惊了,Doris 4.1 把十亿级向量检索拉下神坛?


见字如面,我是一臻
90后新手奶爸,探索Doris x AI Agent
点击关注 👇 免费获取数智AI知识库
“上周五下午六点,隔壁司的老王端着保温杯走来,脸上写满了疲惫:
兄弟,我们那套 向量库 集群又炸了,128G 内存撑不住了,老板让我周末扩容。他顿了顿,关键是隔壁还跑着一套 MySQL 存业务数据,两边数据同步又出了幺蛾子,用户投诉说推荐结果和实际库存对不上。...... 过去一年,几乎每个上了 RAG 或者向量推荐的团队,都在重复同一个剧本——先兴冲冲搭一套向量库,跑通 Demo 皆大欢喜,然后数据量一上来,内存账单像坐火箭,混合查询像缝补丁,DBA同学开始失眠。 向量检索这件事,技术上早就不新鲜了。真正让人头疼的从来不是能不能搜出来,是搜出来之后,钱包和架构还撑不撑得住。

内存这笔账,该算清楚了
先来做道数学题。
一百万个 768 维的 float32 向量,裸数据 3GB。
听起来不多对吧?
但 HNSW 索引的图结构得常驻内存,常用参数下额外吃掉大约 6GB。一共 9GB,一百万条数据而已。
把这个数字乘以一千,十亿向量,索引加数据逼近1TB内存。一台 128G 内存的机器,得买八台才够。这还没算副本、没算其他业务负载、没算运维预留。
老王那天的绝望,根源就在这里。
HNSW 确实快,召回率也高,但它的设计哲学是全部搁内存里才舒服。中小规模没问题,一旦数据进入十亿级别,就变成了"m爷爷的游戏"。
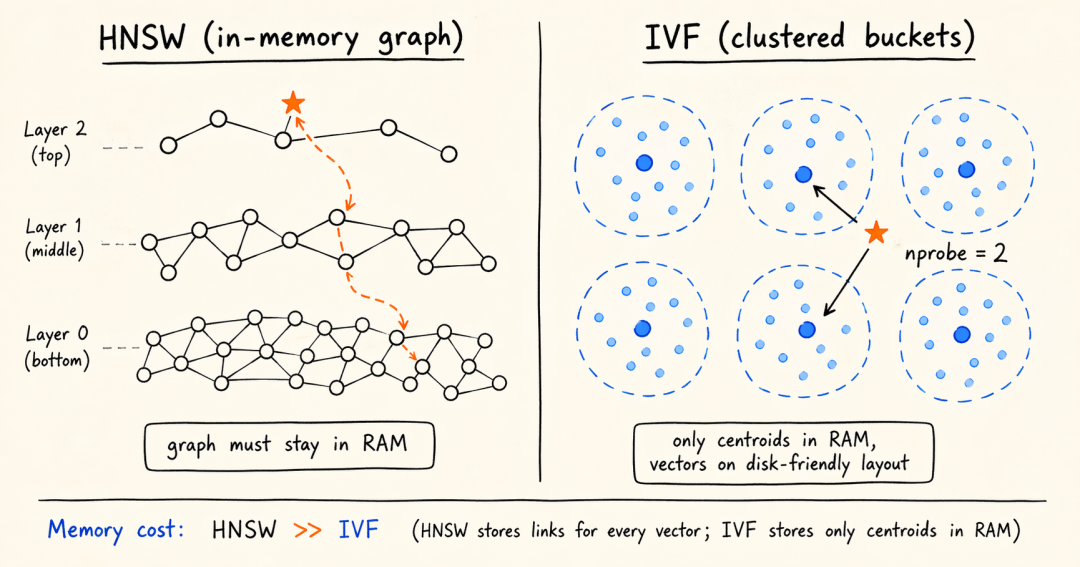
Doris 4.1 给出的答案是 IVF 加磁盘分层:
CREATE TABLE vecs (
idBIGINTNOTNULL,
embedding ARRAY<FLOAT> NOTNULL,
INDEX idx_emb (embedding) USING ANN PROPERTIES (
"index_type" = "ivf",
"metric_type" = "l2_distance",
"dim" = "768",
"nlist" = "1024"
)
) ENGINE=OLAP
DUPLICATEKEY(id)
DISTRIBUTEDBYHASH(id) BUCKETS 8
PROPERTIES ("replication_num" = "1");
思路说起来朴素——先把向量聚类成N个桶,查询时只翻最相关的几个桶就行了,不用全图遍历。
桶的数据可以放磁盘,内存里只保留聚类中心这个目录。
再结合 IVF_ON_DISK配上乘积量化 PQ,768 维向量从 3072 字节压到 64 字节,压缩比接近 48 倍。

实际跑起来什么感受?
同样十亿级数据,内存需求从 TB 级直接降到两位数 GB 级。一台普通的商用服务器就能扛住。
省下的m爷爷,够老王的团队吃N年下午茶了。
有人可能担心:数据搁磁盘上,不慢死了吗?
这里有个反直觉的事实——向量查询具有极强的局部性。
连续到达的查询往往命中相同的热点簇,SSD 上的缓存命中率高得出奇。
官方测试数据显示,IVF_ON_DISK 的 QPS 可以非常接近纯内存 IVF。
便宜和快,在合理的工程设计下并不矛盾。
900 QPS 背后那个关键优化
成本问题解决了,但生产环境最终拍板的那个人,往往还要问一句:延迟和吞吐能不能打?
列式数据库做向量检索有个天然的痛点:选完桶、排完序之后,还得回表读原始向量列来做精确距离计算。
这一步本质上是随机 I/O,在百万级数据上就能把吞吐量拖到地板上。
Doris 4.1 引入了一个叫 ANN Index Only Scan 的机制。
原理类似关系数据库里的覆盖索引——如果你的查询只需要 ID 和距离分数,那根本不用回表翻原始向量列,索引里存的量化向量就够算距离了。
这个优化看起来很小,效果却非常暴力。
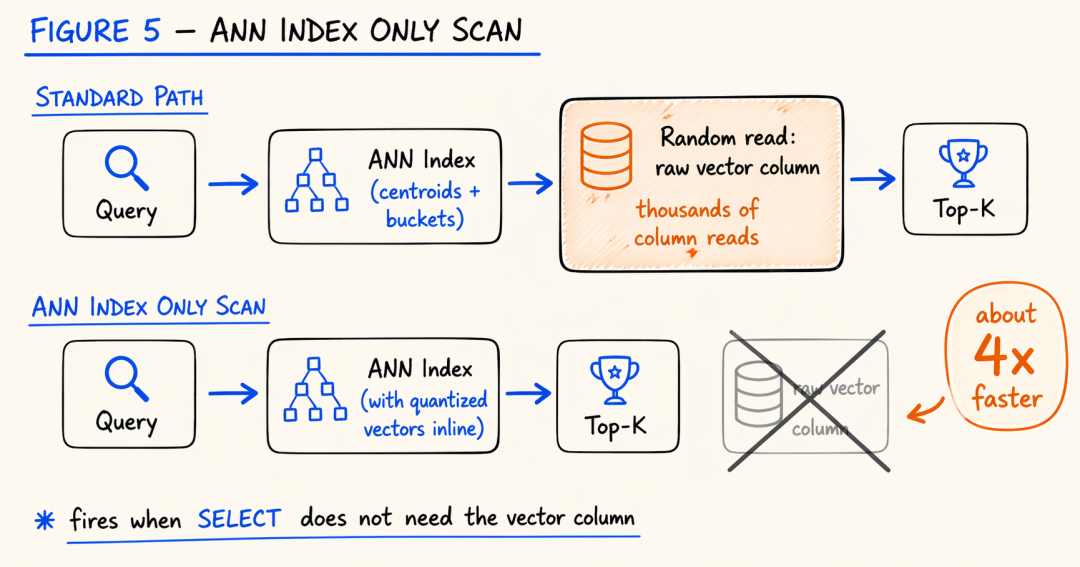
在官方基准测试里(100 万 × 768 维,TopK-10),Standard Path 大概 200 出头的 QPS,开了 Index Only Scan 之后直接拉到 900 QPS,召回率仍然维持在 97%。
四倍性能提升,不靠堆硬件,纯靠少做一次 I/O。
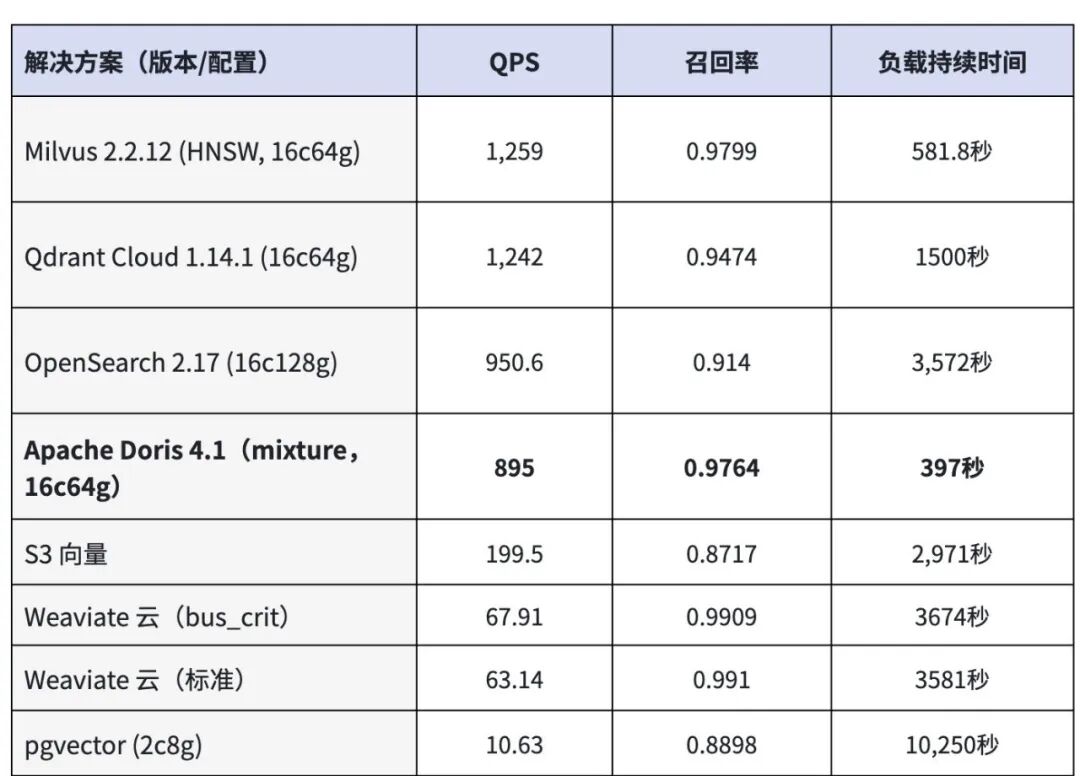
在 VectorDBBench 的公开榜单上,Doris 4.1 的索引构建速度 397 秒是最快的,比 其它向量库 快 30%,比 pgvector 快了十倍以上。
QPS 895 和 OpenSearch 一个梯队,召回率 0.97 也站在第一阵营。
考虑到它还自带完整的分析能力和混合查询,这个成绩单在性价比维度上相当能打。
如果想了解更多,欢迎预约 6.11 SelectDB 产品发布会👆
一条 SQL 搞定既要又要
回到老王那个真实的痛苦——数据同步。他的向量库只管搜相似商品,但有没有库存、价格区间、用户权限这些过滤条件存在另一个系统里。
每次查询得先去向量库捞一批候选,再拿着 ID 列表去业务库过滤,过滤完可能结果不够还得再回向量库捞一轮。延迟翻倍,代码恶心,数据一致性全靠祈祷。
这其实是个架构层面的结构性问题。专用向量库天生就是数据栈之外的一个孤岛,你用得越深,为它搭的桥就越多。
Doris 做这件事的逻辑很直接:向量列和业务列住同一张表里,过滤和检索在同一条 SQL 里完成。
优化器会根据过滤条件的选择性自动选路径——如果结构化条件能把候选集砍到很小,就先过滤再在子集上算精确距离;如果过滤选择性低,就先走向量索引再后过滤。
开发者不用操心策略选择,写一条正常的 SQL 就行。
更有意思的是多路召回的场景。
做搜索的同学都知道,单纯靠向量召回会丢关键词精确匹配的结果,单纯靠 BM25 又捞不到语义相关但字面不同的内容。两路结果的分数尺度完全不一样,L2 距离和 BM25 分数之间没有可直接加权的基础。
业界通行做法是 RRF——不看分数只看排名,把每个候选在各通道中的排名倒数加起来作为最终得分。
在 Doris 里,这整个流程用一条带 CTE 的 SQL 就写完了:倒排索引和向量索引并行跑,各取 Top-N,窗口函数分配排名,一个 GROUP BY 完成融合排序。
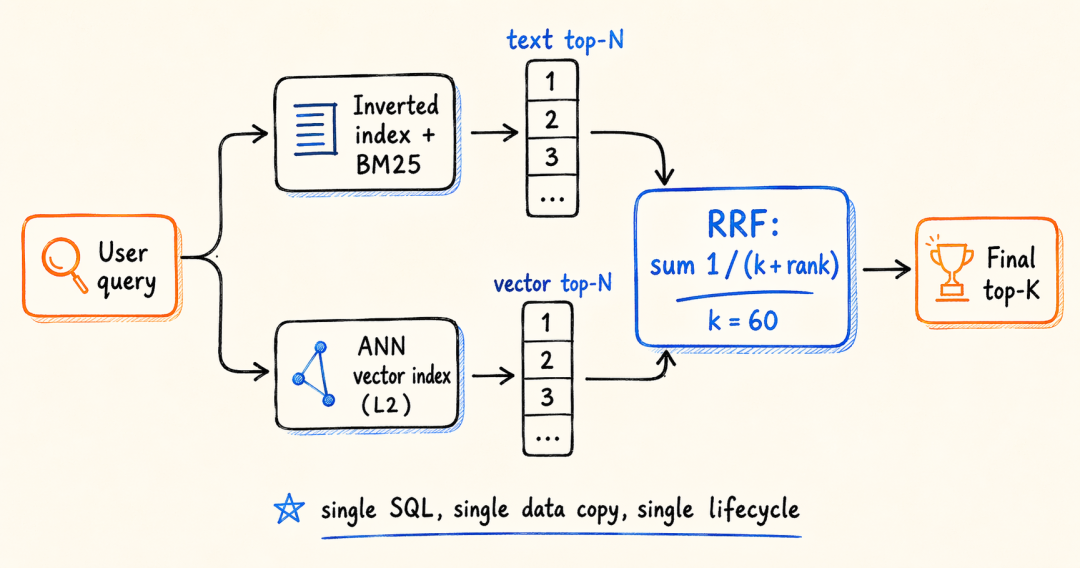
关键不在于 RRF 算法本身——这东西在哪儿都能写。
在于两个检索通道共享同一份数据、同一套事务可见性、同一套生命周期管理。
想加第三路召回?
多写一个 CTE 就行,不用多引一个系统、多维护一条同步链路。
结语
上周末老王没有加班扩容。
他花了一个下午把向量列加进了现有的 Doris 表里,跑通了带过滤条件的混合查询,然后心满意足地关上了电脑。
这不是什么惊天动地的技术革命。向量检索的核心算法——IVF、HNSW——学术界十年前就发表了。
Doris 做的事情更像是一次工程层面的归位:把向量检索从一个需要单独运维的外挂系统,变成数据库里一条普通索引该有的样子。建表时加一行 INDEX 声明,查询时写标准 SQL,扩缩容跟着集群走,数据一致性由引擎保证。
行业正在经历一个有意思的轮回。
当年全文检索也是独立系统,后来被各大数据库吸收为原生能力。向量检索正在走同一条路。
当它不再需要专门的集群、专门的运维、专门的数据同步管道时,开发者才能真正把精力放回那个最该关注的问题上——用 AI 做出用户真正需要的东西,而不是跟基础设施天天扯皮。

完
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号