
在Pandas上循环绘制来自不同DataFrames的行
提问于 2022-03-08 06:17:46
我在Python中有两个不同的DataFrames,一个是实际的收入值,另一个是每天累积的预测值(行的索引)。两个DataFrames具有相同的长度。
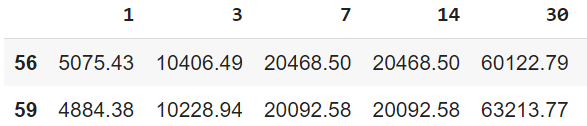
我想在同一幅图上逐行比较它们。如果我只想从每个DataFrame绘制一行,我将使用以下代码:
df_actual.loc[71].T.plot(figsize=(14,10), kind='line')
df_preds.loc[71].T.plot(figsize=(14,10), kind='line')产出如下:
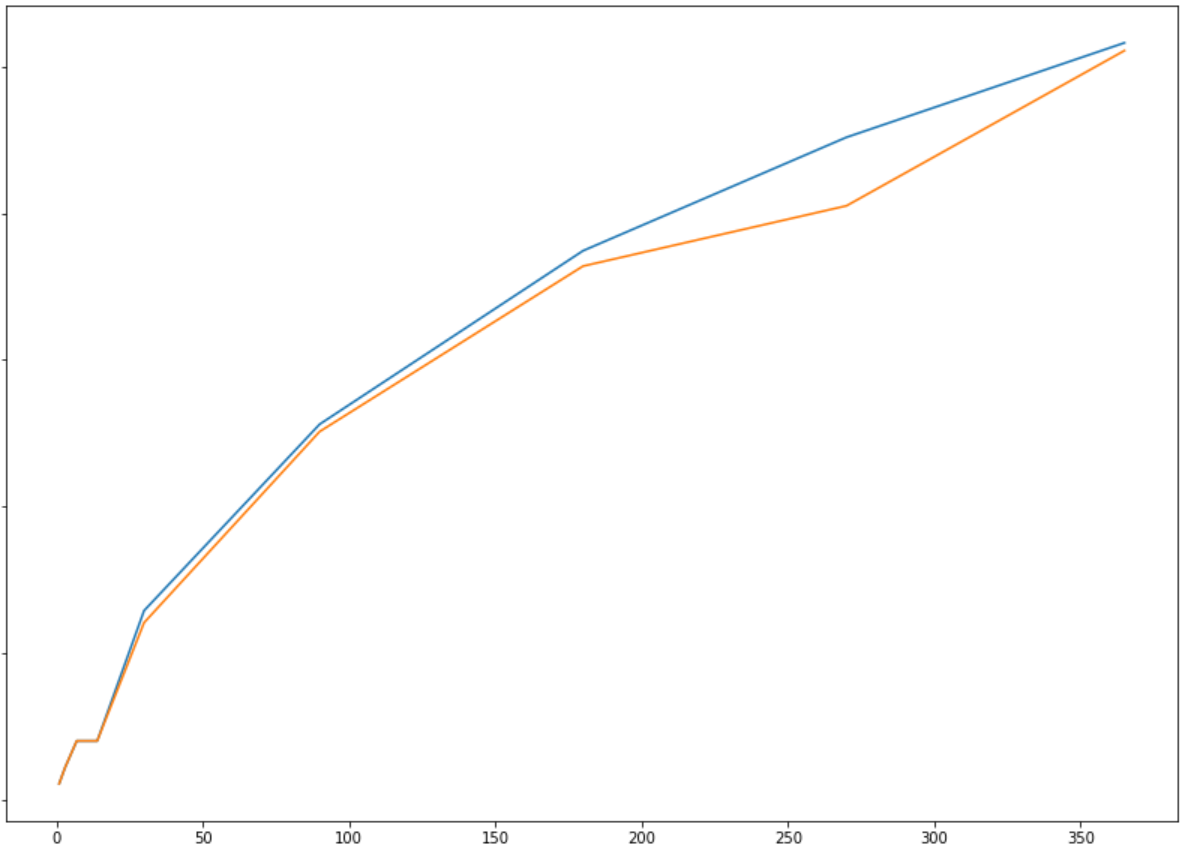
但是,理想的输出是为网格中的每个DataFrame拥有所有行,这样我就可以比较所有的结果:
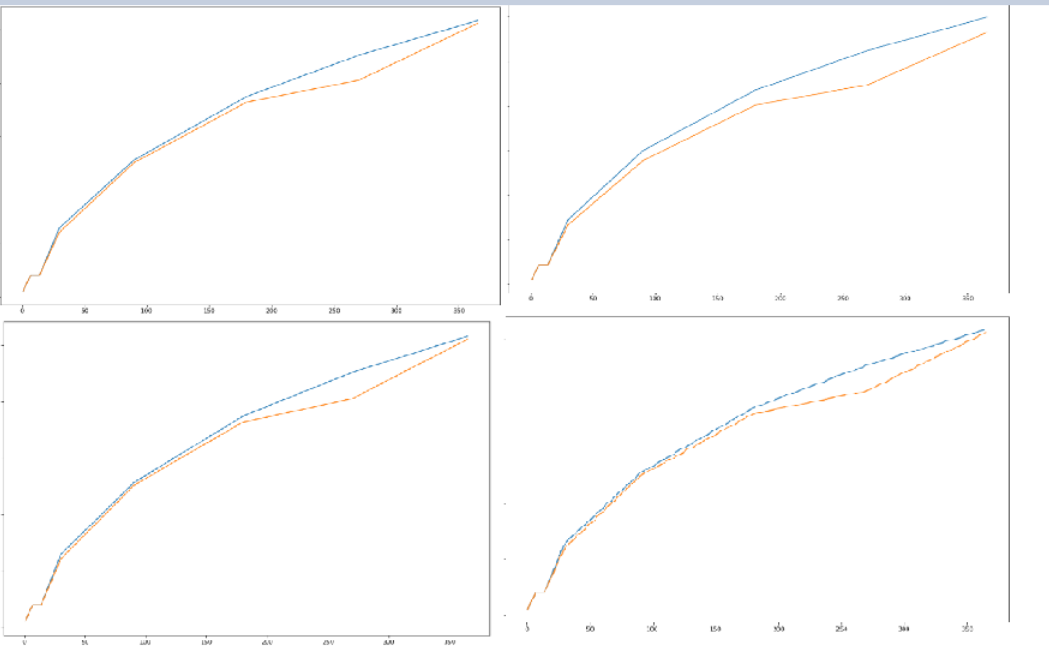
我尝试创建一个for循环来遍历每一行,但是它不起作用:
for i in range(20):
df_actual.loc[i].T.plot(figsize=(14,10), kind='line')
df_preds.loc[i].T.plot(figsize=(14,10), kind='line')有什么方法可以做到这不是手动吗?谢谢!

回答 1
Stack Overflow用户
回答已采纳
发布于 2022-03-08 06:42:51
如果您提供了dfs的示例,这将是有帮助的。
假设两个dfs都有相同的长度&假设您需要2列,请尝试如下:
fig, ax = plt.subplots(round(len(df_actual)/2),2)
ax.ravel()
for i in range(len(ax)):
sns.lineplot(df_actual.loc[i].T, ax=ax[i], color="navy")
sns.lineplot(df_preds.loc[i].T, ax=ax[i], color="orange")编辑:这对我有用(您只需添加您的.T):
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
df_actual = pd.DataFrame(data=[[1,2,3,4,5], [6,7,8,9,10]], columns = ["col1","col2", "col3", "col4", "col5"])
df_pred = pd.DataFrame(data=[[3,4,5,6,7], [8,9,10,11,12]], columns = ["col1", "col2", "col3", "col4", "col5"])
fig, ax = plt.subplots(round(len(df_actual)/2),2)
ax.ravel()
for i in range(len(ax)):
ax[i].plot(df_actual.loc[i], color="navy")
ax[i].plot(df_pred.loc[i], color="orange")页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71396510
复制








腾讯云开发者
