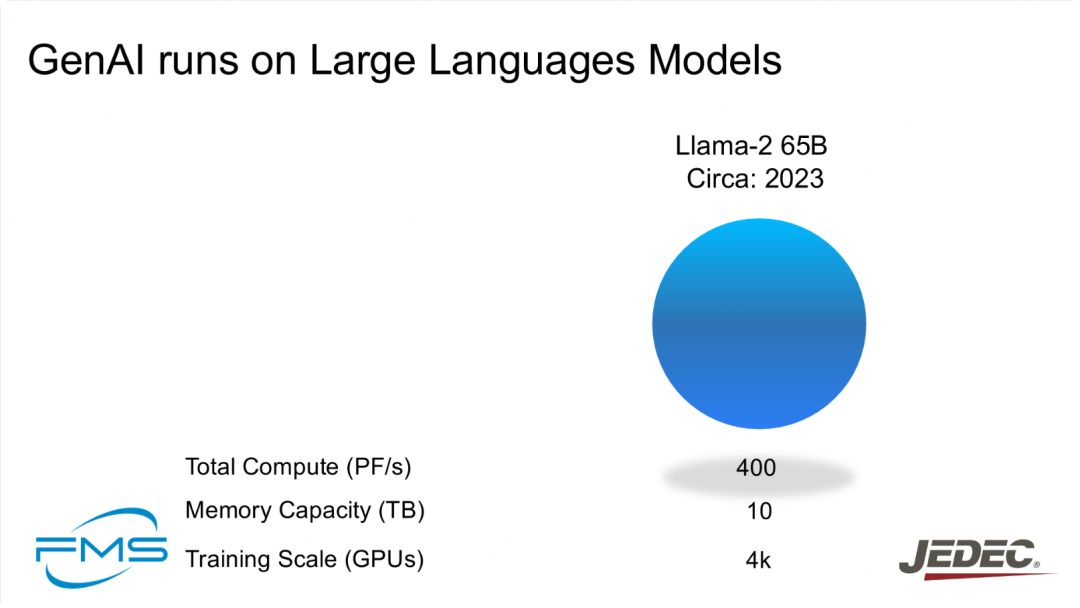
2023 年 训练 Llama-2 65B 时的硬件资源。 计算指标:
- 总计算能力(PF/s):400
- 内存容量(TB):10
- 训练规模(GPU数):4k
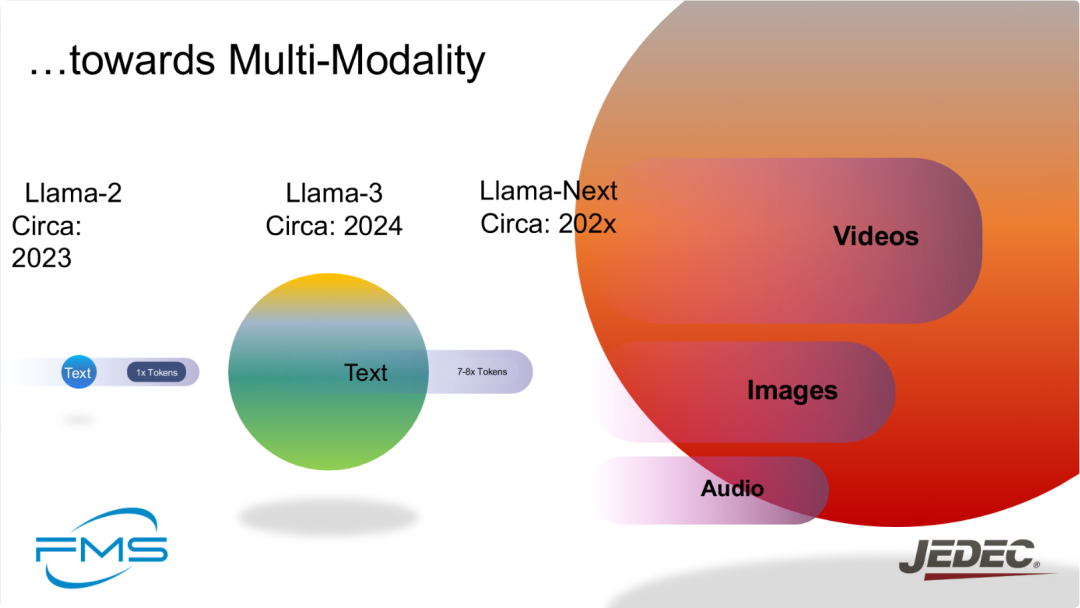
图展示了Llama系列模型在向多模态模型转变的趋势。从Llama-2到Llama-Next,模型的能力逐步扩展,从单一的文本处理,发展到同时处理视频、图像和音频等多种输入类型。
不同版本的Llama模型如何朝着多模态发展,具体包括:
- Llama-2(2023年左右):仅支持文本,1倍Tokens
- Llama-3(2024年左右):主要支持文本,7-8倍Tokens
- Llama-Next(预计202x年):支持多种模式,包括文本、视频、图像和音频。
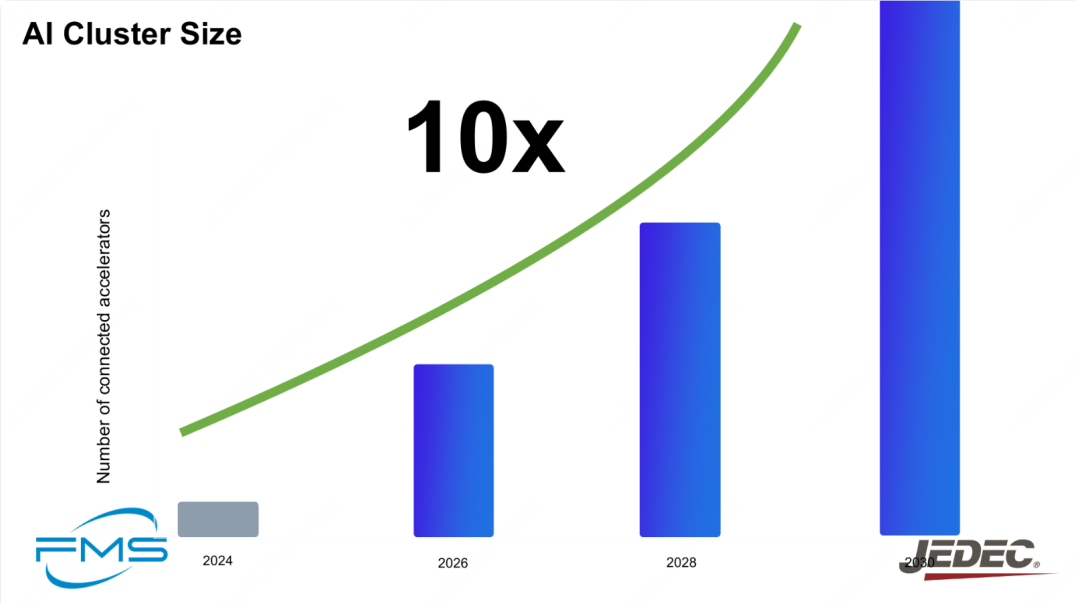
LLM/AGI 运动将直接推动算力集群规模的快速增长。
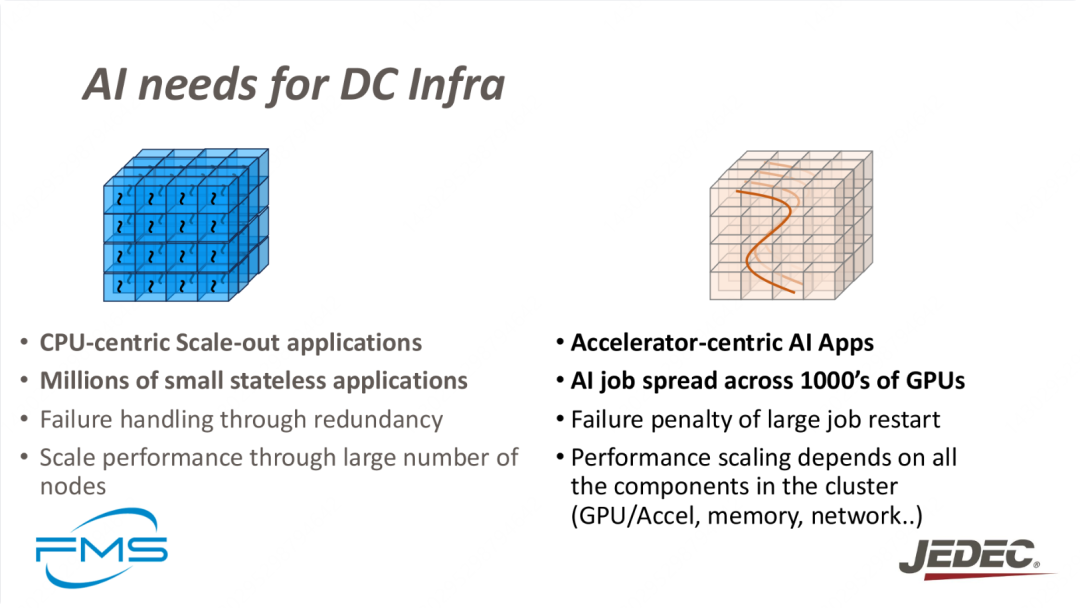
对比了以CPU和以加速器为中心的AI基础设施需求。CPU中心化的应用侧重于扩展和冗余处理,而加速器中心化的AI应用则依赖于大量GPU,且性能扩展需要考虑所有硬件组件的协同工作。
左侧(CPU中心化应用):
- 以CPU为中心的横向扩展应用
- 数百万个小型无状态应用
- 通过冗余处理故障
- 通过大量节点扩展性能
右侧(加速器中心化AI应用):
- 以加速器为中心的AI应用
- AI作业分布在数千个GPU上
- 大作业重启的失败惩罚
- 性能扩展依赖于集群中所有组件(GPU/加速器、内存、网络等)
深入理解智算集群性能扩展带来的挑战
1. 网络带宽和延迟问题
- 挑战随着计算任务变得越来越复杂,数据在集群中节点间的传输量也急剧增加。网络带宽和延迟成为关键因素,影响了GPU之间的同步与数据传输效率。
- 原因当任务分布在数千个GPU时,网络的带宽和延迟将直接影响到任务的执行效率,尤其是在处理大量数据时,低带宽和高延迟的网络会成为瓶颈,导致性能下降。
2. 内存和存储管理
- 挑战随着数据量的增大和计算任务的复杂化,内存和存储管理成为数据中心面临的一个核心问题。如何确保每个计算节点具有足够的内存,以支持高效的数据处理和存储,是一项艰巨的任务。
- 原因内存的扩展不仅仅是增加内存容量,还需要确保数据能够高效地存储和读取。如果内存不能够快速响应请求,或存储系统无法高效地管理海量数据,都会影响整体系统的性能。
3. 故障容忍和容灾能力
- 挑战数据中心中的硬件(如GPU、内存等)可能会发生故障,这对AI任务的执行产生重大影响。如何设计一个有效的容错机制,确保即使部分硬件出现故障,整体任务仍能继续进行,是数据中心设计中的一个关键挑战。
- 原因由于AI任务通常需要长时间的计算,单个节点的故障可能导致整个任务的中断。故障恢复和冗余机制必须设计得足够健壮,以保证系统的高可用性。
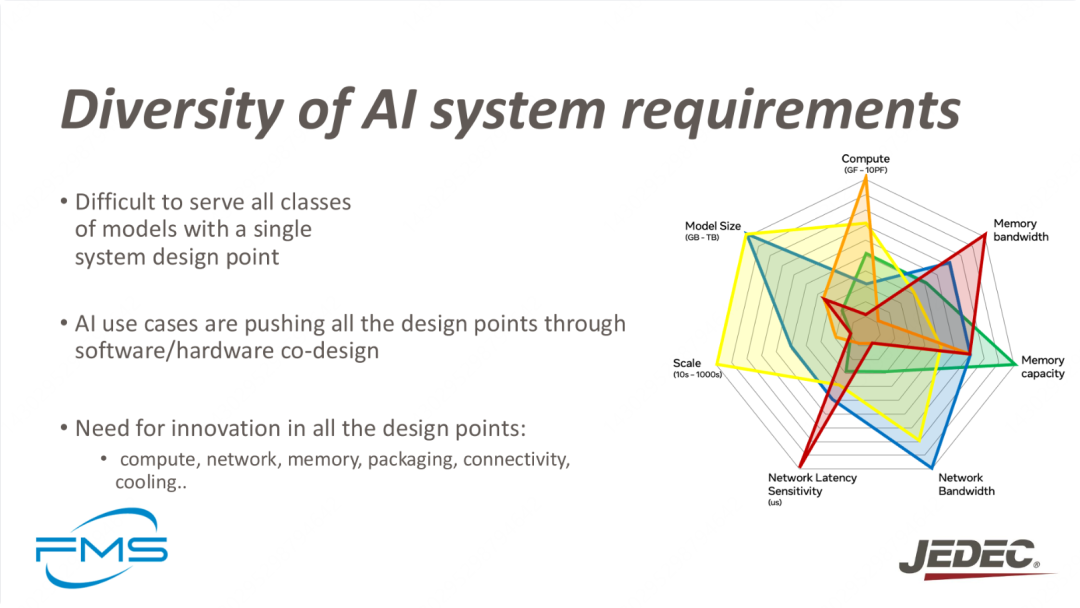
右图用颜色区分不同模型的属性雷达图。强调了AI系统设计的复杂性,尤其是在面对多种类型AI任务时,单一的设计点往往难以满足所有需求。因此,在AI硬件的设计和部署过程中,必须在计算能力、网络带宽、内存、散热等多个维度进行创新,推动软硬件的协同设计,以实现更高效、更可扩展的AI系统。
- 单一的系统设计无法满足所有种类AI模型的需求。AI模型有各种不同的特征(如计算能力、内存需求、模型规模等),因此需要为不同类型的模型设计定制化的硬件架构和系统。
- AI的多样化应用推动了软硬件的协同设计。AI系统的优化不仅仅依赖于硬件的升级,还需要通过软硬件之间的紧密配合来共同推动系统性能的提升。AI应用场景不断发展,推动硬件和软件的不断创新和调整。
AI系统的设计不仅仅是单一维度的优化,而是需要在多个领域进行创新,包括:
- 计算(Compute)不断提升计算能力,以满足AI任务的需求。
- 网络(Network)提升网络带宽和延迟,尤其是随着计算规模扩大,数据传输的需求也随之增加。
- 内存(Memory)内存容量和带宽的提升,支持大规模数据处理。
- 封装(Packaging)合理的硬件封装设计,优化空间和散热。
- 连接性(Connectivity)确保各硬件组件之间的高效通信。
- 散热(Cooling)随着硬件性能的提升,散热成为了重要的技术挑战。
内存容量与带宽在AI加速器和模型中的重要性,特别是随着计算能力和模型规模的不断增长,内存需求的提升。具体内容包括:
1. 加速器和模型的规模不断增加
- 内存需要与计算能力共同增长随着加速器的计算能力不断提升,相应地,内存的容量也需要增加,以满足大规模计算需求。
- 模型尺寸的增大,推动内存容量需求AI模型的规模不断扩大,特别是在深度学习领域,模型的参数和数据集需要更大的内存来进行处理。越来越复杂的模型(如大规模语言模型、图像处理模型等)需要更多的内存来存储和计算数据。
2. 集成内存创新
- 保持平衡设计为确保计算与内存之间的平衡,硬件设计中必须考虑到计算和内存之间的协调。集成内存的创新旨在解决传统内存架构与计算能力不匹配的问题。
- 提供高可靠性内存不仅要具备大容量,还需要在高速数据处理过程中保持高可靠性,以避免数据损坏或丢失。
- 降低功率密度随着内存和计算能力的提升,硬件的功耗问题也日益突出。集成内存技术旨在提供更高效的内存解决方案,以降低功率密度,避免因过度散热导致的性能下降。
3. 为加速器设计的分层内存
- 分层内存随着AI加速器(如GPU、TPU等)计算能力的提升,单一的内存架构可能无法满足性能需求,因此需要采用分层内存的设计方案。分层内存将内存分为多个层次,以便在不同的内存层次中根据任务需求提供不同的存取速度和容量。这样可以平衡高性能和高容量之间的差异,确保计算任务高效执行。
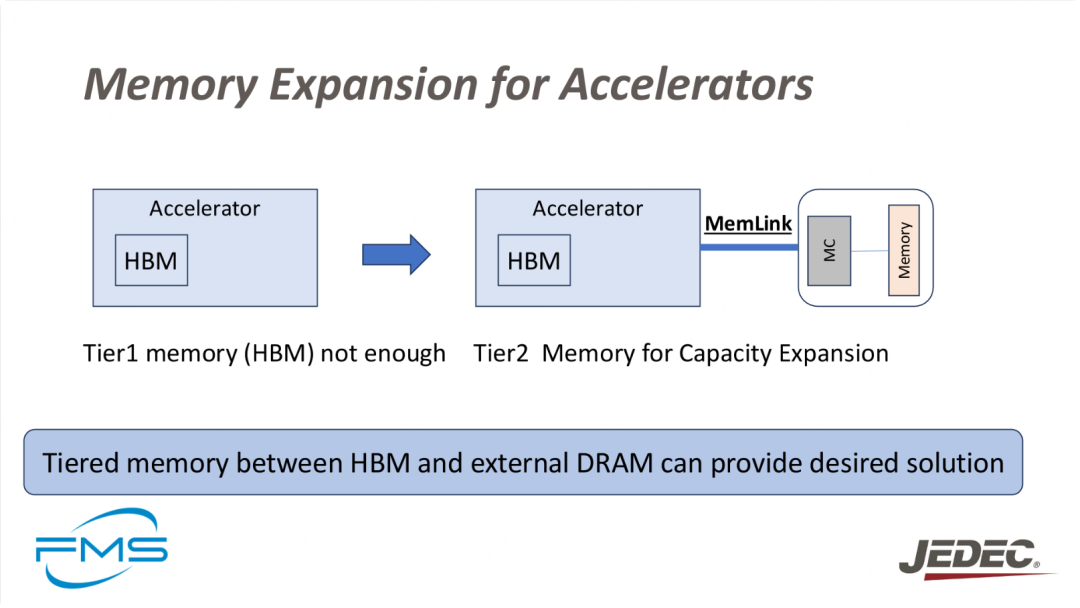
1. 内存扩展的需求
- Tier1内存(HBM)不足HBM(High Bandwidth Memory)是目前加速器常用的内存类型,它提供了较高的带宽,但在某些高性能AI模型或应用中,HBM的内存容量可能无法满足需求。
- Tier2内存用于容量扩展为了应对内存容量不足的问题,可以采用Tier2内存(例如外部DRAM)进行扩展。Tier2内存提供更多的存储空间,但访问速度较HBM慢,因此需要通过优化访问机制来平衡性能。
2. 分层内存架构
- 通过MemLink连接加速器的HBM和外部DRAM,形成分层内存架构。这种架构允许加速器在需要更多内存时,可以无缝地扩展到外部内存(Tier2内存),从而满足大规模计算任务的需求。
3. 分层内存的优势
- 提供容量扩展分层内存架构能够为加速器提供更多的内存空间,以支持更大的AI模型和数据集。
- 优化性能与容量的平衡通过在高速HBM和容量更大的外部DRAM之间建立平衡,既保证了内存容量的扩展,又能最大程度减少性能损失。
Note
需要指出的是,这里的MemLink 泛指实现内存互联的多种技术,并不是特定的传输协议,如NVLink。

左侧图:通过主机CPU的内存控制器进行Tier2内存扩展
- 结构在这种方案中,加速器(如GPU)通过MemLink与主机CPU进行连接。加速器内部使用HBM(高带宽内存)来满足高速计算需求,而Tier2内存(通常是DRAM)则通过主机CPU的内存控制器(MC)进行连接。
- 通信路径通过如PCIe、CXL、NVC2C、Infinity Fabric等高速通信协议,将CPU与加速器之间的内存连接起来。MemLink技术在这里发挥了重要作用,它确保了加速器和CPU内存之间高效的带宽和低延迟通信。
- 应用这种方案适用于加速器需要更多内存容量的情况,能够通过主机CPU提供的额外内存来扩展计算资源,满足大规模计算的需求。
右侧图:通过扩展卡的内存控制器进行Tier2内存扩展
- 结构这种扩展方案中,内存通过专用的扩展卡进行连接。加速器仍然使用HBM,而Tier2内存通过扩展卡内的内存控制器进行连接。扩展卡的内存控制器负责管理连接到外部内存(如DDR/LPDDR、CXL等)的内存资源。
- 通信路径MemLink与扩展卡的内存控制器连接,使加速器能够直接访问扩展卡内的内存,从而实现内存的进一步扩展。
- 应用这种方案通常适用于需要大规模扩展内存的应用,特别是当加速器本身的内存容量不足以支撑计算任务时,通过扩展卡提供更多的内存容量。
Note
右侧基于DDR/LPDDR/CXL等,实现的内存互联,类似支持GPU直通访问的内存扩展,在实际应用中还比较少,绝大多数都还需要和CPU内存做交互。

图讲解了Node Native MemLink架构中的关键技术要素:
- 互连技术:如NV-C2C和CXL等技术可以为加速器提供更多内存,支持高带宽的数据传输。然而,为了避免在CXL中使用更多的通道,需要提升数据传输速度(PCIe Gen7 已发布)。
- 内存控制器:由于对带宽的高需求,内存控制器需要支持更多的内存通道,确保数据传输不会成为瓶颈。
- 内存模块:内存模块的设计需要在满足高速度和大容量的同时,降低功耗并提高可靠性。这是为了适应现代计算中对内存高性能和高可靠性的需求。
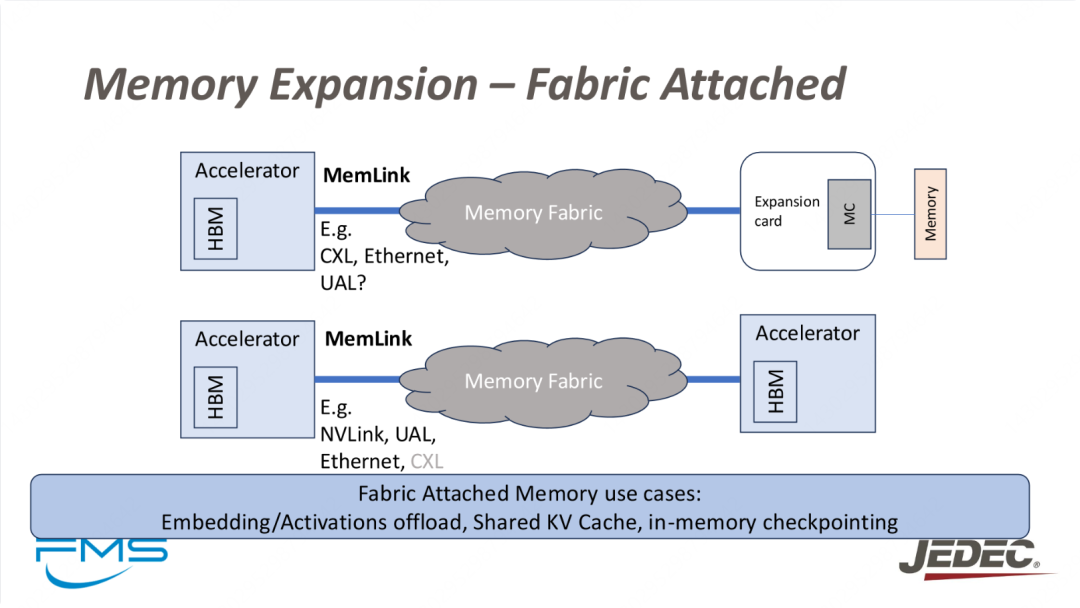
图展示了Fabric Attached Memory在加速器内存扩展中的应用。通过使用MemLink和网络技术(如CXL、Ethernet、NVLink等),加速器可以连接到更大的内存池,并实现内存共享。这种方案特别适用于需要大量内存支持的AI计算任务,如深度学习模型训练和推理等。在此架构下,还可以实现嵌入层和激活数据的卸载、共享缓存和内存检查点等功能,从而提高内存利用率和计算效率。
- 嵌入和激活卸载(Embedding/Activations offload):在AI和深度学习中,嵌入层和激活函数往往需要大量内存,利用Fabric Attached Memory技术可以将这些数据卸载到外部内存,减轻加速器内存压力。
- 共享KV缓存(Shared KV Cache):在分布式计算和机器学习中,共享键值缓存(KV Cache)可以提高多个加速器之间的数据共享和处理效率,Fabric Attached Memory可以提供这样的共享内存。
- 内存检查点(in-memory checkpointing):在长时间计算过程中,定期将计算结果保存到内存中,以防止数据丢失,确保系统恢复。这种内存扩展技术能有效支持高性能计算中的内存检查点功能。
图强调了AI技术发展中的几个关键领域和行动呼吁:
- 内存技术:AI的进步需要更高性能、更大容量以及更高可靠性的内存技术。这些需求推动了内存技术的持续创新,尤其是在处理大规模数据和复杂计算时。
- 系统设计:AI系统不仅需要先进的硬件,还需要软件与硬件的协同设计。系统架构的优化对于提升AI的计算效率至关重要。
- 互连技术:随着计算需求的增加,更高的连接速度、径向和连接性成为提升性能的关键因素。高速互连技术能够支持更高效的数据传输,特别是在多加速器协同计算和大规模计算集群中。
Deep Dive
- 未来AI模型的复杂性将如何进一步推动硬件技术的创新?
- 在分层内存架构中,如何更好地优化HBM与外部DRAM之间的数据传输效率?
- 随着AI应用场景的多样化,如何设计更加灵活且高效的AI硬件系统?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-02-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号