内存大页核心技术解析:原理、分类、演进与选型

内存大页核心技术解析:原理、分类、演进与选型

霞姐聊IT
发布于 2026-05-20 10:22:36
发布于 2026-05-20 10:22:36
在现代操作系统中,页(Page) 是虚拟内存管理的核心单位。Linux 系统在 x86_64、ARM 等主流架构下,默认基础页大小普遍为 4KB,部分架构还支持 16KB、64KB 等更大规格基础页。
这类标准小页是内存管理的最小调度粒度,也是后续各类大内存优化方案的实现基础。
但伴随着服务器物理内存不断扩容、CPU 核数持续增加,CPU 地址转换缓存 TLB 的压力急剧上升,传统4KB标准页的性能短板愈发明显。
为解决这一痛点,业界陆续推出静态大页HugePage、巨页Gigantic Page、透明大页 THP等经典优化方案。
时至今日,相关技术早已发展成体系完备的大页生态,围绕大内存场景延伸出众多底层配套机制,覆盖内核子系统、多尺寸分页、内存碎片整理、虚拟化适配、硬件架构优化、新型内存模型等诸多方向。
所有大页相关技术的设计目标高度统一:减少TLB 缺页、降低页表资源开销、提升连续内存利用率,更好适配大内存服务器业务场景。
其核心逻辑也完全一致:通过使用更大粒度的内存页,减少页表条目数量,压低地址转换开销,最终提升整机内存访问效率。
下文将从底层原理、技术分类、业务选型与线上实战案例等角度,进行完整深度解析。
一、大页技术诞生核心原因
CPU 访问内存遵循固定流程:虚拟地址→多级页表映射→物理地址,整套地址转换流程高度依赖多级页表与CPU 内置 TLB 高速缓存。
1. 4KB 标准小页的原生痛点
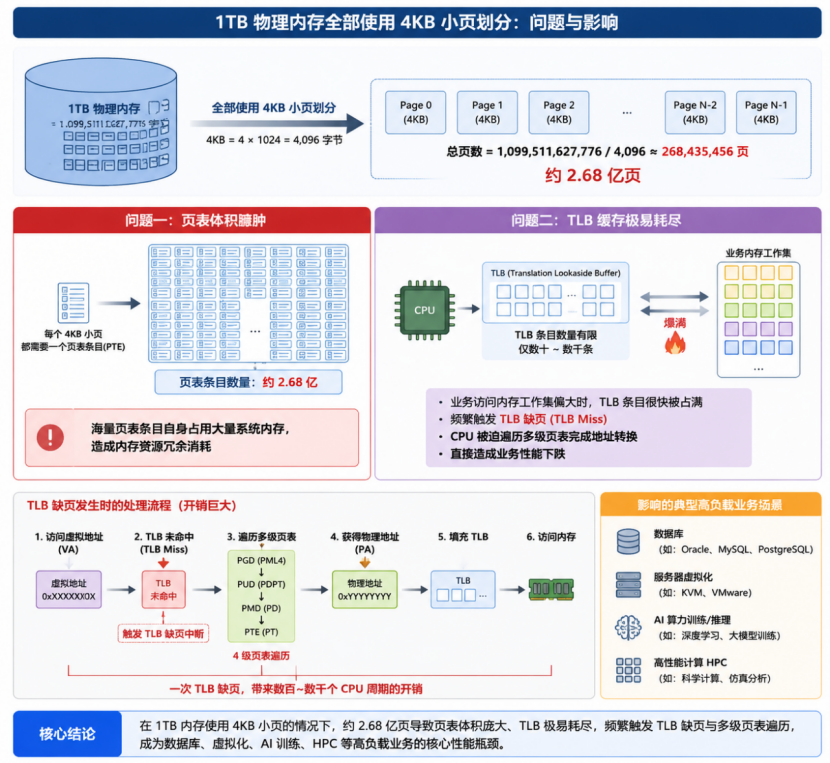
以1TB 物理内存为例,全部使用 4KB 小页划分: 总页数量约2.68 亿,衍生两大致命问题:
(1)页表体积臃肿:海量页表条目自身占用大量系统内存,造成内存资源冗余消耗;
(2)TLB 缓存极易耗尽:CPU 内置 TLB 缓存条目数量有限,仅数十至数千条。业务访问内存工作集偏大时,极易频繁触发TLB 缺页中断,CPU 被迫遍历多级页表完成地址转换,直接造成业务性能下跌。
该问题是数据库、服务器虚拟化、AI 算力训练、高性能计算 HPC 等高负载业务的核心性能瓶颈。
二、静态大页HugePage 与内核原生 HugeTLB 子系统
首先明确定义:HugePage 即静态大页,是 Linux 系统中尺寸大于默认 4KB 标准页、需提前预留并锁定在内存中(不参与 Swap 交换)的专用内存页。
其核心作用是以更大内存粒度精简页表结构、减少TLB 缺页次数,从而大幅降低因 TLB 缺失而引发的多级页表遍历开销,提升大内存场景的访问效率。
在实际技术体系中,支撑整套静态大页调度、分配与管理能力的,并非通用内存机制,而是Linux 内核独立实现的HugeTLB(Huge Translation Lookaside Buffer)大页专属子系统。
1. HugeTLB 核心定义
HugeTLB是内核专为静态预留大页设计的独立管理子系统,也是线上核心业务部署静态大页的底层实现。
(1)核心特性
- 启动时预留,天然连续且无碎片:系统启动阶段提前分配整块连续物理内存,避开运行时内存碎片问题。
- 永久锁定,不Swap、不回收:内存常驻物理内存,既不参与交换分区调度,也不被内核内存回收机制换出。
- 独立管理,与通用内存隔离:拥有独立的HugeTLB 子系统管理逻辑,不与普通 Buddy 分配器争抢资源。
(2)状态查看
cat /proc/meminfo | grep Huge
(3)设置方法
ü引导时配置:
通过修改GRUB配置文件,将参数传递给内核:hugepagesz=<页大小> hugepages=<页数量>
ü运行时配置:
直接向/proc/sys/vm/nr_hugepages 文件写入想要保留的大页数量;
或通过 sysctl 命令设置内核参数\:sysctl vm.nr_hugepages=1024。
2. hugetlbfs 专用文件系统
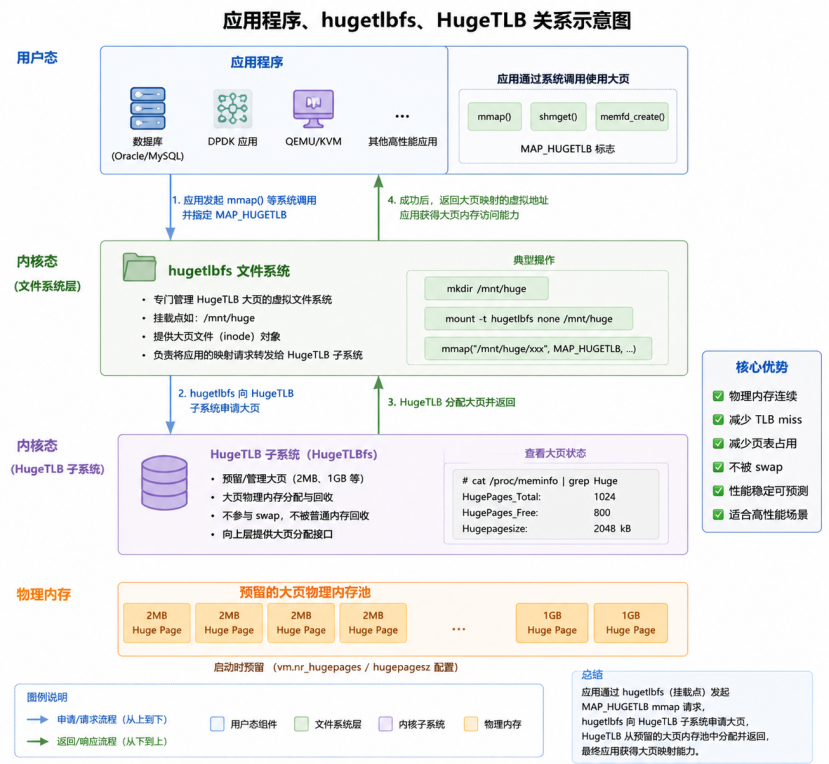
Linux专门提供了hugetlbfs虚拟文件系统,作为应用程序对接内核HugeTLB子系统、使用静态大页的标准入口。
使用时,首先将它挂载到指定目录:
mount -t hugetlbfs none /mnt/huge
业务程序再通过mmap() 系统调用,映射该挂载点下的文件,并配合MAP_HUGETLB 标志,即可向HugeTLB 子系统申请并绑定系统预分配的静态大页资源。
整个过程中,hugetlbfs承担请求转发的角色,将应用的映射请求交给HugeTLB 子系统处理;
内核从预分配的大页池中分配连续物理内存,再通过文件系统返回给应用,完成一次静态大页的绑定。
3. 核心适用业务场景
静态大页凭借高稳定性、低延迟及物理内存连续等优势,广泛用于对运行平稳性要求严苛的生产环境。
以下场景均首选依托HugeTLB 部署静态大页:
(1)关系型数据库:Oracle、PostgreSQL、MySQL(尤其 InnoDB 缓冲池较大时)
(2)内存分析系统:SAP HANA
(3)虚拟化与容器:QEMU/KVM 虚拟机(减少 EPT 缺页异常,提升性能)
(4)高性能网络:DPDK(依赖用户态零拷贝与连续大页)
注意:静态大页存在内部碎片问题,内存总量较小或对象细碎的业务(如部分Redis 实例)不建议启用。
4. x86_64 架构主流大页规格
内存页类型 | 页大小 |
|---|---|
标准普通页 | 4KB |
2MB 大页(标准 HugePage) | 2MB |
1GB 巨页(Gigantic Page) | 1GB |
注:1GB 巨页需要 CPU 支持 pdpe1gb 指令集,且通常通过内核启动参数预留
5. 2MB 大页地址转换细节
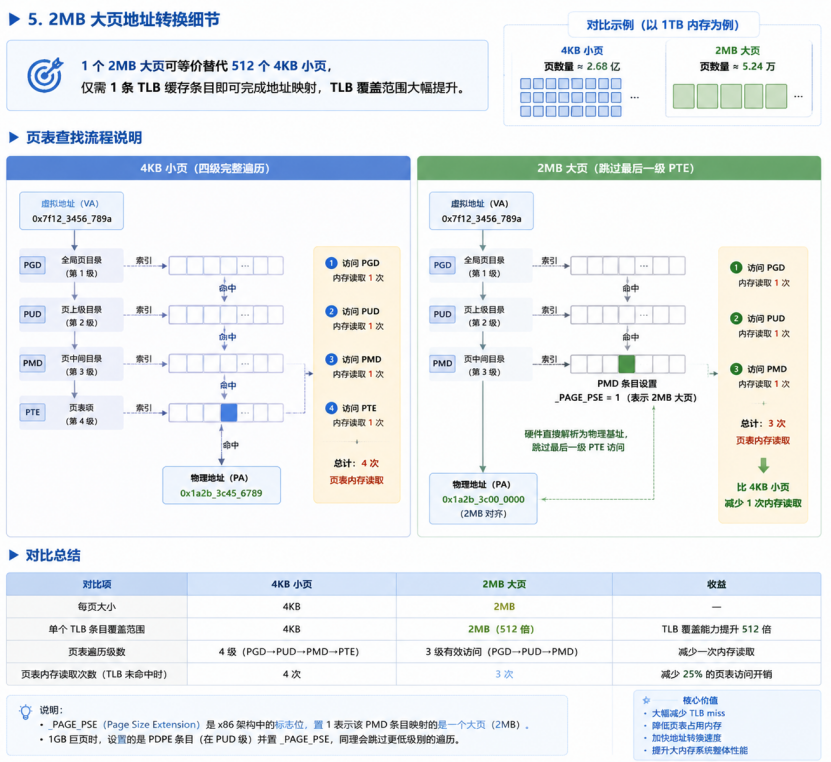
(1)TLB 覆盖范围提升
1个2MB大页可等价替代512个4KB小页,仅需1条TLB条目即可完成地址映射,显著扩大TLB覆盖范围,从而降低TLB miss的发生频率。
(2)页表查找流程对比
4KB 小页:地址转换需要完整遍历四级页表,每级一次内存访问:
PGD → PUD → PMD → PTE
2MB 大页:仍然经过四级页表结构,但在PMD 条目中设置 _PAGE_PSE 标志,硬件直接将该条目解析为物理基址,无需再访问下一级页表(PTE),从而减少一次内存读取,加快地址转换。
总结:2MB大页通过减少页表访问次数和扩大TLB覆盖范围,有效降低地址转换开销,提升CPU内存访问效率。
6. 1GB 巨页深度解析 1GB 巨页属于静态大页体系下的超大规格分页,与普通 2MB 大页在底层实现上存在显著差异。
硬件要求
(1)CPU 必须支持 pdpe1gb 指令集
(2)主板BIOS 需开启对应功能
(3)内核需编译支持(如CONFIG_HUGETLB_PAGE)
查看CPU 指令集示例:
cat /proc/cpuinfo | grep pdpe1gb
页表查找特点
1GB 巨页在 PUD 级设置大页标志;
硬件直接解析为物理地址,跳过PMD 和 PTE 两级页表访问,相比2MB 大页(仅跳过 PTE),进一步减少内存访问次数,降低地址转换开销
分配方式
(1)推荐方式:开机通过内核参数预留
default_hugepagesz=1G hugepagesz=1G hugepages=N
(2)运行时动态分配(仅在内存充足且碎片极低时尝试):
echo N > /sys/kernel/mm/hugepages/hugepages-1048576kB/nr_hugepages
注意:实际热添加成功率较低(难以找到1GB 连续物理内存),生产环境通常不依赖此方式。
典型适配场景
2MB大页适合90%的生产场景,成本低、收益稳。
(1)仅在以下情况考虑1GB 巨页:
(2)单进程内存≥ 64GB,且延迟极度敏感。
(3)硬件支持且业务允许预留巨量连续内存。
(4)能够接受内部碎片(如SAP HANA 的预分配内存池)。
(5)已经完成2MB 大页优化,仍发现 TLB miss 是瓶颈(通过 perf 验证)。
总结:1GB 巨页通过大幅增加页粒度,显著减少页表条目和 TLB miss,提升大内存场景访问效率,但对硬件、内核支持及物理内存连续性有严格要求。
7. 静态大页固有缺陷:内部内存碎片浪费
静态大页的分配粒度较大,业务进程的内存使用往往无法精确对齐页大小,从而产生不可避免的内部碎片。
示例:
假设一个内存对象大小为2.1MB,而静态大页为 2MB 分配单元。
分配时,操作系统需要使用一个完整的大页(2MB)来存放对象的前 2MB 部分;
剩余0.1MB 将占用下一页;
结果,约1.9MB 内存被浪费,长期累积则导致显著的内存利用率下降。
影响:
对轻量级通用业务尤其不友好,因为对象尺寸通常远小于大页
内存碎片不可回收,静态大页占用的物理内存无法被其他进程共享或回收
结论:这种内部碎片是静态大页设计的固有缺陷,也是多数轻量级应用或中小型服务不大规模部署静态大页的核心原因。
技术提示:对于内存使用高度碎片化的场景,可以考虑透明大页(THP)或mTHP 多尺寸大页来缓解内部碎片问题,同时兼顾TLB优化和内存利用率。

三、透明大页THP 及完整扩展体系
1. 为什么需要透明大页(Transparent Huge Pages, THP)?
静态大页(HugeTLB)虽然性能稳定,但存在以下问题,导致运维门槛较高,灵活性有限:
(1)需要手动预留内存
(2)业务程序必须适配hugetlbfs
为了降低使用成本并简化大页部署,Linux 内核引入了透明大页。
2. THP 定义
THP是内核自研的自动大页优化机制,其核心逻辑如下:
内核后台线程khugepaged定期扫描进程地址空间中的匿名内存页,
将连续的4KB小页自动合并为2MB大页
对业务程序零改造、无感知,直接生效
3. 核心特性
(1)懒分配(Lazy Allocation)
分配阶段:应用调用malloc() 或 mmap() 申请内存时,内核优先分配 4KB 标准小页,确保申请快速返回,业务无需等待。
合并阶段:内核后台线程khugepaged 在满足以下条件时,异步扫描并尝试将连续的 4KB 小页合并为 2MB 大页:
l进程存在足够大的连续虚拟地址区域(至少2MB)
l区域内的小页物理地址尽量连续(允许少量空洞,通过页迁移整理)
l系统内存压力不高(避免资源争抢)
可通过/sys/kernel/mm/transparent_hugepage/khugepaged/ 下的参数调整扫描频率与行为
注意:合并是异步且非保证的,取决于内存碎片程度和系统负载。若碎片严重,khugepaged 可能无法完成合并,进程将长期使用 4KB 小页。
(2)无需手动预留:开箱即用,内核自动管理大页的分配、合并与拆分,大幅降低运维门槛。
4. 传统THP 的短板
早期原生THP仅支持2MB单一规格,存在以下弊端:
(1)内存碎片整理开销大 后台线程khugepaged需要不断移动页,以生成连续的2MB空间,消耗CPU和内存资源。
(2)大页拆分资源消耗高 当系统内存压力增大时,2MB大页可能被拆分回4KB小页,增加页表操作开销。
(3)易加剧整机内存碎片化 长期运行后,大页分配与拆分产生的碎片不可回收,降低内存利用率。
(4)小内存业务适配差 对占用几MB的进程,大页分配粒度过大,反而造成内存浪费。
5. 新一代mTHP(Multi-size THP)
mTHP是Linux内核主流演进方向,用于解决单一2MB页粒度过粗的问题
(1)页尺寸支持(由CPU架构+内核配置决定):
x86_64(内核6.6+):64KB、2MB
ARM64:16KB、32KB、64KB、128KB、512KB、2MB等(取决于基础页大小)
(2)设计思路
在TLB优化收益与内存碎片风险之间灵活折中,针对不同应用选择合适页粒度。
(3)核心价值
适配AI、大模型训练等复杂内存访问场景,解决固定2MB大页过粗带来的浪费和性能瓶颈。
6. File-backed THP(文件页透明大页)
传统THP仅支持匿名内存(堆/栈),新版内核拓展支持文件页大页,但需要底层文件系统及挂载选项配合(例如使用mount -o huge=always 挂载,或通过相应 sysfs 接口启用)。
(1)适用场景
RocksDB 等使用内存映射文件(mmap)的数据库
大型 AI 模型文件(模型权重常驻 Page Cache)
系统页缓存(Page Cache)的常规文件 I/O
(2)核心收益
显著降低文件缓存场景下的 TLB miss 频率
提升大文件顺序/随机读性能
是数据库与大模型 AI 场景的重要性能优化手段
注:File-backed THP 的实现依赖内核 Folio 框架,不同内核版本的行为可能有细微差异,生产环境建议先进行验证。
7. THP 运行模式
主流模式:
模式 | 描述 |
|---|---|
always | 系统全局自动启用 THP |
madvise | 仅应用调用 madvise(MADV_HUGEPAGE) 时启用 |
never | 完全禁用 THP |
内核5.4+ 新增 defer 等微调行为,不同发行版实现略有差异。日常运维可主要关注上述三种基础模式。
8. 总结
(1)优势
全自动化,无需业务代码改造
大幅降低运维成本(无需手动预留内存)
适用于大部分通用 Web 服务、中间件、Python/Java 后端
在大内存场景下显著提升 TLB 效率,降低地址转换开销
(2)劣势
后台大页合并(khugepaged)可能导致偶发性延迟抖动
对小内存或轻量级业务不够友好(可能造成资源浪费)
大页拆分与内存碎片整理仍存在一定性能开销
THP 通过自动化大页机制,在性能收益与运维便利性之间取得平衡,尤其适合高内存占用、访问模式复杂的业务场景。
四、虚拟化& 容器场景中页相关优化技术
1. 页表共享(Page Table Sharing / EPT Sharing)
大规模服务器虚拟化集群中,每台虚拟机拥有独立的页表,会占用大量内存,同时增加TLB miss 及页表遍历开销。
通过页表共享机制,多个虚拟机可复用公共页表区域(如同宿主机上运行相同OS 内核的虚拟机),从而缩减页表内存占用,减少 TLB 刷新次数与缺页异常。
该思路与大页“缩减页表体积”的核心思想一致。
2. 嵌套大页(Nested HugePage)
虚拟化存在双层地址转换:客户机虚拟地址(GVA)→ 客户机物理地址(GPA)→ 宿主机物理地址(HPA)。
双层映射使TLB 压力成倍增加。
嵌套大页技术允许客户机使用大页+ 宿主机也使用大页,将两层地址转换的页表级数同时缩减,大幅减少 EPT 页表遍历次数与 VMExit 频率。
该技术是主流公有云底层虚拟化的核心优化手段之一。
3. K8s 容器大页资源隔离
Kubernetes 原生支持大页资源精细化调度,可定义hugepages-2Mi 和 hugepages-1Gi 两种资源。
使用时需同时设置requests 和 limits 且数值相等,并配合 Guaranteed QoS,实现容器间大页资源的独占隔离。
典型应用场景包括:NFV 网络功能虚拟化、DPDK 高速数据面容器、AI 训练与推理容器。普通业务容器极少启用。
五、多架构平台大页布局
1. ARM64 大页体系
ARM 架构(移动端与服务器端)对 TLB 容量依赖较高,原生支持多档位大页(块)组合:
基础页大小 | 支持的大页(块)尺寸 |
|---|---|
4KB | 2MB、1GB |
16KB | 32MB |
64KB | 512MB |
核心原因:ARM 原生 TLB 缓存容量偏小,需要依靠大页机制扩大 TLB 覆盖范围,弥补地址转换性能短板。
2. RISC-V Svnapot 灵活大页
与x86/ARM 固定尺寸大页不同,RISC-V 架构推出了 Svnapot 扩展(Naturally Aligned Power-of-Two)。
该机制允许将 2 的幂次个连续基础页(如 2、4、8 个 4KB 页)组合为一个自然对齐的大页,从而实现多种大页尺寸,不局限于传统的 2MB 或 1GB。Svnapot 为内存管理提供了更高的灵活性,是 RISC-V 在大页支持上的重要创新方向(需硬件与软件共同支持)。
六、静态大页vs 透明大页 THP
对比维度 | 静态HugePage (HugeTLB) | 透明大页THP |
|---|---|---|
管控模式 | 手动配置开机预留 | 内核全自动调度 |
业务感知 | 需业务适配改造 | 完全无感知 |
内存预留 | 提前锁定固定内存 | 动态占用,无强制预留 |
运行稳定性 | 极高,无运行波动 | 一般,存在延迟抖动 |
性能可控性 | 精准可预判 | 不可控 |
运维难度 | 偏高 | 极低 |
内存利用率 | 偏低,易产生内部碎片 | 利用率更高 |
数据库业务 | 官方强制推荐启用 | 主流数据库建议关闭 |
通用Web 业务 | 适配繁琐 | 适配便捷 |
内存回收 | 无法自动回收,易致OOM | 可动态调度回收 |
七、常见认知误区澄清
1. 误区:启用大页可以直接提升物理内存读写带宽
正解:大页不改变DRAM 硬件读写速度,其核心价值仅为降低虚拟地址转换过程中的各类性能损耗(如 TLB miss、多级页表遍历)。
实际业务中TLB 效率的提升可能让 CPU 访存流水线更流畅,但内存带宽本身不变。
2. 误区:THP 性能一定弱于静态 HugeTLB
正解:在系统内存充足、碎片极少的平稳环境下,THP 自动化调度的综合表现不输静态大页。
然而,THP 的后台合并和内存整理可能引发不可控的延迟抖动,因此在数据库等高实时性、低延迟敏感的业务中,静态 HugeTLB 仍然是更稳妥的选择。
3. 误区:页尺寸越大,优化效果越好
正解:1GB 巨页的 TLB 优化效果最强,但分配难度大(需要开机预留 1GB 连续物理内存)、内部碎片浪费严重(每个大页尾部最多浪费 1GB)。
对于内存占用1.5GB 的进程,1GB 巨页需分配 2GB,浪费 0.5GB;而 2MB 大页浪费不超过 2MB。
因此,大页尺寸需根据实际工作集大小和碎片容忍度选择,并非越大越好。
八、总结
内存大页技术是现代Linux 系统应对大内存、多核 CPU 性能瓶颈的核心优化手段。本文从底层原理出发,系统梳理了大页生态的完整脉络,得出以下关键结论:
核心目标不变:所有大页技术(静态HugeTLB、THP、mTHP、1GB 巨页等)均致力于减少 TLB miss、降低页表遍历开销、提升大内存访问效率,而非改变物理内存带宽。
静态HugeTLB 是稳定性基石:通过开机预留、内存锁定、独立管理,为数据库、DPDK、虚拟化等核心业务提供极致稳定与性能确定性,但存在内部碎片和运维成本高的固有缺陷。
透明大页(THP)降低了使用门槛:全自动的懒分配和后台合并机制,让通用Web 服务、中间件等业务零改造获得大页收益,但需警惕后台整理带来的偶发性延迟抖动。
生态持续演进:mTHP 多尺寸大页、File-backed THP、ARM/RISC-V 架构适配、虚拟化嵌套大页、K8s 资源隔离等技术,共同构建了覆盖云原生、AI 训练、边缘计算等全场景的大页优化体系。
选型原则:
延迟敏感型核心业务(数据库、HPC、NFV):首选静态 HugeTLB,必要时使用 1GB 巨页,并关闭 THP。
通用服务与开发测试:优先启用THP 或 madvise 模式,兼顾性能与便捷。
超大内存与AI 场景:根据工作集大小和碎片容忍度,灵活选择 2MB、64KB 或 1GB 大页,并配合 File-backed THP 优化文件缓存。
最终一句话:大页技术不是“越大越好”或“自动最好”,而是根据业务延迟要求、内存规模、运维能力与硬件支持,在性能、稳定性、碎片成本、便捷性之间做出合理权衡的选择。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号