UniADet | VLM小样本工业异常检测新王者

UniADet | VLM小样本工业异常检测新王者

OpenCV学堂
发布于 2026-04-02 18:59:56
发布于 2026-04-02 18:59:56
作者认为VLM异常检测存在结构过度滥用,文本提示并非必须等问题,为解决这些问题,本文重新思考了视觉-语言模型在异常检测中的核心机制,并提出了一种极其简洁、实现了language-free的VLM,通用且高效的通用视觉异常检测框架-UniADet。
代码库:https://github.com/gaobb/UniADet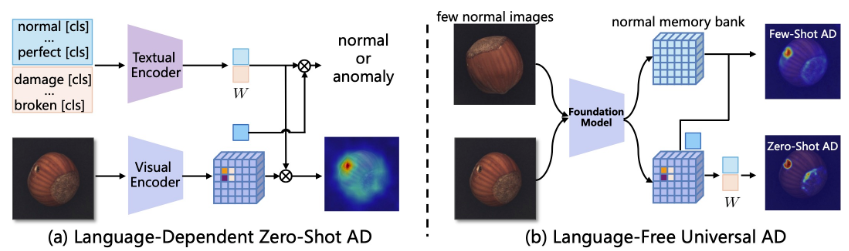
具体而言,我们首先发现语言编码器常被用于推导异常分类与分割的决策权重,随后论证了其在通用异常检测中并非必要。
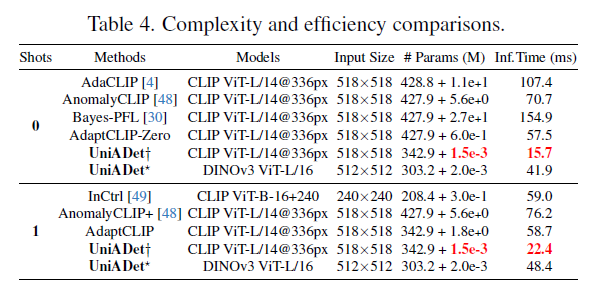
其次,我们提出了一种极其简洁的方法,完全解耦分类与分割任务,并解耦跨层级特征——即为不同任务和层级特征学习独立的权重。UniADet具有高度简洁性(仅学习解耦权重)、参数高效性(仅需0.002M可学习参数)、强通用性(可适配多种基础模型)和高效性能
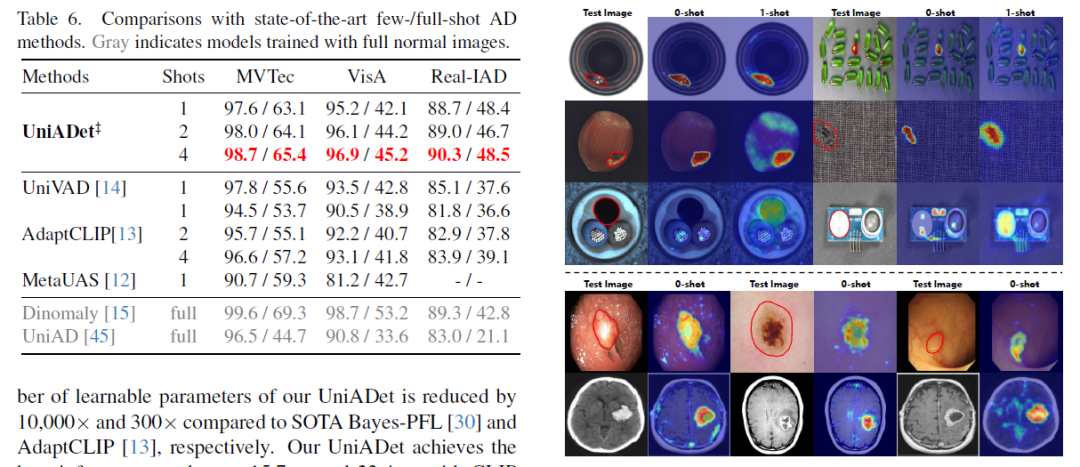
在涵盖工业与医疗领域的14个真实世界异常检测基准测试中,大幅超越当前最优的零样本/小样本方法,甚至首次超越全监督异常检测方法
核心创新与结构
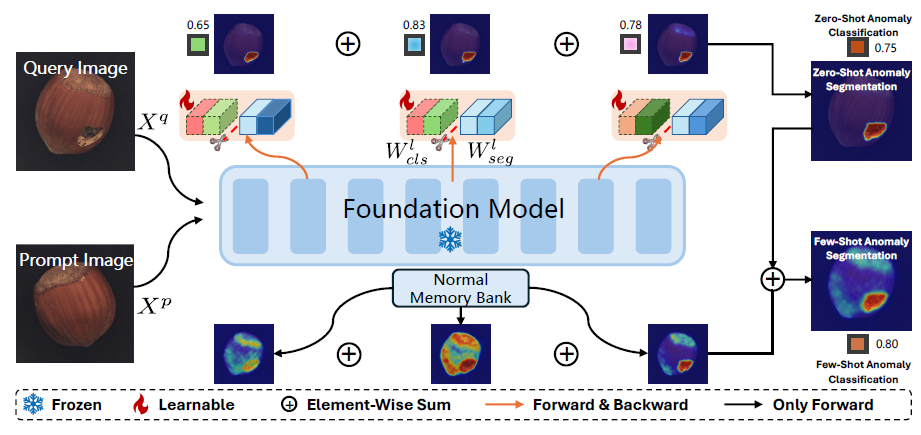
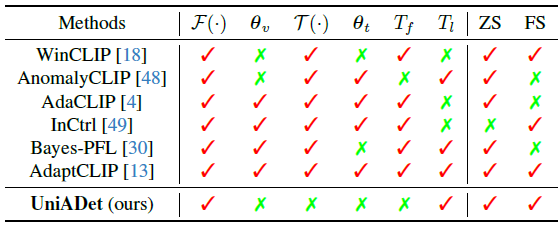
作者目标是开发一种通用异常检测框架,能够在无需对目标数据集进行任何训练或微调的情况下,跨不同领域检测异常。该方法本质上假设训练域与测试域之间存在显著分布差异。框架概览:所提出的 UniADet 包含分类与分割解耦和层级特征解耦 两个核心模块。
1
解耦分类与分割
对于密集视觉感知任务(如目标检测与语义分割),利用基础模型提取的多尺度特征是常见做法。大多数零样本/少样本异常检测工作同样采用多尺度特征,并为这些层级特征共享相同权重。不同尺度的特征自然编码了不同的语义信息,因而嵌入于不同的流形空间中。

令 xqlxql 与 FqlFql 分别表示从第l层提取的全局图像标记与局部图像块标记,Wseg和 Wclsl 为对应层级的特异性权重。因此,第l层的解耦公式进一步优化为以下形式:
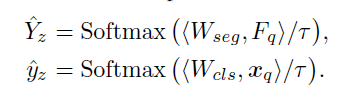
为有效缓解层级特征差异引发的冲突,我们将解耦思想扩展至所有来自不同层级或模块的特征,最终实现多层特异性解耦。这种完全解耦机制确保每一层的异常分类与分割任务能够学习其最优决策边界,而不受异质特征流形的干扰。
2
解耦层次特征信息
对于密集视觉感知任务(如目标检测和语义分割),利用基础模型提取的多尺度特征是常规做法。大多数零样本/少样本异常检测研究也采用多尺度特征,并为这些层级特征共享相同的权重。不同尺度的特征自然编码了不同的语义信息,因此如图5(b)所示,它们嵌入在不同的特征流形中。为了有效缓解由层级特征差异引起的冲突,我们将解耦概念扩展到来自不同层级或模块的所有特征。这最终实现了多层特异性解耦。
令 xql和 Fql 分别表示从第 ll 层提取的全局图像标记和局部图像块标记,Wsegl 和 Wclsl 对应层级的特异性权重。因此,第 ll 层的解耦公式进一步优化为以下形式:
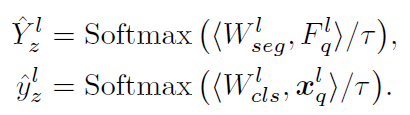
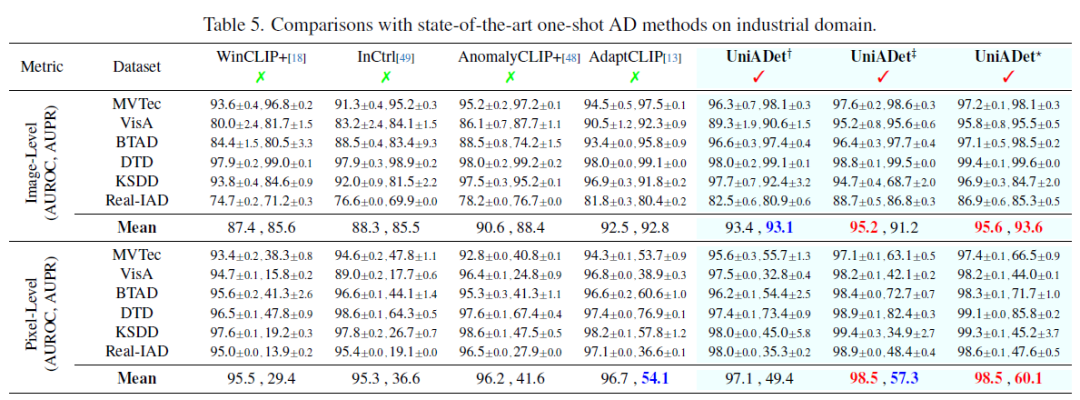
实验结果
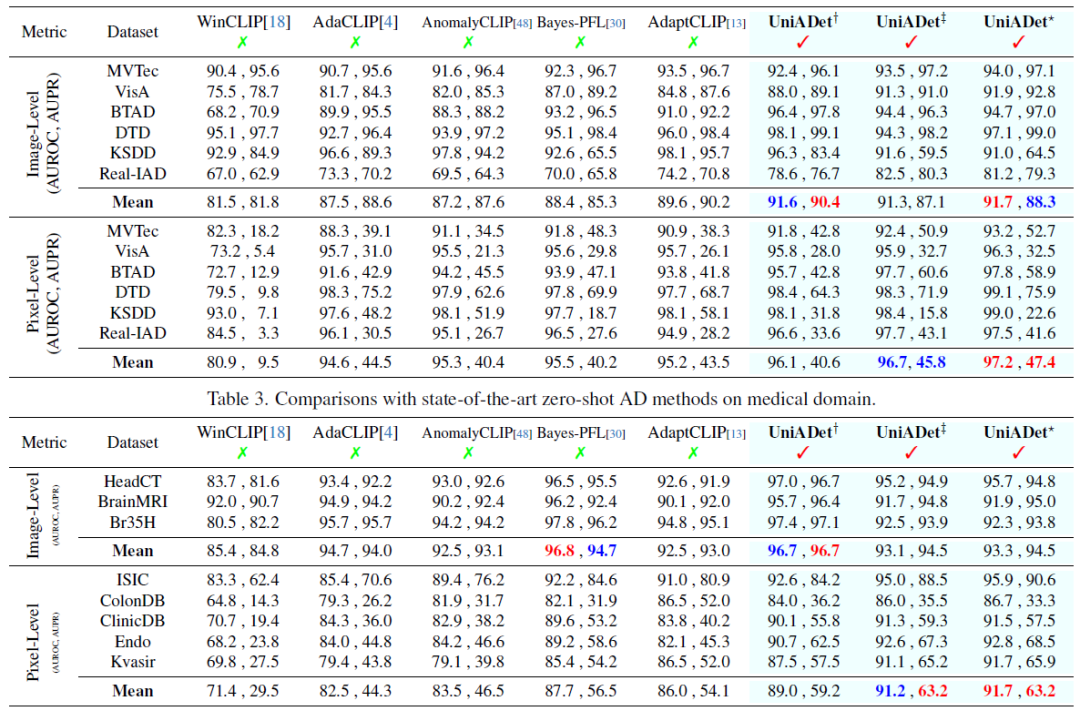
数据集:我们在涵盖工业检测与医疗诊断的两个不同领域中全面评估UniADet。在工业领域,我们使用零样本与小样本设置评估了六个基准数据集:MVTec、VisA、BTAD、DTD、KSDD以及大规模Real-IAD。在医疗领域,我们仅评估零样本设置下的脑肿瘤检测(Head-CTs、BrainMRI、Br35H)、皮肤病变分割(ISIC)、胃肠息肉分割(ClinicDB、ColonDB、Kvasir、Endo)。这些数据集的详细统计信息可在附录中查阅。
评估指标:遵循先前研究,我们在主论文中采用AUROC(受试者工作特征曲线下面积)和AUPR(精确率-召回率曲线下面积)作为图像异常分类和像素异常分割的评估指标。此处需特别指出,像素级AUPR更适用于异常分割任务,因为正常与异常像素间存在极端的类别不平衡问题。在附录中,我们还提供了使用全部指标(包括图像与像素级AUROC、F1max、AUPR以及像素级AUPRO)的详细评估结果。
实验结果对比:
总结
个人看法,就是把CLIP去掉了文本提示,实现了图像-文本解耦的方式完成了异常检测,个人猜测作者肯定参考了DINO系列模型,因为DINO系列模型已经证明了零样本缺陷检测,可以不需要文本提示,所以作者从VLM模型入手,通过两个层次解耦跟去掉文本编码提示部分,修改VLM完成了一个通用的异常检测模型框架。型
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号