别再被你家的AI骗了!D⁴ Lab社区最新方法TraceLift揭穿‘假推理’,模型思考过程真正靠谱

别再被你家的AI骗了!D⁴ Lab社区最新方法TraceLift揭穿‘假推理’,模型思考过程真正靠谱

AI生成未来
发布于 2026-05-18 16:59:41
发布于 2026-05-18 16:59:41
作者: Tianyang Han等
解读:AI生成未来

TraceLift:让推理过程真正“帮得上忙”
正确答案不是终点。对 planner-executor 系统来说,一段推理轨迹的价值取决于它能不能让后续执行器更容易做对。
- 论文:Correct Is Not Enough: Training Reasoning Planners with Executor-Grounded Rewards
- arXiv:https://arxiv.org/abs/2605.03862
- code: https://github.com/MasaiahHan/TraceLift
从“答案对不对”到“推理有没有用”
过去几年,大模型推理能力的提升很大程度上依赖可验证反馈:数学题看最终答案,代码题跑单测,能通过就给奖励。这套逻辑简单、直接,也很有效。但当 reasoning trace 不再只是解释,而是会被后续模型、工具或执行器继续消费时,问题就变复杂了。
很多系统已经不再是“一个模型直接给最终答案”,而是变成两阶段流程:planner 先写推理、计划、约束或中间步骤,executor 再根据这些内容生成最终代码、答案或动作。在这种情况下,最终结果正确只能说明系统最后跑通了,却不一定说明 planner 写出的推理本身可靠。一个 trace 可能看起来很流畅,也可能刚好导向了正确答案,但它未必真的包含 executor 需要的关键信息。
TraceLift 关注的就是这个更细的问题:如何训练一个 reasoning planner,让它生成的推理不仅表面合理,而且真的能提升 frozen executor 的成功率。
TraceLift 的核心观点
TraceLift 把 reasoning trace 看作一种“中间产物”,而不是普通解释文本。这个中间产物的质量不该只由最终答案决定,也不该只由 LLM judge 判断是否写得像推理,而应该看它对后续 executor 的实际帮助。
它的训练框架可以概括为三部分:planner 生成 reasoning trace,frozen executor 消费 trace 并生成最终 artifact,verifier 判断最终 artifact 是否正确。TraceLift 在这个基础上额外引入一个 Reasoning Reward Model,用来评估 trace 本身的推理质量,并用 executor uplift 去衡量:同一个 frozen executor 在“有这段 reasoning”和“没有 reasoning”时,成功率是否真的变高。 方法如下图:
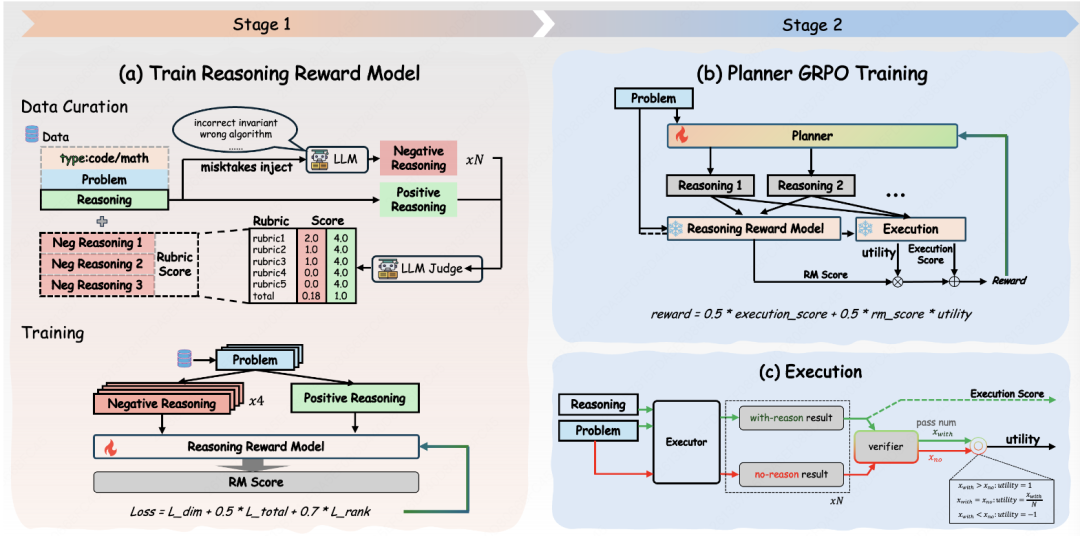
TraceLift framework overview
TraceLift framework overview
最终 reward 不是单一的 outcome reward,而是把三类信号结合起来:最终任务是否成功、推理轨迹本身是否高质量、这段推理是否真的提升了 executor。这样一来,模型不会只因为“答案碰巧对了”就得到高奖励,也不会只因为“推理写得很像样”就被过度奖励。
TraceLift-Groups:专门学习“推理质量”的数据
为了让 Reasoning RM 学会区分推理质量,TraceLift 构造了 TraceLift-Groups。这个数据集不是简单收集题目和答案,而是围绕同一个问题构造一组 reasoning traces:一条高质量参考 trace,以及多条经过局部扰动的 flawed traces。这些 flawed traces 仍然和任务相关,但会破坏关键推理支持。
数据来自两个方向:GSM8K train 和 OpenCodeReasoning,总共构造了 6,000 个 reasoning groups。代码任务中的扰动包括错误算法、遗漏边界情况、off-by-one reasoning、不正确不变量、不可行复杂度、空泛伪解等;数学任务中的扰动包括算术错误、错误操作、遗漏条件、单位不匹配、无支撑跳步、过早给答案等。 这个设计的重点是:让 RM 学到“同一个问题下,哪条推理更可靠、更能支撑后续执行”,而不是简单学习“最终答案是否正确”。
代表结果:TraceLift 到底提升在哪?
下面只放几组最能说明问题的结果,不铺满所有表格。
1. Code:planner 写得更好,executor 真的更容易过测试
在代码任务中,TraceLift 使用固定 planner-executor 协议:planner 先生成 reasoning,frozen executor 再根据 reasoning 写代码,最后用测试判断代码是否正确。也就是说,评测时 executor 不变,变化的是 planner 产生的中间推理。
在 Qwen3-4B 上,TraceLift 相比 Exec-only 在所有代码 benchmark 上都有提升。

这组结果说明,TraceLift 不是让 executor 变强,而是让 planner 生成了更适合 executor 消费的推理。对代码任务来说,这通常意味着更清楚的算法路线、更完整的边界条件、更明确的数据结构和实现约束。
2. Math:推理轨迹越关键,TraceLift 越有价值
数学任务更依赖中间步骤是否真的支撑最终答案。变量定义、单位、运算顺序、条件保留、中间量跟踪,任何一处出错都可能让后续 executor 被带偏。 在 Qwen2.5-7B 上,TraceLift 在数学 benchmark 上的收益非常明显。

尤其是 SVAMP 上的 +21.00 pp 很有代表性:TraceLift 奖励的不是“更长的解释”,而是更能帮助 executor 正确跟踪对象、关系和计算路径的推理。
3. LoRA / Full-Parameter:收益不是单纯来自更多参数
一个自然疑问是:TraceLift 的提升是不是只是因为训练得更充分,或者参数预算更大?论文用 Qwen2.5-7B 比较了 LoRA 和 full-parameter GRPO。在相同参数化设置下,TraceLift 都比 Exec-only 更强。

full-parameter 训练确实能提高部分上限,但它不能替代更好的 reward。TraceLift 的关键不是“多训一点参数”,而是把 reward 对准了更精细的目标:这段推理是否既可靠,又对 executor 有用。
4. Reward 消融:只看最终正确不够,只看推理质量也不够
TraceLift 的 reward 设计里有两个关键轴:最终 verifier 成功,以及 uplift-weighted reasoning reward。论文在 Qwen2.5-7B code 上做了消融,结果很清楚。

No-uplift 去掉了 executor grounding,只保留 reasoning RM 的内在质量分数,结果甚至低于 Exec-only。说明一段推理“看起来质量高”,不代表 executor 真能用上。RM-uplift only 去掉最终 verifier anchor,也不如完整 TraceLift,说明 uplift 不能替代最终任务成功。LLM-as-judge 替换也不理想,因为论文发现 direct judge 分数严重饱和:600 个 logged samples 中有 573 个得分大于 0.95,饱和率 95.50%,平均 judge score 达到 0.990。这样的信号在 GRPO group 内几乎无法区分哪条 trace 更好。
完整 TraceLift 同时保留三件事:最终任务成功、推理质量、executor 实际收益。
我们到底测试了什么?
TraceLift 的实验覆盖了多个模型、任务和训练设置,而不是单点结果。模型包括 Qwen2.5-7B、Llama3.1-8B、Qwen3-4B;任务包括代码和数学;代码评测包括 HumanEval、HumanEval+、MBPP-full、LiveCodeBench;数学评测包括 GSM8K、GSM-Hard、SVAMP、MATH500;训练设置包括 GRPO planner optimization、LoRA GRPO、full-parameter GRPO;额外分析还覆盖了 executor comparison 数量、reward component ablation、LLM-as-judge 替换、reasoning length 和 executor utility dynamics。
整体结论是:TraceLift 在固定 planner-executor 协议下稳定优于 execution-only training。它的收益不是来自更长推理,也不是来自更强 executor,而是来自更合理的训练信号:推理轨迹必须既有质量,又能提升 executor。
TraceLift 的定位:不是让模型“多想”,而是让推理更可执行
很多 reasoning 方法容易把“更长的 CoT”当作能力提升的信号。但 TraceLift 的视角更接近工程系统:推理轨迹是一个接口,接口的好坏不在于它写了多少,而在于它能不能把 executor 需要的信息交代清楚。 在代码里,这些信息可能是算法选择、边界条件、复杂度约束、类型处理和循环不变量。在数学里,它可能是变量定义、中间状态、单位换算、条件保留和目标对象跟踪。TraceLift 奖励的是这些真正可被 executor 使用的内容,而不是流畅但空泛的解释。
所以 TraceLift 可以理解为一种 executor-grounded reasoning training:它不只训练模型“给出推理”,而是训练模型给出“对下游执行真正有帮助的推理”。
哪些场景适合 TraceLift?
TraceLift 最适合 planner-executor 风格的系统:先由一个模型生成计划、推理或中间轨迹,再由另一个 frozen executor 生成最终答案、代码或动作。代码生成是非常自然的场景,因为 planner 需要说明算法、约束和边界条件,executor 再负责实现。数学推理也很适合,因为中间步骤是否可靠会直接影响最终答案。
它也适合那些不希望 reward 被“最终正确”骗过的场景。如果只看最终结果,模型可能学到 shortcut;如果只看 LLM judge,模型可能学到表面流畅的解释。TraceLift 的优势在于把最终成功、推理质量和 executor utility 放在同一个训练信号里。
总结
TraceLift 的核心观点可以概括为一句话:
在 planner-executor 系统里,推理轨迹不只是解释,而是会被下游模型消费的中间产物。
因此,训练 reasoning planner 时,不应该只问最终答案是否正确,也不应该只问推理看起来是否合理,而应该进一步问:这段推理有没有真的帮到 executor?
最核心的结果包括:
- Code:Qwen3-4B 上 code micro avg. 从 65.88 提升到 68.32
- Math:Qwen2.5-7B 上 math micro avg. 从 64.72 提升到 69.23
- LoRA / Full:同等参数化下,TraceLift 持续优于 Exec-only
- Reward 消融:No-uplift、RM-uplift only、LLM-as-judge 都弱于完整 TraceLift
- Judge 分数饱和:direct LLM judge 95.50% 样本得分大于 0.95,难以作为有效 dense reward
TraceLift 给 reasoning training 提供了一个很清晰的新方向:不只是奖励“答对”,而是奖励那些真正能被后续执行器用起来的推理过程。
参考文献
[1] Correct Is Not Enough: Training Reasoning Planners with Executor-Grounded Rewards
技术交流社区免费开放
这是一个高质量AIGC技术社群。
涉及 内容生成/理解(图像、视频、语音、文本、3D/4D等)、大模型、具身智能、自动驾驶、深度学习及传统视觉等多个不同方向。这个社群更加适合记录和积累,方便回溯和复盘。愿景是联结数十万AIGC开发者、研究者和爱好者,解决从理论到实战中遇到的具体问题。倡导深度讨论,确保每个提问都能得到认真对待。

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号