DeepSeek V4 Pro 1个亿Token,到底要花多少钱?

DeepSeek V4 Pro 1个亿Token,到底要花多少钱?

Hello工控
发布于 2026-05-11 13:38:30
发布于 2026-05-11 13:38:30
自从DeepSeek发布V4 Pro和Flash模型来,我就第一时间把这个模型接入了Claude Code:如何在Claude Code里面用上DeepSeek V4 Pro模型?
当然,我为了不在IDE环境里面切来切去,所以,用了VS Code和各类AI工具的扩展:VS Code集成Claude Code,搭配DeepSeek V4 Pro模型,直接开干!
我们这期来分享下这几天V4 Pro和Flash的具体的用量,和实际产生的费用。
01 DeepSeek开放平台
进入DeepSeek官网,然后选择API 开放平台:

然后,我们进入开发平台,选择用量信息即可查看API的用量和实际的费用:
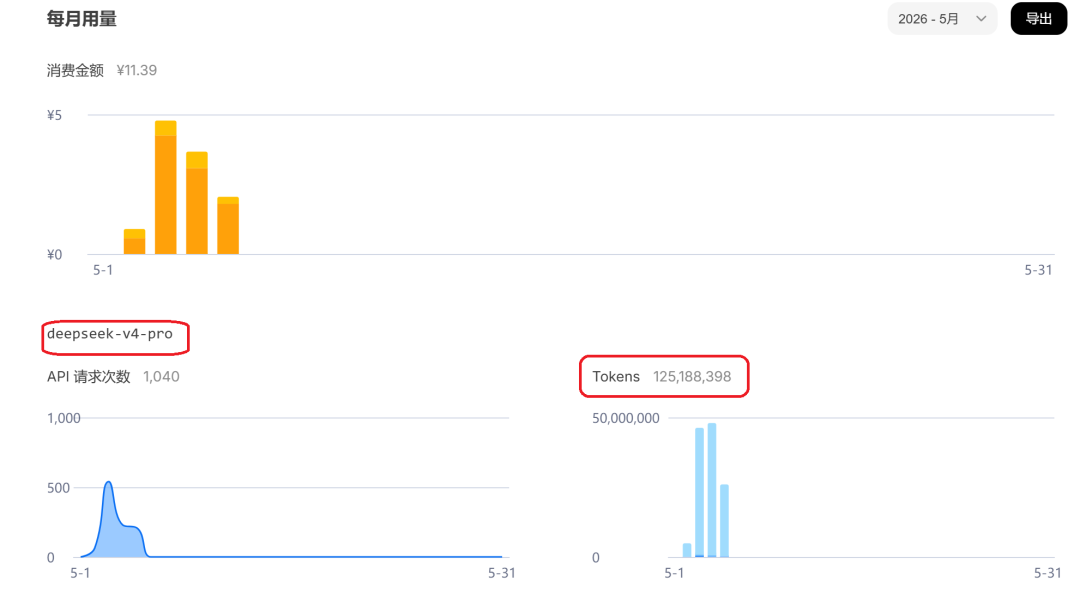
首先,我们看看V4 Pro的实际用量和产生的具体费用:
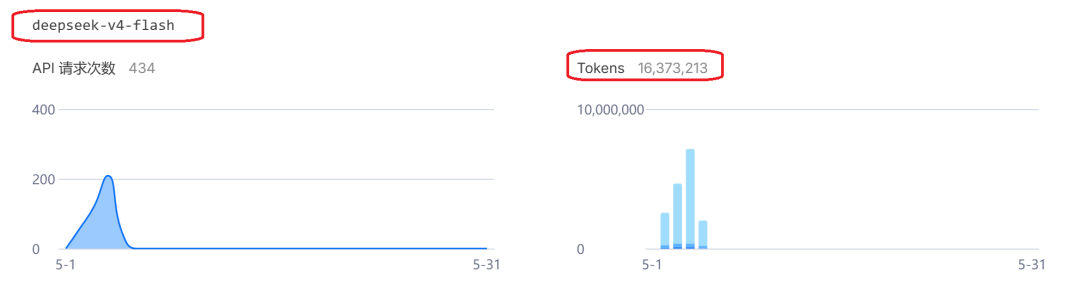
下方紧接着就是V4 Flash的用量和产生的费用:
02 费用分析
同样我们这里也使用DeepSeek开放的识图模式来帮我们分析和总结下:
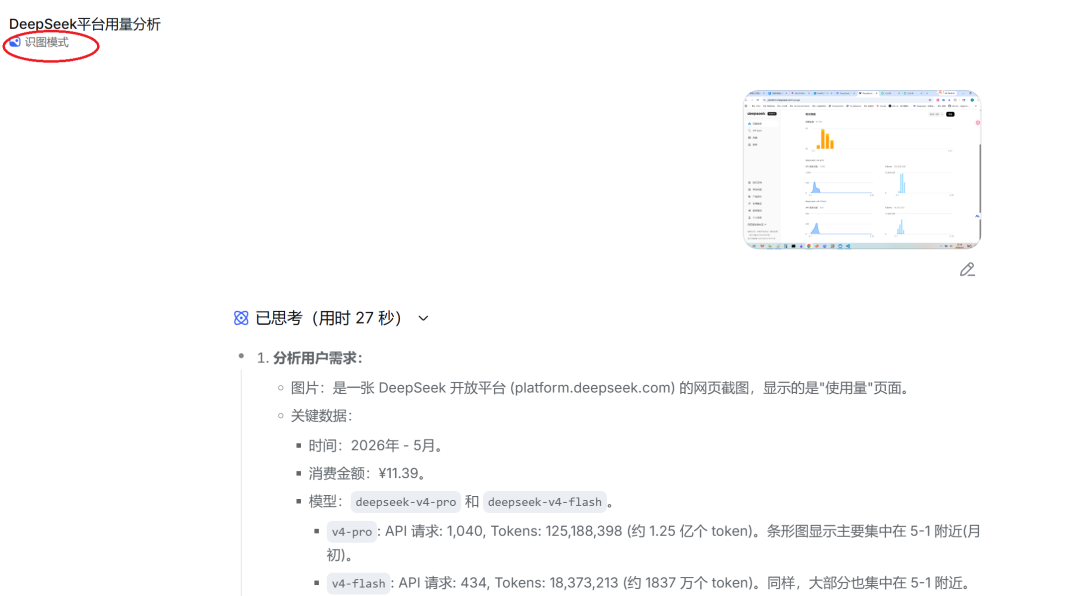
我们主要使用了 deepseek-v4-pro 和 deepseek-v4-flash 两个模型。通过DeepSeek也简单分析了一下我们这次的实际费用:
1. 惊人的性价比
这是最值得关注的点:您这个月总共消耗了 约 1.43亿 Tokens(Token 是AI模型的计量单位,可以理解为字数或计算量)。
v4-pro: 1.25亿 Tokensv4-flash: 1837万 Tokens- 总花费:11.39元人民币。
平均下来,每百万 Token 的成本不到 0.08 元人民币。这说明目前咱们使用的这两个 v4 模型的定价极其良心,或者大量使用了 DeepSeek 特有的上下文缓存(Cache)(命中缓存会比原始计算便宜很多),目前 V4 系列模型的性价比确实非常高。
命中缓存的比例目前是挺高的:
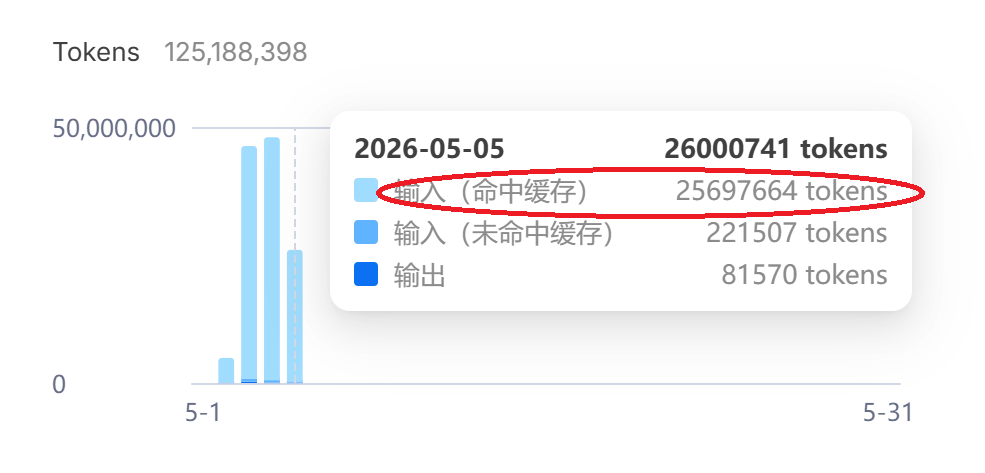
例如:今天命中缓存的量为25697664,占全部的Token的98%:

所以,最后的费用也还好:
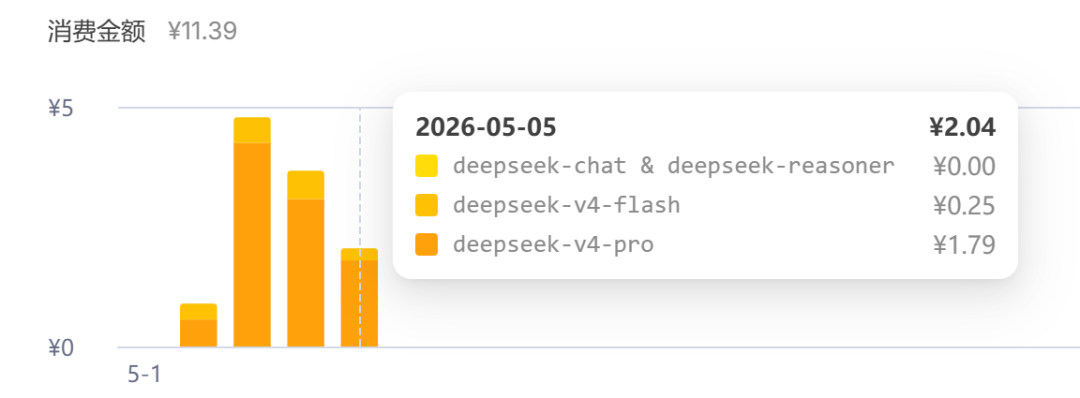
按照这个费用计算:每千万Token费用是约0.69元。
你就说这个费用和国外的费用比起来相差多大吧。
03 小结
国产模型把这个价格做到这个水平和实际效果确实牛!关键DeepSeek官网还有这句话:
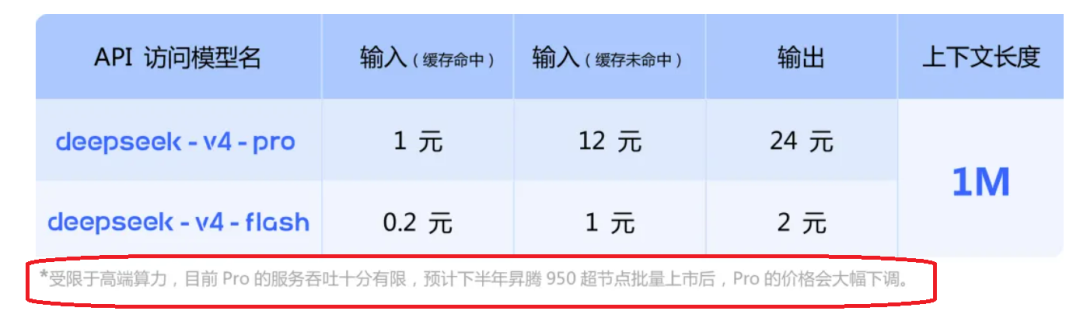
意思,算力上来后,价格还得降下去。服不服吧!
不管怎样,我目前已经把DeepSeek作为主力的模型之一了!大家都用上了吗?体感如何,欢迎留言分享你的使用心得体会哦!
参考链接:
【1】https://www.deepseek.com/
【2】https://platform.deepseek.com/usage
【3】DeepSeek-V4 预览版:迈入百万上下文普惠时代
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号