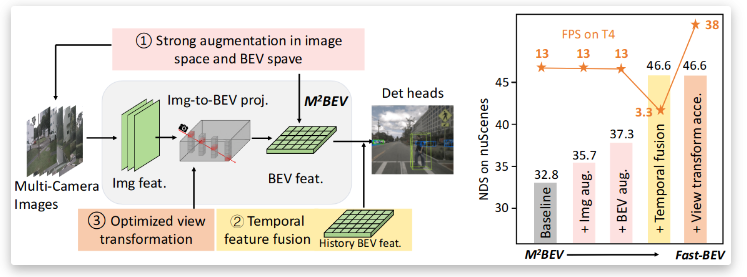
Fast-BEV 简单快速的纯视觉全卷积BEV框架


Fast-BEV 是一种用于自动驾驶系统的先进技术,它专注于提高多摄像头图像到 3D bounding box 和速度预测的实时性能,本文记录相关内容。
简介
自动驾驶系统分为三个层级:感知层,决策层,执行层,快速且准确的感知系统,是自动驾驶技术的关键。
目前,基于纯相机的BEV视图展现出了不同于传统方法的巨大潜力:3D感知能力强,成本低,既可单独表达,也可同时处理多个任务。但目前大多数BEV方案占用资源大,或性能不佳。基于这些缺陷,一种Fast BEV框架被提出,它能够在车载芯片上执行更快的BEV感知。该算法可使Fast BEV在快速部署,快速运算的同时,还可以保证高性能。
近两年,BEV感知在自动驾驶领域里发展的如火如荼,从而受到了越来越多专业人士的关注。不过,大多数现有的BEV技术,例如基于transformer的BevFormer、基于深度转换的BevDepth等等,均对算力的要求颇高,尤其对于车载芯片Xavier, Orin, Tesla T4等来讲,多少有点吃不消。在Fast-BEV这篇论文论文中,作者提出了一种对车载芯片友好的且简单轻便的BEV新框架。
论文: https://arxiv.org/abs/2301.12511
代码: https://github.com/Sense-GVT/Fast-BEV
背景
对于自动驾驶来说,一个快速准确的 3D 感知系统是很有必要的。经典方法,例如:Pointpillars、Voxlnet等,强烈依赖基于激光雷达点云提供的准确3D信息。然而,激光雷达传感器通常要花费数千美元,为此在汽车上应用起来成本过高。最近基于纯相机的鸟瞰图 (BEV) 方法显示出了巨大潜力,它的3D感知能力不仅令人印象深刻,如图1所示,而且还可以极大地降低经济成本。BEV方法基本上遵循着如下范式:首先将多目环视相机的图像特征从二维图像空间转换至汽车坐标系下的三维BEV特征空间,然后采用特定的head结构应用于统一的BEV特征,以便执行定制的3D任务,统一的BEV特征可以高效且灵活的执行单个任务或同时执行多项任务,例如:3D 检测、分割等多种任务。
经典3D感知算法常需要依赖激光雷达传感器,通常价格十分昂贵。相比之下,基于纯相机的BEV途径3D感知能力强,成本低。BEV视图的转换途径为:将多摄像机的2D视图基于汽车为中心坐标,形成3D鸟瞰视图。现有的方法为基于查询的 transformation 方法和基于深度变换的方法。
这些方法通常需要难以加速的体素池操作,在不支持CUDA加速推理库的芯片上难以运行,并且运算耗时大。基于这些结构,本文提出了Fast-Ray转换,借助于“查找表”和“多视图到一个体素”操作,将BEV转换加速到一个新的水平。基于Fast Ray变换,论文进一步提出了Fast BEV,这是一种更快、更强的全卷积BEV感知框架,无需昂贵的视图transformer或深度表示。所提出的快速BEV包括五个部分,Fast-Ray变换、多尺度图像编码器、高效BEV编码器、数据增强和时间融合,这些共同构成了一个框架,赋予Fast BEV快速推理速度和有竞争力的性能。
方法
Fast BEV共分为5个模块:Fast-Ray转换器,多尺度图像编码器,高效BEV编码器,数据增强,时态融合变换器。
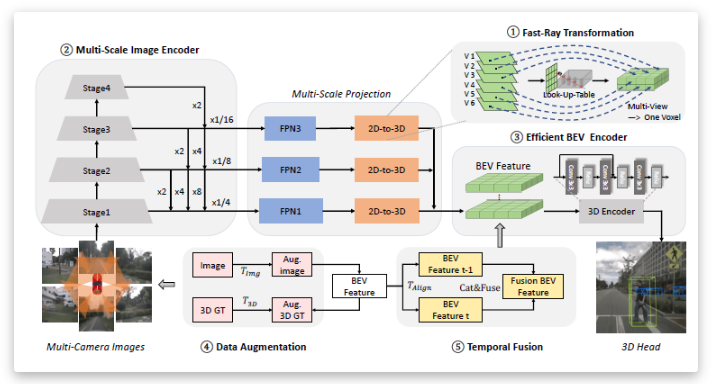
1.Fast-Ray转换器: 视图转换是将特征从2D图像空间转换到3D BEV空间的关键组件。这种方式优点是,一旦获得了相机的内在/外在参数,就可以很容易地知道2D到3D的投影。基于这一假设,本文从两个角度进一步加速该过程:预计算投影索引(查找表)和密集体素特征生成(多视图到一个体素)。
一般来说,从图像特征从二维图像空间投影至三维BEV体素空间会占据着大量的耗时,为此作者提出了两种优化手段来加速这个模块的计算:一是预计算一个固定的投影索引,构建出一个LUT查询表;二是将所有的相机图像特征一次性投影至同一个密集的BEV体素空间下,从来避免复杂的聚合操作。
在标定获取到每个相机的内参以及相机至车辆坐标系的外参后,可以很容易的计算出二维图像特征空间至三维BEV体素空间之间的投影关系,因为不像之前的DevDepth有依赖于深度预测结果和BevFormer的transformer模式造成的投影关系变动,为此可以把这种投影索引直接写死并存储下来,而不用每次推理时都重新计算索引。如图3所示,对三维BEV体素空间下的每一个体素,直接构建其与每一个相机索引及对应相机图像特征二维坐标系(x,y)之间投影关系。
在BevFormer中,每一个相机图像特征都会各自投影至一个稀疏的BEV体素空间里,为此便需要一个复杂的聚合操作来将多个不同的BEV体素空间集成到一起,见图4a所示。而Fast-BEV为了避免聚合这种复杂操作,则是将所有相机图像特征直接投影至同一个密集的BEV体素空间下,见图4b所示。这个加速投影便是通过上面构建的LUT表来完成的,多视图相机图像特征投影至同一个体素空间的过程如图所示。

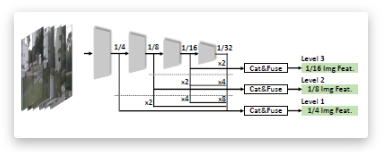
2.多尺度图像编码器: 使用 fast-ray 转换器可将多张图像输入到图像编码器中,最终得到4级特征,然后在图像编码器输出部分采用了三层多尺度FPN结构。FPN的每一层通过1*1卷积,将以下层上采样后的相同大小的特征进行融合,最终得到F1=4;F1=8;F1=16 3级综合图像特征作为输出。
如下图所示,6张多目环视相机图像 𝐼∈𝑅^{𝐻×𝑊×3}输入给 ResNet-50 网络提取多尺度 backbone 特征,并后接了3层特征金字塔结构,其中每层特征金字塔层均融合了当前层特征与深层特征上采样来的特征,最终获得了 𝐹_{1𝐹_{1/4}_{1/𝐹_{1/8}{1/1𝐹_{1/16}度图像特征输出。 在得到多视图相机图像的多尺度图像特征 𝐹={𝑅^{𝑁𝐹={𝑅^{𝑁×𝑊_𝑖×𝐻_𝑖×𝐶}|𝑖∈[4,8,16]}变换,将多尺度图像特征 投影至多尺度BEV特征空间,得到: 𝑉={𝑅^{𝑋_𝑖×𝑌_𝑖×𝑍×𝑉={𝑅^{𝑋_𝑖×𝑌_𝑖×𝑍×𝐶}|𝑋_𝑖,𝑌_𝑖∈[200,150,100]}
3.高效BEV编码器: BEV作为4D张量需要大量计算,可使用三位缩减操作加快其运算速度,从而避免3D卷积占用大量内存。此外,BEV编码器的块数和3D体素分辨率的大小对性能影响相对较小,但占用了较大的速度消耗,因此更少的块和更小的体素分辨率也更为关键。
BEV 特征𝑉是一个4维的向量,如果使用时间融合操作将特征堆叠在一块,会使得BEV编码模块产生大量的计算。为了加速BEV编码的计算,通常需要使用S2C、MSCF、MFCF三种算子来降低计算量。S2C操作用于将4维的体素向量 𝑉𝑉∈𝑅^{𝑋×𝑌×𝑍×𝐶}BEV向量 𝑉∈𝑅^{𝑋×𝑉∈𝑅^{𝑋×𝑌×(𝑍𝐶)}耗内存的3D卷积算子。因为BEV特征本身就是一个多尺度的,即 [200,150,100][200,150,100]样的方式,把低尺度的BEV特征放大到同一尺度 200×200 ,然后再200×200&MFCF 操作在通道维度上进行多尺度多帧特征连接,即
$$ 𝐹𝑢𝑠𝑒(𝑉_𝑖|𝑉_𝑖) ∈ 𝑅^{𝑋_𝑖×𝑌_𝑖×(𝑍𝐶𝐹_{𝑠𝑐𝑎𝑙𝑒𝑠}𝑇_{𝑓𝑟𝑎𝑚𝑒𝑠})} ⇒ 𝑉_𝑖 | 𝑉_𝑖 ∈ 𝑅^{𝑋_𝑖×𝑌_𝑖×𝐶_{𝑀𝑆𝐶𝐹 \& 𝑀𝐹𝐶𝐹}},𝑖∈3−𝑙𝑒𝑣𝑒𝑙 $$
从而可以将原有的高参数量融合至低参数量,并最终加速BEV编码的计算时间。
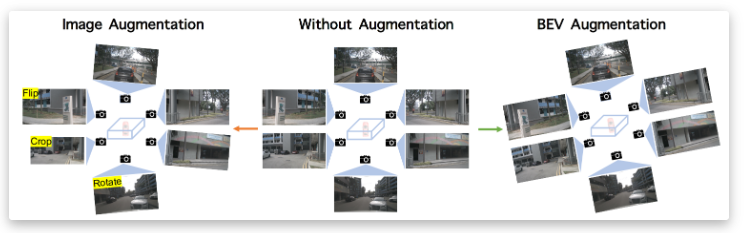
4.数据增强: 本研究为图像空间和BEV空间添加了数据增强。如果对图像应用数据增强,还需要改变相机固有矩阵。对于增强操作,基本上遵循常见的操作,例如翻转、裁剪和旋转。BEV增强变换可以通过相应地修改相机外部矩阵来控制,增强后,需要对3D gt框进行同步变更,而且还需要修改对应的外参矩阵。
5.时态融合变换器: 本研究将历史帧引入到当前帧中以进行时间特征融合。通过空间对齐操作和级联操作,将历史帧的特征与当前帧的对应特征融合。时间融合可以被认为是帧级的特征增强,在一定范围内较长的时间序列可以带来更多的性能增益。
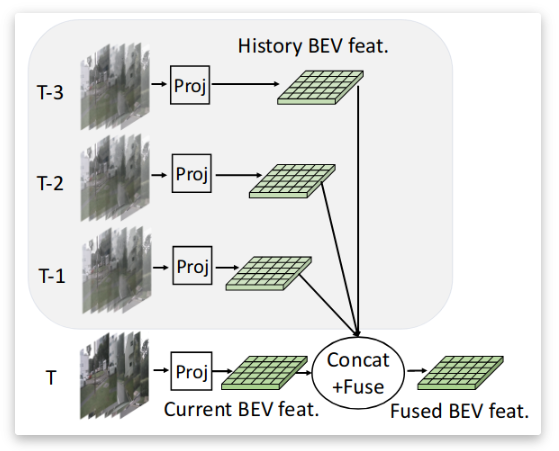
和主流方法的Latency进行比较,结果如下图:
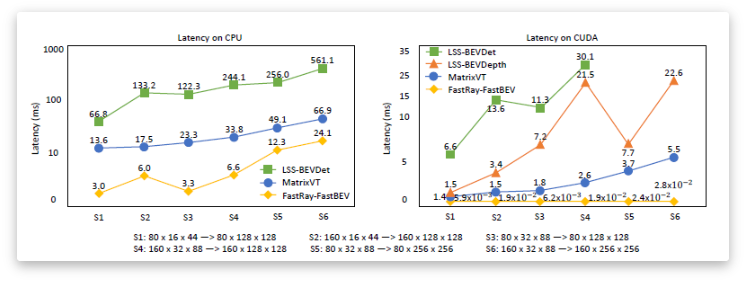
结论
经测试,Fast BEV有着以下优势:可在使用低计算能力芯片进行部署,可在非GPU芯片上部署,扩展能力强。随着技术的发展,许多自动驾驶制造商已经开始放弃激光雷达,只使用纯视觉进行感知。在实际开发中,模型放大或数据放大通常基于从真实车辆收集的数据,以利用数据潜力提高性能。在这种情况下,基于深度监控的解决方案遇到瓶颈,而Fast BEV不引入任何深度信息,可以更好地应用。
原始论文
参考资料
- https://arxiv.org/abs/2301.12511
- https://zhuanlan.zhihu.com/p/606891036
- https://cloud.tencent.com/developer/article/2317485
- https://github.com/Sense-GVT/Fast-BEV
文章链接:
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-9-5,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号