"最后一公里"的盲区:首个S2S气候服务多模态基准测试发布


关注地球与人工智能,设置EarthAi星标
S2SSERVICEBENCH:面向最后1km次季节到季节(S2S)气候服务的多模态基准测试

https://arxiv.org/pdf/2602.14017
https://arxiv.org/pdf/2602.14017
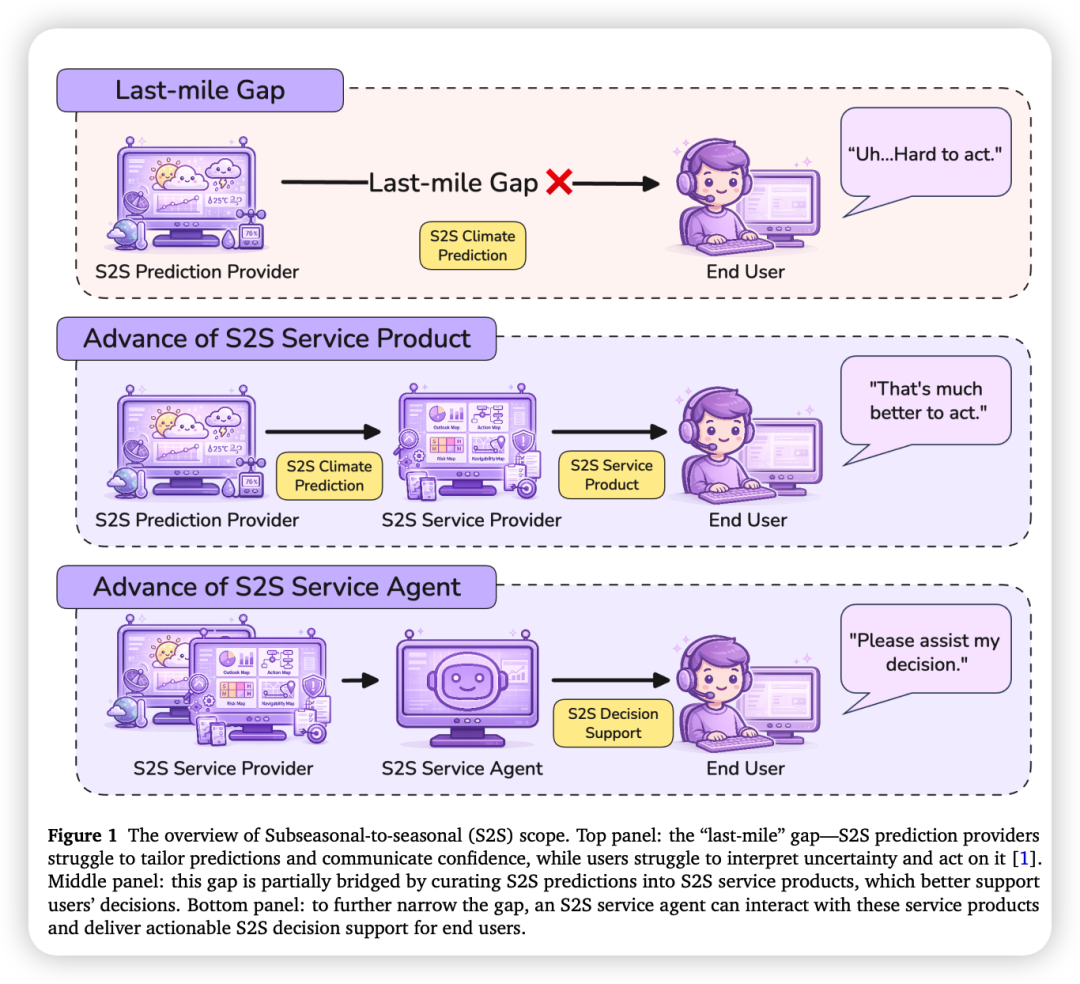
本文提出了S2SSERVICEBENCH,首个专门评估多模态大语言模型(MLLMs)在"最后一公里"次季节到季节(S2S)气候服务中表现的基准测试。该基准从实际业务化气候服务系统中精选了10个服务产品、150+个案例,覆盖农业、灾害、能源、金融、健康、航运六大领域。通过三个递进的服务层级(信号理解、决策交接、分析规划)和两种结构化输出格式(短槽位完成与报告生成),研究系统评估了GPT-5.2、Claude 4.5 Opus、Gemini 3 Pro等前沿模型。结果显示:当前MLLMs在将科学预报转化为可操作的决策支持方面存在显著瓶颈,特别是在时间定位、不确定性量化、触发条件设定和可行性约束处理等方面表现不佳,且标准化智能体工作流并未显著改善性能。研究指出,构建可靠的气候服务智能体需要专门的服务特定训练与评估对齐的防护机制,而非仅依赖通用提示或标准智能体框架。
1. 研究背景:从气候预测到决策服务的"最后一公里"鸿沟
次季节到季节(Subseasonal-to-seasonal, S2S)预测(预报时效约2周至2个月)是气候预测业务中的关键环节,为气候韧性和可持续发展提供关键的决策窗口。然而,这一领域长期存在一个**"最后一公里"差距**(Last-mile Gap):一方面,S2S预测提供者难以将复杂的集合预报结果转化为针对特定部门和地区的可操作信息;另一方面,终端用户(如农业管理者、能源调度员、灾害应急人员)难以解读不确定性并据此采取行动。
近年来,随着多模态大语言模型(MLLMs)和智能体(Agentic)工作流的快速发展,构建能够自动解读业务化服务产品并生成决策支持交付物的"S2S服务智能体"(S2S Service Agent)成为可能。这类智能体需要具备三项核心能力:
- 1. 可操作信号理解(Actionable Signal Comprehension):从多模态产品(如图表、风险地图)中提取时间定位明确、决策相关的信号;
- 2. 决策交接(Decision-making Handoff):将产品证据转化为包含明确触发条件、约束和不确定性场景分支的可执行响应指南;
- 3. 决策分析与规划(Decision Analysis & Planning):基于证据对时空模式进行战略解读,提出规划导向的建议,同时避免过度推断。
然而,关键问题在于:当前的MLLMs或智能体是否能够在业务化服务产品的基础上可靠地提供这三项核心能力? 为回答这一问题,研究团队构建了S2SSERVICEBENCH。
2. S2SSERVICEBENCH基准测试框架
2.1 基准设计原则
S2SSERVICEBENCH基于四个设计原则构建,直接针对最后一公里S2S服务的业务需求:
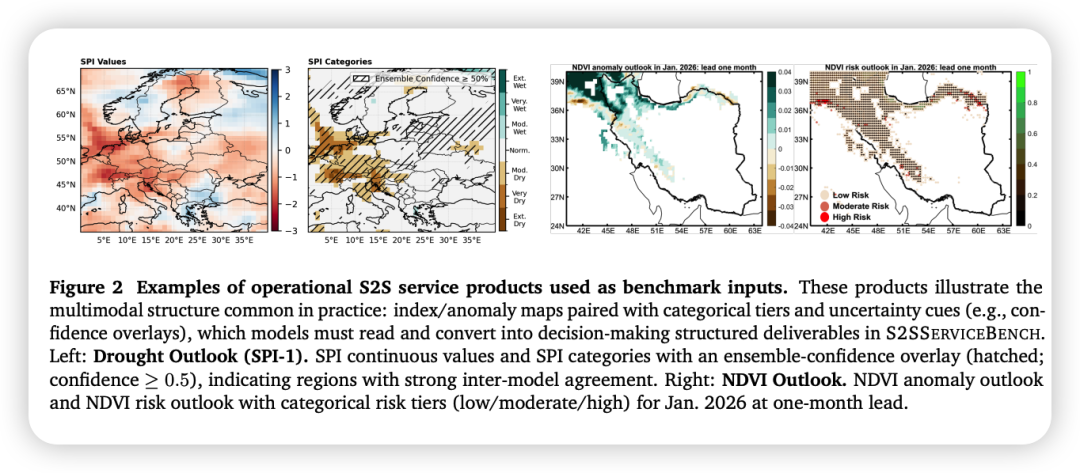
- • 业务真实性:任务源自真实业务产品,保留实际可视化模板、置信度标识和工作流约束;
- • 时间定位评估:大量任务要求识别和报告正确的有效时间窗口(如第2-4周、第1个月),这对诊断S2S服务中的时间定位故障至关重要;
- • 不确定性感知推理:任务要求模型表示产品中的不确定性信号(如概率、置信度、风险类别),而非将预报视为确定性陈述;
- • 交付物导向:评估模型是否能够生成业务可用的产出(从可操作的短字段到报告式决策交接),而非仅回答自由形式的问题。
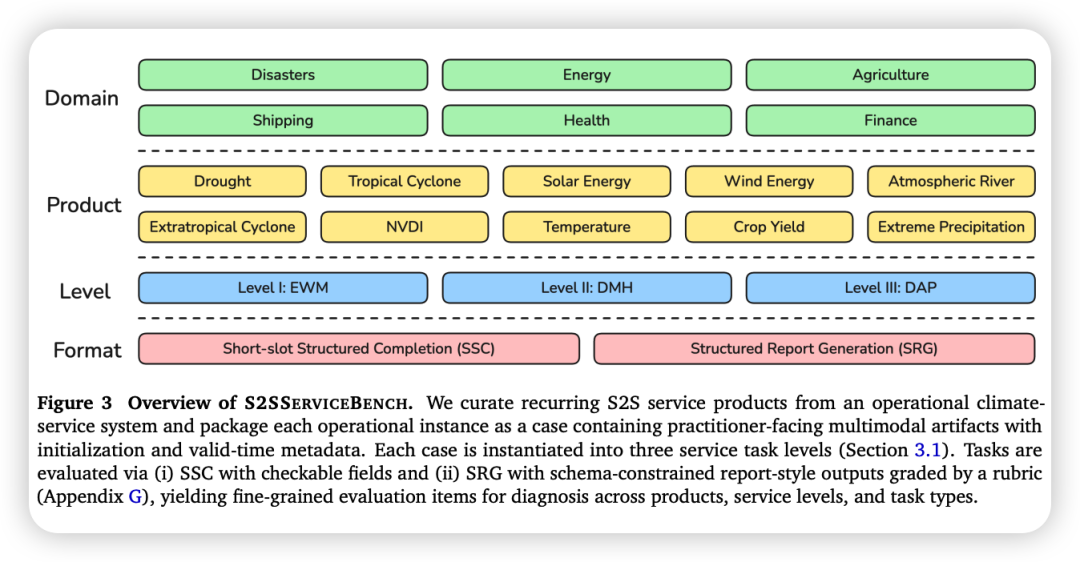
2.2 产品分类与覆盖范围
基准涵盖10个经常性业务服务产品,跨越六大高影响应用领域:
产品类型 | 覆盖领域 | 业务用途 |
|---|---|---|
干旱展望 (Drought) | 农业、灾害、金融 | 基于SPI指数的水资源管理和早期预警 |
NDVI异常展望 | 农业、金融 | 基于归一化植被指数的农业胁迫监测 |
作物产量展望 | 农业、金融 | 空间显式的产量预测,支持粮食安全评估 |
太阳能潜力展望 | 能源 | 太阳能资源分布和低光照事件概率,支持可再生能源规划 |
风能潜力展望 | 能源 | 风资源概率预报,支持能源调度和运营规划 |
热带气旋展望 | 灾害、航运、金融、能源 | 路径可视化及强度分类,支持灾害防备 |
温带气旋频率展望 | 灾害、航运、能源 | 中纬度灾害监测和防备规划 |
极端降水频率 | 灾害、农业、金融 | 月尺度极端降水累积频率预报 |
大气河展望 | 灾害、能源、农业 | 检测大气河路径和强度,支持洪水防备和水资源管理 |
温度监测 | 健康、能源、农业 | 温度异常和集合时间序列摘要,支持高温风险监测 |
2.3 三级服务能力评估体系
每个案例被实例化为三个服务任务层级,逐步测试从基础阅读到决策交付的能力:
Level I: 信号理解 — 早期预警与缓解(EWM)
- • 目标:从服务产品中提取决策相关信号(受影响区域、风险层级、置信度提示),并以机器可消费的形式输出,要求正确的时间定位;
- • 输出格式:短槽位结构化完成(SSC, Short-slot Structured Completion),严格模式约束的JSON格式,禁止自由形式说明;
- • 评估要点:模式合规性和槽位级准确性。
Level II: 行动交接 — 决策交接(DMH)
- • 目标:生成业务可用的决策交接,将产品信号转化为不确定条件下的可执行响应指南,包含明确的场景分支(高/中/低置信度;最优/基准/最差情况)和应急行动;
- • 输出格式:结构化报告生成(SRG, Structured Report Generation),预定义字段的报告式交接;
- • 评估要点:基于评分标准的维度评估,强调触发条件/时间清晰度、可行性/约束、不确定性处理、可操作性和证据基础。
Level III: 战略评估 — 决策分析与规划(DAP)
- • 目标:提供基于推理的战略评估,解释服务产品中的时空模式,识别关键异常区域/信号及其潜在影响,提出规划导向的考虑(监测优先级、防备姿态、长期风险管理);
- • 输出格式:SRG格式,包含预定义的分析/规划字段(关键信号、影响、假设、规划说明、不确定性/限制);
- • 评估要点:强调证据基础、不确定性校准、影响清晰度、规划指导和业务可行性。
2.4 评估项目规模
- • 案例数:约161个专家精选案例
- • 任务数:约500个(每个案例在3个层级实例化)
- • 评估项目数:1,000+个检查项
- • 评估格式:SSC(Level I为主)和SRG(Level II-III)
3. 实验设计与评估方法
3.1 评估协议
短槽位结构化完成(SSC)评估:
- • 模式合规性:输出必须解析为有效JSON并符合所需模式;
- • 字段评分:布尔值(精确匹配)、数值(相对误差<5%)、字符串(LLM作为评判者处理语义等价和地理区域覆盖);
- • 地理区域匹配:采用基于覆盖率的评分,计算预测区域与参考区域的重叠度。
结构化报告生成(SRG)评估: 采用六维度评分标准(每项0-5分):
- 1. 情境定制(Context Tailoring):地理/部门/人口/资产特异性;
- 2. 可操作性(Actionability):具体可执行的措施;
- 3. 触发条件与时间/时效清晰度(Trigger & Time/Horizon):明确的激活-升级-降级时机和操作触发条件;
- 4. 证据基础(Evidence Grounding):行动与输入产品证据的一致性;
- 5. 可行性与约束(Feasibility & Constraints):识别能力、资源、协调、安全、法规等限制并提供可行替代方案;
- 6. 不确定性与置信度处理(Uncertainty & Confidence):利用置信度调节行动强度(低遗憾vs.承诺行动),提供应对意外情况的应急分支。
3.2 测试模型
研究评估了当前最先进的MLLMs,包括:
- • 专有模型:GPT-5.2 (OpenAI)、Grok-4 (xAI)、Claude 4.5 Opus (Anthropic)、Gemini 3 Pro (Google)
- • 开源模型:Qwen3-VL-32B-Instruct (阿里巴巴)、Llama 4 Maverick Instruct (Meta)
3.3 推理设置
两种评估协议:
- • 直接提示(Direct Prompting):单轮次查询,测试独立能力;
- • 智能体工作流(Agentic Workflow):基于LangChain Deep Agents的标准化脚手架,包含轻量级规划、基于文件的工作空间和Tavily网络搜索工具访问。
4. 实验结果与关键发现
4.1 总体能力水平评估
Level I(信号理解)表现:
- • 即使顶尖模型(GPT-5.2和Gemini 3 Pro)的总体准确率也仅约36%,绝对性能仍然较低;
- • 这表明瓶颈不在于生成能力,而在于S2S服务图表理解和可检查提取。
Level II(决策交接)表现:
- • GPT-5.2表现最佳(总体0.64),其次是Claude 4.5 Opus(0.51);
- • 但不同产品间差异巨大,例如GPT-5.2在温度产品上表现优异(0.915),但在极端降水(0.36)和NDVI(0.29)上表现较差。
Level III(分析规划)表现:
- • GPT-5.2仍领先(总体0.51),但主题间方差更大;
- • 在动态灾害(如热带气旋、大气河)上性能显著下降,表明为动态灾害生成稳定的决策导向规划交付物存在持续困难。
4.2 决策支持交付物的关键瓶颈
通过SRG评分标准分析,研究识别出以下核心瓶颈:
证据基础(EG)普遍较强:
- • GPT-5.2在各产品上的EG评分通常较高(3.2-4.8),表明模型通常能够基于提供的服务产品证据,而非产生无根据的叙述。
操作化维度存在严重缺陷:
- • 触发条件与时间/时效清晰度(TTH):在大气河(2.53/5)、温带气旋(2.45/5)等产品上表现不佳;
- • 可行性与约束(FC):在风能(4.00→0.31,Level III骤降)、热带气旋(接近0分)等产品上崩溃;
- • 不确定性与置信度处理(UC):在动态灾害产品上常接近0分,即使证据基础仍强。
关键洞察:主要困难不在于多模态基础本身,而在于将产品信号可靠地转化为具有可执行触发条件、资源感知可行行动和不确定条件下应急分支的决策支持交付物。
4.3 直接提示 vs. 智能体范式
令人意外的发现:标准化智能体工作流并非可靠改进:
- • Level I:智能体带来小幅提升(GPT-5.2: 0.3613→0.3800),符合多步脚手架有助于严格槽位填充的预期;
- • Level II:智能体降低了两款模型的性能(GPT-5.2: 0.6379→0.6115;Claude 4.5: 0.5054→0.4326),表明通用多步工作流可能偏离严格的证据/约束要求,或在不确定性条件下的行动指导中累积中间错误;
- • Level III:效果不一致,GPT-5.2略有提升(0.5088→0.5588),但Claude 4.5显著下降(0.4181→0.3425)。
启示:标准化脚手架对于生成业务化决策支持交付物并非万能药,甚至可能有害。这突显了标准通用智能体工作流的潜在缺陷,并表明鲁棒的决策支持交付物可能需要专门的气候服务智能体,具有更严格的证据和约束感知控制,而非依赖标准化通用工作流。
5. 气候服务智能体的未来方向
基于上述发现,论文提出了构建未来气候服务智能体的具体路径:
5.1 能力对齐的智能体组件设计
针对三个核心能力的各自缺陷,需设计专门组件:
针对可操作信号理解:
- • 产品感知理解技能:开发专门针对S2S产品可视化约定(如SPI图、NDVI异常图)的解读技能;
- • 验证器:针对时间/区域/风险槽位的时间定位验证器和区域匹配验证器。
针对决策交接:
- • 约束检查器:自动检测计划中的资源、政策、操作限制冲突;
- • 触发条件生成器:基于产品信号自动生成明确的阈值和条件;
- • 不确定性条件分支模板:确保低置信度与承诺行动的明确映射。
针对决策分析与规划:
- • 规划子智能体:检索领域背景(报告、数据库、政策),同时执行非过度声称的证据规则;
- • 长期风险评估模块:在保持证据基础的同时,处理动态灾害的长期影响评估。
5.2 工具集成与领域知识
现代智能体系统可通过以下工具增强气候服务能力:
- • 代码执行:用于定量检查和单位转换;
- • 网络/政策搜索:获取操作规则和预警;
- • 检索增强:基于大气报告、公告和历史灾害目录;
- • 领域数据库查询:再分析/预报档案、灾害编目、阈值和气候学数据。
6. 结论与启示
S2SSERVICEBENCH首次系统评估了MLLMs在业务化S2S气候服务"最后一公里"中的表现,揭示了当前技术与实际业务需求之间的显著差距:
- 1. 产品异质性:不同服务产品间性能差异巨大,单一"多模态推理"分数无法捕捉服务就绪性;
- 2. 操作化瓶颈:主要瓶颈不在于多模态理解,而在于触发条件设定、时效清晰度、可行性约束处理和不确定性到行动的映射;
- 3. 智能体局限性:标准化智能体脚手架不仅未能解决这些问题,有时还加剧了性能下降,表明需要专门的气候服务智能体设计;
- 4. 动态灾害挑战:对于热带气旋、大气河等动态灾害,在决策分析和规划层面性能接近崩溃,突显了在快速演变灾害条件下维持证据基础和不确定性感知的困难。
这项研究为气候AI社区提供了明确的行动指南:开发可靠的气候服务智能体需要服务特定的训练、评估对齐的防护机制和业务感知接口,而非仅依赖提示工程或通用智能体框架。随着S2S预测能力的不断提升,缩小这最后一公里的差距将是实现气候韧性社会的关键一步。
以上是对文章的详细解读,如有不当之处欢迎批评指出!
END
声明:欢迎转载、转发。气象学家公众号转载信息旨在传播交流,其内容由作者负责,不代表本号观点。文中部分图片来源于网络,如涉及内容、版权和其他问题,请联系小编处理。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号