【CVPR2023】Vita-CLIP:通过多模态提示的视频和文本自适应CLIP

【CVPR2023】Vita-CLIP:通过多模态提示的视频和文本自适应CLIP

数据派THU
发布于 2023-04-18 11:41:21
发布于 2023-04-18 11:41:21

来源:专知本文为论文介绍,建议阅读5分钟本文提出一种多模态提示学习方案,在单一统一训练下平衡有监督和零样本的性能。
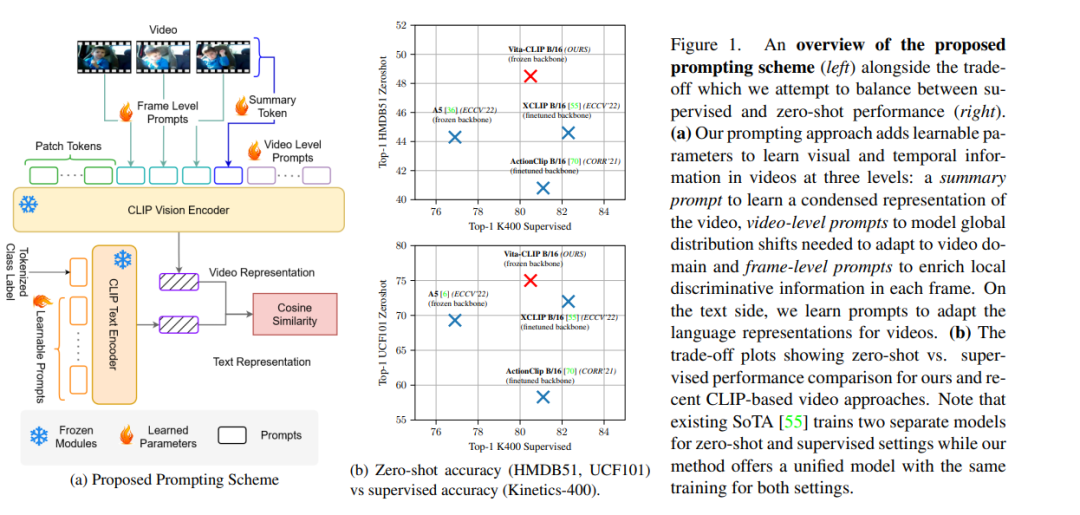
将CLIP等对比图像-文本预训练模型用于视频分类,因其成本效益和具有竞争力的性能而受到关注。然而,最近在这一领域的工作面临一个权衡。对预训练模型进行微调以实现强监督性能,会导致低零样本泛化。类似地,冻结主干以保留零样本能力会导致监督精度的显著下降。因此,最近的文献工作通常为监督和零样本行为识别训练单独的模型。本文提出一种多模态提示学习方案,在单一统一训练下平衡有监督和零样本的性能。视觉方面的提示方法满足了三个方面的需求:1)全局视频级提示对数据分布进行建模;2)局部帧级提示,为每帧提供判别式条件;以及3)用于提取浓缩视频表示的摘要提示。此外,在文本端定义了一个提示方案,以增强文本上下文。通过这种激励方案,可以在Kinetics-600、HMDB51和UCF101上实现最先进的零样本性能,同时在有监督的环境中保持竞争力。通过保持预训练主干冻结,优化了更少的参数数量,并保留了现有的通用表示,这有助于实现强大的零样本性能。我们的代码/模型发布在https://github.com/TalalWasim/Vita-CLIP.

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-04-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号