EFFICIENCY IN THE COLUMBIA DATABASE QUERY OPTIMIZER(翻译)介绍

EFFICIENCY IN THE COLUMBIA DATABASE QUERY OPTIMIZER(翻译)介绍

jhonye
修改于 2023-09-27 17:21:36
修改于 2023-09-27 17:21:36
摘要
查询优化是数据库系统可以实现显著性能提升的领域。现代数据库应用程序需要具有高度可扩展性和效率的优化器。尽管在这些领域已经做出了十多年的努力,但优化器研究的最新成果仍然无法满足业务的需求。我们 Columbia 项目的目标是为查询优化提供高效且可扩展的工具,特别是针对复杂查询和新的数据模型。本论文的主要关注点是效率。
本论文描述了 Columbia 查询优化器的设计和实现,该优化器在不牺牲可扩展性的情况下实现了显著的性能提升。基于级联优化器框架的自顶向下优化算法,Columbia 通过精心重新设计搜索空间结构和搜索算法,简化了自顶向下优化器的设计。实现了两种剪枝技术,可以实现显著的性能改进。Columbia 还通过添加友好的用户界面和广泛的跟踪支持来提高可用性。在关系数据模型上进行了 Columbia 优化器的实验。通过将 Columbia 与级联等其他自顶向下优化器进行比较,可以展示其在效率改进方面的结果。
前言
研究的动机
尽管查询优化已经是一个研究课题超过15年了[SAC+79],但查询优化器仍然是数据库系统中最大且最复杂的模块之一,使得它们的开发和修改成为困难且耗时的任务。现代数据库应用程序[ZdM90]的需求进一步增加了复杂性,例如决策支持系统(DSS)和在线分析处理(OLAP),大型数据仓库,复杂对象(例如多媒体数据库,万维网和地理信息系统),以及处理新的评估技术(例如并行和分布式评估)。这些新的应用领域反过来需要新的数据库技术,例如新的查询语言和新的查询处理技术,这些技术与传统的事务处理应用程序中的技术相当不同。
在过去几年中,已经开发了几代商业和研究查询优化器,为优化器的可扩展性和效率做出了贡献。
- 最早的可扩展优化器技术(我们称之为第一代)始于大约十年前,意识到了对新的数据模型、查询类别、语言和评估技术的需求。这些项目包括Exodus [GrD87]和Starburst [HCL90]。它们的目标是使优化器更模块化和更易于扩展。它们使用的技术包括组件分层、基于规则的转换等。然而,这些努力存在一些缺点,例如扩展的复杂性、搜索性能以及对面向记录的数据模型的偏好。
- 第二代可扩展优化器工具,如Volcano优化器生成器[GrM93],增加了更复杂的搜索技术,更多地利用物理属性来指导搜索,并更好地控制搜索策略,以实现更好的搜索性能。尽管这些优化器在某种程度上是灵活的,但仍然很难和复杂来进行扩展。
- 第三代查询优化器框架,如 Cascades [Gra95]、OPT++ [KaD96]、EROC [MBH96]和METU [ONK95],使用面向对象的设计简化了实现、扩展和修改优化器的任务,同时保持了效率并使搜索策略更加灵活。这一最新一代的优化器已经达到了满足现代商业数据库系统需求和要求的复杂程度。这一点可以通过工业界对这些优化器的实现来证明,例如微软的 Cascades [Gra96]和Tandem [Cel96],以及NCR的EROC [MBH96]。
这三代查询优化器可以分为两种搜索策略:Starburst风格的自底向上动态规划优化器和Cascades风格的自顶向下分支限界规则驱动的成本优化器。自底向上优化在当前传统商业数据库系统中被广泛使用,因为人们认为它至少在传统应用中是高效的。但是,自底向上优化在可扩展性方面本质上不如自顶向下优化,因为它需要将原始问题分解为子问题。此外,为了在大型查询中实现可接受的性能,自底向上优化需要使用启发式算法。
尽管以前的自顶向下优化器的实现表明,它们很难调整以获得与自底向上优化相竞争的性能,但我们相信自顶向下优化器在效率和可扩展性方面具有优势。本论文的剩余部分描述了我们开发一种替代的自顶向下优化器Columbia的尝试,以证明在自顶向下的方法中可以实现高效率。
基于级联优化器框架的自顶向下优化,Columbia广泛利用了C++的面向对象特性,并通过精心设计和简化自顶向下优化来实现效率和可扩展性的平衡。它定义了几个关键的抽象类和虚方法。搜索策略完全是基于这些抽象类实现的。搜索策略调用这些抽象类的虚方法来执行搜索和基于成本的搜索空间剪枝。因此,通过从抽象类派生新类并重写虚方法,很容易扩展优化器以操作复杂的数据模型,添加新的操作符和转换规则。由于本论文的主要关注点是关系数据模型中的优化效率,我们在这里不讨论优化器的可扩展性,并将优化器扩展到操作其他数据模型的工作留作将来的研究。
为了最小化CPU和内存的使用,Columbia采用了几种工程技术来提高效率。这些技术包括使用快速哈希函数来消除重复表达式,将逻辑表达式和物理表达式分离在一个组中,使用小型和紧凑的数据结构,使用高效的算法来优化组和输入,以及处理强制规则的高效方式。
Columbia 提供的一个重要技术是组剪枝,它可以显著减少搜索空间而不影响计划质量。优化器在生成某些较低级别的计划之前计算高级物理计划的成本。这些早期成本作为后续优化的上界。我们将展示,在许多情况下,这些上界可以用来避免生成整个表达式组,从而在搜索空间中剪枝大量可能的查询计划。
除了组剪枝外,Columbia还实现了另一种剪枝技术:全局ε剪枝。这种技术通过生成接近最优解的可接受解来显著减少搜索空间。当找到一个与最优解足够接近的解时,优化目标就完成了,因此不需要考虑大量的表达式。本论文对这种剪枝技术进行了分析,讨论了优化的有效性和误差。
论文概述
本论文的剩余部分按如下方式组织。
第2章介绍了本论文中使用的术语和基本概念。
第3章介绍了相关工作,我们在该章节中调研了商业和研究领域在这一领域的贡献,从传统到新一代,从自底向上到自顶向下的优化器。我们将重点关注性能分析。
第4章描述了Columbia系统的整体结构和设计,包括搜索空间、规则和优化任务。讨论了两种剪枝技术。本章还讨论了可用性改进。由于 Columbia 是基于Cascades构建的,讨论将重点比较它们之间的差异,并解释Columbia如何实现更好的效率。
第5章展示了我们使用优化器的经验所得到的结果。通过与其他优化器的比较,说明了性能的改进。
第6章包含了总结和结论,并概述了潜在的未来研究方向。
术语
在本节中,我们回顾了查询优化文献中的术语和基本概念[ElN94] [Ram97],这些术语和概念也用于描述Columbia的设计和实现。更详细的术语将在第4章中讨论,即Columbia优化器的结构部分。
查询优化
查询处理器的目的是接收一个以数据库系统的数据操作语言(DML)表示的请求,并根据数据库的内容对其进行评估。
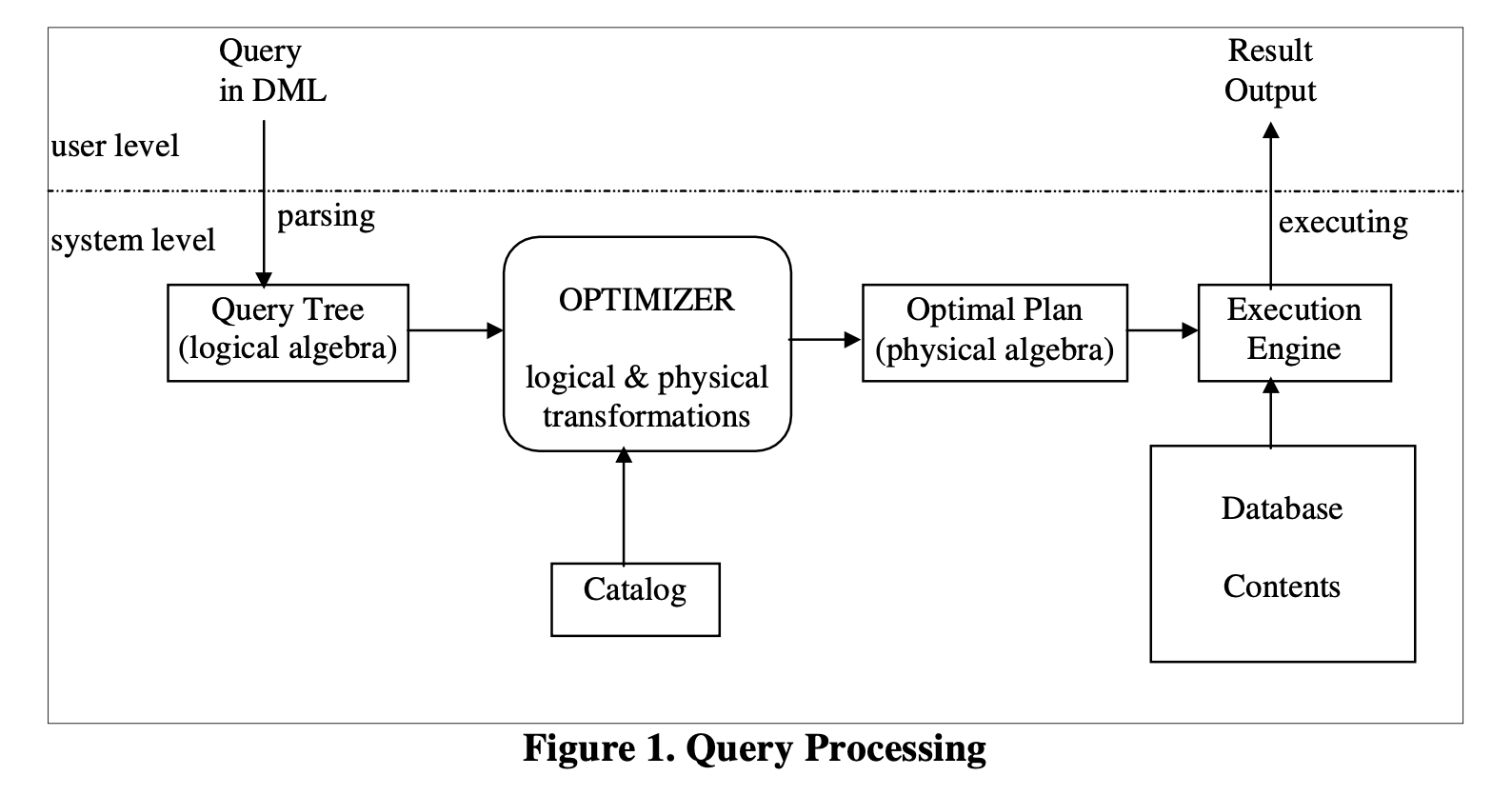
图1
图1 展示了查询处理的步骤。原始的以DML语法表示的查询被解析成一个逻辑表达式树,该树基于一个逻辑代数,后续的阶段可以轻松地对其进行操作。这个内部的逻辑形式的查询然后传递给查询优化器,负责将逻辑查询转换为一个物理计划,该计划将针对保存数据的物理数据结构进行执行。将执行两种类型的转换:逻辑转换,用于创建查询的替代逻辑形式,例如交换树的左右子节点;物理转换,选择特定的物理算法来实现逻辑操作符,例如使用排序合并连接来进行连接操作。这个过程通常会生成大量实现查询树的计划。查询优化器的主要任务是找到最优的计划(相对于成本模型,包括统计和其他目录信息)。一旦选择了查询的最优(或接近最优)物理计划,它将被传递给查询执行引擎。查询执行引擎使用存储的数据库作为输入执行计划,并将查询的结果作为输出产生。
从用户层面来看,查询处理隐藏在查询处理器的黑盒中。用户将他们的查询提交给数据库系统,通常以高级语言(如SQL、Quel或OQL [Cat94](在面向对象数据库系统的情况下))编写,期望系统能够正确且快速地输出查询结果。正确性是查询处理器的绝对要求,而性能是一个可取的特性,也是查询处理器的主要关注点。正如我们在查询处理的系统层面所看到的,查询优化器是一个对高性能有重要贡献的关键组件。有许多实现查询正确性的计划,但对于某些性能指标(如执行时间、内存),它们的执行性能不同。优化器的一个目标是找到具有最佳执行性能的计划。优化器可以采用一种天真的方式来实现这一目标,即生成所有可能的计划并选择最便宜的计划。但是,由于即使是相对简单的查询也有大量的备选计划,探索所有可能的计划是非常昂贵的。因此,优化器必须以某种方式缩小它们考虑的备选计划空间。
查询优化是一个复杂的搜索问题。研究表明,这个问题的简化版本是NP难问题[IbK84]。事实上,即使对于最简单的关系连接类别,使用动态规划时需要评估的连接数量也随着输入关系的数量呈指数增长[OnL90]。因此,一个良好的搜索策略对于优化器的成功至关重要。
本章的剩余部分将回顾一些用于解决查询优化问题的基本概念。我们将使用这些概念来描述Columbia的设计和实现。
逻辑算子和Query树(逻辑执行计划)
逻辑算子是高级操作符,用于指定数据转换,而不指定要使用的物理执行算法。在关系模型中,逻辑操作符通常以表为输入,并生成一个单独的表作为输出。每个逻辑算子都有固定数量的输入,并可能具有区分操作符变体的参数。两个典型的逻辑操作符是GET和EQJOIN。GET操作符没有输入,只有一个参数,即存储关系的名称。GET从磁盘检索关系的元组,并输出用于进一步操作的元组。EQJOIN操作符有两个输入,即要连接的左表和右表,以及一个与左表和右表相关的连接谓词集合作为参数。
Query树是查询的树形表示,作为优化器的输入。通常,Query树被表示为逻辑算子的树,其中每个节点是一个逻辑算子,其输入是零个或多个逻辑算子。节点的子节点数量正好等于操作符的arity。树的叶子节点是arity为零的操作符。图2展示了一个查询的查询树表示的示例。
查询树用于指定操作符应用的顺序。为了应用树中的顶层操作符,必须先应用其输入。在这个例子中,EQJOIN有两个输入,这两个输入来自两个GET操作符的输出。EQJOIN的参数,“Emp.dno=Dept.dno”,描述了连接操作的条件。EQJOIN的输出将产生查询的结果。GET操作符没有输入,因此它们是树的叶子节点,通常提供查询评估的数据源。每个GET操作符的参数定义了将检索哪个存储关系。
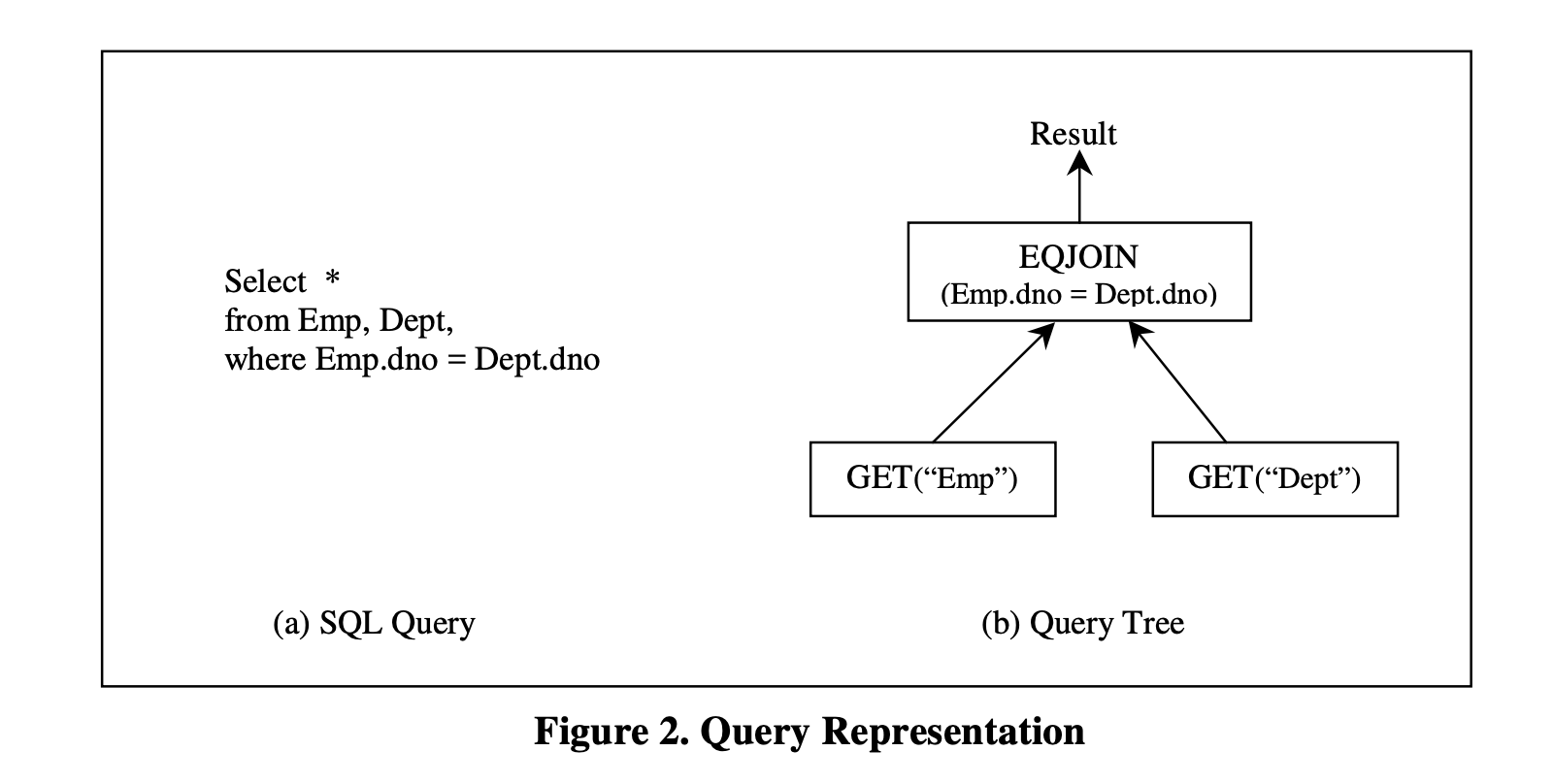
图2
物理算子与执行计划(物理执行计划)
物理操作符表示实现特定数据库操作的具体算法。在数据库中,可以使用一个或多个物理执行算法来实现给定的查询逻辑算子。例如,EQJOIN操作符可以使用嵌套循环、排序合并或其他算法来实现。这些具体的算法可以在不同的物理操作符中实现。因此,两个典型的物理操作符是LOOPS_JOIN,它实现了嵌套循环连接算法,以及MERGE_JOIN,它实现了排序合并连接算法。对于GET逻辑操作符,典型的实现算法是按存储顺序扫描表,这在另一个物理操作符FILE_SCAN中实现。与逻辑操作符类似,每个物理操作符也有固定数量的输入,并且可能具有参数。
将Query树中的逻辑操作符替换为可以实现它们的物理算子,得到一个物理算子组成的树,称为给定查询的执行计划或访问计划。图3显示了与图2(b)中的查询树对应的两个可能的执行计划。
执行计划指定如何评估查询。每个计划都有一个执行成本,对应于成本模型和目录信息。通常,优化器生成给定查询的良好执行计划,并作为查询执行引擎的输入,该引擎根据数据库系统的数据执行整体算法,生成给定查询的输出结果。
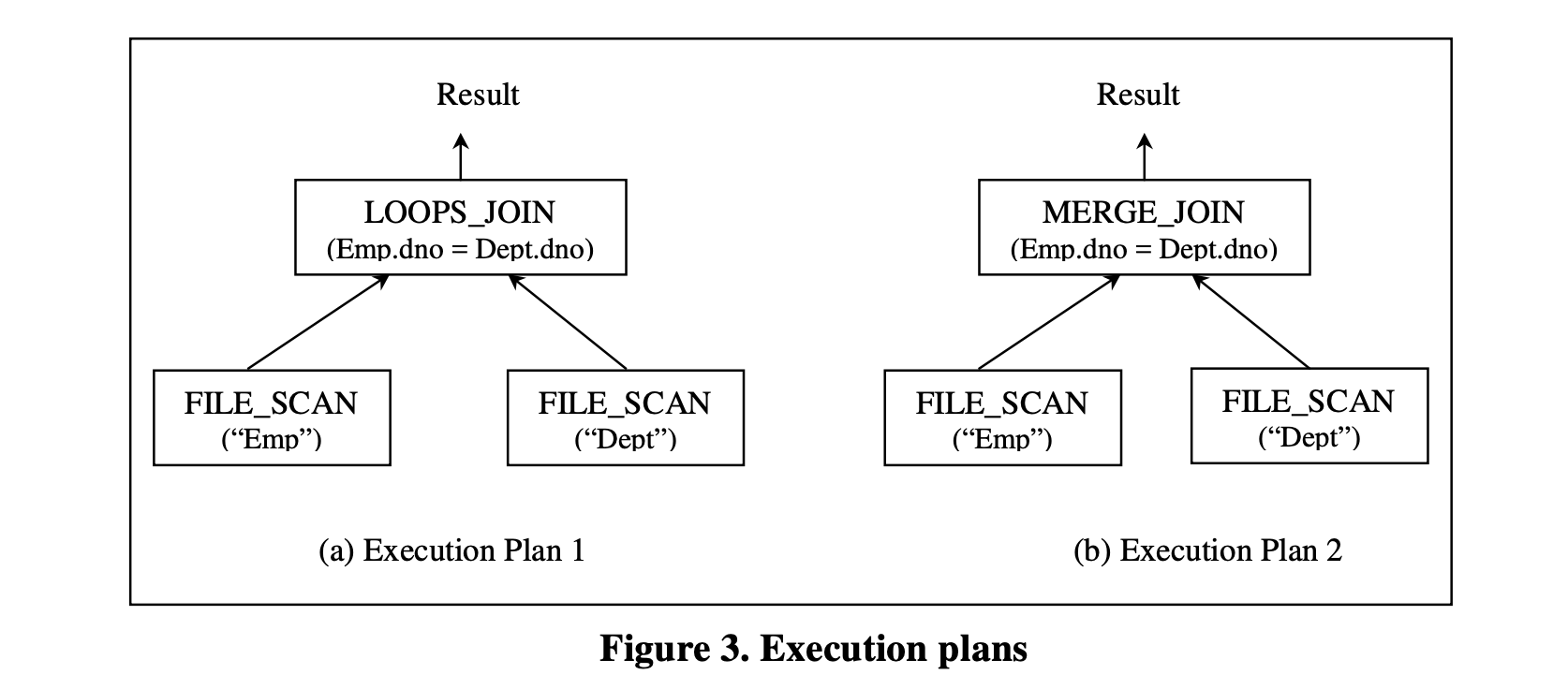
图3
分组
给定的查询可以由一个或多个逻辑等价的Query树表示。如果两个Query树对于数据库的任何数据集产生完全相同的结果,则它们在逻辑上是等价的[Gra95]。通常情况下,对于每个Query树,都存在一个或多个相应的执行计划来实现Query树,并产生完全相同的结果。类似地,这些执行计划在逻辑上是等价的。图4显示了几个逻辑等价的Query树和实现这些Query树的逻辑等价的执行计划。
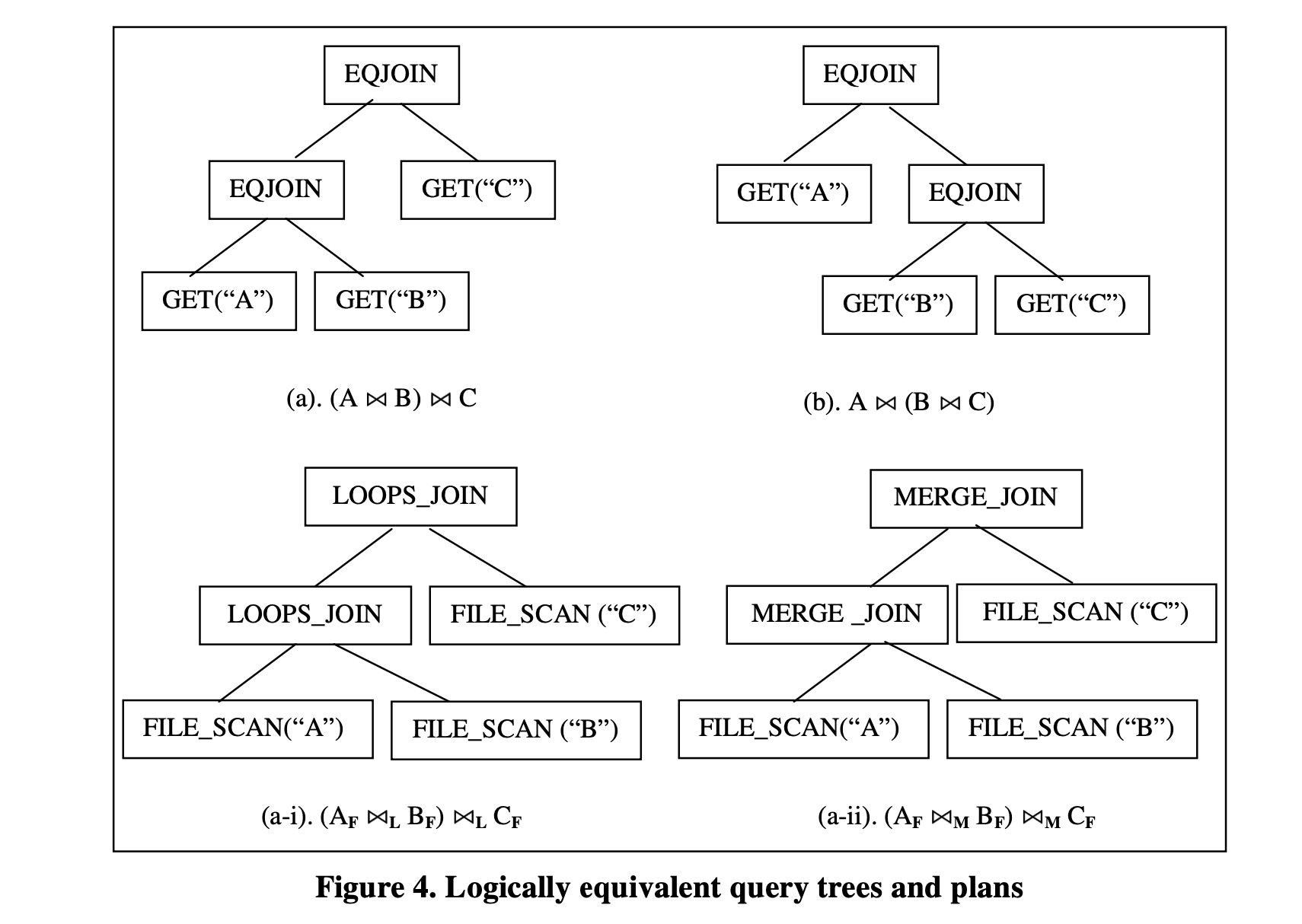
图4
如图4所示,我们用 ~ 表示EQJOIN操作符,用 ~L 表示LOOPS_JOIN,用 ~M 表示MERGE_JOIN。为了简化,我们还用其参数表示GET操作符,用参数加上子F表示FILE_SCAN。在图4中,(a)和(b)是两个逻辑等价的Query树。它们的区别在于逻辑操作符的顺序。(a-i)和(a-ii)是实现Query树(a)的两个逻辑等价的执行计划。它们使用了两种不同的连接算法。
我们还可以使用表达式来表示Query树和执行计划(或子树和子计划)。一个表达式由一个操作符和零个或多个输入表达式组成。根据操作符的类型,我们将表达式称为逻辑表达式或物理表达式。因此,Query树是逻辑表达式,执行计划是物理表达式。
给定一个逻辑表达式,存在许多逻辑上等价的逻辑表达式和物理表达式。将它们收集到组中,并定义它们的共同特征是很有用的。一个组是一组逻辑上等价的表达式。通常情况下,一个组将包含一个表达式的所有等价逻辑形式,以及基于选择相应逻辑形式的可允许的物理算子而导出的所有物理表达式。通常,每个逻辑表达式在一个组中会有多个物理表达式。图5显示了一个包含图4中的表达式和其他等价表达式的组。

图5
通常我们用逻辑表达式中的一个来表示一个组。例如,(A ~ B) ~ C,或简单地写作[ABC]。图5显示了组[ABC]的所有等价逻辑表达式和一些物理表达式。我们可以看到,即使是逻辑表达式,也存在许多等价的表达式。
为了减少组中的表达式数量,引入了多表达式。多表达式由一个逻辑或物理操作符组成,并以组作为输入。多表达式与表达式相同,只是它以组作为输入,而表达式以其他表达式作为输入。例如,多表达式 "[AB] ~ [C]" 表示以组[AB]和[C]作为输入的EQJOIN操作符。多表达式的优势在于节省空间,因为组中的等价多表达式较少。图6显示了组[ABC]中的等价多表达式。与图5中的表达式相比,多表达式要少得多。实际上,一个多表达式通过以组作为输入来表示多个表达式。使用多表达式,一个组可以被重新定义为一组逻辑上等价的多表达式。

图6
在典型的查询处理过程中,在生成最终结果之前会产生许多中间结果(元组的集合)。中间结果是通过计算一个组的执行计划(或物理表达式)来产生的。在这个意义上,组对应于中间结果(这些组被称为中间组)。只有一个最终结果,其组被称为最终组。
组的逻辑属性被定义为结果的逻辑属性,而不考虑结果如何被物理计算和组织。这些属性包括基数(元组的数量)、模式和其他属性。逻辑属性适用于组中的所有表达式。
搜索空间
搜索空间表示给定初始查询的逻辑Query树和物理计划。为了节省空间,搜索空间被表示为一组组,每个组以一些组作为输入。有一个顶级组被指定为最终组,对应于对初始查询进行评估的最终结果。图7显示了给定查询的初始搜索空间。
在初始搜索空间中,每个组只包含一个来自初始查询树的逻辑表达式。在图7中,顶级组[ABC]是查询的最终组。它对应于三个关系的连接的最终结果。我们可以从初始搜索空间推导出初始查询树。查询树中的每个节点对应于搜索空间中每个组的多表达式的操作符。在图7中,顶级组[ABC]有一个多表达式,它由一个EQJOIN操作符和两个组[AB]和[C]作为输入组成。我们可以从组[AB]和组[C]中推导出具有EQJOIN作为顶级操作符的查询树,并递归地从查询树的输入组中推导出输入操作符,直到考虑的组是叶子节点(没有输入)。从这个初始搜索空间推导出的查询树正是初始查询树。换句话说,初始搜索空间表示初始查询树。
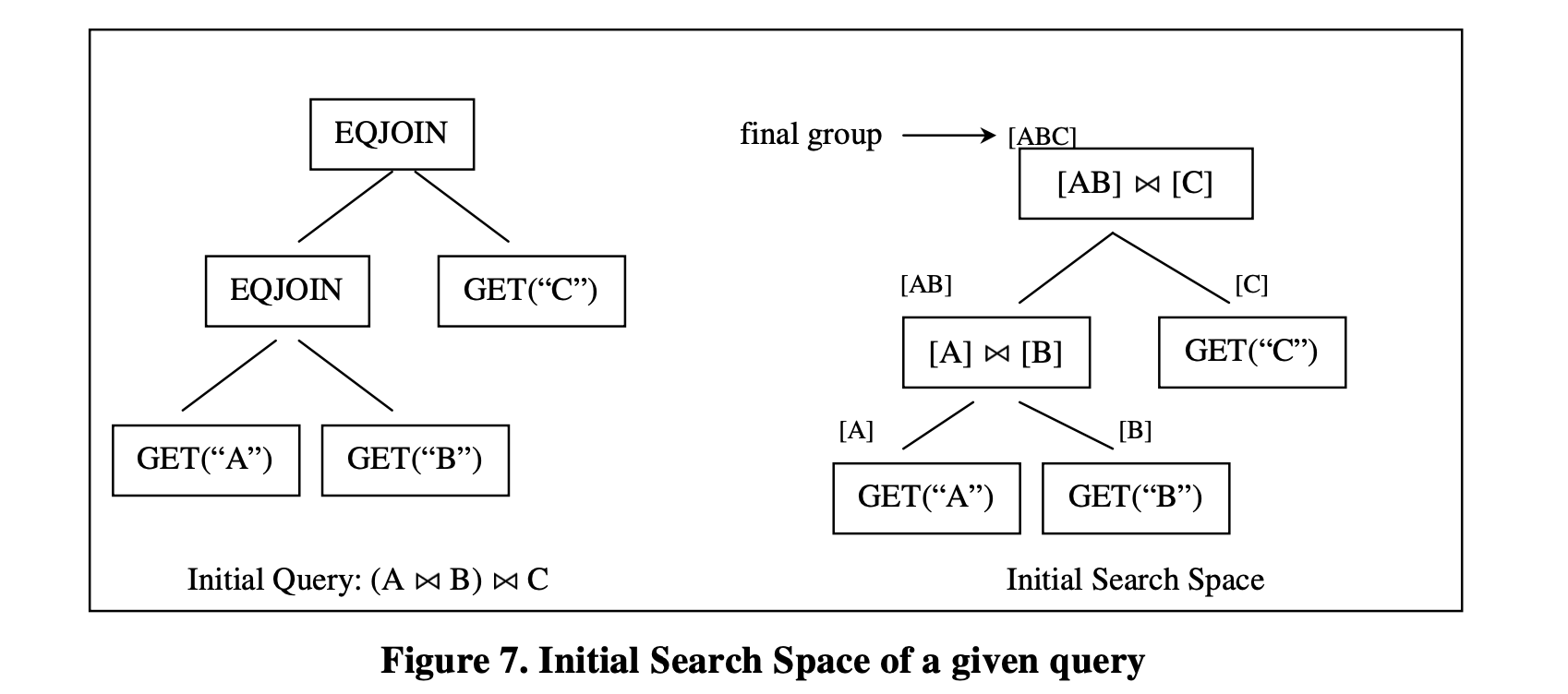
图7
在优化过程中,为每个组生成了逻辑上等价的逻辑和物理表达式,搜索空间大大扩展。每个组将有大量的逻辑和物理表达式。同时,优化生成物理表达式的同时,计算了物理表达式(即执行计划)的执行成本。从某种意义上说,生成所有物理表达式是优化的目标,因为我们希望找到最优的计划,而我们知道成本只与物理表达式相关。但为了生成所有物理表达式,必须生成所有逻辑表达式,因为每个物理表达式都是逻辑表达式的物理实现。优化完成后,即为每个组生成了所有等价的物理表达式,并计算了所有可能执行计划的成本,可以在搜索空间中找到最便宜的执行计划,并作为优化器的输出。一个完全展开的搜索空间被称为最终搜索空间。通常情况下,最终搜索空间表示给定查询的所有逻辑上等价的表达式(逻辑和物理)。实际上,所有可能的查询树和执行计划都可以通过使用我们从初始搜索空间中推导初始查询树的递归方法,从最终搜索空间中推导出来。搜索空间中的每个(逻辑或物理)多表达式的操作符在查询树或执行计划中充当操作符节点。由于搜索空间中的组包含许多逻辑上等价的表达式,最终搜索空间表示了大量的查询树和执行计划。
表1 [Bil97] 显示了n个关系连接的完整逻辑搜索空间的复杂度(仅显示逻辑表达式的数量)。例如,4个关系连接的搜索空间有15个组,包括54个逻辑表达式,表示了120个查询树。
从表1可以看出,即使只考虑逻辑表达式,随着连接关系数量的增加,搜索空间的大小呈指数级增长。物理表达式的数量取决于逻辑操作符使用了多少个实现算法。例如,如果搜索空间中有N个逻辑表达式,并且数据库系统使用了M(M>=1)个连接算法,则搜索空间中将有M*N个物理表达式。因此,物理表达式的数量至少与逻辑表达式的数量相同或更大。
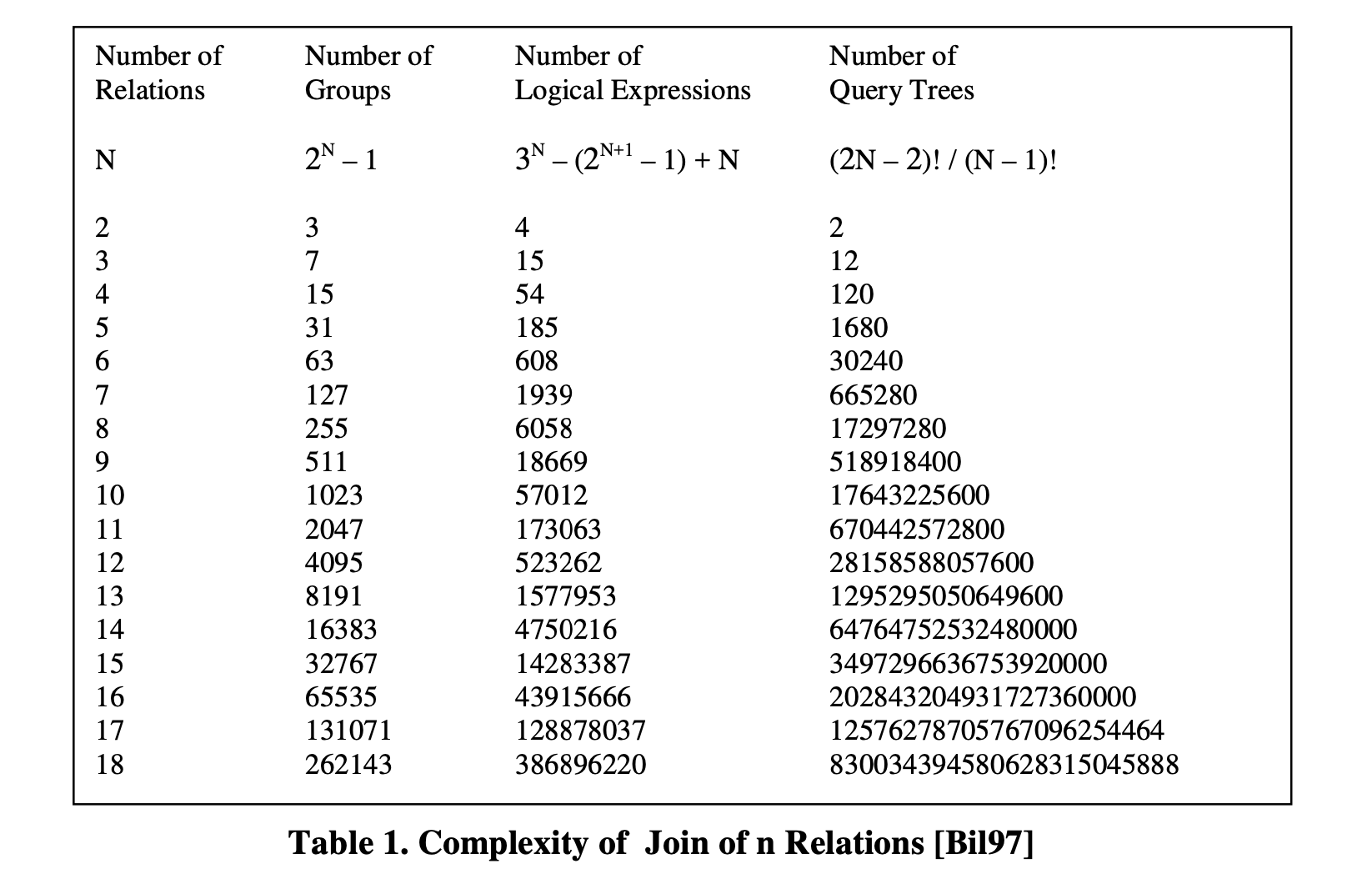
表1
规则
许多优化器使用规则来生成给定初始查询的逻辑上等价表达式。规则是将一个表达式转换为逻辑上等价表达式的描述。当应用规则到给定表达式时,会生成一个新的表达式。优化器使用规则来扩展初始搜索空间,并生成给定初始查询的所有逻辑上等价表达式。
每个规则被定义为模式和替代的一对。模式定义了可以应用于规则的逻辑表达式的结构。替代定义了应用规则后的结果结构。在扩展搜索空间时,优化器将检查每个逻辑表达式(注意,规则仅适用于逻辑表达式),并检查该表达式是否与规则集中的任何规则的模式匹配。如果匹配了规则的模式,则触发规则,根据规则的替代生成新的逻辑上等价表达式。
Cascades使用表达式来表示模式和替代。模式始终是逻辑表达式,而替代可以是逻辑或物理表达式。转换规则和实现规则是两种常见的规则类型。如果替代是逻辑表达式,则称该规则为转换规则。如果替代是物理表达式,则称该规则为实现规则。
例如,EQJOIN_LTOR是一个转换规则,它将左深逻辑表达式应用于左到右的关联性,并生成一个右深逻辑表达式,该表达式在逻辑上等价于原始表达式。EQJOIN_MERGEJOIN是一个实现规则,通过用MERGEJOIN物理操作符替换EQJOIN操作符来生成一个物理表达式。这个物理表达式使用排序-合并连接算法来实现原始的逻辑表达式。图8展示了这两个简单规则的示意图。
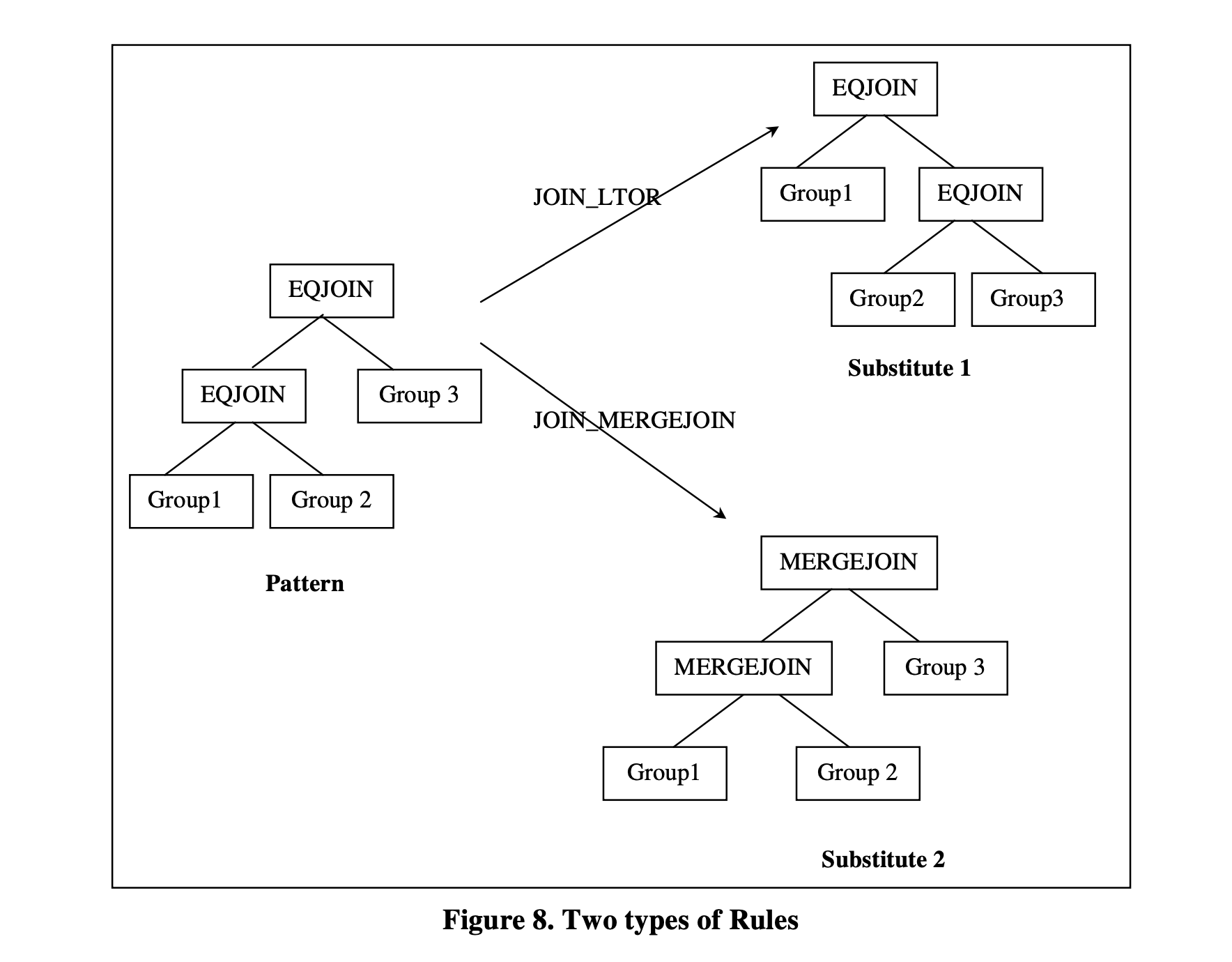
图8
相关工作
查询优化的开创性工作可以追溯到二十年前。IBM的System R优化器[SAC+79]取得了成功,并且表现出色,成为许多当前商业优化器的基础。
数据库系统和应用程序不断发展,并需要新一代的优化器来处理数据库系统的新扩展。关系数据模型通过支持新的数据类型和新的操作等更多功能进行了扩展。面向对象的数据模型被引入以处理更复杂的数据。由于早期的优化器设计用于相对简单的关系数据模型,因此开发了新一代可扩展的优化器,以满足不断发展的数据库系统的要求。新一代的优化器注重可扩展性,同时也是所有优化器的困难目标:效率。本章将介绍一些在查询优化文献中有重要贡献的著名优化器。
The System R and Starburst Optimizer
当前的关系型查询优化器在设计上受到IBM的System R查询优化器[SAC+79]使用的技术的很大影响。System R优化器的一个重要贡献是基于成本的优化。优化器使用存储在系统目录中的关系和索引的统计信息来估计查询评估计划的成本。估计成本有两个部分:一个是估计执行操作的成本,另一个是估计查询块的结果大小以及是否已排序。
估计操作的成本需要了解输入关系的各种参数,例如基数(关系的大小)、页面数和可用索引。这些统计信息在数据库管理系统的系统目录中维护。大小估计在成本估计中起着重要作用,因为一个操作的输出可以成为另一个操作的输入,而操作的成本取决于其输入的大小。System R定义了一系列大小估计公式,这些公式也被当前的查询优化器使用,尽管近年来提出了基于更详细统计信息(例如系统中值的直方图)的更复杂技术[Ioa93] [PIH96]。
System R优化器的另一个重要贡献是自底向上的动态规划搜索策略。动态规划的思想是在查询树中找到较低级别查询块的最佳计划,并仅保留最佳计划与较高级别查询块一起考虑。这是一种自底向上的风格,因为它总是先优化较低级别的表达式。为了计算较高级别表达式的成本,必须计算其较低级别输入(也是表达式)的所有成本(以及结果的大小)。动态规划的技巧是:在优化查询块后(即找到最佳计划),我们丢弃该查询块的所有等价表达式,只保留该查询块的最佳计划。[OnL90]指出,动态规划需要考虑 O(3的N次方) 个表达式(计划)。由于这种指数级增长率,当N很大时,优化器需要考虑的表达式数量仍然是不可接受的。因此,System R优化器还使用启发式方法,例如将笛卡尔积的优化推迟到最终处理阶段,或者在优化大型查询时仅考虑左深树(排除了大量的查询树,如 bushy 树)[GLS93]。然而,排除笛卡尔积或仅考虑左深树可能会导致选择较差的计划,因此无法保证最优性。
IBM的Starburst优化器[HCL90]扩展了System R优化器,采用了可扩展且更高效的方法。Starburst优化器由两个基于规则的子系统组成:查询重写或查询图模型(QGM)优化器和计划优化器。QGM是查询的内部语义表示。QGM优化器使用一组产生规则,启发式地将QGM转换为语义上等效的“更好”的QGM。这个过程的目的是简化和改进[JaK84]:消除冗余并生成对计划优化器更容易以基于成本的方式进行优化的表达式。计划优化器是一个选择-投影-连接优化器,由连接枚举器和计划生成器组成。连接枚举器使用两种类型的连接可行性准则(强制性和启发式)来限制连接的数量。连接枚举器算法不是基于规则的,是用C语言编写的,其模块化设计允许用替代的枚举算法替换它。计划生成器使用类似语法的产生规则来构建连接的访问计划。这些参数化的产生规则被称为策略性替代规则(STARs)。STARs可以确定哪个表是内部表,哪个是外部表,要考虑哪些连接方法等。
在Starburst中,查询优化是一个两步过程。在第一阶段,将初始查询表示为QGM,并将其传递给QGM优化器,将其重写为一个新的更好的QGM。然后将新的QGM传递给计划优化器。在第二阶段,计划优化器与QGM优化器进行通信,生成访问计划,并以类似System R优化器的自底向上方式构建最优执行计划。
QGM优化器能够进行复杂的启发式优化,从而提高了Starburst优化器的效率。然而,正如[KaD96]所指出的,启发式有时会做出错误的决策,因为它们仅基于逻辑信息,即不基于成本估计。此外,启发式很难扩展到包含非关系运算符的更复杂查询。显然,类似语法规则的基于规则的方法来转换QGM和计划是可扩展查询优化的一种贡献,但如何用于优化包含非关系运算符和复杂转换的查询尚不清楚。
The Exodus and Volcano Optimizer Generators
Exodus优化器生成器[GrD87]是第一个使用自顶向下优化的可扩展优化器框架。Exodus的目标是构建一个基础设施和工具,用于对查询进行优化,对数据模型的假设最小化。Exodus的输入是一个模型描述文件,描述了一组操作符、在构建和比较访问计划时要考虑的一组方法,转换规则(定义查询树的转换)和实现规则(定义操作符和方法之间的对应关系)。为了为新的数据模型实现查询优化器,数据库接口(DBI)编写一个模型描述文件和一组C程序。生成器将模型文件转换为一个C程序,该程序与一组C程序一起编译和链接,生成一个特定于数据模型的优化器。生成的优化器逐步转换初始查询树,使用一种称为MESH的数据结构来维护到目前为止探索的所有备选方案的信息。在优化过程中的任何时候,可能存在一组可能的下一步转换,这些转换存储在一个称为OPEN的队列结构中。当OPEN不为空时,优化器将从OPEN中选择一个转换,将其应用于MESH中的正确节点,对新节点进行成本估算,并将新启用的转换添加到OPEN中。
Exodus的主要贡献是自顶向下的优化器生成器框架,它将优化器的搜索策略与数据模型分离,并将转换规则和逻辑操作符与实现规则和物理操作符分离。尽管构建高效的优化器很困难,但它为下一代可扩展优化器提供了有用的基础。
为了提高Exodus的效率,Volcano优化器生成器[GrM93]旨在实现更高的效率、更大的可扩展性和更好的效果。通过将动态规划与基于物理属性的有向搜索、分支限界剪枝和启发式引导相结合,实现了一种称为有向动态规划的新的搜索算法,从而提高了效率。Volcano中的搜索策略是一种自顶向下的目标导向控制策略:只有在有必要的情况下才对子表达式进行优化。也就是说,只有那些真正参与有希望的更大计划的表达式和计划才会被考虑进行优化。它还使用动态规划来存储所有最优子计划以及优化失败,直到查询完全优化。由于它非常注重目标,通过使用物理属性(一种在System R中使用的“有趣属性”的泛化)推导出有希望的表达式和计划,因此搜索算法是高效的。Volcano的更大可扩展性是通过从数据模型规范生成优化器源代码,并将成本以及逻辑和物理属性封装为抽象数据类型来实现的。通过允许详尽的搜索,并仅在优化器实现者的自由裁量下进行剪枝,实现了更好的效果。
Volcano搜索策略的效率使得可以生成真正的优化器,其中一个用于面向对象数据库系统[BMG93],另一个用于具有许多规则的原型科学数据库系统[Wog93]。
The Cascades Optimizer Framework
Cascades优化器框架[Gra95]是一个可扩展的查询优化框架,解决了EXODUS和Volcano优化器生成器的许多缺点。它在功能性、易用性和稳健性方面相比前任产品有了显著改进,同时保持了可扩展性、动态规划和记忆化的特点。选择Cascades作为Tandem的NonStop SQL产品[Cel96]和Microsoft的SQL Server产品[Gra96]中新查询优化器的基础,证明了Cascades满足现代商业数据库系统的要求和需求。以下列举了Cascades的一些优点:
- Optimization tasks as data structures
- Rules as objects
- Rules to place property enforcers such as sort operations
- Ordering of moves by promise
- Predicates as operators that is both logical and physical
- Abstract interface class defining the DBI-optimizer interface and permitting DBI-defined subclass hierarchies.
- More robust code written in C++ and a clean interface making full use of the abstraction mechanisms of C++
- Extensive tracing support and better documentation to assist the DBI
在Cascades中,优化算法被分解为几个部分,称为"任务"。任务被实现为对象,其中定义了一个"perform"方法。所有这些任务对象都被收集在一个任务结构中,该结构被实现为一个后进先出的堆栈。调度任务非常类似于调用函数:任务从堆栈中弹出,并调用任务的"perform"方法。在优化过程中的任何时候,都有一堆等待执行的任务。执行一个任务可能导致更多的任务被放入堆栈中。
Cascades优化器首先将原始查询复制到初始搜索空间中(在Cascades中,搜索空间称为"memo",这是从Volcano继承而来的)。然后,通过一个任务来触发整个优化过程,该任务用于优化初始搜索空间的顶部组,从而触发对搜索空间中越来越小的子组的优化。优化一个组意味着找到该组中的最佳计划(称为"优化目标"),因此对所有表达式应用规则。在这个过程中,新的任务被放入任务堆栈中,新的组和表达式被添加到搜索空间中。完成优化顶部组的任务后,需要等待顶部组的所有子组完成优化,才能找到顶部组的最佳计划,从而完成优化过程。
与Volcano优化器生成器类似,Cascades从顶部组开始优化过程,被认为使用自顶向下的搜索策略。动态规划和记忆化也在优化组的任务中使用。在开始优化组的所有表达式之前,它会检查是否已经追求过相同的优化目标;如果是,则直接返回在先前搜索中找到的计划。Cascades和Volcano之间搜索策略的一个主要区别是,Cascades仅在需要时探索一个组,而Volcano在实际优化阶段开始之前,在第一个预优化阶段始终生成所有等效的逻辑表达式。在Cascades中,没有分为两个阶段。对于所有表达式,例如谓词的所有逻辑等效形式,推导出来并不实用。一个组只在需要时使用转换规则进行探索,并且仅为创建与给定模式匹配的组的所有成员而进行探索。由于Cascades仅为真正有用的模式探索组,其搜索策略更高效。
与Volcano优化器生成器的繁琐用户界面相比,Cascades提供了清晰的数据结构抽象和DBI与优化器之间的接口。构成Cascades优化器与DBI之间接口的每个类都被设计为子类层次结构的根。优化器仅依赖于此接口中定义的方法;DBI可以在定义子类时自由添加额外的方法。一些重要的接口包括操作符、成本模型和规则。这种清晰的接口对于使优化器更加健壮,并且使DBI实现或扩展优化器更加容易非常重要。
[Bil97]描述了一个实验性优化器Model D,用于在Cascades优化器框架下优化TPC-D查询[TPC95]。Model D具有许多逻辑操作符,这些操作符又需要一些规则和物理操作符。通过从基本接口类派生,DBI可以定义并轻松地将新的操作符和规则添加到优化器中。通过对Cascades搜索引擎进行少量更改,Model D展示了关系模型中Cascades框架的可扩展性。
Cascades只是一个优化器框架。它提出了许多性能改进,但目前许多功能未被使用或仅以基本形式提供。Cascades的当前设计和实现还有很大的改进空间。优化器框架与DBI规范的强分离、广泛使用虚拟方法、非常频繁的对象分配和释放可能导致性能问题。可以应用一些修剪技术来对自顶向下的优化进行剪枝,从而显著提高搜索性能。所有这些观察结果激发了我们对Cascades的研究,并开发了一个新的、更高效的优化器——Columbia优化器。
原理与实现
参考文章:EFFICIENCY IN THE COLUMBIA DATABASE QUERY OPTIMIZER(翻译)优化器架构
Columbia 优化器的可用性
除了在前面的章节中描述的对Cascades的效率改进之外,Columbia还通过使用Windows界面与用户进行交互并支持持续跟踪信息来改进可用性。本节介绍了Columbia在可用性方面对Cascades的改进。
Windows Interface
对优化器进行实验是一项繁琐的任务。优化器有三种输入:查询、目录和成本模型。其中任何一个都会影响优化器的行为。Columbia提供了一个方便的界面,让用户选择不同的查询文件、目录文件和成本模型文件。优化器将在不退出优化器的情况下对这个新的输入集进行优化。
此外,像Columbia这样的实验性优化器为用户提供了一些修剪标志,以体验不同的修剪技术。优化器中还有其他参数,允许用户控制优化器的输出。Columbia中友好的用户界面提供了一种简单的方式来控制和实验优化器。
图26展示了Columbia优化器中的选项设置对话框,用户可以在其中选择优化器的参数。当用户在对话框上点击“确定”时,优化器将接受这些设置,并基于当前的设置(参数)进行新的优化。
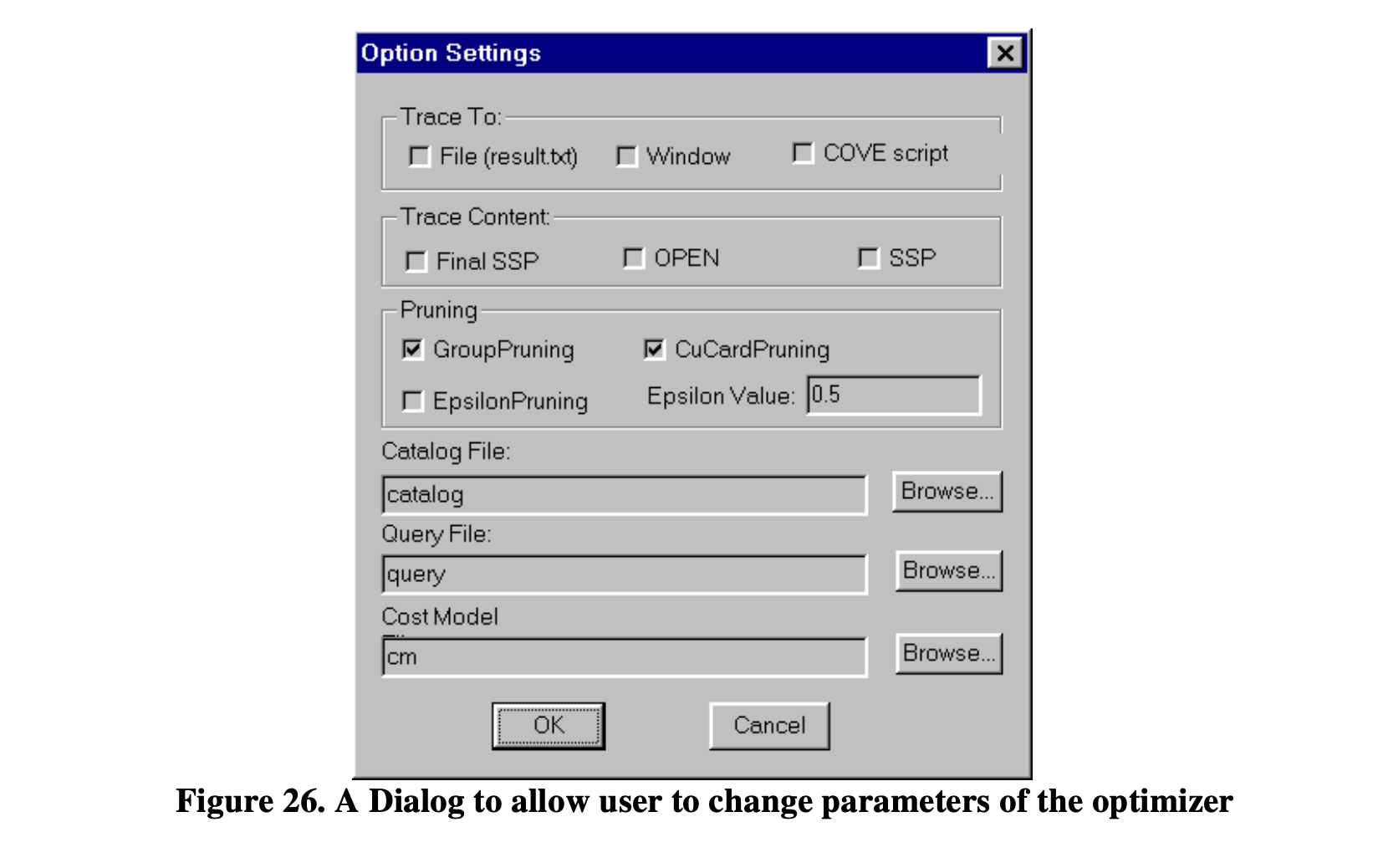
图26
如图26所示,选项设置对话框允许用户选择不同的输入文件。如第4.1节所讨论的,优化器的输入被建模为文本文件,可以在优化器之外使用任何文本编辑器编写,并存储在优化器程序所在的文件系统中。"浏览"按钮使用户能够在文件系统中查找文件并将其选为优化器的输入。
在此对话框中,用户可以选择优化器的三个修剪标志:GroupPruning、CuCardPruning和EpsilonPruning,它们分别代表任务O_INPUTS算法中的三个标志:Pruning、CuCardPruning和GlobalepsPruning。第4.2.3.5节描述了这三个标志的含义以及它们的组合如何控制优化器的行为。对于EpsilonPruning,还有一个编辑字段供用户输入他们想要的epsilon值。
在对话框的顶部部分,有一些与优化器行为跟踪相关的选项。它们将在下一节“优化器的跟踪”中描述。
一旦设置了新的参数,下一次优化将基于这些设置,并将结果输出到一个窗口中。优化器应用程序还提供了一个搜索工具,让用户在结果输出中搜索关键词。当结果有很多行时,这个搜索工具将帮助用户快速定位输出中感兴趣的部分。
图27显示了在生成结果输出并由用户选择搜索工具菜单后,优化器应用程序的界面。
图27
Tracing of the optimizer
由于优化器的行为复杂,很难调试或验证优化过程。优化器在优化过程中提供的跟踪信息是让用户了解优化过程并了解优化器工作方式的一种方法。Columbia改进了Cascades中的跟踪机制,为用户提供易于阅读和可控的跟踪信息。
优化的跟踪信息可能包括:
- 优化器的输入内容:正在优化的查询、目录、成本模型和优化器中使用的规则集。通过查看这些信息,我们可以知道优化器正在处理什么内容。
- 任务栈的内容:也称为OPEN栈。该栈包含待调度的任务。每次从栈顶移除一个任务并执行。通过查看OPEN栈,我们可以了解优化器的工作方式和优化任务的调度情况。
- 每个任务的详细处理过程:这些信息跟踪特定任务的处理过程。
- 每个任务后的搜索空间内容:每个任务执行后,搜索空间可能会发生变化,因为可能会添加更多的表达式或获胜者到搜索空间中。这些信息跟踪每个任务的结果。
- 最终搜索空间的内容:在优化完成后,将打印出最终的搜索空间。通过查看最终的搜索空间,用户可以找到优化器的最终状态。例如,每个组中生成了多少个表达式。
上述信息非常详尽。有时用户只对跟踪结果中的某一部分感兴趣。Columbia通过为优化器设置跟踪选项来提供这种控制。在“选项设置”对话框(图26)中,有两组用于跟踪控制的设置。
- 跟踪输出目标:用户可以选择将跟踪结果输出到文本文件、窗口或COVE17脚本文件。
- 跟踪内容:此选项允许用户选择跟踪内容中感兴趣的部分。有三个选择,并允许组合使用。
- Final SSP:跟踪中包含最终搜索空间的内容。
- 附录D展示了跟踪结果中最终搜索空间的示例。
- OPEN:跟踪中包含每个任务后的OPEN栈内容。
- 附录E展示了跟踪结果中一些OPEN栈的示例。
- SSP:跟踪中包含每个任务后的搜索空间内容。
这些选项允许用户控制跟踪,并为他们提供了一种方便的方式来调试和验证优化器的行为。
结果和性能
本章介绍了Columbia优化器的效率实验评估。首先,展示了Columbia优化器在链式查询和星型查询上的性能,包括表达式生成、内存使用和优化时间。其次,将Columbia优化器与Cascades优化器进行比较。第三,检查了Columbia中全局epsilon剪枝技术的有效性。
实验中使用的查询是仅包含连接操作的查询。对两种类型的查询进行了研究,即链式查询和星型查询。它们代表了两种基本的连接顺序形状。在链式查询中,所有连接的关系通过它们的连接谓词相互连接在一起。在星型查询中,中心的连接关系通过它们的谓词与周围的关系相连接。
Columbia优化器的实验在一台具有4个Intel Pentium Pro 200MHz CPU和1G内存的SMP系统上运行。操作系统为Windows NT Server 4.0。使用附录B中显示的简单成本模型。优化器中使用的规则集显示在附录C中。嵌套循环连接和排序合并连接被用来实现连接算法。查询中使用的所有基本表在目录中被定义为具有相同的基数。
链式查询和星型查询的性能
本节介绍了使用Columbia优化器来优化两类查询(链式查询和星型查询)的结果。在这里,我们只使用了Columbia中的下界组剪枝来展示Columbia的最佳性能,同时仍然生成最优解。图28-30展示了Columbia优化器优化链式查询和星型查询的性能。进行了三项测量:优化时间、多表达式数量和内存使用。随着查询中表的数量增加,优化查询的复杂性急剧增加。查询的形状也会影响优化的复杂性。优化星型查询比链式查询更复杂。
图28显示了优化不同链式查询和星型查询的时间。我们可以看到,优化星型查询的时间增长速度比链式查询快得多。Columbia优化器在优化链式查询时效率很高。从图28中可以看出,优化少于11个表的查询只需要几秒钟,而优化一个包含16个表的链式查询只需要不到1分钟。
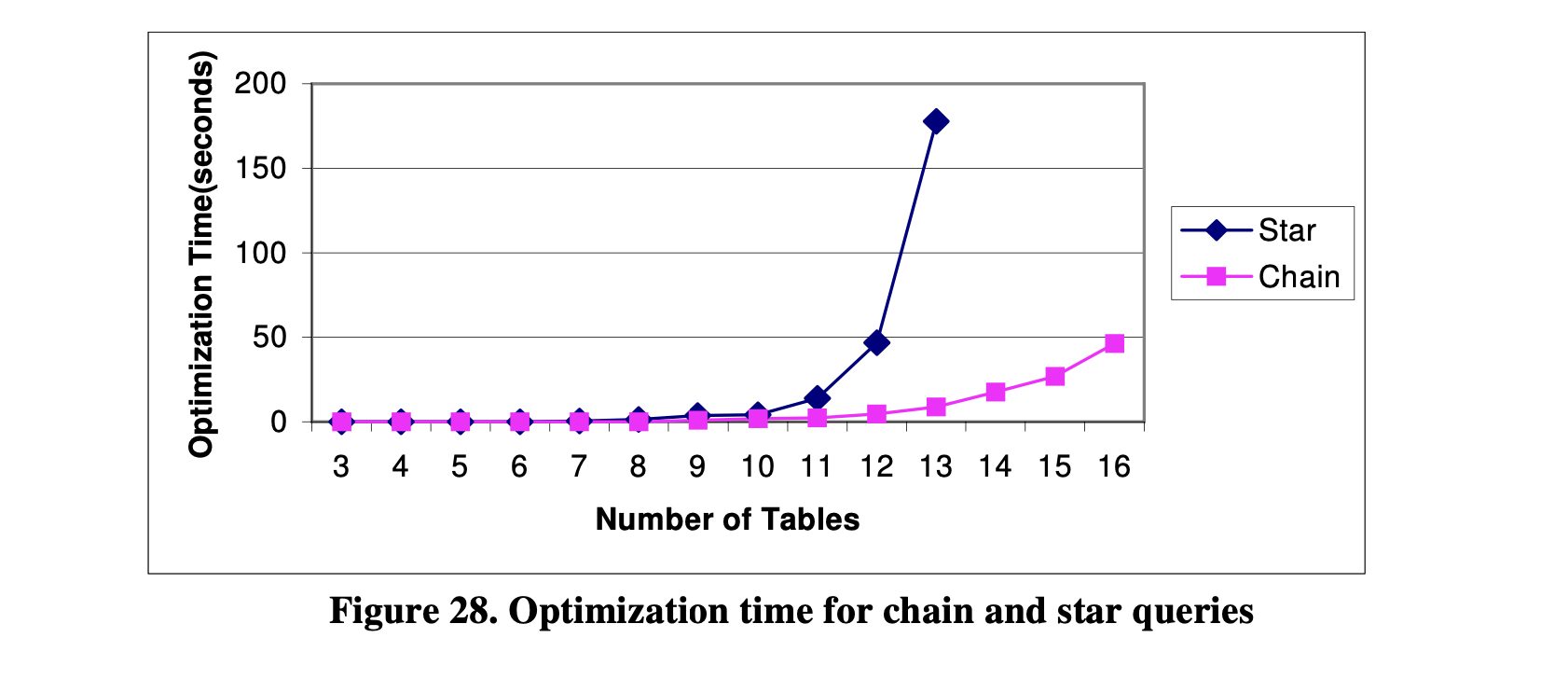
图28
优化的过程是生成可能的多表达式并找到最便宜的计划。因此,多表达式的数量也是优化复杂性的一个重要因素。图29展示了在优化链式查询和星型查询过程中生成的多表达式数量。这里计算了所有逻辑和物理多表达式。我们可以看到,当查询中的表的数量超过11个时,星型查询生成的多表达式比链式查询多得多。
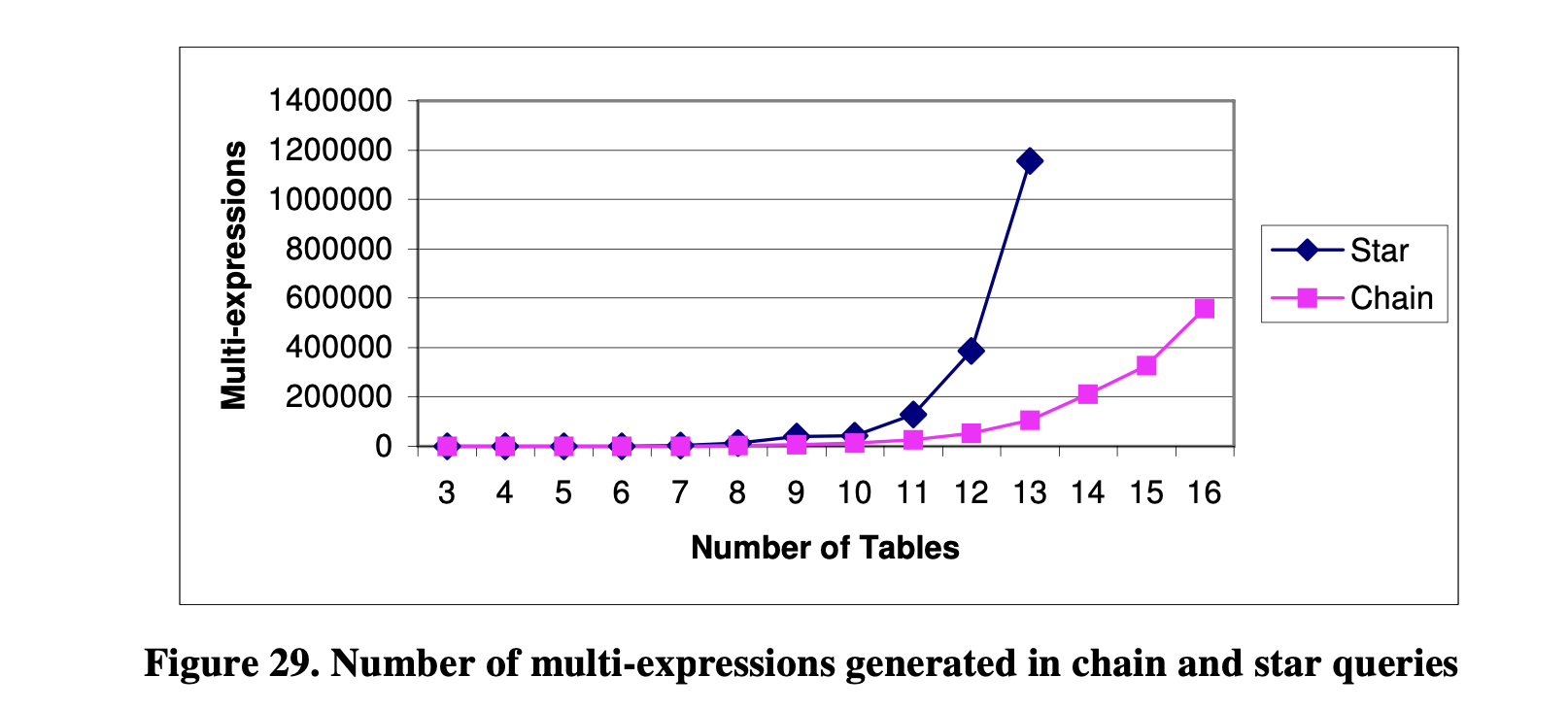
图29
在自顶向下的优化器中,所有的多表达式都被记忆化以供进一步处理。它们占用了大量的内存。生成的多表达式越多,它们占用的内存就越多。图30显示了优化链式查询和星型查询时的内存使用情况。我们可以看到,在优化少于11个表的查询时,内存使用情况几乎没有变化。随着表的数量增加,内存使用量急剧增加,尤其是对于星型查询而言。
正如[OnL90]所指出的,星型查询的优化比链式查询更加复杂,因为链式查询在优化过程中会生成许多笛卡尔积,而星型查询生成的笛卡尔积相对较少。由于笛卡尔积容易被优化器使用组剪枝技术剪枝,因此优化器更有效地优化链式查询而不是星型查询是合理的。
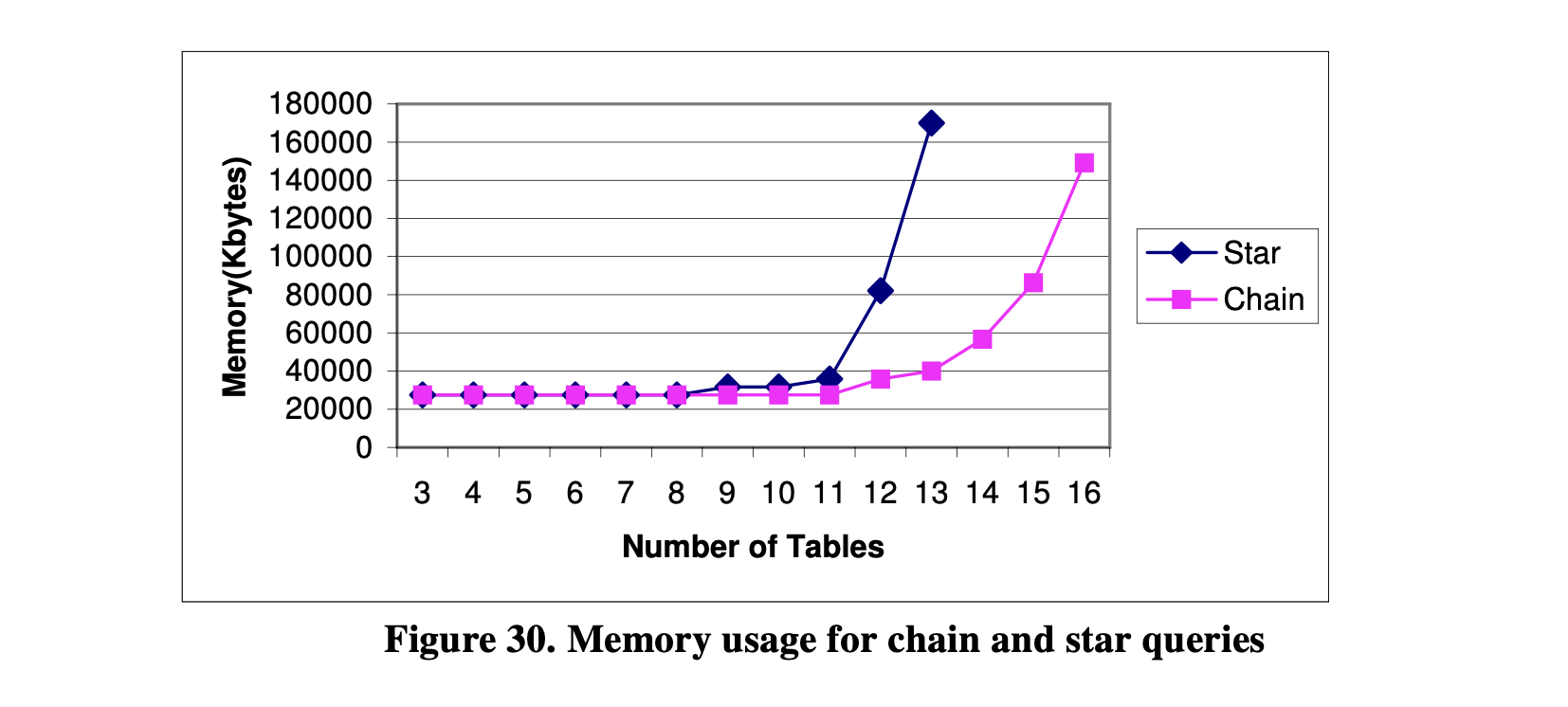
图30
考虑到Columbia优化器可以在1分钟内优化一个包含16个表的链式查询,并且只使用了不到150M的内存,它在优化大型链式查询方面变得实用起来。
对比 Cascades
本节介绍了Columbia优化器和Cascades优化器在搜索效率方面的实验比较。在相同的数据模型上,即相同的目录、相同的规则集和相同的成本模型下,两个优化器都对几个链式查询和星型查询进行了优化。对比了它们的优化时间。
图31-32显示了链式查询和星型查询的优化时间。从图31中可以看出,Columbia优化器只需要几秒钟就能优化一个包含10个表的链式查询,而Cascades优化器需要12秒。在优化星型查询时,Columbia优化器和Cascades优化器之间的差异更大。从图32中可以看出,对于包含9个表的星型查询,Columbia优化器只需要几秒钟,而Cascades优化器需要超过1分钟。
通过这个比较,我们可以看出Columbia优化器的性能优于Cascades优化器。当查询中的表的数量增加时,性能显著提高。此外,Columbia优化器在优化星型查询时比Cascades优化器表现更好。这表明Columbia优化器中使用的剪枝技术对星型查询比Cascades优化器中的剪枝技术更有效。
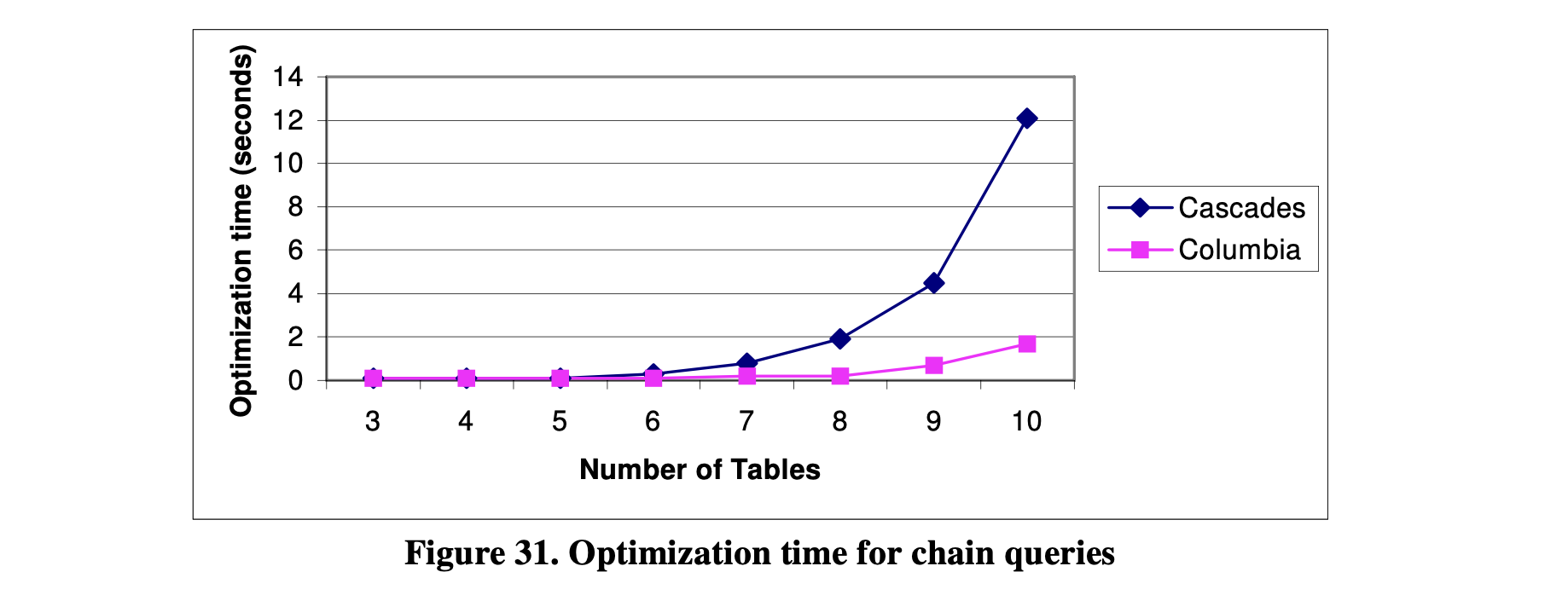
图31
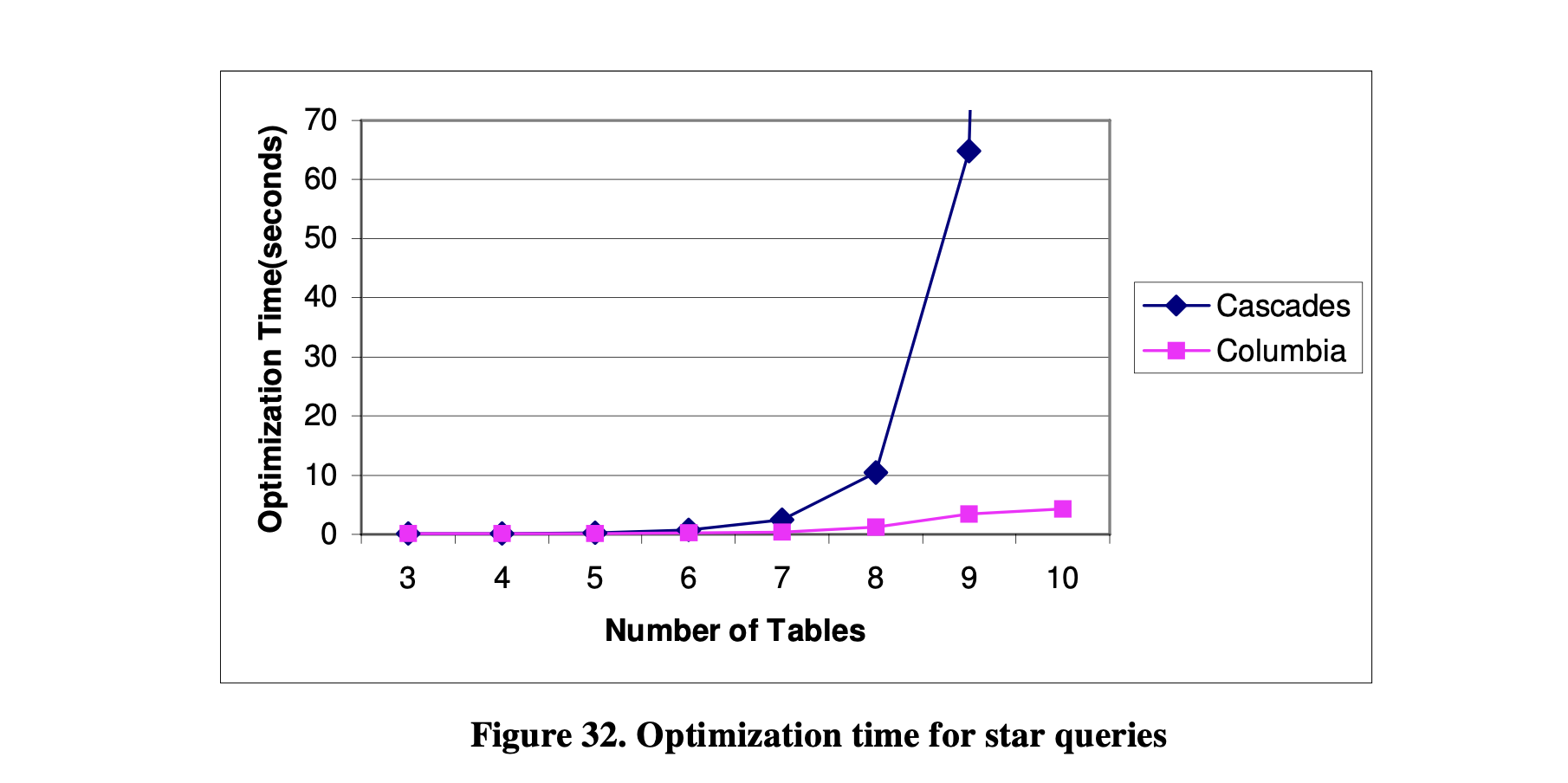
图32
Epsilon Pruning Technique Analysis
本节分析了Columbia优化器中使用的全局ε剪枝技术。如第4.3.2节所讨论的,ε剪枝的有效性严重依赖于我们选择的ε值,并且ε剪枝可能无法产生最优的计划。我们首先运行优化器来优化查询,不使用ε剪枝,并记录优化器生成的最优计划的成本。然后,我们运行优化器使用不同的ε值来进行ε剪枝,并测量生成的多表达式数量。同时,计算并报告优化器输出的成本与最优计划成本之间的误差。误差的计算公式为:
Error = (cost of optimizer output – cost of optimal plan) / cost of optimal plan.
误差表示输出与最优计划之间的距离。例如,误差为1表示优化器输出的成本是最优计划的两倍。因此,我们可以认为大于1的误差与最优计划相差较远。 实验中使用的查询是一个包含8个具有相同基数的表的链式查询。图33显示了在不同的ε值下进行优化时生成的多表达式数量。图34显示了在不同的ε值下进行优化时输出与最优计划之间的误差。我们可以看到,随着ε值的增加,多表达式的数量迅速减少,而误差也增加。当ε值为零时,即与不使用ε剪枝进行优化相同的情况下,生成了最优计划。当误差为零时,生成了最多的多表达式。当ε值为15时,多表达式的数量显著减少,从3174个减少到1293个。生成的多表达式不到一半,而此时的误差为0.4,相对较小。如果我们看误差为1的情况,即ε值为30的情况下,多表达式的数量减少到608个,仅为原始多表达式数量的五分之一。
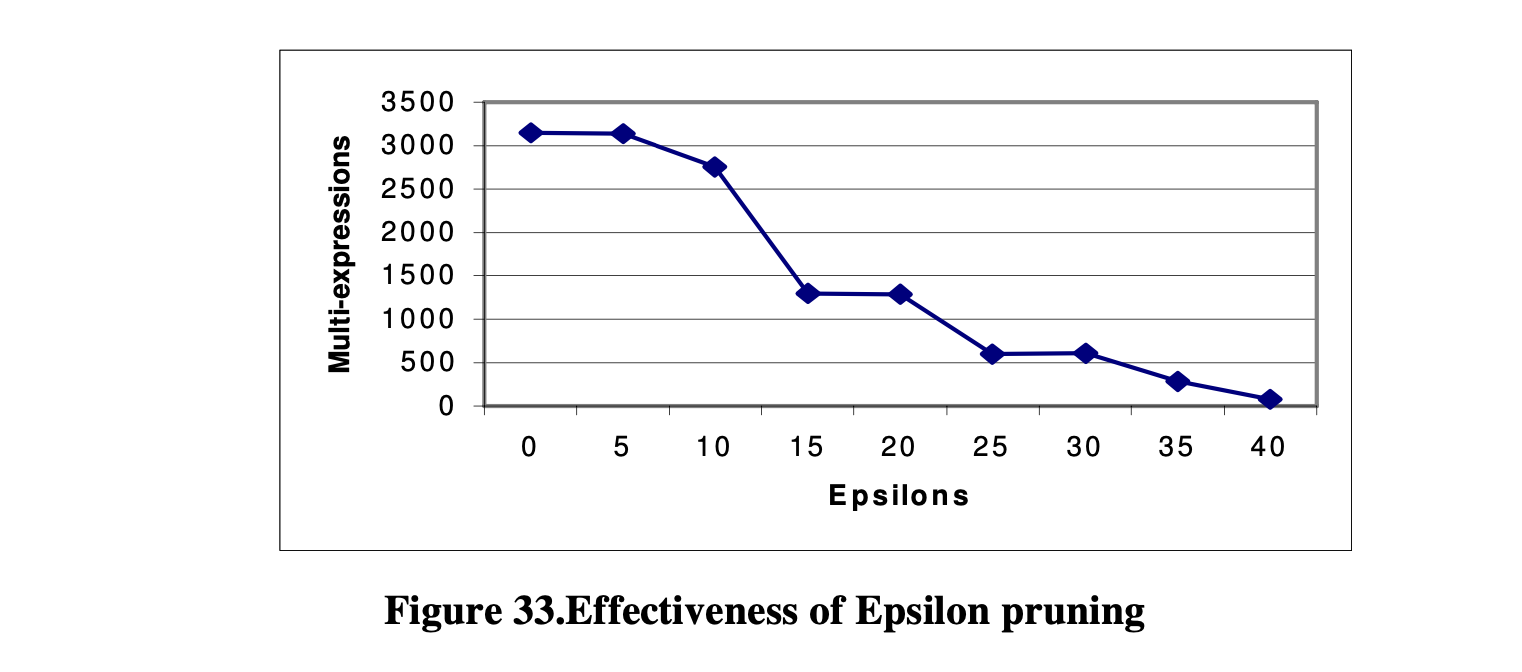
图33
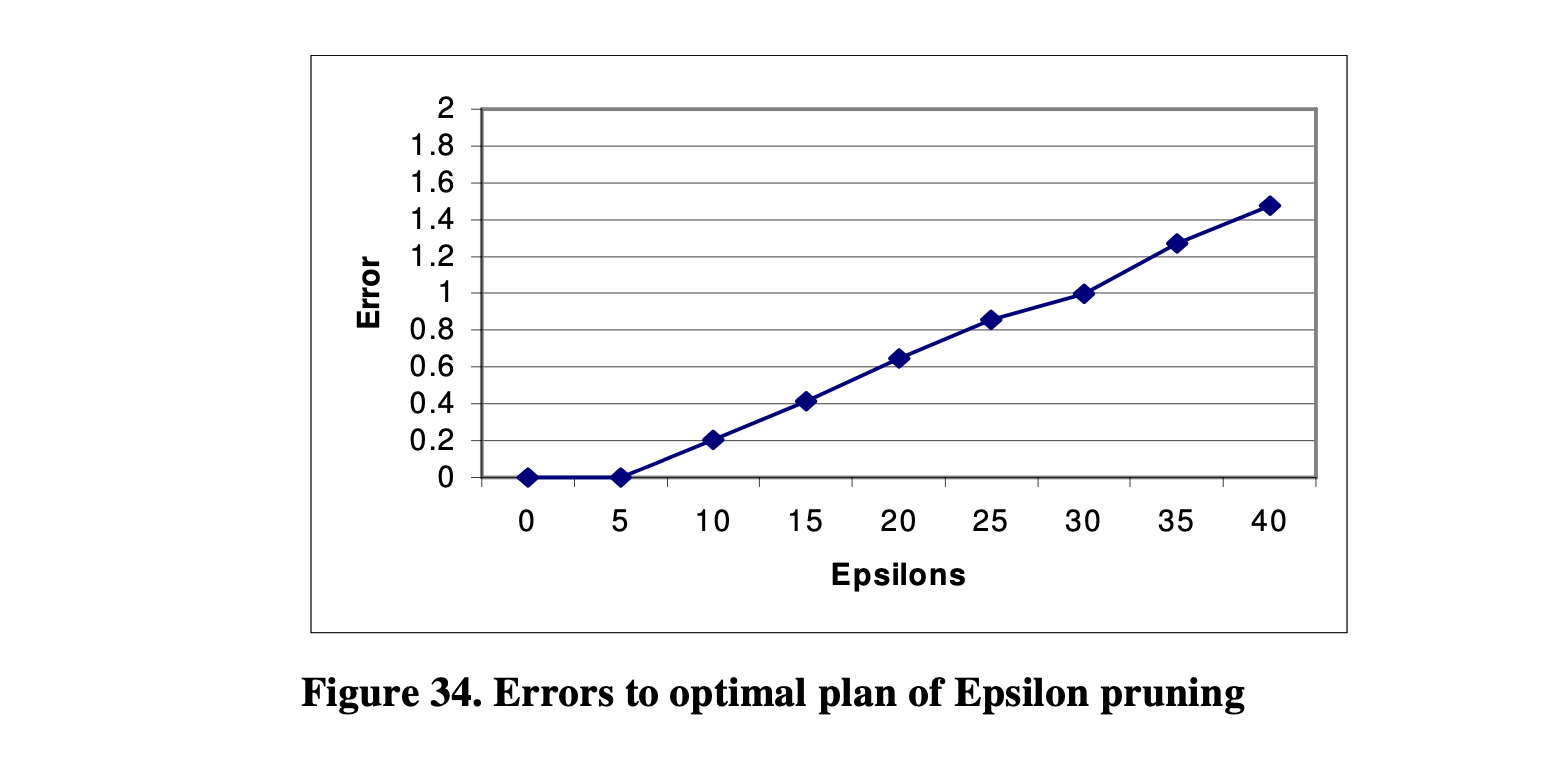
图34
由此可见,通过使用ε剪枝技术,优化器可以快速优化查询并生成接近最优的计划,从而提高了优化器的效率。
总结和未来工作
本论文描述了Columbia查询优化器的设计和实现。通过与其前身Cascades优化器的比较,展示了性能的提升。Columbia优化器的性能表明它在优化大型查询方面具备实用性。许多现代数据库应用程序对高效优化大型查询的能力有着很大需求。
基于Cascades框架的设计,Columbia采用了几种工程技术来提高效率。这些技术包括使用快速哈希函数来消除重复表达式,将逻辑表达式和物理表达式分离在一个组中,使用小型紧凑的数据结构,高效的算法来优化组和输入,以及处理强制规则的高效方式。这些技术最大程度地减少了优化过程中CPU和内存的使用。
Columbia优化器实现了两种剪枝技术。通过使用下界组剪枝,可以在不影响计划质量的情况下显著剪枝搜索空间。在组进行优化之前,可以快速获得组的下界。下界超过搜索限制(上界)的组将被安全地剪枝。Columbia优化器中的另一种剪枝技术是全局ε剪枝。该技术通过生成接近最优解的可接受解来显著剪枝搜索空间。当找到一个与最优解足够接近的解时,优化目标就完成了。对这种剪枝技术的有效性和误差的分析表明,通过仔细选择ε值,优化可以非常高效,并且仍然生成一个可接受的解。
不同的查询类别对优化有很大影响。通过与Cascades优化器在不同的查询类别上进行比较,我们展示了Columbia优化器在优化星型查询时比Cascades优化器表现更好。这表明Columbia优化器中使用的剪枝技术对星型查询比Cascades优化器中的剪枝技术更有效。
除了在Cascades基础上的性能改进外,Columbia还通过使用Windows用户界面与用户进行交互,并支持持续跟踪优化信息来提高可用性。
还有很多额外的工作需要完成来改进Columbia优化器。优化器在优化大型查询时仍然使用大量内存。当优化非常大的查询时,如包含超过16个表的星型查询,内存使用可能变得不可接受。类似于周期性垃圾回收和内存共享的技术可能有助于最小化内存使用。这值得进一步进行系统性的研究。
另一个重要问题是优化器生成的解的正确性。很难证明优化器是否生成了最优计划,或者只是因为优化器中的编程错误而生成了次优计划,特别是在优化大型查询时。尽管Columbia优化器添加了跟踪功能,但证明和调试优化仍然是一个复杂而耗时的任务。一些可视化工具或快速优化验证工具对于实验优化器是有用的。
最后,我们打算将我们的工作扩展到其他类型的查询,如TPC查询、OLAP查询和基于OQL的查询。只要Columbia优化器从Cascades继承了可扩展性,我们希望它可以在保持高效率的同时轻松扩展。
References
Keith Billings, A TPC-D Model for Database Query Optimization in Cascades, M.S. Thesis, Portland State University, Spring 1997.
J.A. Blakeley, W.J. McKenna and G. Graefe, Experiences Building the Open OODB Query Optimizer. Proc. ACM SIGMOD Conf., Washington, DC, May 1993.287
Bob Jenkins, Hash Functions for Hash Table Lookup, Dr. Dobb's Journal, September 1997, pages 107-109.
R.G.G. Cattell, editor, The Object Database Standard: ODMG-93, Release 1.1, Morgan Kaufmann, San Francisco, 1994
Pedro Celis, The Query Optimizer in Tandem's ServerWare SQL Product. Proceedings of the 22th International Conference on Very Large Data Bases, 1996.
R. Elmasri and S. Navathe. Fundamentals of Database Systems, Second Edition, Benjamin-Cummings, 1994
P. Gassner, G. M. Lohman and K. B. Schiefer, Query Optimization in IBM's DB2 Family of DBMSs, IEEE Data Engineering Bulletin, 16(4), December 1993.
G. Graefe, The Cascades Framework for Query Optimization, Bulletin of the Technical Committee on Data Engineering, Vol 18 No. 3, September 1995, Pg 19-29
G. Graefe, The Microsoft Relational Engine, Proceedings of the 12th International Conference on Data Engineering",, May 1996, 160-161.
G. Graefe and D. J. DeWitt, The EXODUS Optimizer Generator, Proceedings ACM SIGMOD Conference, San Francisco, CA, May 1987, 160.
G. Graefe and W . J. McKenna, The V olcano Optimizer Generator: Extensibility and Efficient Search, Proc. IEEE Int’l. Conf. On Data Eng., Vienna, Austria, April 1993, 209.
L.Haas, W.Chang, G.Lohman, etc, Starburst Mid-Flight: As the Dust Clears, IEEE Trans. on Knowledge and Data Engineering, pages 143, Vol. 2, No.1 March 1990
T.Ibaraki and T.Kameda, On the Optimal Nesting order for Computing N-Relational Joins, ACM Trans.on the Database Sys. Vol.9, No. 3, September 1984 , 483
Y.E.Ioannidis. Universality o serial histograms. Proc. of the Conf. On Very Large Database, Aug. 1993
N. Kabra, D. DeWitt, OPT++: An Object-Oriented Implementation for Extensible Database Query Optimization, Proc. ACM SIGMOD Conf. 1996.
W. McKenna, L. Burger, C. Hoang and M. Truong, EROC: A Toolkit for Building NEATO Query Optimizers, PROC VLDB Conf. 1996.
M.Jarke and J. Koch, “Query optimization in Database Systems”, ACM Computing Surveys. 16,2(June 1984),111
F. Ozcan, S. Nural, P. Koksal, M. Altinel, A. Dogac, A Region Based Query Optimizer through Cascades Optimizer Framework, Bulletin of the Technical Committee on Data Engineering, Vol 18 No. 3, September 1995, Pg 30-40.
K. Ono and G. M. Lohman, Measuring the Complexity of Join Enumeration in Query Optimization, Proc. Int’l. Conf. on Very Large Data Bases, Brisbane, Australia, August 1990, 314
V.Poosala, Y.Ioannidis, P.Haas, and E.Shekita. Improved histograms for selectivity estimation of range predicates. ACM SIGMOD Conf. On the Management of Data, Montreal, June 1996
R. Ramakrishnan. Database Management Systems, Second Edition, McGraw-Hill, 1997
P. Selinger, M. Astahan, D. Chamberlin, R. Lorie and T. Price Access Path Selection in a Relational Database Management System, Proceedings of SIGMOD, May 1979
Transaction Processing Performance Council, TPC Benchmark D (Decision Support) Standard Specification Revision 1.1, December, 1995
R.H.Wolniewicz and G.Graefe, Algebraic Optimization of Computations over Scientific Databases, Proc. Intl’ Conf. On Very Large Data Bases, Dublin, Ireland, August 1993, 13
S. Zdonik and D. Maier. Readings in Object-Oriented Database Systems. Morgan Kaufmann, San Mateo, CA, 1990
本文系外文翻译,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系外文翻译,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号