手撕 GPT#06:手把手 30 分钟:零基础跑通你的第一个 GPT

手撕 GPT#06:手把手 30 分钟:零基础跑通你的第一个 GPT

烟雨平生
发布于 2026-05-29 13:12:11
发布于 2026-05-29 13:12:11
前几篇文章讲了原理、讲了架构、讲了踩坑。今天只做一件事:
带你从零跑通一个能回答中文问题的 GPT。
不需要 GPU,不需要云服务器,不需要任何深度学习经验。
你需要的东西:一台电脑,30 分钟。
零、你会得到什么
训练完成时,你会看到:
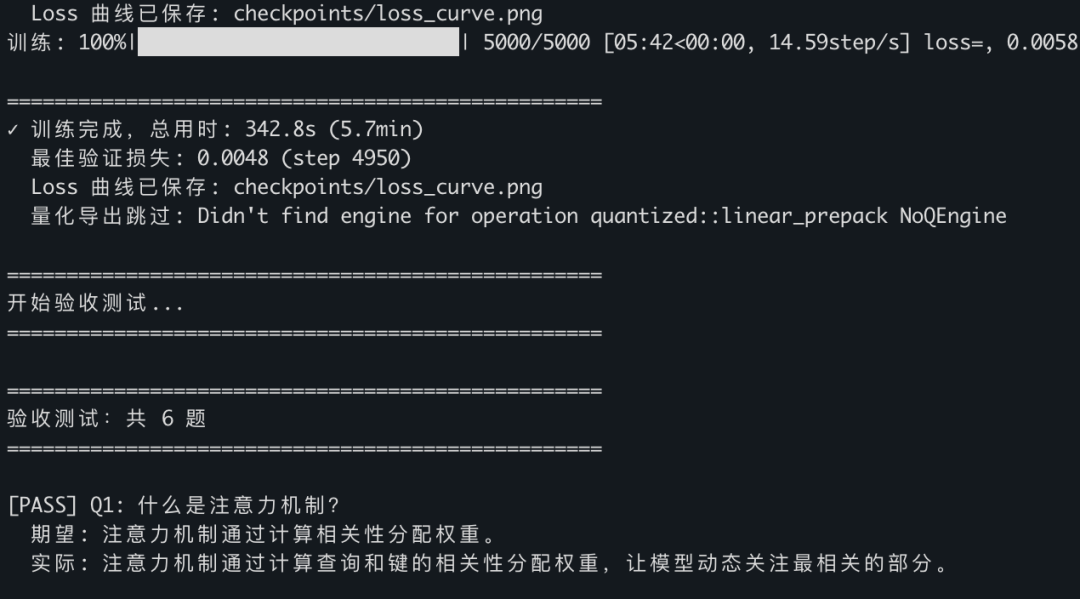
问它几个问题:
问:什么是注意力机制? 答:注意力机制通过计算查询和键的相关性分配权重,让模型动态关注最相关的部分。 问:你是谁? 答:我是一个基于 Transformer 的小型 GPT 教学演示模型。
从零训练的,不是调 API,不是微调。 模型只有 3.16M 参数——还没你手机里一张照片大。
好,开始。
一、装环境(5 分钟)
你只需要装一个工具:uv。它比 pip 快 100 倍,自动管理 Python 版本。
▪ Mac / Linux
# 装uv(一行命令) curl -LsSf https://astral.sh/uv/install.sh | sh # 重启终端让 uv 生效
▪ Windows
# PowerShell 里执行 powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
装好了验证一下:
uv --version # 输出类似:uv 0.4.x
二、克隆项目(1 分钟)
git clone https://github.com/helloworldtang/GPT_teacher-3.37M-cn.git cd GPT_teacher-3.37M-cn
看一下项目结构:
GPT_teacher-3.37M-cn/ ├── config/config.yml #模型和训练配置 ├── data/ #训练数据(JSONL 格式) ├── tokenizer/ #分词器 ├── checkpoints/ #预训练模型(可以直接用) ├── src/ │ ├── model.py #模型定义(193 行,核心) │ ├── train.py #训练脚本 │ ├── infer.py #推理脚本 │ ├── evaluate.py #验收测试 │ ├── web_demo.py #Web演示界面 │ └── visualize.py #注意力和分词可视化 └── notebooks/ └── tutorial.ipynb #Jupyter教程
三、安装依赖(2 分钟)
# 创建虚拟环境 + 安装依赖(uv 会自动处理一切) uv sync
等它跑完,大概 1-2 分钟。会装 PyTorch、Gradio 等依赖。
如果你在国内网络慢,可以先设镜像:
export UV_INDEX_URL=https://mirrors.aliyun.com/pypi/simple/ uv sync
四、先体验预训练模型(1 分钟)
项目自带训练好的模型。先跑一下,确认环境没问题:
uv run python -m src.evaluate
你会看到:
加载模型: checkpoints/best.pt 模型参数量: 3,161,600 (3.16M) 验收测试:共 6 题 [PASS] Q1: 什么是注意力机制? 期望: 注意力机制通过计算查询和键的相关性分配权重... 实际: 注意力机制通过计算查询和键的相关性分配权重... [PASS] Q2: RoPE 是什么? ... 结果: 6/6 通过 (100%) 验收通过!
6/6。一个 3M 的模型,从零训练的,答对了所有测试题。
如果到这一步没报错,说明环境没问题。继续。
五、看看训练数据(2 分钟)
在训练之前,先看看模型要学什么:
# 看前 3 条训练数据 head -3 data/train.jsonl
每条数据长这样:
{"text": "用:什么是注意力机制?\n助手:注意力机制通过计算查询和键的相关性分配权重,让模型动态关注最相关的部分。"}
格式很简单:用:问题\n助手:答案。
模型的任务就是学会:看到"用:xxx",生成"助手:yyy"。
六、开始训练(5-30 分钟)
uv run python -m src.train
你会看到 loss 从高到低:
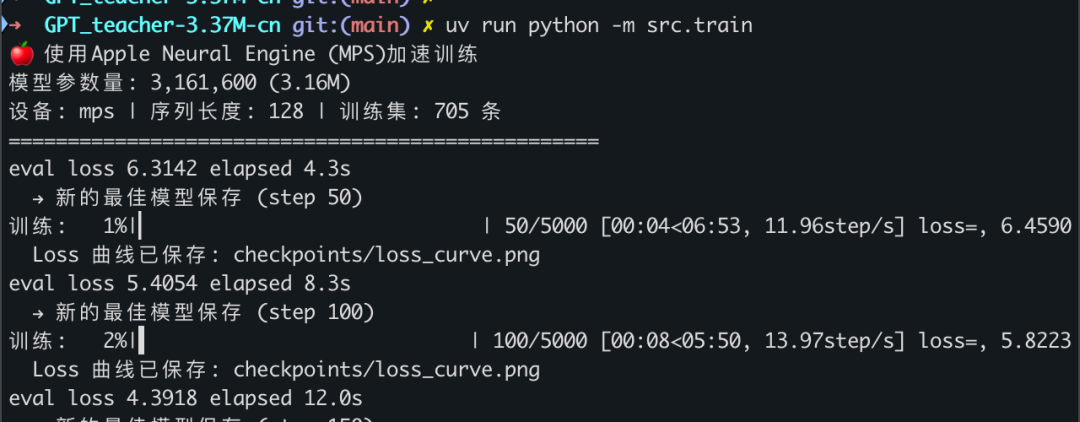
训练时间参考:
- Mac M1/M2/M3(MPS 加速):5-6 分钟
- 普通 CPU:30-60 分钟
- 有 GPU(CUDA):2-3 分钟
训练完自动验收,不用你手动检查。
七、问模型问题(1 分钟)
训练完了,亲手问问看:
uv run python -c " from src.infer import generate print(generate('什么是注意力机制?')) print() print(generate('你是谁?')) "
输出:
注意力机制通过计算查询和键的相关性分配权重,让模型动态关注最相关的部分。 我是一个基于 Transformer 的小型 GPT 教学演示模型。
你自己训练的模型,能回答问题了。
八、Web 演示(秒开)
想要一个更好看的界面?
uv run python src/web_demo.py
打开浏览器 http://127.0.0.1:7860 ,你会看到一个问答界面。
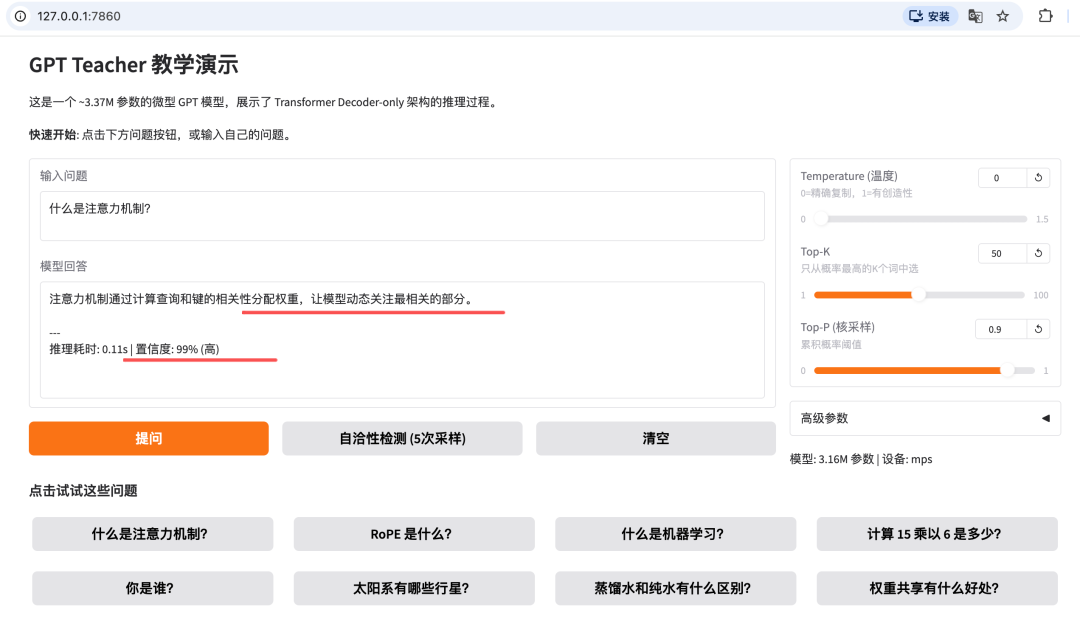
点击预设的问题,或者输入自己的问题,模型实时回答。
九、看模型在"看什么"——注意力可视化
这是我觉得最酷的部分。你可以看到模型在回答每个字的时候,注意力在看哪里:
uv run python -m src.visualize --only real_attention --prompt "什么是注意力机制?"
会生成一张热力图,保存到 docs/ 目录。
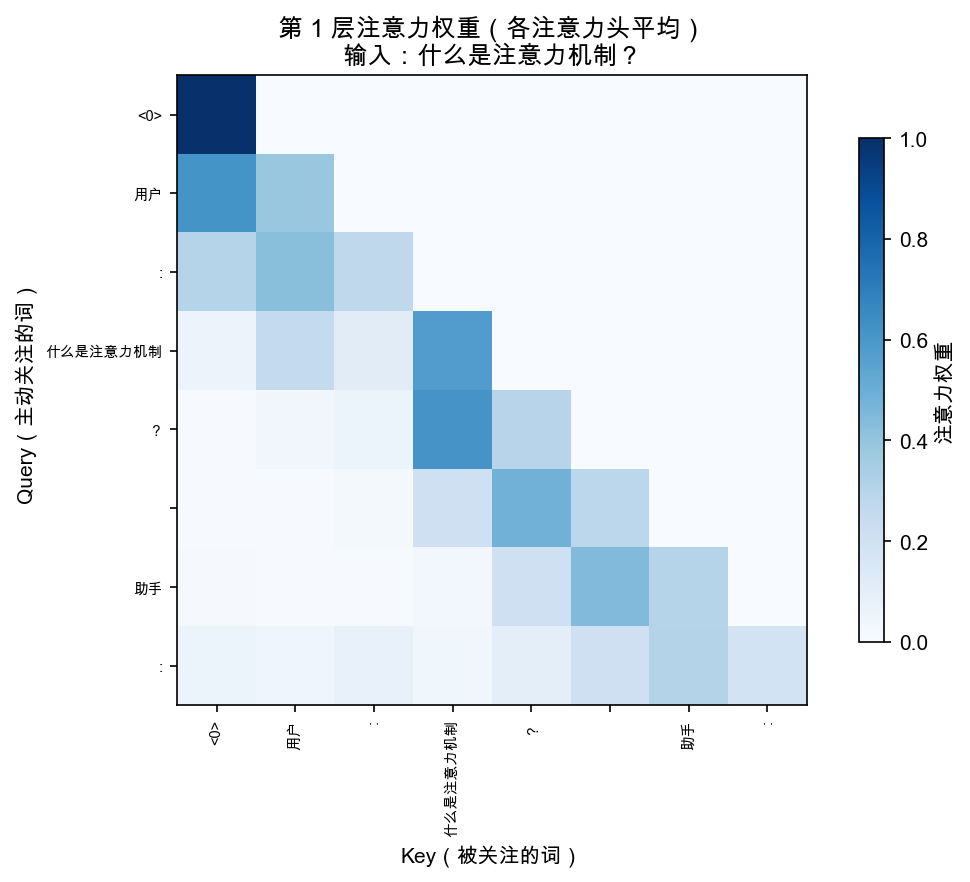
你能看到:模型在写"注意力"这个词的时候,目光确实在看问题里的"注意力"三个字。
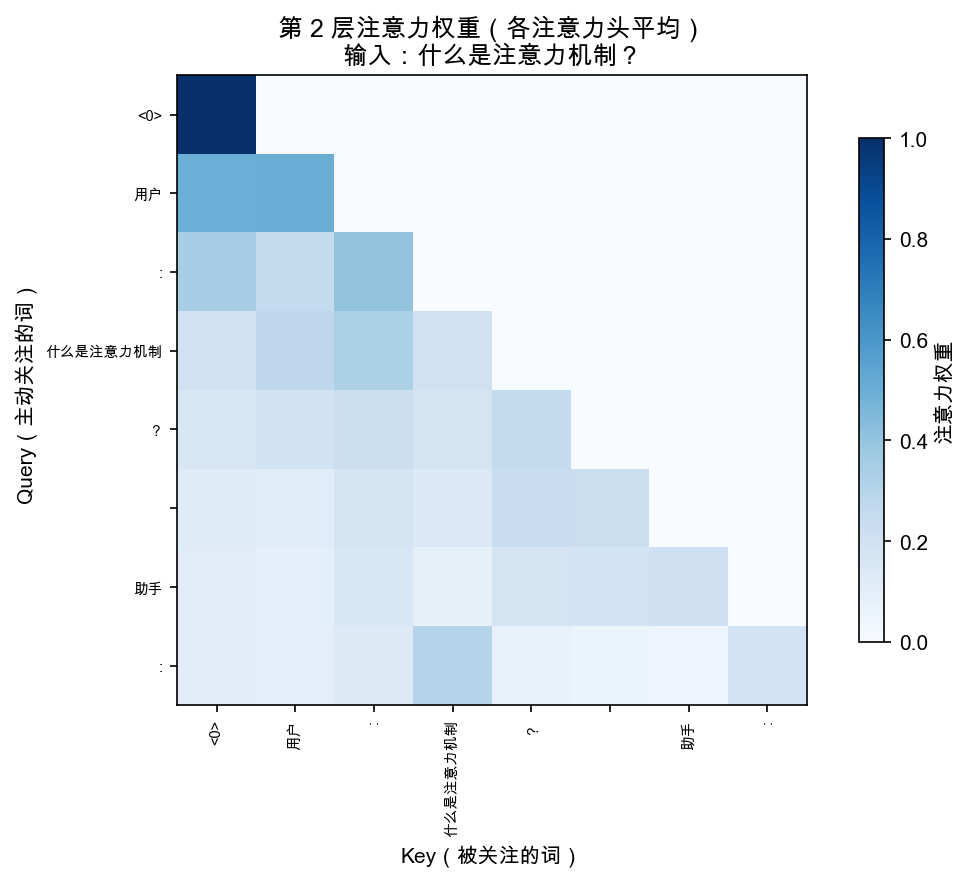
这不是巧合,这就是注意力机制在起作用。
十、遇到问题?
▪ Q:uv sync 报错 / 网络超时
# 用国内镜像 export UV_INDEX_URL=https://mirrors.aliyun.com/pypi/simple/ uv sync
▪ Q:训练很慢
确认是否用了加速设备:
# Mac 用户应该看到 "设备: mps" # 如果看到 "设备: cpu",说明 MPS 没启用 # 检查:uv run python -c "import torch; print(torch.backends.mps.is_available())"
▪ Q:验收没通过(比如 5/6 或 4/6)
很正常。3M 模型对随机种子敏感,再跑一次可能就过了:
uv run python -m src.train
▪ Q:想训练更大的模型
编辑 config/config.yml:
model: n_embd: 384 #256→384(更宽) n_layer: 6 #4→6(更深) n_head: 6 #4→6
大约 10M 参数,效果更好,MPS 训练 10-20 分钟。
▪ Q:想看代码但不知道从哪开始
按这个顺序读:
src/model.py— 模型定义,193 行,核心中的核心
src/train.py— 训练循环,看 loss 怎么算、怎么反向传播src/infer.py— 推理过程,看模型怎么一个字一个字地生成
十一、你刚刚做了什么?
如果一路跑通了,恭喜。你刚刚完成了:
- ✅ 从零训练了一个 GPT(不是微调,不是调 API)
- ✅ 模型能正确回答中文问题
- ✅ 看到了注意力可视化——模型真的在"看"问题
- ✅ 搭建了 Web 演示界面
这不是玩具。虽然只有 3M 参数,但架构和 Llama 一样:GQA 注意力、SwiGLU 激活函数、RoPE 位置编码、RMSNorm 归一化。你训练的每一步,和训练一个 70B 模型的原理完全相同。
区别只是规模,不是原理。
十二、跑完了,然后呢?
你可能正在想:3M 模型只能答 6 道题,然后呢?我能用它做什么?
这个问题的答案分两条路:
▪ 路线 A:继续深入原理(免费,只要电脑)
改 config/config.yml 的参数,看模型大小和效果的关系这条路的终点: 你能看懂任何 LLM 论文(Llama、GPT-4、Mistral),因为架构你已经手撕过了。
▪ 路线 B:往实战方向走(需要 GPU 或云服务器)
阶段 | 做什么 | 需要什么 |
|---|---|---|
1. 加自己的数据 | 修改 data/train.jsonl,换成你想教模型的内容 | 只需电脑 |
2. 训练更大的模型 | 调 config 参数到 10M-30M | Mac M 芯片或 GPU |
3. 微调开源模型 | 用 Hugging Face 上的预训练模型做 LoRA 微调 | 一张 GPU(或 Colab 免费 T4) |
4. 部署模型服务 | 用 vLLM、Ollama 把模型跑成 API | 云服务器 |
路线 B 的关键一步是第 3 步:微调。 你已经理解了"从零训练"的全过程,微调只是在已经训练好的大模型上,用你自己的数据再做一轮训练。原理一样,只是起点不再是随机数字,而是一个已经会说话的模型。
推荐入门路径:
国内:魔搭 ModelScope 库 + LoRA 微调 + 魔搭 Notebook(免费 GPU)。
国外:Hugging Face 的 Transformers 库 + LoRA 微调 + Google Colab(免费 GPU)。
▪ 不管走哪条路,你已经不是零了
很多人被挡在"模型训练"门外,不是因为没有 GPU,而是因为:
- 不敢动手(觉得需要先学很多数学)
- 不知道从哪开始(教程要么太理论,要么太黑箱)
- 跑通了一个 demo 但不知道自己做了什么
你现在:
- ✅ 从零训练了一个 GPT,不是黑箱
- ✅ 知道模型里面就是 316 万个数字
- ✅ 知道训练就是反复调整这些数字
- ✅ 知道 loss 骗人,数据比架构重要
- ✅ 知道 Llama 的每个改动解决什么问题
这些就是"打破枷锁"的那个起点。 从这里出发,无论读论文、看开源项目、还是自己动手,你都有了根基。
训练完了但不知道下一步做什么?系列最后一篇总结了你现在会了什么,还讲了接下来的路怎么走。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号