AI多任务学习在药物设计中的应用:原理、架构与前沿挑战

AI多任务学习在药物设计中的应用:原理、架构与前沿挑战

DrugIntel
发布于 2026-05-20 12:48:26
发布于 2026-05-20 12:48:26

文献来源:Allenspach S, Hiss JA & Schneider G. Neural multi-task learning in drug design. Nature Machine Intelligence, 2024, 6: 124–137. DOI:10.1038/s42256-023-00785-4 作者单位:ETH Zurich,化学与应用生物科学系
写在前面
新药研发是一项耗时漫长、成本极高的系统工程。化学空间的浩瀚(估计包含 至 个可合成有机分子,乃至多达 个符合 Lipinski 类药五原则的分子)使得对候选药物的高通量计算筛选成为早期药物发现的核心任务。
近年来,深度学习在计算机视觉、自然语言处理、蛋白质结构预测(AlphaFold)等领域取得了突破性进展,极大地激发了研究者将其应用于药物设计的热情。多任务学习(Multi-Task Learning, MTL)作为一种能够同时利用多个相关任务信息、提升模型泛化能力的机器学习范式,近年来在计算机辅助药物设计(Computer-Assisted Drug Design, CADD)领域受到了广泛关注。
本文对发表于 Nature Machine Intelligence(2024)的综述论文进行系统梳理,重点介绍神经 MTL 模型的核心原理、架构分类、典型应用场景及当前面临的主要挑战,以期为从事相关研究的读者提供参考。
一、多任务学习的基本原理
1.1 从单任务学习到多任务学习
在传统的单任务学习(Single-Task Learning, STL)中,每个模型仅针对单一任务进行训练,任务间的信息相互独立,无法共享。当数据量有限时,STL 模型容易对特定任务的数据产生过拟合。
相比之下,MTL 允许一个模型同时学习多个任务之间的关系,通过共享参数和信息,实现跨任务的知识迁移。其核心优势体现在以下几个维度:
比较维度 | 单任务学习(STL) | 多任务学习(MTL) |
|---|---|---|
过拟合风险 | 较高(单任务数据有限) | 较低(多任务自然正则化) |
数据需求 | 每任务需大量数据 | 可从关联任务借力 |
模型数量 | M 个任务需 M 个模型 | 理论上一个模型可覆盖 |
对新任务的泛化 | 需重新训练 | 归纳型 MTL 可零样本预测 |
任务相关性依赖 | 无依赖 | 高度依赖任务相关性 |
值得注意的是,任务的选择是 MTL 成功的关键:引入过多不相关任务反而会"干扰"模型的学习,导致负迁移(Negative Transfer),使其表现不如对应的 STL 模型。
1.2 配对输入 MTL 框架
本文的一个重要理论贡献是将 MTL 统一表述为配对输入预测问题(Pair-Input Prediction):给定一个"实例-任务"对 ,模型预测二者之间的关系 。
这一框架可用关系矩阵(Relation Matrix)直观呈现:行代表实例(如分子),列代表任务(如蛋白质靶标),矩阵元素为对应的关系值(如结合亲和力)。矩阵中存在大量缺失值(问号),模型的任务即为矩阵补全(Matrix Completion)或矩阵扩展(Matrix Extension)。

药物设计中的两类典型应用:
- • 药物重定向(Drug Repurposing):预测已知分子与已知蛋白质的结合亲和力 → 对实例和任务均为转导性(Transductive)预测
- • 虚拟筛选(Virtual Screening):预测新颖分子与已知或新蛋白质的结合亲和力 → 需要对实例(乃至任务)具备归纳性(Inductive)预测能力
1.3 转导性与归纳性:MTL 模型的核心分类维度
分类 | 实例层面 | 任务层面 |
|---|---|---|
转导性(Transductive) | 仅预测训练集中已见实例 | 仅预测训练集中已见任务 |
归纳性(Inductive) | 可预测训练时未见的新实例 | 可预测训练时未见的新任务 |
独热编码(One-Hot Encoding)表示的任务或实例,因缺乏内在关联信息,只能用于转导性预测。而使用结构化表征(如氨基酸序列、蛋白质图)的模型,则有潜力实现对新蛋白质(新任务)的归纳性泛化。
1.4 与相关学习范式的对比
学习范式 | 核心逻辑 | 与 MTL 的区别 |
|---|---|---|
迁移学习(Transfer Learning) | 在任务间顺序学习知识迁移 | MTL 是并发学习多任务,迁移学习是序贯的 |
元学习(Meta-Learning) | 提取"如何快速学习新任务"的元知识 | 关注学习过程本身,MTL 关注任务间的共享结构 |
多模态学习(Multi-Modal Learning) | 融合多种数据模态描述同一实体 | MTL构建跨任务的共享实例表征;多模态学习构建跨模态的单任务统一表征 |
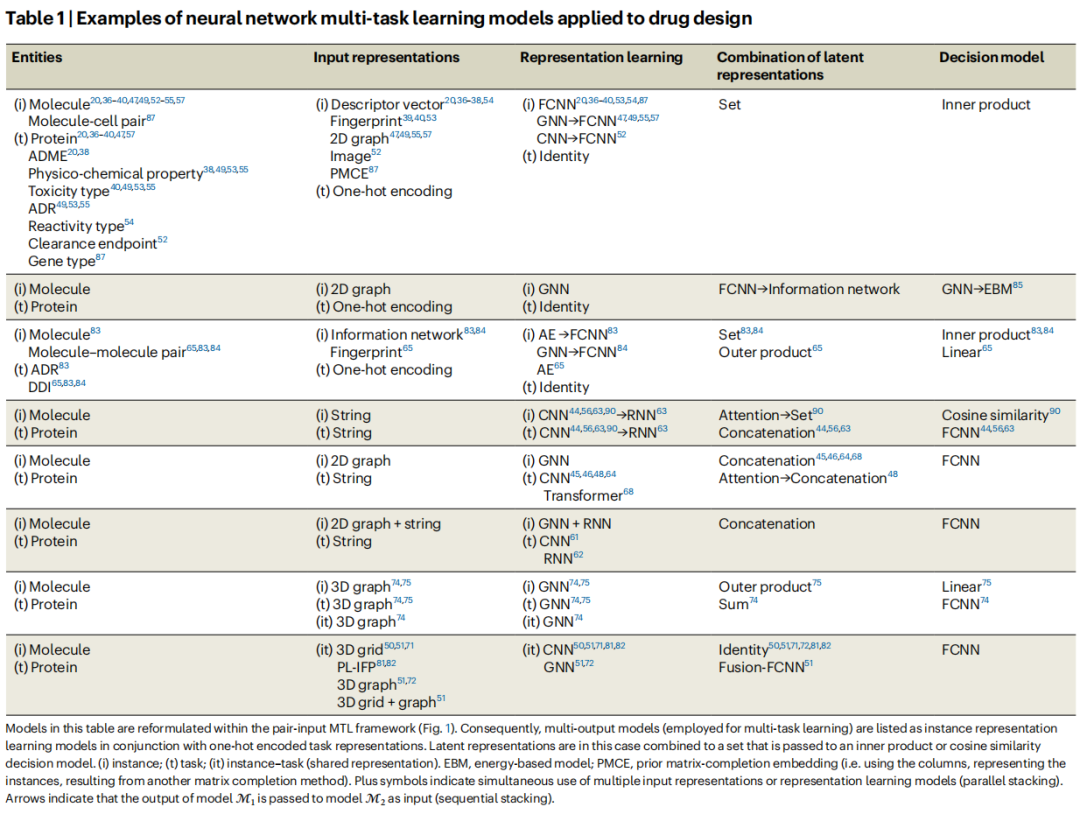
二、神经 MTL 模型的架构框架
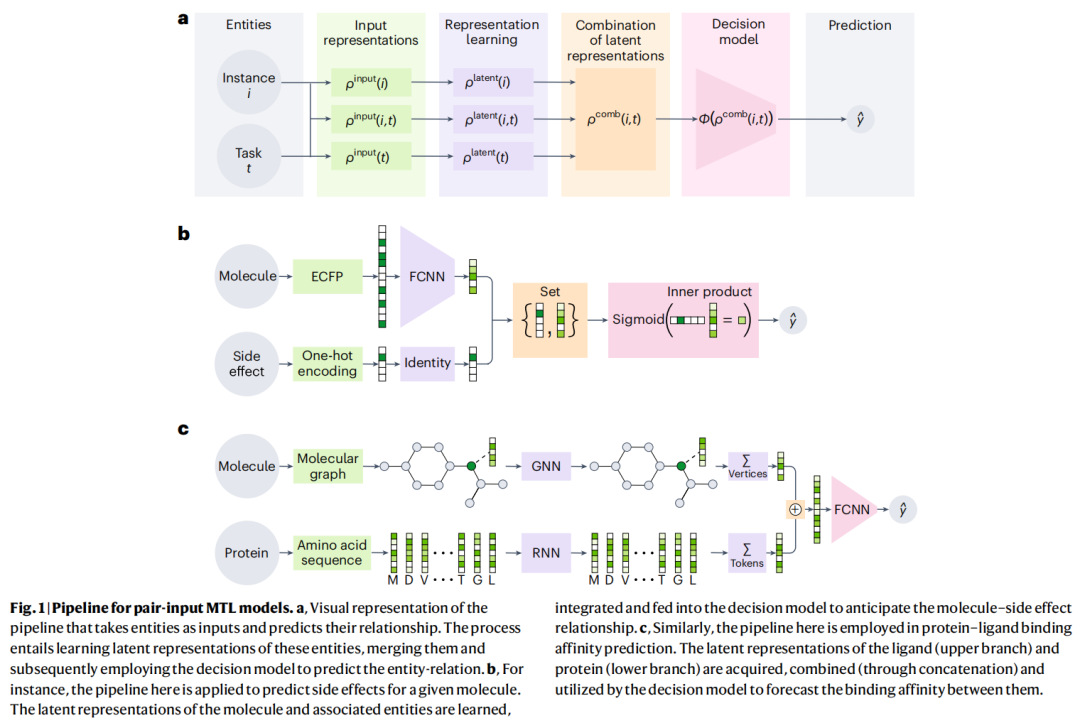
作者提出了一个统一的配对输入 MTL 模型流水线,将现有神经 MTL 模型解构为四个核心模块。
[实例 i] ──→ ρ_input(i) ──→ [表征学习] ──→ ρ_latent(i) ──┐
├──→ ρ_comb(i,t) ──→ [决策模型 Φ] ──→ ŷ
[任务 t] ──→ ρ_input(t) ──→ [表征学习] ──→ ρ_latent(t) ──┘2.1 输入表征(Input Representations)
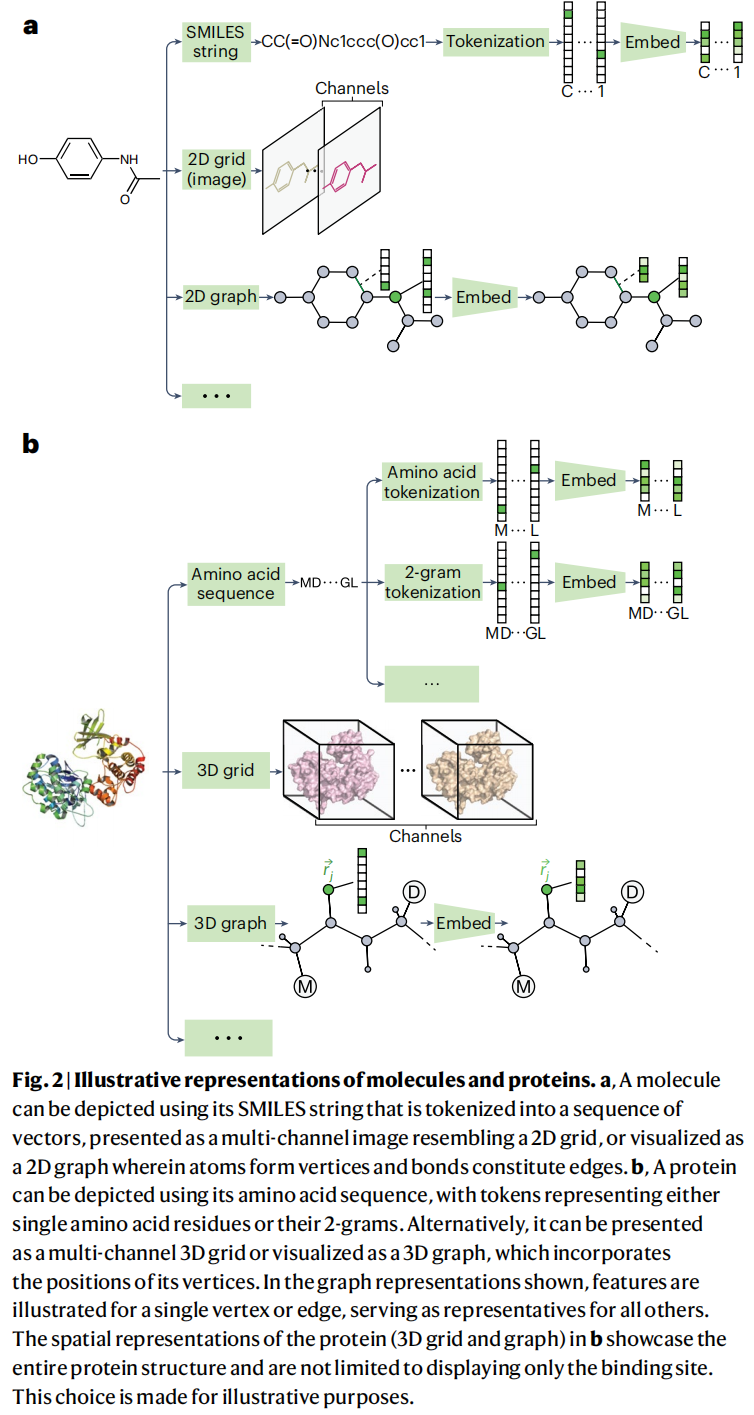
分子输入表征
表征类型 | 代表方法 | 特点 |
|---|---|---|
分子指纹 | ECFP(扩展连通指纹) | 基于结构特征,计算高效,不可微 |
描述符向量 | RDKit 描述符等 | 融合多类物理化学描述符 |
字符串(SMILES) | SMILES、DeepSMILES | 可作为 1D 网格处理,支持序列模型 |
分子图像 | 2D 网格(多通道) | 将原子特征(如电荷、原子序数)编码为图像通道 |
2D 分子图 | 原子为顶点,化学键为边 | 支持 GNN 直接学习结构特征,主流趋势 |
3D 分子图 | 含空间坐标的点云或网格 | 编码构象信息,需结构数据 |
蛋白质输入表征
表征类型 | 描述 |
|---|---|
单氨基酸 token | 序列中每个氨基酸作为独立 token |
重叠/非重叠 3-gram token | 将氨基酸序列分解为三联子序列 |
蛋白质结构域/motif | 以功能域序列作为 token |
3D 网格(硬/软分配) | 将蛋白质结构离散化为三维体素网格 |
3D 图(点云/表面网格) | 原子或伪原子为顶点,空间邻近建边 |
蛋白质-分子复合体联合表征
表征类型 | 代表工作 |
|---|---|
蛋白质-配体相互作用指纹(PL-IFP) | 结构相互作用指纹(SIFt)、原子对计数 IFP |
3D 网格(聚焦结合位点) | KDEEP、OnionNet 系列 |
3D 图(结合位点选择性顶点) | PotentialNet、DENVIS |
2.2 表征学习(Representation Learning)
文章系统梳理了以下神经网络架构在 MTL 药物设计中的应用:
全连接神经网络(FCNN)
- • 适用于向量化输入(指纹、描述符)
- • 早期 MTL 工作(2014–2017)的主流架构
- • 神经正切核(NTK)可在无限宽度极限下实现核回归预测
卷积神经网络(CNN)
- • 1D CNN:处理 SMILES/氨基酸序列(字符串 → 特征图)
- • 2D CNN:处理分子图像、蛋白质-配体 3D 网格截面
- • 3D CNN:处理蛋白质-配体复合体三维体素表征
循环神经网络(RNN)
- • GRU(门控循环单元):用于分子字符串表征学习
- • LSTM(长短期记忆):用于分子和蛋白质序列
Transformer
- • 构建氨基酸序列的潜在表征,捕捉长程依赖关系
图神经网络(GNN) ← 当前最受关注的表征学习范式
GNN 类型 | 核心机制 | 代表应用 |
|---|---|---|
图卷积网络(GCN) | 对邻居顶点特征做卷积聚合 | GraphDTA、GeneralizedDTA |
图注意力网络(GAT) | 学习邻居权重的注意力机制 | AttentiveFP、Withnall et al. |
图同构网络(GIN) | 单射多集函数,理论上等价于 WL 图同构测试 | MGraphDTA、Bao et al. |
广义聚合图网络 | 可学习的聚合函数 | DeepNC |
超图卷积网络 | 支持超边(连接多个顶点的边) | DeepNC |
多尺度图神经网络 | 周期性降维的多尺度特征卷积 | MGraphDTA |
表征学习的两种堆叠策略:
- • 并行堆叠(Parallel Stacking):多个表征学习模型共享输入,输出融合 → 可视为多模态学习
- • 序列堆叠(Sequential Stacking):前一模型的输出作为下一模型的输入
信息网络(Information Networks):将分子或蛋白质建模为信息图的顶点,以已知蛋白质-蛋白质相互作用或化学相似性建边,用于 ADR 预测和 DDI 预测。
2.3 潜在表征的融合方法
融合方法 | 代表工作 | 特点 |
|---|---|---|
拼接(Concatenation) | DeepDTA、GraphDTA 等 | 简单有效,维度增加 |
内积(Inner Product) | 多输出 MTL 模型 | 计算余弦相似度,适合对称任务 |
外积(Outer Product) | DAEM | 捕捉特征间交叉关系 |
注意力机制 | Tsubaki et al.、Weng et al. | 蛋白质序列 token 对图表征加权 |
恒等映射(Identity) | 蛋白质-配体复合体模型 | 直接使用联合表征 |
融合-FCNN | Jones et al. | 基于 FCNN 的多表征融合 |
2.4 决策模型(Decision Models)
决策模型的输出类型由预测目标的数据类型决定:
- • 连续关系(结合亲和力 、、IC;ADME 性质;量子化学性质)→ 线性层或 FCNN 回归
- • 二元关系(活性/非活性;是否具有某种副作用;结合位姿类别)→ Sigmoid + 交叉熵损失
- • 基于相似度的决策(内积、余弦相似度)→ 适用于实例与任务潜在空间的对齐
此外,任务加权(Task Weighting)是 MTL 中的重要问题:Bao et al. 采用了 Kendall et al. 提出的基于不确定性的任务损失加权策略,允许模型自适应地为不同任务分配重要性权重。
三、典型实体类型与关系
在 MTL 药物设计的关系矩阵中,常见的实体类型包括:
实例(Instances)
- • 分子(小分子药物/配体)
- • 分子-分子对(用于药物-药物相互作用)
- • 细胞系(用于表型筛选)
任务(Tasks)
- • 蛋白质靶标(结合亲和力预测的核心任务)
- • 副作用类别(ADR 预测)
- • ADME 终点(吸收、分布、代谢、排泄)
- • 药物-药物相互作用类型(DDI)
- • 毒性类别、反应活性类型等
关系(Relations)
- • 连续关系:、、IC、药物清除率、量子化学性质
- • 二元关系:活性/非活性、是否具有某种 ADR、结合位姿正负样本
四、当前面临的核心挑战与结论
4.1 模型复杂度的选择
近年来 MTL 模型参数量指数级增长,但"模型越复杂越好"的假设值得审视。作者引用 Occam's Razor 原则指出:在预测不确定性范围内,更简单的模型往往应被优先考虑。复杂模型在需要高度平滑预测时不可或缺,但在数据量有限的场景中,过参数化带来的是噪声放大而非性能提升。
4.2 表征的选择
输入表征必须在"信息量充分"与"避免过拟合"之间取得平衡。值得关注的是:
- • 在蛋白质-配体复合体 3D 图表征中,仅使用配体图或蛋白质图,在某些条件下可优于使用完整的相互作用图(Volkov et al., 2022)
- • 并行堆叠多种表征(多模态学习)的有效性高度依赖具体问题场景
- • 表征的选择本质上是一种归纳偏置(Inductive Bias)的体现(详见 Box 4 的认识论讨论)

4.3 归纳偏置的选择
通过将几何深度学习(Geometric Deep Learning)引入 GNN,可将平移不变性、旋转等变性等物理先验知识编码进模型结构,从而约束预测的合理性。此外,聚合操作的选择(求和 vs 均值 vs 最大值)对与分子大小相关的性质预测有显著影响。
4.4 数据与任务的质量管理
- • 精心策划的数据集(信噪比最优)优于盲目堆积的大规模数据
- • 未来数据采集应由主动学习(Active Learning)策略指导,以迭代获取最具信息量的样本
- • 使用多个采用不同输入表征的集成模型(Ensemble),可能比单一超大模型更能有效降低噪声
4.5 数据分割策略
MTL 模型的评估需根据具体应用场景选择合适的分割方式:
分割方式 | 评估重点 | 适用场景 |
|---|---|---|
配体分割(Ligand Split) | 对新配体的泛化能力 | 虚拟筛选 |
蛋白质分割(Protein Split) | 对新蛋白质的泛化能力 | 孤儿靶标预测 |
时间分割(Temporal Split) | 前瞻性预测能力 | 模拟真实发现流程 |
实例-任务联合分割 | 全归纳性能力 | 最严格评估 |
作者建议:将实例、任务及实例-任务联合分割统一纳入归纳性 MTL 模型的基准评估,以全面衡量模型的真实泛化能力。
4.6 适用域与不确定性量化
即使模型在结构上能接受任意蛋白质输入,其实际适用域(Domain of Applicability)仍受训练数据覆盖范围限制。不确定性量化应区分:
- • 偶然不确定性(Aleatoric Uncertainty):源自测量噪声,不可消除
- • 认知不确定性(Epistemic Uncertainty):源自模型参数的不确定性,可通过更多数据降低
当前多数 MTL 工作仅使用小型模型集成(不同初始参数的若干副本)进行不确定性估计,方法较为粗糙,仍有较大改进空间。
4.7 可解释性
神经网络的"黑箱"特性在药物设计中尤为突出。可解释性方法(如基于梯度的特征归因、注意力可视化、SHAP 值)已被初步应用于揭示 MTL 模型的决策逻辑,但系统性的 MTL 可解释性研究仍处于起步阶段。
五、未来展望
作者指出,神经 MTL 在药物设计领域的未来发展方向包括:
- 1. 蛋白质表征的系统性比较:目前缺乏针对不同蛋白质表征方式(序列 vs 3D 图 vs 表面网格)在不同 MTL 任务上的综合基准研究
- 2. GNN 架构的系统性比较:不同 GNN(GCN/GAT/GIN/多尺度 GNN 等)在 MTL 场景下的性能差异尚不明确
- 3. 与主动学习的深度融合:在"设计-合成-测试-分析"(DMTA)循环中,以主动学习策略指导数据采集与模型迭代
- 4. 更严格的不确定性量化:引入贝叶斯方法、深度集成、蒙特卡罗 Dropout 等,系统评估预测置信度
- 5. 可解释性与可信度的提升:开发专门针对 MTL 的可解释性工具,增强模型在实际药物发现中的可信赖性
结语
本综述通过提出统一的配对输入 MTL 流水线框架,系统梳理了神经 MTL 在药物设计中从表征选择到决策模型的全链路设计空间,并对模型复杂度、表征选择、不确定性量化和可解释性等关键挑战提供了深刻见解。
随着大语言模型、基础模型(Foundation Model)在化学与生物学领域的兴起,MTL 的理念与这些新范式的结合值得持续关注。对于从事 AI 制药、计算化学或机器学习的研究者而言,这篇综述提供了一个兼顾理论深度与实践导向的优质参考框架。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号